Puede crear trabajos de extracción, transformación y carga (ETL) de streaming que se ejecuten continuamente, consuman datos de orígenes de streaming como Amazon Kinesis Data Streams, Apache Kafka y Amazon Managed Streaming for Apache Kafka (Amazon MSK). Los trabajos limpian y transforman los datos y, a continuación, cargan los resultados en los lagos de datos de Amazon S3 o en los almacenes de datos JDBC.
Además, puede generar datos para los flujos de Amazon Kinesis Data Streams. Esta característica solo está disponible al escribir scripts de AWS Glue. Para obtener más información, consulte Conexión de Kinesis.
De forma predeterminada, AWS Glue procesa y escribe datos en periodos de 100 segundos. Esto permite que los datos se procesen de forma eficiente y permite que las agregaciones se realicen en los datos que lleguen más tarde de lo previsto. Puede modificar este tamaño de ventana para aumentar la puntualidad o la precisión de la agregación. Los trabajos de streaming de AWS Glue utilizan puntos de control en lugar de marcadores de trabajo para rastrear los datos leídos.
nota
AWS Glue factura por hora para trabajos de ETL de streaming mientras se están ejecutando.
Este video analiza los desafíos de costos de ETL de streaming y las funciones de ahorro de costos en AWS Glue.
La creación de un trabajo ETL de streaming consta de los siguientes pasos:
-
Para un origen de streaming de Apache Kafka, cree una conexión de AWS Glue al origen de Kafka o al clúster de Amazon MSK.
-
Cree manualmente una tabla del Catálogo de datos para el origen de streaming.
-
Cree un trabajo ETL para el origen de datos de streaming. Defina propiedades de trabajo específicas de streaming y proporcione su propio script o también puede modificar el script generado.
Para obtener más información, consulte ETL de streaming en AWS Glue.
Al crear un trabajo de ETL de streaming para Amazon Kinesis Data Streams, no es necesario crear una conexión de AWS Glue. Sin embargo, si hay una conexión asociada al trabajo de ETL de streaming de AWS Glue que tenga Kinesis Data Streams como origen, se requiere un punto de enlace de la nube privada virtual (VPC) para Kinesis. Para obtener más información, consulte Creación de un punto de conexión de interfaz en la Guía del usuario de Amazon VPC. Al especificar un flujo de Amazon Kinesis Data Streams en otra cuenta, debe configurar los roles y las políticas para permitir el acceso entre cuentas. Para obtener más información, consulte Ejemplo: leer desde un flujo de Kinesis en una cuenta diferente.
Los trabajos de ETL de streaming en AWS Glue pueden detectar automáticamente datos comprimidos, descomprimir de forma transparente los datos de streaming, realizar las transformaciones habituales en el origen de entrada y cargarlos en el almacén de salida.
AWS Glue admite la descompresión automática para los siguientes tipos de compresión dado el formato de entrada:
| Tipo de compresión | Archivo Avro | Datos de Avro | JSON | CSV | Grok |
|---|---|---|---|---|---|
| BZIP2 | Sí | Sí | Sí | Sí | Sí |
| GZIP | No | Sí | Sí | Sí | Sí |
| SNAPPY | Sí (Snappy sin formato) | Sí (con encuadre de Snappy) | Sí (con encuadre de Snappy) | Sí (con encuadre de Snappy) | Sí (con encuadre de Snappy) |
| XZ | Sí | Sí | Sí | Sí | Sí |
| ZSTD | Sí | No | No | No | No |
| DEFLATE | Sí | Sí | Sí | Sí | Sí |
Temas
Creación de una conexión de AWS Glue para un flujo de datos Apache Kafka
Para leer en una transmisión de Apache Kafka, debe crear una conexión de AWS Glue.
Para crear una conexión de AWS Glue para un origen de Kafka (consola)
Abra la consola de AWS Glue en https://console.aws.amazon.com/glue/
. -
En el panel de navegación, en Data catalog (Catálogo de datos), elija Connections (Conexiones).
-
Elija Agregar conexión y, en la página Configurar las propiedades de la conexión escriba un nombre de conexión.
nota
Para obtener más información acerca de cómo especificar propiedades de conexión, consulte Propiedades de conexión de AWS Glue.
-
En Tipo de conexión, elija Kafka.
-
Para Kafka bootstrap servers URLs (URL de servidores de arranque Kafka), ingrese el host y el número de puerto de los agentes de arranque para su clúster de Amazon MSK o Apache Kafka. Utilice sólo los puntos de enlace de Transport Layer Security (TLS) para establecer la conexión inicial con el clúster de Kafka. No se admiten puntos de enlace de texto no cifrado.
A continuación se ofrece una lista de pares de nombre de host y número de puerto para un clúster de Amazon MSK a modo de ejemplo.
myserver1.kafka.us-east-1.amazonaws.com:9094,myserver2.kafka.us-east-1.amazonaws.com:9094, myserver3.kafka.us-east-1.amazonaws.com:9094Para obtener más información sobre cómo obtener la información del agente de arranque, consulte Obtener los agentes de arranque para un clúster de Amazon MSK en la Guía para desarrolladores de Amazon Managed Streaming for Apache Kafka.
-
Si desea una conexión segura al origen de datos de Kafka, seleccione Require SSL connection (Solicitar conexión SSL), y para Kafka private CA certificate location (Ubicación del certificado de CA privado de Kafka), ingrese una ruta válida de Amazon S3 a un certificado SSL personalizado.
Para una conexión SSL a Kafka autoadministrado, el certificado personalizado es obligatorio. Es opcional para Amazon MSK.
Para obtener más información sobre cómo especificar un certificado personalizado para Kafka, consulte Propiedades de las conexiones SSL de AWS Glue.
-
Use AWS Glue Studio o CLI AWS para especificar un método de autenticación de cliente Kafka. Para obtener acceso a AWS Glue Studio, seleccione AWS Glue en el menú ETL en el panel de navegación izquierdo.
Para obtener más información acerca de los métodos de autenticación de cliente Kafka, consulte Propiedades de conexión de AWS Glue Kafka para autenticación de clientes .
-
Si lo desea, escriba una descripción y, a continuación, elija Next (Siguiente).
-
Para un clúster de Amazon MSK, especifique la nube virtual privada (VPC), su subred y el grupo de seguridad. La información de la VPC es opcional para Kafka autoadministrado.
-
Elija Next (Siguiente) para revisar todas las propiedades de conexión y, a continuación, elija Finish (Finalizar).
Para obtener más información acerca de las conexiones de AWS Glue, consulte Conexión a datos.
Propiedades de conexión de AWS Glue Kafka para autenticación de clientes
- Autenticación SASL/GSSAPI (Kerberos)
-
La elección de este método de autenticación le permitirá especificar propiedades de Kerberos.
- Keytab de Kerberos
-
Seleccione la ubicación del archivo keytab. Una keytab almacena claves a largo plazo para uno o varias entidades principales. Para obtener más información, consulte MIT Kerberos Documentation: Keytab
(Documentación de MIT Kerberos: Keytab). - Archivo Kerberos krb5.conf
-
Seleccione el archivo krb5.conf. Contiene el dominio predeterminado (una red lógica, similar a un dominio, que define un grupo de sistemas bajo el mismo KDC) y la ubicación del servidor KDC. Para obtener más información, consulte MIT Kerberos Documentation: krb5.conf
(Documentación de MIT Kerberos: krb5.conf). - Nombre principal y nombre de servicio de Kerberos
-
Ingrese el nombre principal y el de servicio de Kerberos. Para obtener más información, consulte la documentación de Kerberos de MIT: principal de Kerberos
. - Autenticación SASL/SCRAM-SHA-512
-
La elección de este método de autenticación le permitirá especificar credenciales de autenticación.
- AWS Secrets Manager
-
Busque el token en el cuadro de búsqueda mediante el nombre o ARN.
- Nombre de usuario y contraseña del proveedor directamente
-
Busque el token en el cuadro de búsqueda mediante el nombre o ARN.
- Autenticación SSL del cliente
-
La elección de este método de autenticación le permite seleccionar la ubicación del almacén de claves del cliente Kafka navegando por Amazon S3. Opcionalmente, puede ingresar la contraseña del almacén de claves del cliente Kafka y la contraseña de clave de cliente Kafka.
- Autenticación de IAM
-
Este método de autenticación no requiere especificaciones adicionales y solo se aplica cuando la fuente de streaming es Kafka para MSK.
- Autenticación de SASL/PLAIN
-
Al elegir este método de autenticación, puede especificar las credenciales de autenticación.
Creación de una tabla del Catálogo de datos para un origen de streaming
Es posible crear de forma manual una tabla del Catálogo de datos que especifique las propiedades del flujo de datos de origen, incluido el esquema de datos, para un origen de streaming. Esta tabla se utiliza como origen de datos para el trabajo ETL de streaming.
Si no conoce el esquema de los datos en el flujo de datos de origen, puede crear la tabla sin un esquema. A continuación, cuando cree el trabajo de ETL de streaming, puede habilitar la función detección de esquema de AWS Glue. AWS Glue determinará el esquema a partir de los datos de streaming.
Utilice la consola de AWS Glue
nota
No puede usar la consola de AWS Lake Formation para crear la tabla; debe usar la consola de AWS Glue.
Tenga en cuenta también la siguiente información para los orígenes de streaming en formato Avro o para los datos de registro a los que puede aplicar patrones Grok.
Origen de datos de Kinesis
Al crear la tabla, configure las siguientes propiedades de ETL de streaming (consola).
- Tipo de origen
-
Kinesis
- Para un origen de Kinesis en la misma cuenta:
-
- Región
-
La región de AWS en la que reside el servicio Amazon Kinesis Data Streams. La región y el nombre del flujo de Kinesis se traducen juntos a un ARN de flujo.
Ejemplo: https://kinesis.us-east-1.amazonaws.com
- Nombre de flujo de Kinesis
-
Nombre de la transmisión, tal como se describe en Creación de una transmisión en la Guía para desarrolladores de Amazon Kinesis Data Streams.
- Para un origen de Kinesis en otra cuenta, consulte este ejemplo para configurar los roles y políticas que permitan el acceso entre cuentas. Configure estas opciones:
-
- ARN de flujo
-
El ARN del flujo de datos de Kinesis con el que está registrado el consumidor. Para obtener más información, consulte Nombres de recursos de Amazon (ARNs) y espacios de nombres de servicios de AWS en la Referencia general de AWS.
- ARN de rol asumido
-
El nombre de recurso de Amazon (ARN) del rol que se asignará.
- Nombre de la sesión (opcional)
-
Un identificador para la sesión del rol asumido.
Utilice el nombre de la sesión del rol para identificar de forma única una sesión cuando el mismo rol es asumido por diferentes entidades o por diferentes razones. En escenarios entre cuentas, el nombre de la sesión del rol es visible para la cuenta que es titular del rol. Esta cuenta podrá registrar el rol. El nombre de la sesión del rol también se utiliza en el ARN de la entidad principal del rol asumido. Esto significa que las solicitudes posteriores de API entre cuentas que utilizan las credenciales de seguridad temporales expondrán el nombre de la sesión del rol a la cuenta externa en sus registros de AWS CloudTrail.
Para configurar las propiedades de ETL de streaming para Amazon Kinesis Data Streams (API de AWS Glue o AWS CLI)
-
Para configurar las propiedades de ETL de streaming para un origen de Kinesis en la misma cuenta, especifique los parámetros
streamNameyendpointUrlen la estructuraStorageDescriptorde la operación de la APICreateTableo el comando de la CLIcreate_table."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamName": "sample-stream", "endpointUrl": "https://kinesis.us-east-1.amazonaws.com" } ... }O bien, especifique
streamARN."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream" } ... } -
Para configurar las propiedades de ETL de streaming para un origen de Kinesis en otra cuenta, especifique los parámetros
streamARN,awsSTSRoleARNyawsSTSSessionName(opcional) en la estructuraStorageDescriptoren la operación de la APICreateTableo el comando de la CLIcreate_table."StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream", "awsSTSRoleARN": "arn:aws:iam::123456789:role/sample-assume-role-arn", "awsSTSSessionName": "optional-session" } ... }
Origen de datos de Kafka
Al crear la tabla, configure las siguientes propiedades de ETL de streaming (consola).
- Tipo de origen
-
Kafka
- Para un origen de Kafka:
-
- Nombre del tema
-
Nombre del tema como se especifica en Kafka.
- Connection
-
Una conexión de AWS Glue que hace referencia a un origen de Kafka, como se describe en Creación de una conexión de AWS Glue para un flujo de datos Apache Kafka.
Origen de tablas de AWS Glue Schema Registry
A fin de utilizar AWS Glue Schema Registry para trabajos de streaming, siga las instrucciones de Caso de uso: AWS Glue Data Catalog para crear o actualizar una tabla de Schema Registry.
Actualmente, el streaming de AWS Glue solo soporta el formato Avro de Glue Schema Registry con inferencia de esquema establecida en false.
Notas y restricciones para orígenes de streaming de Avro
Las siguientes notas y restricciones corresponden a los orígenes de streaming en formato Avro:
-
Cuando se activa la detección de esquemas, el esquema de Avro debe incluirse en la carga. Cuando se desactiva, la carga debe contener solo datos.
-
Algunos tipos de datos de Avro no se admiten en marcos dinámicos. No se pueden especificar estos tipos de datos al definir el esquema con la página Define a schema (Definir un esquema) en el asistente de creación de tabla en la consola de AWS Glue. Durante la detección de esquemas, los tipos no soportados en el esquema Avro se convierten en tipos soportados de la siguiente manera:
-
EnumType => StringType -
FixedType => BinaryType -
UnionType => StructType
-
-
Si define el esquema de tabla mediante la página Define a schema (Definir un esquema) en la consola, el tipo de elemento raíz implícito para el esquema es
record. Si desea un tipo de elemento raíz distinto derecord, por ejemplo,arrayormap, no puede especificar el esquema mediante la página Define a schema (Definir un esquema). En su lugar, debe omitir esa página y especificar el esquema como propiedad de tabla o dentro del script de ETL.-
Para especificar el esquema en las propiedades de la tabla, complete el asistente de creación de tabla, edite los detalles de la tabla y agregue un nuevo par clave-valor en Table properties (Propiedades de la tabla). Utilice la clave
avroSchema, e ingrese un objeto JSON de esquema para el valor, tal y como se muestra en la siguiente captura de pantalla.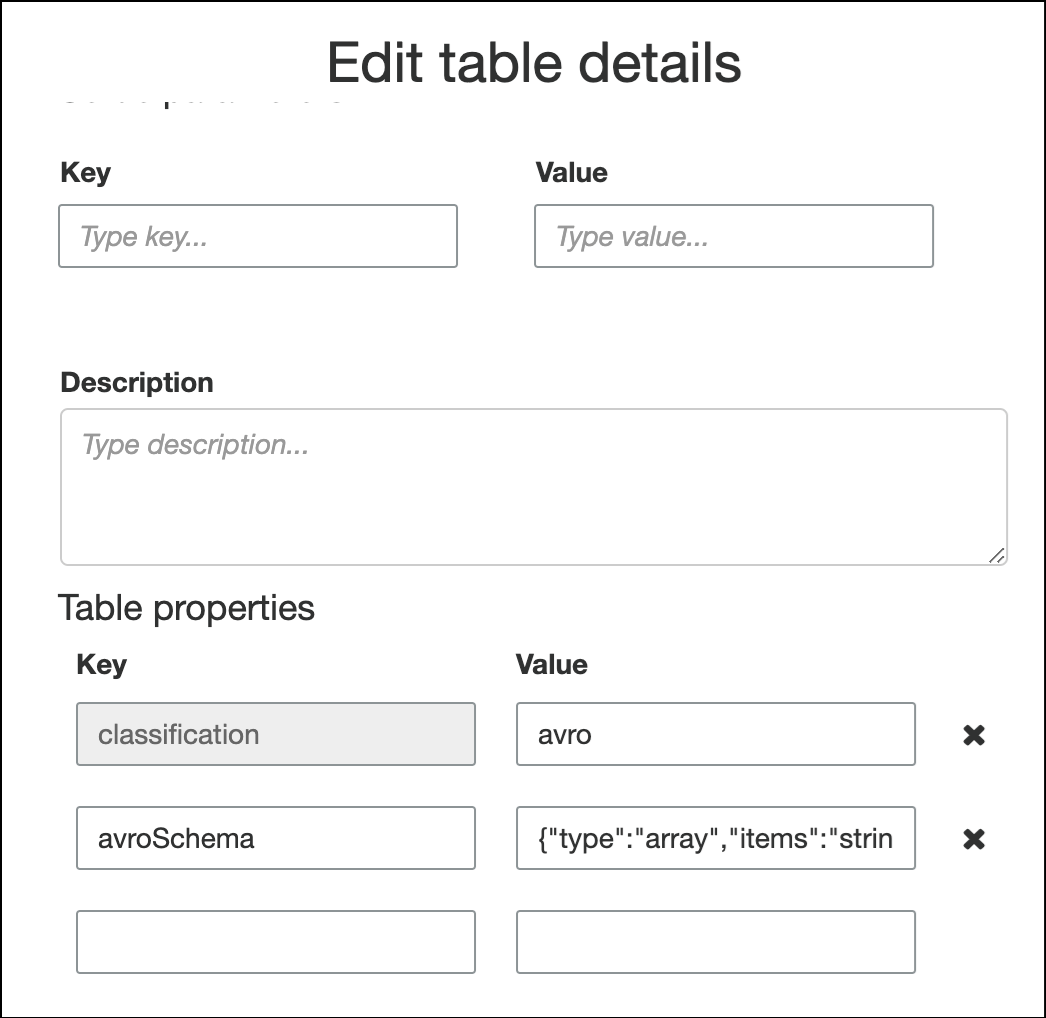
-
Para especificar el esquema en el script de ETL, modifique la instrucción de asignación
datasource0y agregue la claveavroSchemaa la instrucciónadditional_options, tal y como se muestra en los siguientes ejemplos de Python y Scala.SCHEMA_STRING = ‘{"type":"array","items":"string"}’ datasource0 = glueContext.create_data_frame.from_catalog(database = "database", table_name = "table_name", transformation_ctx = "datasource0", additional_options = {"startingPosition": "TRIM_HORIZON", "inferSchema": "false", "avroSchema": SCHEMA_STRING})
-
Aplicación de patrones Grok a orígenes de streaming
Puede crear un trabajo de ETL de streaming para un origen de datos de registro y utilizar patrones Grok para convertir los registros en datos estructurados. Luego, el trabajo de ETL procesa los datos como un origen de datos estructurados. Especifique los patrones Grok que se aplicarán al crear la tabla del Catálogo de datos para el origen de streaming.
Para obtener información acerca de los patrones Grok y los valores de la cadena de patrones personalizados, consulte Escritura de clasificadores personalizados de Grok.
Para agregar patrones Grok a la tabla del Catálogo de datos (consola)
-
Utilice el asistente de creación de tablas y cree la tabla con los parámetros especificados en Creación de una tabla del Catálogo de datos para un origen de streaming. Especifique el formato de datos como Grok, complete el campo Grok pattern (Patrón de Grok) y, opcionalmente, agregue patrones personalizados en Custom patterns (Patrones personalizados) (opcional).
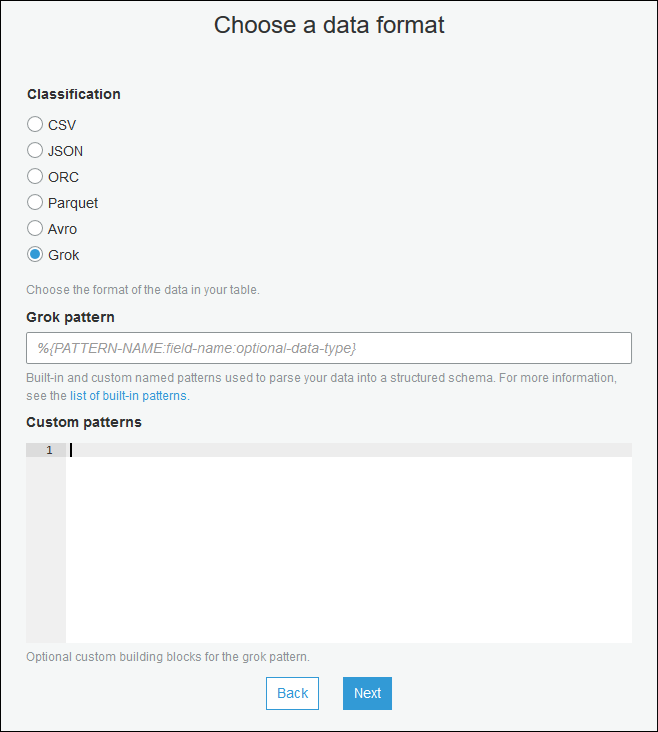
Presione Enter (Intro) después de cada patrón personalizado.
Para agregar patrones grok a la tabla del Catálogo de datos (API de AWS Glue o AWS CLI)
-
Agregue el parámetro
GrokPatterny, opcionalmente, el parámetroCustomPatternsa la operación de APICreateTableo al comando de la CLIcreate_table."Parameters": { ... "grokPattern": "string", "grokCustomPatterns": "string", ... },Indique
grokCustomPatternscomo una cadena y use “\n” como separador entre patrones.El siguiente ejemplo muestra cómo especificar estos parámetros.
"parameters": { ... "grokPattern": "%{USERNAME:username} %{DIGIT:digit:int}", "grokCustomPatterns": "digit \d", ... }
Definición de propiedades de trabajo para un trabajo ETL de streaming
Cuando defina un trabajo de ETL de streaming en la consola de AWS Glue, proporcione las siguientes propiedades específicas de los flujos. Para obtener propiedades de trabajo adicionales, consulte Definición de propiedades de trabajo para trabajos de Spark.
- rol de IAM
-
Especifique el rol AWS Identity and Access Management (IAM) que se usa para dar una autorización a los recursos que se utilizan para ejecutar un trabajo, acceder a orígenes de streaming y acceder a almacenes de datos de destino.
Para acceder a Amazon Kinesis Data Streams, asocie la política
AmazonKinesisFullAccessadministrada por AWS al rol o asocie una política IAM similar que permita un acceso más detallado. Para obtener información sobre políticas de ejemplo, consulte Control del acceso a los recursos de Amazon Kinesis Data Streams mediante IAM.Para obtener más información acerca de los permisos para ejecutar trabajos en AWS Glue, consulte Administración de identidades y accesos para AWS Glue.
- Tipo
-
Elija Spark Streaming.
- Versión de AWS Glue
-
La versión de AWS Glue determina las versiones de Apache Spark y Python o Scala que están disponibles para el trabajo. Elija una selección que especifique la versión de Python o Scala disponible para el trabajo. AWS Glue La versión 2.0 con soporte de Python 3 es la predeterminada para los trabajos de ETL de streaming.
- Periodo de mantenimiento
-
Especifica una ventana en la que se puede reiniciar un trabajo de streaming. Consulte Ventanas de mantenimiento para AWS Glue Streaming.
- Job timeout (Tiempo de espera de flujo de trabajo)
-
Si lo desea, escriba una duración en minutos. El valor predeterminado está en blanco.
Los trabajos de streaming deben tener un valor de tiempo de espera inferior a 7 días o 10 080 minutos.
Si el valor se deja en blanco, el trabajo se reiniciará después de 7 días, si no ha establecido un periodo de mantenimiento. Si ha configurado un periodo de mantenimiento, el trabajo se reiniciará durante el periodo de mantenimiento después de 7 días.
- Origen de datos
-
Elimine la tabla que creó en Creación de una tabla del Catálogo de datos para un origen de streaming.
- Destino de datos
-
Realice una de las siguientes acciones:
-
Elija Crear tablas en el destino de datos y especifique las siguientes propiedades de destino de datos.
- Almacén de datos
-
Seleccione Amazon S3 o JDBC.
- Formato
-
Elija cualquier formato. Todos son compatibles para streaming.
-
Elija Use tables in the data catalog and update your data target (Utilizar tablas en el Catálogo de datos y actualizar el destino de los datos) y elija una tabla para un almacén de datos JDBC.
-
- Definición de esquema de salida
-
Realice una de las siguientes acciones:
-
Seleccione Automatically detect schema of each record (Detectar automáticamente el esquema de cada registro) para habilitar la detección de esquemas. AWS Glue determina el esquema a partir de los datos de streaming.
-
Seleccione Specify output schema for all records (Especificar esquema de salida para todos los registros) para utilizar la transformación de la función de aplicar mapeo a fin de definir el esquema de salida.
-
- Script
-
Si lo desea, proporcione su propio script o modifique el script generado para realizar operaciones compatibles con el motor Apache Spark Structured Streaming. Para obtener información sobre las operaciones disponibles, consulte Operaciones en DataFrames/conjuntos de datos de streaming
.
Notas y restricciones de ETL de streaming
Tenga en cuenta las siguientes notas y restricciones:
-
La descompresión automática para los trabajos de ETL de streaming en AWS Glue solo está disponible para los tipos de compresión admitidos. Tenga también en cuenta lo siguiente:
Con encuadre de Snappy se refiere al formato de encuadre
oficial para Snappy. Deflate es compatible con la versión 3.0 de Glue, no con la versión 2.0.
-
Cuando se utiliza la detección de esquemas, no se pueden realizar combinaciones de datos de streaming.
-
Los trabajos ETL de streaming de AWS Glue no admiten el tipo de datos de la Unión para el Registro de esquemas de AWS Glue con formato Avro.
-
Su script de ETL puede usar las transformaciones incorporadas de AWS Glue y las transformaciones nativas de Apache Spark Structured Streaming. Para obtener más información, consulte Operaciones en DataFrames/conjuntos de datos de streaming
en el sitio web de Apache Spark o Referencia de transformaciones de PySpark de AWS Glue. -
Los trabajos de ETL de streaming de AWS Glue utilizan puntos de comprobación para realizar un seguimiento de los datos que se han leído. Por lo tanto, un trabajo detenido y reiniciado comienza donde lo dejó en la transmisión. Si desea volver a procesar los datos, puede eliminar la carpeta de puntos de control a la que se hace referencia en el script.
-
No se admiten los marcadores de trabajo.
-
Para la función de distribución mejorada de Kinesis Data Streams en un trabajo, consulte Uso de una distribución mejorada en los trabajos de streaming de Kinesis.
-
Si utiliza una tabla del Catálogo de datos creada a partir de AWS Glue Schema Registry, cuando se encuentre disponible una versión de esquema nueva, para reflejar el esquema nuevo, debe realizar lo siguiente:
-
Detenga los trabajos asociados a la tabla.
-
Actualice el esquema de la tabla del Catálogo de datos.
-
Reinicie los trabajos asociados a la tabla.
-
