Monitoreo del progreso de varios trabajos
Puede generar perfiles en varios trabajos de AWS Glue de forma conjunta y monitorear el flujo de datos entre ellos. Se trata de un patrón de flujo de trabajo habitual y requiere el monitoreo del progreso de trabajos individuales, las tareas pendientes de procesamiento de datos, el reprocesamiento de datos y los marcadores de trabajos.
Temas
Código con perfil
En este flujo de trabajo, tiene dos trabajos: un trabajo de entrada y un trabajo de salida. El trabajo de entrada está programado para ejecutarse cada 30 minutos mediante un disparador periódico. El trabajo de salida está programado para ejecutarse tras cada ejecución correcta del trabajo de entrada. Estos trabajos programados se controlan mediante disparadores del trabajo.

Trabajo de entrada: este trabajo lee datos desde una ubicación de Amazon Simple Storage Service (Amazon S3), los transforma mediante ApplyMapping y los escribe en una ubicación de Amazon S3 provisional. El siguiente código es código con perfil para el trabajo de entrada:
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": ["s3://input_path"], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": staging_path, "compression": "gzip"}, format = "json")
Trabajo de salida: este trabajo lee la salida del trabajo de entrada desde la ubicación provisional en Amazon S3, la vuelve a transformar y la escribe en un destino:
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [staging_path], "useS3ListImplementation":True,"recurse":True}, format="json") applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [map_spec]) datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": output_path}, format = "json")
Visualizar las métricas con perfil en la consola de AWS Glue
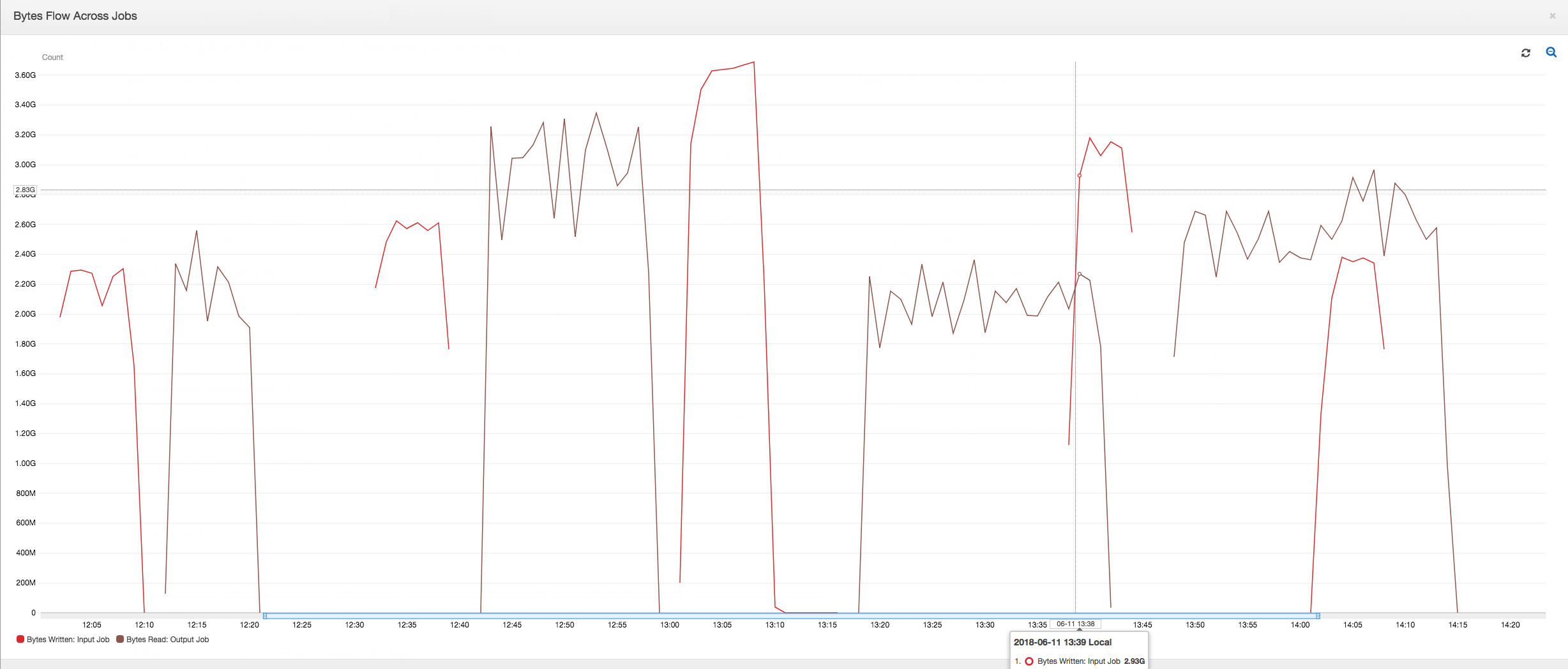
El siguiente panel superpone la métrica escrita de bytes de Amazon S3 desde el trabajo de entrada en la métrica leída de bytes de Amazon S3 en la misma escala de tiempo del trabajo de salida. La escala de tiempo muestra diferentes ejecuciones de trabajo de los trabajos de entrada y salida. El trabajo de entrada (mostrado en rojo) comienza cada 30 minutos. El trabajo de salida (mostrado en marrón) comienza al finalizar el trabajo de entrada, con una simultaneidad máxima de 1.
En este ejemplo, los marcadores de trabajos no están habilitados. No se usa ningún contexto de transformación para habilitar marcadores de trabajos en el código de script.
Historial de trabajos: los trabajos de entrada y salida tienen varias ejecuciones, como se muestra en la pestaña History (Historial), las cuales comienzan a partir de las 12:00 h.
El trabajo de entrada de la consola de AWS Glue tiene este aspecto:

En la siguiente imagen se muestra el trabajo de salida:

Primeras ejecuciones de trabajo: como se muestra en el siguiente gráfico de bytes de datos leídos y escritos, las primeras ejecuciones de trabajo de los trabajos de entrada y salida entre las 12:00 y las 12:30 h muestran más o menos la misma área bajo las curvas. Esas áreas representan los bytes de Amazon S3 escritos por el trabajo de entrada y los bytes de Amazon S3 leídos por el trabajo de salida. Estos datos también están confirmados por la relación de bytes de Amazon S3 escritos (suma de más de 30 minutos, la frecuencia del desencadenador de trabajo para el trabajo de entrada). El punto de datos de la relación para la ejecución de trabajo de entrada que comenzó a las 12:00 h también es 1.
En el siguiente gráfico se muestra la relación de flujo de datos entre todas las ejecuciones de trabajo:

Segundas ejecuciones de trabajo: en la segunda ejecución de trabajo, existe una clara diferencia entre el número de bytes leídos por el trabajo de salida y el número de bytes escritos por el trabajo de entrada (compare el área bajo la curva entre las dos ejecuciones de trabajo para el trabajo de salida, o bien las áreas en la segunda ejecución de los trabajos de entrada y salida). La relación de los bytes leídos y escritos muestra que el trabajo de salida lee alrededor de 2,5 veces los datos escritos por el trabajo de entrada en el segundo periodo de 30 minutos de 12:30 a 13:00 h. Esto se debe a que el trabajo de salida reprocesó la salida de la primera ejecución de trabajo del trabajo de entrada porque los marcadores de trabajos no estaban habilitados. Una relación superior a 1 muestra que hay tareas pendientes adicionales de datos que el trabajo de salida procesó.
Terceras ejecuciones de trabajo: el trabajo de entrada es bastante coherente en términos del número de bytes escritos (consulte el área bajo las curvas rojas). Sin embargo, la tercera ejecución de trabajo del trabajo de entrada se ejecutó más tiempo del que se había previsto (consulte la larga cola de la curva roja). Como resultado, la tercera ejecución de trabajo del trabajo de salida comenzó tarde. La tercera ejecución de trabajo procesó solo una fracción de los datos acumulados en la ubicación provisional durante los 30 minutos restantes entre las 13:00 y las 13:30 h. La relación del flujo de bytes muestra que solo procesó 0,83 de los datos escritos por la tercera ejecución de trabajo del trabajo de entrada (consulte la relación a las 13:00 h).
Solapamiento de los trabajos de entrada y salida: la cuarta ejecución de trabajo del trabajo de entrada comenzó a las 13:30 h según el programa, antes de finalizar la tercera ejecución de trabajo del trabajo de salida. Existe un solapamiento parcial entre estas dos ejecuciones de trabajo. Sin embargo, la tercera ejecución de trabajo del trabajo de salida captura solo los archivos que listó en la ubicación provisional de Amazon S3 cuando empezó alrededor de las 13:17 h. Esta consta de la salida de todos los datos de las primeras ejecuciones de trabajo del trabajo de entrada. La relación real a las 13:30 h es de aproximadamente 2,75. La tercera ejecución de trabajo del trabajo de salida procesó alrededor de 2,75 veces los datos escritos por la cuarta ejecución de trabajo del trabajo de entrada de 13:00 a 14:00 h.
Tal como muestran estas imágenes, el trabajo de salida reprocesa datos de la ubicación provisional de todas las ejecuciones de trabajo anteriores del trabajo de entrada. Como resultado, la cuarta ejecución de trabajo para el trabajo de salida es la más larga y se solapa con la quinta ejecución de trabajo al completo del trabajo de entrada.
Corregir el procesamiento de los archivos
Debe garantizar que el trabajo de salida procese solo los archivos que no han procesado las ejecuciones de trabajo anteriores del trabajo de salida. Para ello, habilite marcadores de trabajos y establezca el contexto de transformación en el trabajo de salida, como se indica a continuación:
datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3", connection_options = {"paths": [staging_path], "useS3ListImplementation":True,"recurse":True}, format="json", transformation_ctx = "bookmark_ctx")
Con los marcadores de trabajos habilitados, el trabajo de salida no reprocesa los datos en la ubicación provisional de todas las ejecuciones de trabajo anteriores del trabajo de entrada. En la siguiente imagen donde se muestran los datos leídos y escritos, el área bajo la curva marrón es bastante coherente y similar a la de las curvas rojas.

Las relaciones de flujo de bytes también permanecen más o menos próximas a 1 al no haber datos adicionales procesados.
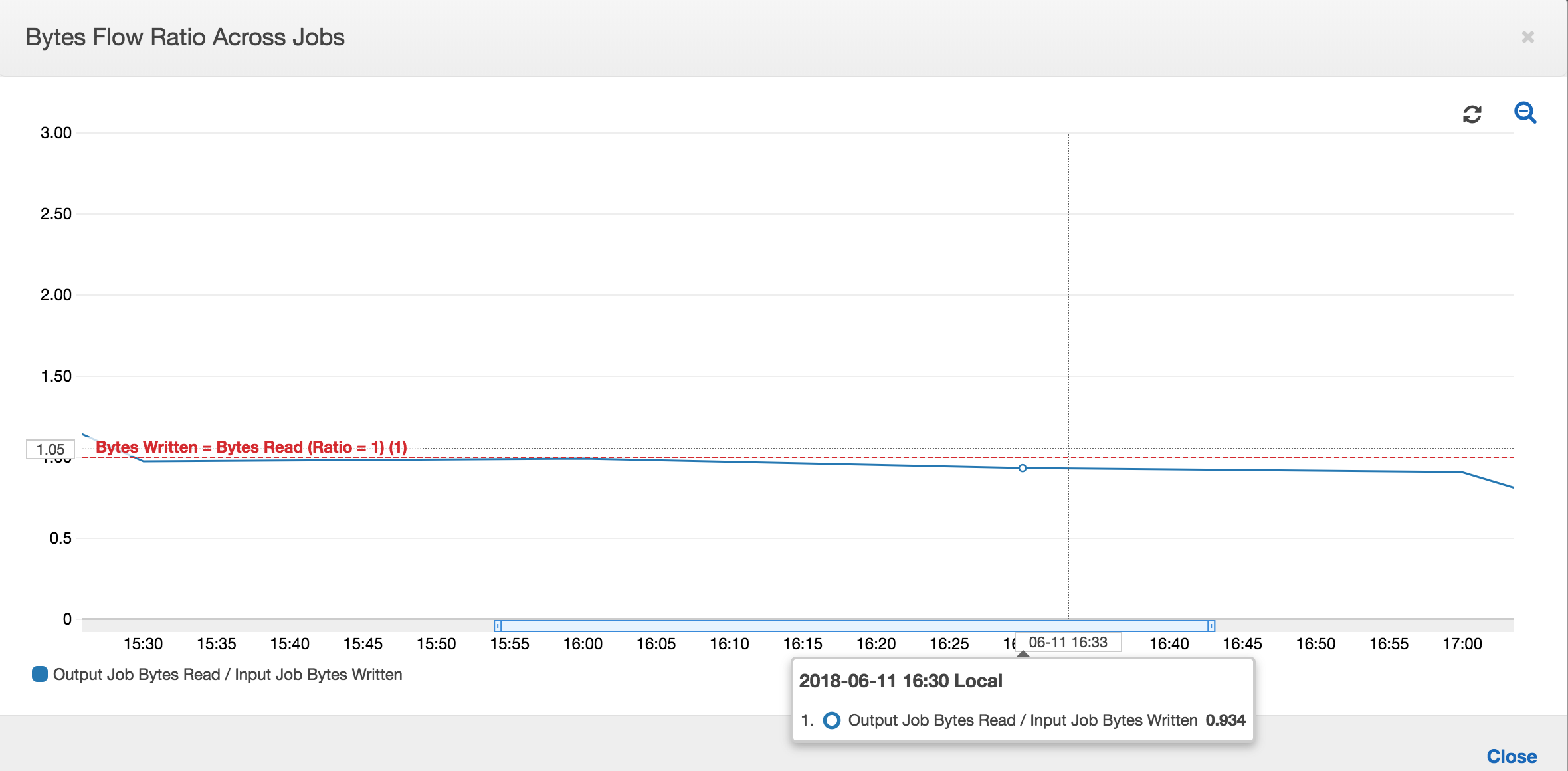
Una ejecución de trabajo para el trabajo de salida comienza y captura los archivos en la ubicación provisional antes de que la siguiente ejecución de trabajo de entrada comience a poner más datos en la ubicación provisional. Siempre que siga haciendo esto, procesará solo los archivos capturados de la ejecución de trabajo de entrada anterior, mientras que la relación permanece próxima a 1.
Supongamos que el trabajo de entrada tarda más de lo esperado y, como resultado, el trabajo de salida captura archivos en la ubicación provisional de dos ejecuciones de trabajo de entrada. A continuación, la relación es mayor que 1 para esa ejecución de trabajo de salida. Sin embargo, las siguientes ejecuciones de trabajo del trabajo de salida no procesan ningún archivo que ya hayan procesado las ejecuciones de trabajo anteriores del trabajo de salida.
