Puede usar un Rastreador de AWS Glue para completar el AWS Glue Data Catalog con bases de datos y tablas. Este es el método principal usado por la mayoría de los usuarios de AWS Glue. Un rastreador puede rastrear varios almacenes de datos en una única ejecución. Cuando finaliza, el rastreador crea o actualiza una o varias tablas del Catálogo de datos. Los trabajos de extracción, transformación y carga (ETL) que define en AWS Glue usan estas tablas del Catálogo de datos como orígenes y destinos. El trabajo de ETL lee y escribe en los almacenes de datos que se especifican en las tablas de origen y destino del Catálogo de datos.
Flujo de trabajo
En el siguiente diagrama de flujo de flujo de trabajo se muestra cómo los rastreadores de AWS Glue interactúan con almacenes de datos y otros elementos para rellenar el Catálogo de datos.
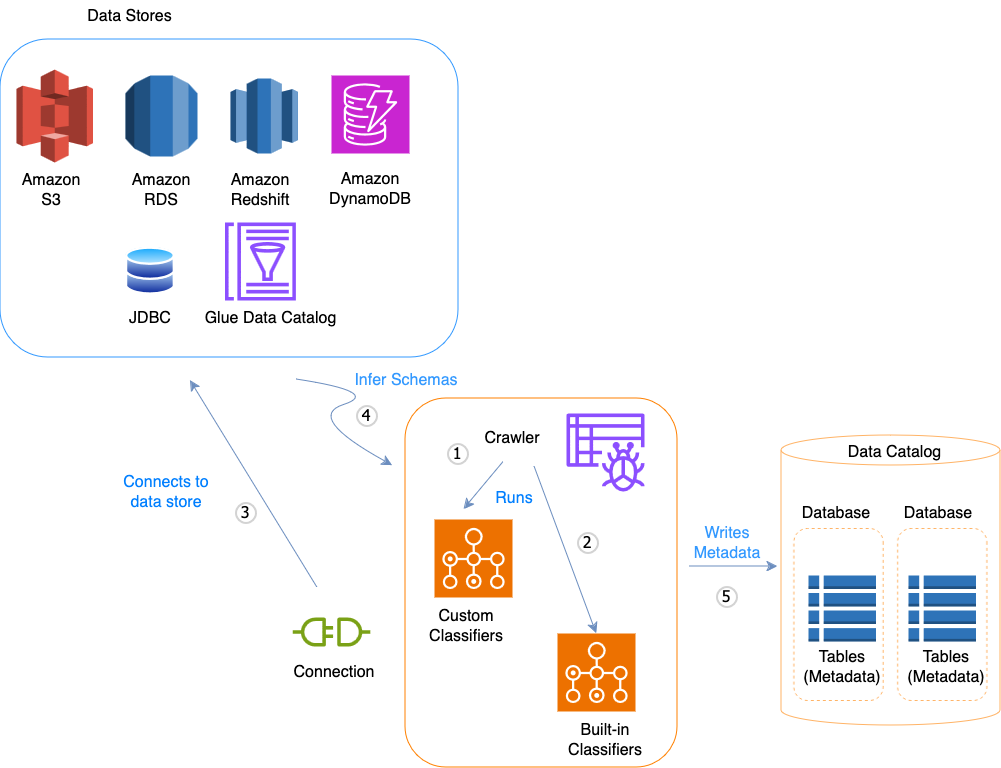
Este es el flujo de flujo de trabajo general de rellenado de AWS Glue Data Catalog por parte de un rastreador:
-
Un rastreador ejecuta cualquier clasificador personalizado que elija para inferir el formato y el esquema de sus datos. Debe proporcionar el código para clasificadores personalizados, que se ejecutan en el orden especificado.
El primer clasificador personalizado en reconocer correctamente la estructura de sus datos se usa para crear un esquema. Los clasificadores personalizados que aparecen más abajo en la lista se omiten.
-
Si no coincide ningún clasificador con el esquema de sus datos, los clasificadores integrados intentarán reconocer el esquema de sus datos. Un ejemplo de un clasificador integrado es uno que reconoce JSON.
-
El rastreador se conecta al almacén de datos. Algunos almacenes de datos requieren propiedades de conexión para el acceso del rastreador.
-
El esquema inferido se crea para sus datos.
-
El rastreador escribe los metadatos en el Catálogo de datos. Una definición de tabla contiene metadatos acerca de los datos de su almacén de datos. La tabla se escribe en una base de datos, que es un contenedor de tablas en el Catálogo de datos. Entre los atributos de una tabla se incluye la clasificación, que es una etiqueta creada por el clasificador que determinó el esquema de tabla.
Temas
Funcionamiento de los rastreadores
Cuando se ejecuta un rastreador, realiza las siguientes acciones para interrogar a un almacén de datos:
-
Clasifica los datos para determinar el formato, el esquema y las propiedades asociadas de los datos sin procesar: puede configurar los resultados de clasificación mediante la creación de un clasificador personalizado.
-
Agrupa los datos en tablas o particiones: los datos se agrupan en función de la heurística de rastreador.
-
Escribe los metadatos en el Catálogo de datos: puede configurar cómo el rastreador agrega, actualiza y elimina tablas y particiones.
Al definir un rastreador, puede elegir uno o varios clasificadores que evalúen el formato de sus datos para inferir un esquema. Al ejecutarse el rastreador, el primer clasificador de su lista en reconocer correctamente su almacén de datos se usa para crear un esquema para su tabla. Puede usar clasificadores integrados o definir los suyos propios. Puede definir sus clasificadores personalizados en una operación independiente, antes de definir los rastreadores. AWS Glue proporciona clasificadores integrados para inferir esquemas a partir de archivos comunes con formatos entre los que se incluyen JSON, CSV y Apache Avro. Para ver la lista actual de clasificadores integrados en AWS Glue, consulte Clasificadores integrados.
Las tablas de metadatos que crea un rastreador se incluyen en una base de datos al definir un rastreador. Si su rastreador no especifica una base de datos, sus tablas se colocan en la base de datos predeterminada. Además, cada tabla tiene una columna de clasificación que rellena el clasificador que reconoció correctamente el almacén de datos en primer lugar.
Si se comprime el archivo que se rastrea, el rastreador debe descargarlo para procesarlo. Cuando un rastreador se ejecuta, interroga los archivos para determinar su formato y tipo de compresión, y escribe estas propiedades en el Catálogo de datos. Algunos formatos de archivo (por ejemplo, Apache Parquet) le permiten comprimir partes del archivo a medida que se escribe. Para estos archivos, los datos comprimidos son un componente interno del archivo y AWS Glue no rellena la propiedad compressionType cuando escribe tablas en el Catálogo de datos. Por el contrario, si un archivo completo se comprime mediante un algoritmo de compresión (por ejemplo, gzip), la propiedad compressionType se rellena cuando las tablas se escriben en el Catálogo de datos.
El rastreador genera los nombres para las tablas que crea. Los nombres de las tablas que se almacenan en el AWS Glue Data Catalog siguen estas reglas:
-
Solo se permiten caracteres alfanuméricos y guiones bajos (
_). -
Ningún prefijo personalizado puede tener más de 64 caracteres.
-
La longitud máxima del nombre no puede ser superior a 128 caracteres. El rastreador trunca nombres generados para que quepan en el límite.
-
Si se encuentran nombres de tabla duplicados, el rastreador añade un sufijo de cadena hash al nombre.
Si su rastreador se ejecuta más de una vez, quizás en una programación, busca archivos o tablas nuevos o cambiados en su almacén de datos. La salida del rastreador incluye nuevas tablas y particiones encontradas desde una ejecución anterior.
¿Cómo determina un rastreador cuándo crear particiones?
Cuando un rastreador de AWS Glue escanea el almacén de datos de Amazon S3 y detecta varias carpetas en un bucket, determina la raíz de una tabla en la estructura de carpetas y qué carpetas son particiones de una tabla. El nombre de la tabla se basa en el prefijo de Amazon S3 o el nombre de carpeta. Proporcione una ruta de inclusión que apunte al nivel de carpeta que se rastreará. Cuando la mayoría de los esquemas en el nivel de carpeta son similares, el rastreador crea particiones de una tabla en vez de tablas independientes. Para influir en el rastreador con el fin de que cree tablas independientes, agregue la carpeta raíz de cada tabla como un almacén de datos independiente al definir el rastreador.
Por ejemplo, considere la siguiente estructura de carpetas de Amazon S3.

Las rutas de acceso a las cuatro carpetas de nivel inferior son las siguientes:
S3://sales/year=2019/month=Jan/day=1
S3://sales/year=2019/month=Jan/day=2
S3://sales/year=2019/month=Feb/day=1
S3://sales/year=2019/month=Feb/day=2Supongamos que el destino del rastreador está establecido en Sales y que todos los archivos en la carpeta day=n tienen el mismo formato (por ejemplo, JSON, no cifrado) y tienen los mismos esquemas o muy similares. El rastreador creará una sola tabla con cuatro particiones, con claves de partición year, month y day.
Por ejemplo, considere la siguiente estructura de Amazon S3:
s3://bucket01/folder1/table1/partition1/file.txt
s3://bucket01/folder1/table1/partition2/file.txt
s3://bucket01/folder1/table1/partition3/file.txt
s3://bucket01/folder1/table2/partition4/file.txt
s3://bucket01/folder1/table2/partition5/file.txt
Si los esquemas para los archivos en table1 y table2 son similares, y se define un almacén de datos individual en el rastreador con Include path (Ruta de inclusión) s3://bucket01/folder1/, el rastreador crea una sola tabla con dos columnas de claves de partición. La primera columna de clave de partición contiene table1 y table2, y la segunda columna de clave de partición contiene partition1 a partition3 para la partición de la table1, y partition4 y partition5 para la partición de la table2. Para crear dos tablas independientes, defina el rastreador con dos almacenes de datos. En este ejemplo, defina la primera ruta de inclusión como s3://bucket01/folder1/table1/ y la segunda como s3://bucket01/folder1/table2.
nota
En Amazon Athena, cada tabla corresponde a un prefijo de Amazon S3 con todos los objetos que contiene. Si los objetos tienen diferentes esquemas, Athena no reconoce objetos distintos en el mismo prefijo como tablas independientes. Esto puede suceder si un rastreador crea varias tablas a partir del mismo prefijo de Amazon S3. Esto podría dar lugar a consultas en Athena que no devuelvan resultados. Para que Athena reconozca y consulte las tablas correctamente, cree el rastreador con una Include path (Ruta de inclusión)diferente para cada esquema de tabla en la estructura de carpetas de Amazon S3. Para obtener más información, consulte las Mejores prácticas de uso de Athena con AWS Glue y este artículo del Centro de conocimientos de AWS
