El lenguaje de definición de calidad de datos (DQDL) es un lenguaje específico de un dominio que se utiliza para definir las reglas de Calidad de datos de AWS Glue.
En esta guía, se presentan los conceptos clave de DQDL para entender el lenguaje. También proporciona una referencia para los tipos de reglas de DQDL con sintaxis y ejemplos. Antes de utilizar esta guía, le recomendamos que se familiarice con Calidad de datos de AWS Glue. Para obtener más información, consulte Calidad de datos de AWS Glue.
nota
Las reglas dinámicas solo se admiten en ETL de AWS Glue.
Contenido
Sintaxis de DQDL
Un documento de DQDL distingue entre mayúsculas y minúsculas y contiene un conjunto de reglas que agrupa las reglas individuales de la calidad de los datos. Para crear un conjunto de reglas, debe crear una lista denominada Rules (en mayúscula), delimitada por un par de corchetes. La lista debe contener una o más reglas de DQDL separadas por comas, como en el ejemplo siguiente.
Rules = [
IsComplete "order-id",
IsUnique "order-id"
]Estructura de la regla
La estructura de una regla de DQDL depende del tipo de regla. Sin embargo, las reglas de DQDL se suelen ajustar al siguiente formato.
<RuleType> <Parameter> <Parameter> <Expression>
RuleType es el nombre que distingue entre mayúsculas y minúsculas del tipo de regla que quiere configurar. Por ejemplo, IsComplete, IsUnique o CustomSql. Los parámetros de la regla son diferentes para cada tipo de regla. Para obtener una referencia completa de los tipos de reglas de DQDL y sus parámetros, consulte Referencia de tipo de regla de DQDL.
Reglas compuestas
DQDL admite los siguientes operadores lógicos que puede utilizar para combinar las reglas. Estas reglas se denominan reglas compuestas.
- y
-
El operador lógico
andda como resultadotrue, siempre y cuando las reglas que conecta seantrue. De lo contrario, la regla combinada da como resultadofalse. Cada regla que conecte con el operadoranddebe estar entre paréntesis.El siguiente ejemplo usa el operador
andpara combinar dos reglas de DQDL.(IsComplete "id") and (IsUnique "id") - o
-
El operador lógico
orda como resultadotrue, siempre y cuando una o varias de las reglas que conecta seantrue. Cada regla que conecte con el operadorordebe estar entre paréntesis.El siguiente ejemplo usa el operador
orpara combinar dos reglas de DQDL.(RowCount "id" > 100) or (IsPrimaryKey "id")
Puede utilizar el mismo operador para conectar varias reglas, por lo que se permite la siguiente combinación de reglas.
(Mean "Star_Rating" > 3) and (Mean "Order_Total" > 500) and (IsComplete "Order_Id")Puede combinar los operadores lógicos en una sola expresión. Por ejemplo:
(Mean "Star_Rating" > 3) and ((Mean "Order_Total" > 500) or (IsComplete "Order_Id"))También puede crear reglas anidadas más complejas.
(RowCount > 0) or ((IsComplete "colA") and (IsUnique "colA"))Funcionamiento de las reglas compuestas
De manera predeterminada, las reglas compuestas son evaluadas como reglas individuales a lo largo de todo el conjunto de datos y de la tabla y luego se combinan los resultados. En otras palabras, primero evalúan toda la columna y, a continuación, aplican el operador. Este comportamiento predeterminado se explica a continuación con un ejemplo:
# Dataset
+------+------+
|myCol1|myCol2|
+------+------+
| 2| 1|
| 0| 3|
+------+------+
# Overall outcome
+----------------------------------------------------------+-------+
|Rule |Outcome|
+----------------------------------------------------------+-------+
|(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)|Failed |
+----------------------------------------------------------+-------+
En el ejemplo anterior, AWS Glue Data Quality primero evalúa (ColumnValues "myCol1" > 1), lo cual resultará en una falla. Luego evaluará (ColumnValues "myCol2" > 2), que también fallará. La combinación de los dos resultados se indicará como fallida.
Sin embargo, si prefiere SQL como el comportamiento en caso de que necesite evaluar una fila entera, tiene que establecer de manera explícita el parámetro ruleEvaluation.scope como se muestra en additionalOptions, en el fragmento de código a continuación.
object GlueApp {
val datasource = glueContext.getCatalogSource(
database="<db>",
tableName="<table>",
transformationContext="datasource"
).getDynamicFrame()
val ruleset = """
Rules = [
(ColumnValues "age" >= 26) OR (ColumnLength "name" >= 4)
]
"""
val dq_results = EvaluateDataQuality.processRows(
frame=datasource,
ruleset=ruleset,
additionalOptions=JsonOptions("""
{
"compositeRuleEvaluation.method":"ROW"
}
"""
)
)
}
En Catálogo de datos de AWS Glue, puede configurar fácilmente esta opción en la interfaz de usuario, como se muestra a continuación.

Una vez establecidas, las reglas compuestas se comportarán como una regla única que evalúa la fila en su totalidad. En el ejemplo a continuación se muestra este comportamiento.
# Row Level outcome
+------+------+------------------------------------------------------------+---------------------------+
|myCol1|myCol2|DataQualityRulesPass |DataQualityEvaluationResult|
+------+------+------------------------------------------------------------+---------------------------+
|2 |1 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed |
|0 |3 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed |
+------+------+------------------------------------------------------------+---------------------------+
Algunas reglas no son compatibles con esta característica debido a que los resultados generales se basan en umbrales o proporciones. Estas regulas se enumeran a continuación.
Reglas que se basan en las proporciones:
-
Integridad
-
DataSetMatch
-
ReferentialIntegrity
-
Singularidad
Reglas que se basan en los umbrales:
Cuando las reglas que se mencionan a continuación incluyen con un umbral, no son compatibles. Sin embargo, las reglas que no incluyen with threshold sí mantienen la compatibilidad.
-
ColumnDataType
-
ColumnValues
-
CustomSQL
Expressions
Si un tipo de regla no produce una respuesta booleana, debe proporcionar una expresión como parámetro para crear una respuesta booleana. Por ejemplo, la siguiente regla compara la media (promedio) de todos los valores de una columna con una expresión para obtener un resultado true (verdadero) o false (falso).
Mean "colA" between 80 and 100Algunos tipos de reglas, como IsUnique y IsComplete ya producen una respuesta booleana.
En la tabla siguiente, se enumeran las expresiones que puede utilizar en las reglas de DQDL.
| Expression | Descripción | Ejemplo |
|---|---|---|
=x |
Se resuelve en true si la respuesta del tipo de regla es igual que x. |
|
!=x |
Se resuelve en verdadero si la respuesta del tipo de regla es igual a x. |
|
> x |
Se resuelve en true si la respuesta del tipo de regla es mayor que x. |
|
< x |
Se resuelve en true si la respuesta del tipo de regla es menor que x. |
|
>= x |
Se resuelve en true si la respuesta del tipo de regla es mayor o igual que x. |
|
<= x |
Se resuelve en true si la respuesta del tipo de regla es menor o igual que x. |
|
entre x e y |
Se resuelve en true si la respuesta del tipo de regla se encuentra en un rango especificado (exclusivo). Solo debe utilizar este tipo de expresión para los tipos numéricos y de datos. |
|
no está entre x e y |
Se resuelve en verdadero si la respuesta del tipo de regla no se encuentra en un rango especificado (inclusivo). Solo debe utilizar este tipo de expresión para los tipos numéricos y de fecha. |
|
en [a, b, c, ...] |
Se resuelve en true si la respuesta del tipo de regla se encuentra en el conjunto especificado. |
|
no está en [a, b, c,... ] |
Se resuelve en true si la respuesta del tipo de regla no se encuentra en el conjunto especificado. |
|
coincide con /ab+c/i |
Se resuelve en true si la respuesta del tipo de regla coincide con una expresión regular. |
|
no coincide con /ab+c/i |
Se resuelve en true si la respuesta del tipo de regla no coincide con una expresión regular. |
|
now() |
Solo funciona con el tipo de regla ColumnValues para crear una expresión de fecha. |
|
en/coincide con [...] / no está en/no coincide con [...] with threshold |
Indica el porcentaje de valores que coinciden con las condiciones de la regla. Solo funciona con los tipos de regla ColumnValues, ColumnDataType y CustomSQL. |
|
Palabras clave para NULL, EMPTY y WHITESPACES_ONLY
Para validar si una columna de cadenas contiene una cadena nula, vacía o solo con espacios en blanco, puede utilizar las palabras clave a continuación:
-
NULL/null: esta palabra clave se resuelve como verdadera para un valor
nullen una columna de cadenas.ColumnValues "colA" != NULL with threshold > 0.5devolvería el valor verdadero si más del 50 % de los datos no tienen valores nulos.(ColumnValues "colA" = NULL) or (ColumnLength "colA" > 5)devolvería el valor verdadero para todas las filas que tengan un valor nulo o una longitud superior a 5. Tenga en cuenta que esto requiere que se utilice la opción “compositeRuleEvaluation.method” = “ROW”. -
EMPTY/empty: esta palabra clave se resuelve como verdadera para un valor de cadena vacío (“”) en una columna de cadenas. Algunos formatos de datos transforman los valores nulos de una columna de cadenas en cadenas vacías. Esta palabra clave ayuda a remover las cadenas vacías en los datos.
(ColumnValues "colA" = EMPTY) or (ColumnValues "colA" in ["a", "b"])devolvería el valor verdadero si una fila está vacía, “a” o “b”. Tenga en cuenta que esto requiere que se utilice la opción “compositeRuleEvaluation.method” = “ROW”. -
WHITESPACES_ONLY/whitespaces_only: esta palabra clave se resuelve como verdadera para una cadena que solo tiene un valor de espacios en blanco (“ ”) en una columna de cadenas.
ColumnValues "colA" not in ["a", "b", WHITESPACES_ONLY]devolvería el valor verdadero si una fila no es ni “a” ni “b” ni solo contiene espacios en blanco.Reglas admitidas:
Puede utilizar las palabras clave a continuación para validar si una columna contiene un valor nulo al trabajar con expresiones numéricas o basadas en fechas.
-
NULL/null: esta palabra clave se resuelve como verdadera para un valor nulo en una columna de cadenas.
ColumnValues "colA" in [NULL, "2023-01-01"]devolvería el valor verdadero si una fecha de la columna es2023-01-01o nula.(ColumnValues "colA" = NULL) or (ColumnValues "colA" between 1 and 9)devolvería el valor verdadero para todas las filas que tengan un valor nulo o cuyos valores sean entre 1 y 9. Tenga en cuenta que esto requiere que se utilice la opción “compositeRuleEvaluation.method” = “ROW”.Reglas admitidas:
Filtrado con la cláusula Where
nota
La cláusula Where solo es compatible con AWS Glue 4.0.
Puede filtrar sus datos durante la creación de reglas. Esto resulta útil cuando se quieren aplicar reglas condicionales.
<DQDL Rule> where "<valid SparkSQL where clause> " El filtro debe especificarse con la palabra clave where, seguida de una instrucción de SparkSQL válida entre comillas ("").
Si desea agregar la cláusula Where a una regla que tiene un umbral, la cláusula Where debe especificarse antes de la condición de umbral.
<DQDL Rule> where "valid SparkSQL statement>" with threshold <threshold condition>
Con esta sintaxis, puede escribir reglas como las siguientes.
Completeness "colA" > 0.5 where "colB = 10"
ColumnValues "colB" in ["A", "B"] where "colC is not null" with threshold > 0.9
ColumnLength "colC" > 10 where "colD != Concat(colE, colF)" Comprobaremos si la instrucción de SparkSQL proporcionada es válida. Si no es válida, la evaluación de la regla fallará y mostrará el error IllegalArgumentException con el siguiente formato:
Rule <DQDL Rule> where "<invalid SparkSQL>" has provided an invalid where clause :
<SparkSQL Error>Comportamiento de la cláusula Where cuando la identificación del registro de errores a nivel de la fila está activada
Con Calidad de datos de AWS Glue, puede identificar registros específicos que fallaron. Al aplicar una cláusula Where a las reglas que admiten resultados a nivel de la fila, etiquetaremos las filas filtradas por la cláusula Where como Passed.
Si prefiere etiquetar por separado las filas filtradas como SKIPPED, puede configurar las siguientes additionalOptions para el trabajo de ETL.
object GlueApp {
val datasource = glueContext.getCatalogSource(
database="<db>",
tableName="<table>",
transformationContext="datasource"
).getDynamicFrame()
val ruleset = """
Rules = [
IsComplete "att2" where "att1 = 'a'"
]
"""
val dq_results = EvaluateDataQuality.processRows(
frame=datasource,
ruleset=ruleset,
additionalOptions=JsonOptions("""
{
"rowLevelConfiguration.filteredRowLabel":"SKIPPED"
}
"""
)
)
}Como ejemplo, consulte la siguiente regla y el marco de datos:
IsComplete att2 where "att1 = 'a'"| id | att1 | att2 | Resultados a nivel de la fila (predeterminado) | Resultados a nivel de la fila (opción omitida) | Comentarios |
|---|---|---|---|---|---|
| 1 | a | f | PASSED | PASSED | |
| 2 | b | d | PASSED | SKIPPED | La fila está filtrada, ya que att1 no es "a" |
| 3 | a | null | ERROR | ERROR | |
| 4 | a | f | PASSED | PASSED | |
| 5 | b | null | PASSED | SKIPPED | La fila está filtrada, ya que att1 no es "a" |
| 6 | a | f | PASSED | PASSED |
Reglas dinámicas
nota
Las reglas dinámicas solo se admiten en la ETL de AWS Glue y no en el Catálogo de datos de AWS Glue.
Ahora puede crear reglas dinámicas para comparar las métricas actuales generadas por sus reglas con sus valores históricos. Estas comparaciones históricas se habilitan usando el operador last() en las expresiones. Por ejemplo, la regla RowCount >
last() se aplicará correctamente cuando el número de filas de la ejecución actual sea superior al recuento de filas anterior más reciente del mismo conjunto de datos. last() utiliza un argumento numérico natural opcional que describe cuántas métricas anteriores se deben tener en cuenta; last(k) donde k
>= 1 hará referencia a las últimas métricas k.
-
Si no hay puntos de datos disponibles,
last(k)devolverá el valor predeterminado, 0,0. -
Si hay menos de las métricas
kdisponibles,last(k)devolverá todas las métricas anteriores.
Para formar expresiones válidas utilice last(k), donde k > 1 requiera una función de agregación para reducir varios resultados históricos a un solo número. Por ejemplo, RowCount > avg(last(5)) comprobará si el recuento de filas del conjunto de datos actual es estrictamente mayor que el promedio de los últimos cinco recuentos de filas del mismo conjunto de datos. RowCount > last(5) producirá un error, porque el recuento de filas del conjunto de datos actual no se puede comparar de forma significativa con una lista.
Funciones de agregación admitidas:
-
avg -
median -
max -
min -
sum -
std(desviación estándar) -
abs(valor absoluto) -
index(last(k), i)permitirá seleccionar el valor en la posiciónide los más recientes del últimok.iestá indexado a cero, por lo queindex(last(3), 0)devolverá el punto de datos más reciente yindex(last(3), 3)generará un error, ya que solo hay tres puntos de datos e intentaremos indexar el cuarto más reciente.
Ejemplos de expresiones
ColumnCorrelation
ColumnCorrelation "colA" "colB" < avg(last(10))
DistinctValuesCount
DistinctValuesCount "colA" between min(last(10))-1 and max(last(10))+1
La mayoría de los tipos de reglas con condiciones o umbrales numéricos admiten reglas dinámicas; consulte la tabla dada, Analizadores y reglas, para determinar si las reglas dinámicas son compatibles con su tipo de regla.
Exclusión de las estadísticas de las reglas dinámicas
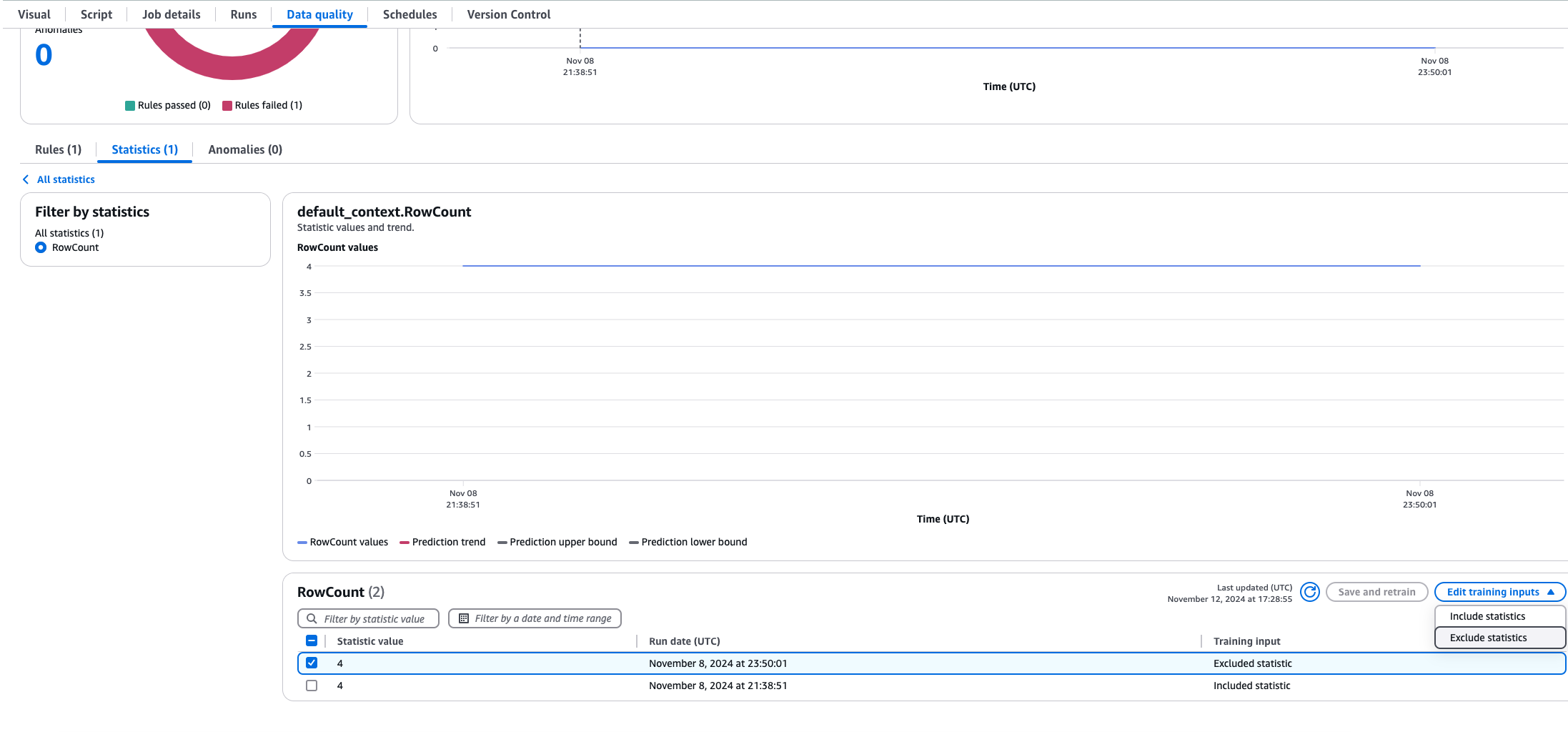
En ocasiones, tendrá que excluir las estadísticas de datos de los cálculos de las reglas dinámicas. Supongamos que ha efectuado una carga de datos históricos y no quiere que eso afecte a sus promedios. Para ello, abra el trabajo en la ETL de AWS Glue y seleccione la pestaña Calidad de los datos; a continuación, seleccione Estadísticas y seleccione las estadísticas que desee excluir. Podrá ver un gráfico de tendencias junto con una tabla de estadísticas. Seleccione los valores que desee excluir y elija Excluir estadísticas. Ahora las estadísticas que estén excluidas no se incluirán en los cálculos de las reglas dinámicas.
Analizadores
nota
El Catálogo de datos de AWS Glue no es compatible con los analizadores.
Las reglas de DQDL usan funciones denominadas analizadores para recopilar información sobre los datos. La expresión booleana de una regla hace uso de esta información para determinar si la regla debe funcionar correctamente o no. Por ejemplo, la regla RowCount RowCount > 5 usará un analizador de recuento de filas para descubrir el número de filas del conjunto de datos y compararlo con la expresión > 5, para comprobar si existen más de cinco filas en el conjunto de datos actual.
A veces, en lugar de crear reglas, recomendamos crear analizadores y luego hacer que generen estadísticas que puedan usarse para detectar anomalías. Para estos casos, puede crear analizadores. Los analizadores se diferencian de las reglas en estas formas.
| Característica | Analizadores | Reglas |
|---|---|---|
| Parte del conjunto de reglas | Sí | Sí |
| Genera estadísticas | Sí | Sí |
| Genera observaciones | Sí | Sí |
| Puede evaluar y hacer valer una condición | No | Sí |
| Puede configurar acciones como detener los trabajos por fallas o continuar procesando el trabajo | No | Sí |
Los analizadores pueden existir de forma independiente sin reglas, por lo que es posible configurarlos rápidamente y crear progresivamente reglas de calidad de datos.
Algunos tipos de reglas se pueden introducir en el bloque Analyzers del conjunto de reglas para ejecutar las reglas necesarias para los analizadores y recopilar información sin comprobar ninguna condición. Algunos analizadores no están asociados a las reglas y solo se pueden introducir en el bloque Analyzers. La siguiente tabla indica si cada elemento se admite como regla o como analizador independiente, junto con información adicional para cada tipo de regla.
Ejemplos de conjunto de reglas con el analizador
El siguiente conjunto de reglas usa:
-
una regla dinámica para comprobar si un conjunto de datos está creciendo por arriba de su media final en las últimas tres ejecuciones de tareas,
-
un analizador
DistinctValuesCountpara registrar la cantidad de valores distintos de la columna del conjunto de datos deName, -
un analizador
ColumnLengthpara rastrear el tamaño mínimo y máximo deNamea lo largo del tiempo.
Los resultados de las métricas del analizador pueden verse en la pestaña Calidad de los datos durante la ejecución del trabajo.
Rules = [
RowCount > avg(last(3))
]
Analyzers = [
DistinctValuesCount "Name",
ColumnLength "Name"
]
Calidad de datos de AWS Glue es compatible con los siguientes analizadores.
| Nombre del analizador | Funcionalidad |
|---|---|
RowCount |
Calcula los recuentos de filas de un conjunto de datos |
Completeness |
Calcula el porcentaje de integridad de una columna |
Uniqueness |
Calcula el porcentaje de exclusividad de una columna |
Mean |
Calcula la media de una columna numérica |
Sum |
Calcula la suma de una columna numérica |
StandardDeviation |
Calcula la desviación estándar de una columna numérica |
Entropy |
Calcula la entropía de una columna numérica |
DistinctValuesCount |
Calcula el número de valores distintos de una columna |
UniqueValueRatio |
Calcula la relación de valores únicos de una columna |
ColumnCount |
Calcula el número de columnas de un conjunto de datos |
ColumnLength |
Calcula la longitud de una columna |
ColumnValues |
Calcula el mínimo y el máximo para las columnas numéricas Calcula la longitud mínima de la columna y la longitud máxima de la columna para las columnas no numéricas |
ColumnCorrelation |
Calcula las correlaciones de columnas para las columnas dadas |
CustomSql |
Calcula las estadísticas que devuelve CustomSQL |
AllStatistics |
Calcula las siguientes estadísticas:
|
Comentarios
Puede utilizar el carácter “#” para agregar un comentario al documento DQDL. DQDL ignorará todo lo que figure a continuación del “#” hasta el final de la línea.
Rules = [
# More items should generally mean a higher price, so correlation should be positive
ColumnCorrelation "price" "num_items" > 0
]