Creación de tablas
Aunque ejecutar un rastreador es el método recomendado para hacer un inventario de los datos incluidos en sus almacenes de datos, puede añadir tablas de metadatos al AWS Glue Data Catalog manualmente. Este enfoque le permite tener más control sobre las definiciones de los metadatos y personalizarlas de acuerdo con sus requisitos específicos.
También puede agregar tablas al Catálogo de datos manualmente de las siguientes formas:
-
Utilice la consola de AWS Glue para crear de forma manual una tabla en el AWS Glue Data Catalog. Para obtener más información, consulte Creación de tablas mediante la consola.
-
Use la operación
CreateTableen API de AWS Glue para crear una tabla en AWS Glue Data Catalog. Para obtener más información, consulte Acción CreateTable (Python: create_table). -
Utilice plantillas de AWS CloudFormation. Para obtener más información, consulte AWS CloudFormation para AWS Glue.
Al definir una tabla de forma manual mediante la consola o una API, especifica el esquema de tabla y el valor de un campo de clasificación que indica el tipo y el formato de los datos de la fuente de datos. Si un rastreador crea la tabla, el formato de los datos y el esquema se determinan por un clasificador personalizado o un clasificador integrado. Para obtener información adicional acerca de cómo crear una tabla mediante la consola de AWS Glue, consulte Creación de tablas mediante la consola.
Temas
Particiones de la tabla
Una definición de tabla de AWS Glue de una carpeta de Amazon Simple Storage Service (Amazon S3) puede describir una tabla con particiones. Por ejemplo, para mejorar el desempeño de las consultas, una tabla con particiones podría separar datos mensuales en diferentes archivos con el nombre del mes como clave. En AWS Glue, las definiciones de tabla incluyen la clave de partición de una tabla. Cuando AWS Glue evalúa los datos de carpetas de Amazon S3 para catalogar una tabla, determina si se agrega una tabla individual o con particiones.
Puede crear índices de partición en una tabla para obtener un subconjunto de las particiones en lugar de cargar todas las particiones de la tabla. Para obtener más información sobre cómo trabajar con índices de partición, consulte Creación de índices de particiones .
Todas las condiciones siguientes deben cumplirse para que AWS Glue cree una tabla con particiones para una carpeta de Amazon S3:
-
Los esquemas de los archivos son similares, según determine AWS Glue.
-
El formato de datos de los archivos es el mismo.
-
El formato compresión de los archivos es el mismo.
Por ejemplo, es posible que posea un bucket de Amazon S3 denominado my-app-bucket, en el que almacene datos de aplicaciones de ventas de iOS y Android. Los datos se distribuyen en particiones por año, mes y día. Los archivos de datos para ventas iOS y Android tienen el mismo esquema, formato de datos y formato de compresión. En AWS Glue Data Catalog el rastreador de AWS Glue crea una definición de tabla con claves de partición para año, mes y día.
En la siguiente lista de Amazon S3 para my-app-bucket se muestran algunas de las particiones. El símbolo = se utiliza para asignar valores de clave de partición.
my-app-bucket/Sales/year=2010/month=feb/day=1/iOS.csv my-app-bucket/Sales/year=2010/month=feb/day=1/Android.csv my-app-bucket/Sales/year=2010/month=feb/day=2/iOS.csv my-app-bucket/Sales/year=2010/month=feb/day=2/Android.csv ... my-app-bucket/Sales/year=2017/month=feb/day=4/iOS.csv my-app-bucket/Sales/year=2017/month=feb/day=4/Android.csv
Enlaces de recursos a tabla
| La consola de AWS Glue se ha actualizado recientemente. La versión actual de la consola no admite enlaces de recursos a tabla. |
El Catálogo de datos también puede contener enlaces de recursos a tablas. Un enlace de recursos a tablas es un enlace a una tabla local o compartida. En la actualidad, puede crear enlaces de recursos solo en AWS Lake Formation. Después de crear un enlace de recurso a una tabla, puede utilizar el nombre del enlace de recursos donde quiera que utilice el nombre de la tabla. Junto con las tablas que posee o que se comparten con usted, los enlaces de recursos a tablas son devueltos por glue:GetTables() y aparecerán como entradas en la página Tables (Tablas) de la consola de AWS Glue.
El Catálogo de datos también puede contener enlaces de recursos a tablas.
Para obtener más información acerca de los enlaces de recursos, consulte Creación de enlaces de recursos en la Guía para desarrolladores de AWS Lake Formation.
Creación de tablas mediante la consola
Una tabla en el AWS Glue Data Catalog es la definición de metadatos que representa los datos en un almacén de datos. Puede crear tablas al ejecutar un rastreador, o bien puede crear una tabla manualmente en la consola de AWS Glue. En la lista Tablas en la consola de AWS Glue se muestran los valores de los metadatos de su tabla. Puede usar definiciones de tabla para especificar orígenes y destinos al crear trabajos de ETL (extracción, transformación y carga).
nota
Con los cambios recientes en la consola de administración de AWS, es posible que tenga que modificar sus roles de IAM existentes para obtener permiso de SearchTables. Para la creación de nuevos roles, se agregó de forma predeterminada el permiso de la API de SearchTables.
Para comenzar, inicie sesión en AWS Management Console y abra la consola de AWS Glue en https://console.aws.amazon.com/glue/
Adición de tablas en la consola
A fin de usar un rastreador para agregar tablas, elija Agregar tablas y Agregar tablas mediante un rastreador. A continuación, siga las instrucciones en el asistente Adición de rastreadores. Cuando se ejecuta el rastreador, se agregan las tablas al AWS Glue Data Catalog. Para obtener más información, consulte Uso de rastreadores para completar el Catálogo de datos .
Si conoce los atributos necesarios para crear una definición de tabla de Amazon Simple Storage Service (Amazon S3) en su Data Catalog puede crearla con el asistente de tabla. Elija Agregar tablas, Agregar tabla manualmente y siga las instrucciones en el asistente Agregar tabla.
Al agregar una tabla manualmente a través de la consola, tenga en cuenta lo siguiente:
-
Si tiene previsto obtener acceso a la tabla desde Amazon Athena, proporcione un nombre únicamente con caracteres alfanuméricos y guiones bajos. Para obtener más información, consulte Nombres de Athena.
-
La ubicación de sus datos de origen debe ser una ruta de Amazon S3.
-
El formato de datos de los datos debe coincidir con uno de los formatos que aparecen en el asistente. La clasificación correspondiente, SerDe, y otras propiedades de tabla se rellenan automáticamente según el formato elegido. Puede definir tablas con los siguientes formatos:
- Avro
-
Formato binario JSON Apache Avro.
- CSV
-
Valores separados por caracteres. También puede especificar el delimitador de coma, barra vertical, punto y coma, tabulador o Ctrl-A.
- JSON
-
JavaScript Object Notation, notación de objetos de JavaScript.
- XML
-
Formato de lenguaje de marcado extensible. Especifique la etiqueta XML que define una fila en los datos. Las columnas se definen dentro de etiquetas de fila.
- Parquet
-
Almacenamiento en columnas de Apache Parquet.
- ORC
-
Formato archivo Optimized Row Columnar (ORC). Formato diseñado para almacenar de forma eficiente los datos de Hive.
-
Puede definir una clave de partición para la tabla.
-
Actualmente, las tablas con particiones que crea con la consola no se pueden usar en los trabajos de ETL.
Atributos de tabla
A continuación se muestran algunos atributos importantes de su tabla:
- Nombre
-
El nombre se determina al crearse la tabla y no puede cambiarlo. Puede hacer referencia a un nombre de tabla en muchas operaciones de AWS Glue.
- Base de datos
-
El objeto contenedor donde reside su tabla. Este objeto contiene una organización de sus tablas que existe en el AWS Glue Data Catalog y puede diferir de una organización en su almacén de datos. Al eliminar una tabla, todas las tablas incluidas en la base de datos también se eliminan del Data Catalog.
- Descripción
-
Descripción de la tabla. Puede escribir una descripción para ayudarle a entender el contenido de la tabla.
- Formato de tabla
-
Especifique la creación de una tabla estándar de AWS Glue o de una tabla en formato Apache Iceberg.
El Catálogo de datos proporciona las siguientes opciones de optimización de tablas para administrar el almacenamiento de las tablas y mejorar el rendimiento de las consultas para las tablas de Iceberg.
-
Compactación: los archivos de datos se combinan y se reescriben para eliminar los datos obsoletos y consolidar los datos fragmentados en archivos más grandes y eficientes.
Retención de instantáneas: las instantáneas son versiones con fecha y hora de una tabla de Iceberg. Las configuraciones de retención de instantáneas permiten a los clientes determinar cuánto tiempo se deben retener las instantáneas y cuántas instantáneas retener. La configuración de un optimizador de retención de instantáneas puede ayudar a administrar la sobrecarga de almacenamiento al eliminar las instantáneas antiguas e innecesarias y los archivos subyacentes asociados.
Eliminación de archivos huérfanos: los archivos huérfanos son archivos a los que los metadatos de la tabla de Iceberg ya no hacen referencia. Con el tiempo, estos archivos se pueden acumular, sobre todo después de operaciones como la eliminación de tablas o los errores en los trabajos de ETL. Habilitar la eliminación de archivos huérfanos permite a AWS Glue identificar y eliminar periódicamente estos archivos innecesarios y así liberar espacio de almacenamiento.
Para obtener más información, consulte Optimización de las tablas de Iceberg.
-
- Configuración de optimización
Puede utilizar la configuración predeterminada o personalizar la configuración para activar los optimizadores de tablas.
- Rol de IAM
Para ejecutar los optimizadores de tablas, el servicio asume un rol de IAM en su nombre. Puede elegir un rol de IAM mediante el menú desplegable. Asegúrese de que el rol tenga los permisos necesarios para habilitar la compactación.
Para obtener más información sobre los permisos necesarios para este rol de IAM, consulte Requisitos previos para la optimización de tablas .
- Ubicación
-
El señalizador a la ubicación de los datos en un almacén de datos que representa esta definición de tabla.
- Clasificación
-
Un valor de categorización proporcionado cuando se creó la tabla. Normalmente, este se escribe al ejecutarse un rastreador y especifica el formato de los datos de origen.
- Última actualización
-
La hora y la fecha (UTC) en que se actualizó esta tabla en el Data Catalog.
- Fecha agregada
-
La hora y la fecha (UTC) en que se agregó esta tabla al Data Catalog.
- Obsoleto
-
Si AWS Glue descubre que una tabla en el Data Catalog ya no existe en su almacén de datos original, marca la tabla como obsoleta en el catálogo de datos. Si ejecuta un flujo de trabajo que hace referencia a una tabla obsoleta, podría producirse un error en el flujo de trabajo. Edite trabajos que hagan referencia a tablas obsoletas para quitarlas como orígenes y destinos. Recomendamos que elimine las tablas obsoletas cuando ya no sean necesarias.
- Connection
-
Si AWS Glue requiere una conexión a su almacén de datos, el nombre de la conexión se asocia a la tabla.
Visualización y administración de los detalles de la tabla
Para ver los detalles de una tabla existente, elija el nombre de tabla de la lista y, a continuación, elija Acción, Ver detalles.
Entre los detalles de la tabla se incluyen propiedades de su tabla y su esquema. Esta vista muestra el esquema de la tabla, incluidos los nombres de columna en el orden definido para la tabla, los tipos de datos y las columnas con clave para las particiones. Si una columna es un tipo complejo, puede elegir Ver propiedades para mostrar detalles de la estructura de ese campo, como se muestra en el siguiente ejemplo:
{ "StorageDescriptor": { "cols": { "FieldSchema": [ { "name": "primary-1", "type": "CHAR", "comment": "" }, { "name": "second ", "type": "STRING", "comment": "" } ] }, "location": "s3://aws-logs-111122223333-us-east-1", "inputFormat": "", "outputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat", "compressed": "false", "numBuckets": "0", "SerDeInfo": { "name": "", "serializationLib": "org.apache.hadoop.hive.serde2.OpenCSVSerde", "parameters": { "separatorChar": "|" } }, "bucketCols": [], "sortCols": [], "parameters": {}, "SkewedInfo": {}, "storedAsSubDirectories": "false" }, "parameters": { "classification": "csv" } }
Para obtener más información acerca de las propiedades de una tabla, como StorageDescriptor, consulte Estructura StorageDescriptor.
Para cambiar el esquema de una tabla, elija Editar esquema para agregar y quitar columnas, cambiar nombres de columna y cambiar tipos de datos.
Para comparar diferentes versiones de una tabla, incluido su esquema, elija Comparar versiones para ver una comparación paralela de dos versiones del esquema para una tabla. Para obtener más información, consulte Comparación de las versiones del esquema de la tabla .
Para mostrar los archivos que componen una partición de Amazon S3, elija Ver partición. Para las tablas de Amazon S3, la columna Clave muestra las claves de partición que se usan para particionar la tabla en el almacén de datos de origen. La creación de particiones es una forma de dividir una tabla en partes relacionadas según los valores de una columna de clave, tales como fecha, ubicación o departamento. Para obtener más información acerca de las particiones, busque en Internet información acerca de la "creación de particiones Hive".
nota
Para obtener instrucciones paso a paso para ver los detalles de una tabla, consulte el tutorial Explorar tabla en la consola.
Comparación de las versiones del esquema de la tabla
Cuando compara dos versiones de esquemas de tablas, puede comparar los cambios en las filas anidadas al expandir y contraer las filas anidadas, puede comparar los esquemas de dos versiones y ver las propiedades de las tablas lado a lado.
Comparación de versiones
-
En la consola de AWS Glue, seleccione Tablas, Acciones y, a continuación, elija Comparar versiones.
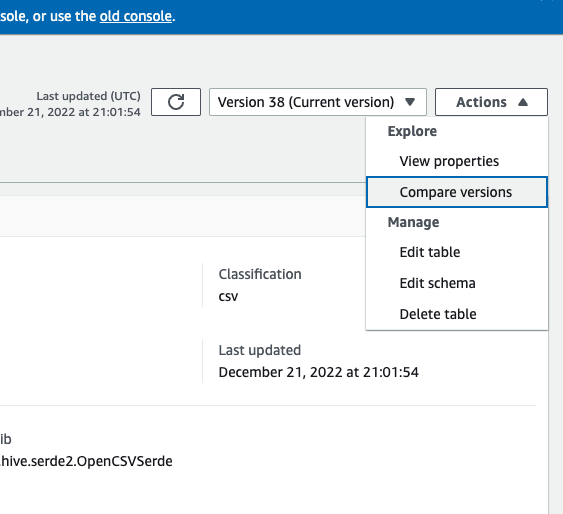
-
Elija una versión para comparar mediante el menú desplegable de versiones. Cuando compare esquemas, la pestaña Esquema aparece resaltada en naranja.
-
Cuando compare tablas entre dos versiones, los esquemas de las tablas se muestran en la parte izquierda y derecha de la pantalla. Esto le permite visualizar los cambios al comparar los campos de Nombre de columna, tipo de datos, clave y comentario uno al lado del otro. Cuando se produce un cambio, aparece un icono de color que muestra el tipo de cambio realizado.
-
Eliminada: se muestra un icono rojo que indica dónde se quitó la columna de una versión anterior del esquema de la tabla.
-
Editada o movida: se muestra un icono azul que indica dónde se modificó o movió la columna en una versión más reciente del esquema de la tabla.
-
Agregado: se muestra un icono verde que indica dónde se agregó una columna a una versión más reciente del esquema de la tabla.
-
Cambios anidados: se muestra un icono amarillo que indica dónde contiene cambios la columna anidada. Elija la columna para expandirla y ver las columnas que se eliminaron, editaron, movieron o agregaron.
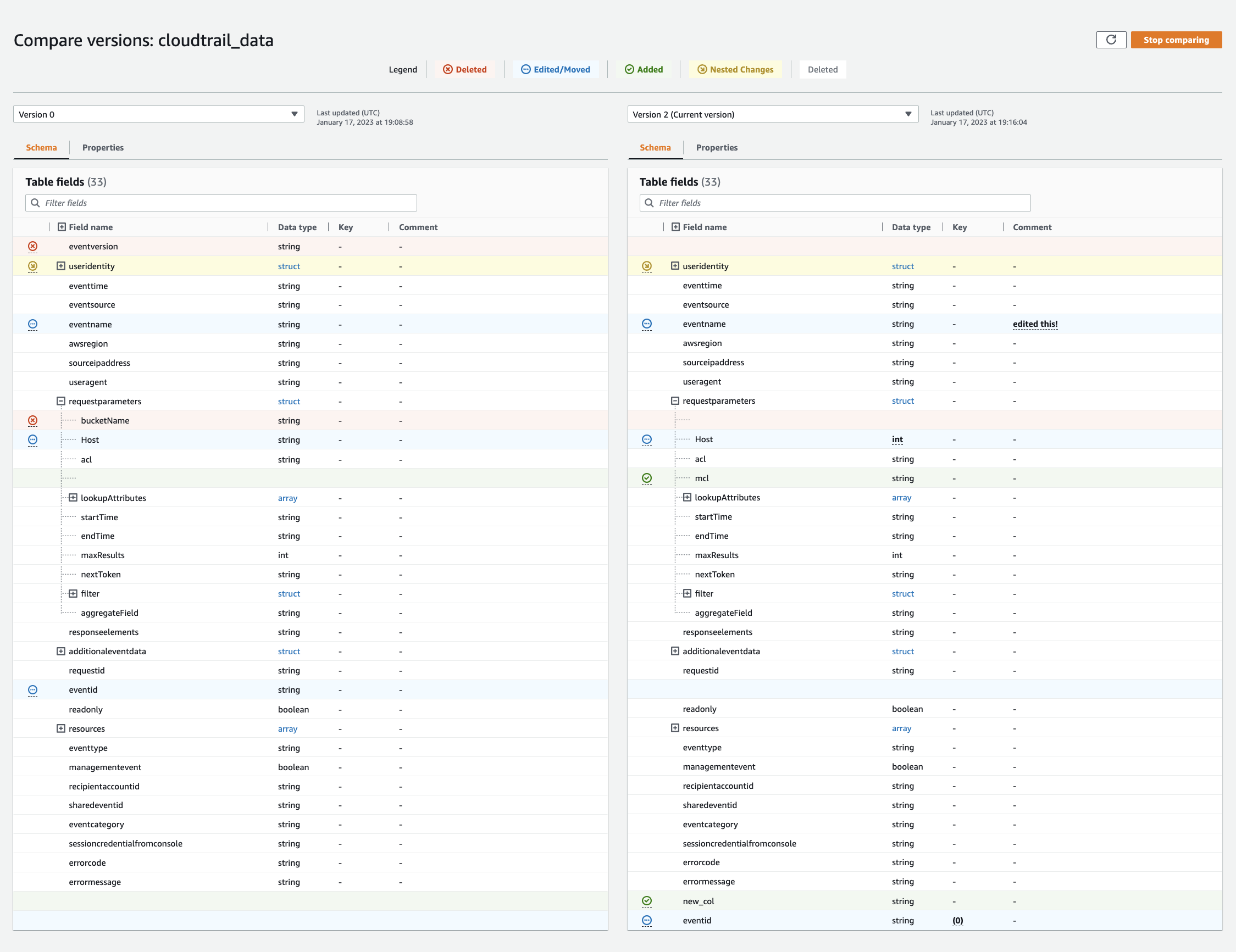
-
-
Utilice la barra de búsqueda de campos filtrados para mostrar los campos en función de los caracteres que introduzca aquí. Si introduce un nombre de columna en cualquier versión de la tabla, los campos filtrados se muestran en ambas versiones de la tabla para mostrarle dónde se produjeron los cambios.
-
Para comparar propiedades, elija la pestaña de Propiedades.
-
Para detener la comparación de versiones, elija Detener comparación para volver a la lista de tablas.
Actualización de tablas del Catálogo de datos creadas de forma manual mediante rastreadores
Es posible que desee crear tablas de AWS Glue Data Catalog de forma manual y, a continuación, mantenerlas actualizadas con rastreadores de AWS Glue. Los rastreadores que se ejecutan en una programación pueden añadir nuevas particiones y actualizar las tablas con cualquier cambio de esquema. Esto también se aplica a tablas migradas desde un metaalmacén de Apache Hive.
Para ello, cuando defina un rastreador, en lugar de especificar un almacén de datos o más como origen de un rastreador, especifique una o más tablas existentes del Catálogo de datos. El rastreador rastrea los almacenes de datos especificados por las tablas del catálogo. En este caso, no se crean tablas nuevas. En su lugar, las tablas que usted crea de forma manual se actualizan.
A continuación se muestran otros motivos por los que podría desear crear tablas de catálogos de forma manual y especificar tablas de catálogos como la fuente del rastreador:
-
Desea elegir el nombre de la tabla de catálogo y no confía en el algoritmo de denominación de tablas de catálogos.
-
Desea evitar que se creen tablas nuevas en caso de que los archivos que tengan un formato que podría interrumpir la detección de particiones se guarden de forma errónea en la ruta de la fuente de datos.
Para obtener más información, consulte Paso 2: elegir orígenes de datos y clasificadores.
Propiedades de la tabla del catálogo de datos
Las propiedades o los parámetros de la tabla, tal como se les conoce en la AWS CLI, son cadenas de valores y claves no validadas. Puede establecer sus propias propiedades en la tabla para permitir usos del catálogo de datos fuera de AWS Glue. Otros servicios que utilizan el Catálogo de datos también pueden hacerlo. AWS Glue establece algunas propiedades de la tabla al ejecutar trabajos o rastreadores. A menos que se describa lo contrario, estas propiedades son para uso interno, no se admite que sigan existiendo en su forma actual ni el comportamiento del producto si estas propiedades se cambian manualmente.
Para obtener más información sobre las propiedades de tabla establecidas por los rastreadores de AWS Glue, consulte Parámetros establecidos en las tablas del catálogo de datos por el rastreador.
