Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Solución para supervisar la infraestructura de Amazon EKS con Amazon Managed Grafana
La supervisión de la infraestructura de Amazon Elastic Kubernetes Service es uno de los escenarios más comunes en los que se utiliza Amazon Managed Grafana. En esta página se describe una plantilla que le proporciona una solución para este escenario. La solución se puede instalar mediante AWS Cloud Development Kit (AWS CDK) o con Terraform
Esta solución configura:
-
Su espacio de trabajo de Amazon Managed Service para Prometheus para almacenar métricas del clúster de Amazon EKS y crear un recopilador administrado para reunir las métricas e insertarlas en ese espacio de trabajo. Para obtener más información, consulta Ingesta métricas con recopiladores AWS gestionados.
-
Recopilación de registros de su clúster de Amazon EKS mediante un CloudWatch agente. Los registros se almacenan en CloudWatch Grafana gestionada por Amazon y los consulta. Para obtener más información, consulte Logging for Amazon EKS
-
Su espacio de trabajo de Amazon Managed Grafana puede extraer esos registros y métricas, y crear paneles y alertas que lo ayuden a supervisar su clúster.
Al aplicar esta solución, se crearán paneles y alertas que:
-
Evalúen el estado general del clúster de Amazon EKS.
-
Muestren el estado y el rendimiento del plano de control de Amazon EKS.
-
Muestren el estado y el rendimiento del plano de datos de Amazon EKS.
-
Muestren información sobre las cargas de trabajo de Amazon EKS en los espacios de nombres de Kubernetes.
-
Muestren el uso de los recursos en los espacios de nombres, incluido el uso de CPU, memoria, disco y red.
Acerca de esta solución
Esta solución configura un espacio de trabajo de Amazon Managed Grafana para proporcionar métricas para su clúster de Amazon EKS. Las métricas se utilizan para generar paneles y alertas.
Las métricas lo ayudan a operar los clústeres de Amazon EKS de manera más eficaz al proporcionar información sobre el estado y el rendimiento del plano de datos y de control de Kubernetes. Puede comprender su clúster de Amazon EKS desde el nivel de nodo, pasando por los pods y hasta el nivel de Kubernetes, incluida la supervisión detallada del uso de los recursos.
La solución ofrece capacidades tanto anticipatorias como correctivas:
-
Las capacidades anticipatorias incluyen:
-
Administración de la eficiencia de los recursos impulsando las decisiones de programación. Por ejemplo, para proporcionar SLA de rendimiento y fiabilidad a los usuarios internos del clúster de Amazon EKS, puede asignar suficientes recursos de CPU y memoria a sus cargas de trabajo en función del seguimiento del uso histórico.
-
Previsiones de uso: en función del uso actual de los recursos del clúster de Amazon EKS, como los nodos, los volúmenes persistentes respaldados por Amazon EBS o los equilibradores de carga de aplicaciones, puede planificar con antelación, por ejemplo, un nuevo producto o proyecto con demandas similares.
-
Detección anticipada de los posibles problemas: por ejemplo, al analizar las tendencias de consumo de recursos de nivel de espacio de nombres de Kubernetes, podrá comprender la estacionalidad del uso de la carga de trabajo.
-
-
Las capacidades correctivas incluyen:
-
Reducción del tiempo medio de detección (MTTD) de los problemas en la infraestructura y el nivel de carga de trabajo de Kubernetes. Por ejemplo, si consulta el panel de resolución de problemas, puede probar rápidamente hipótesis sobre lo que salió mal y eliminarlas.
-
Determinación de en qué parte de la pila se está produciendo un problema. Por ejemplo, el plano de control de Amazon EKS está totalmente gestionado por, AWS y algunas operaciones, como la actualización de una implementación de Kubernetes, pueden fallar si el servidor de API está sobrecargado o la conectividad se ve afectada.
-
En la siguiente imagen se muestra un ejemplo de la carpeta del panel de la solución.
Puede elegir un panel para ver más detalles; por ejemplo, si elige ver los recursos de computación de las cargas de trabajo, se mostrará un panel como el que se muestra en la siguiente imagen.
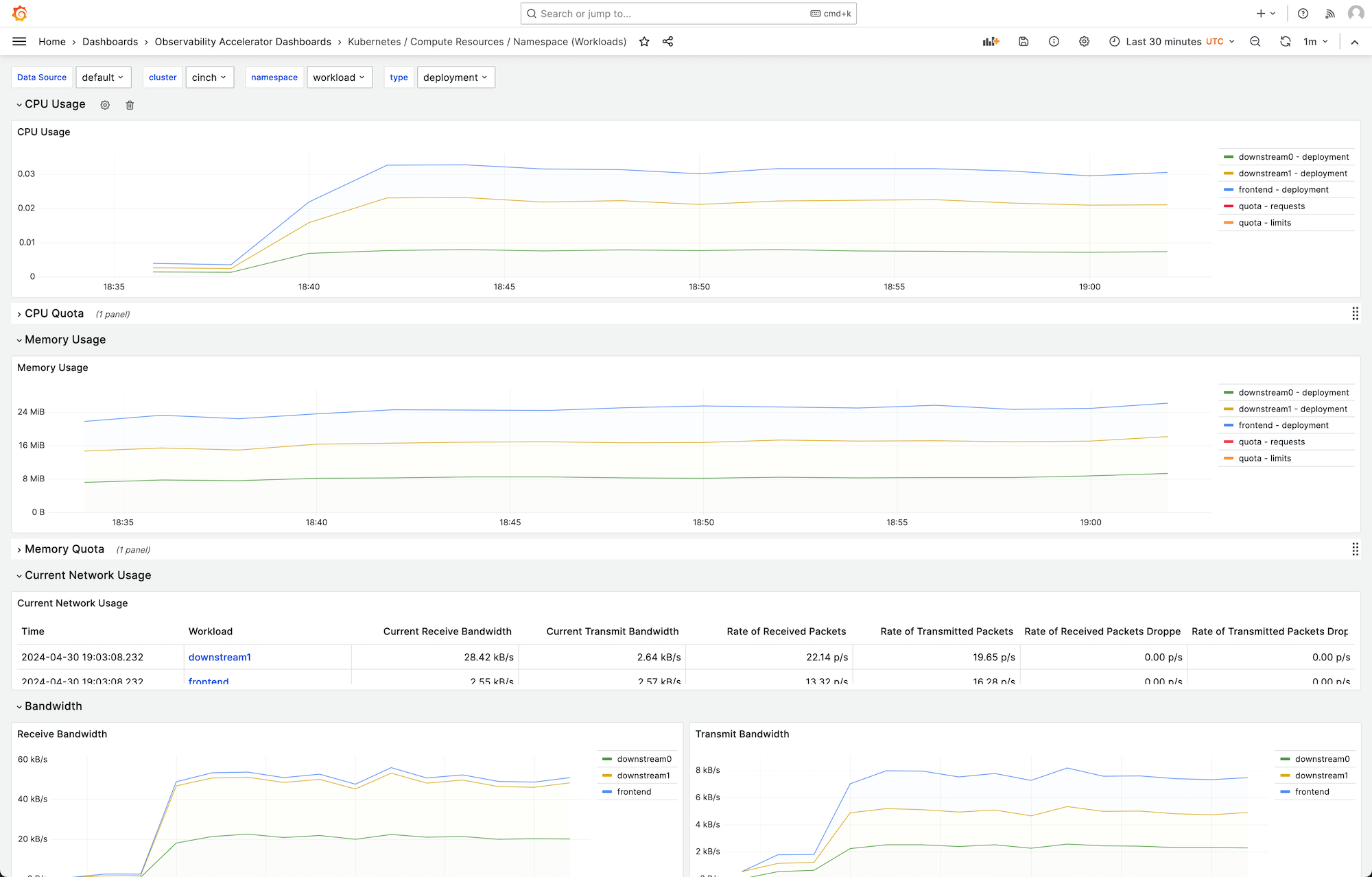
Las métricas se recopilan con un intervalo de extracción de 1 minuto. Los paneles muestran las métricas agregadas en 1 minuto, 5 minutos o más, en función de la métrica específica.
Los registros también se muestran en los paneles, de modo que puede consultarlos y analizarlos para encontrar las causas fundamentales de los problemas. En la siguiente imagen se muestra un ejemplo de panel de registros.
Para obtener una lista de las métricas rastreadas por esta solución, consulte Lista de métricas rastreadas.
Para obtener una lista de las alertas creadas por la solución, consulte Lista de alertas creadas.
Costos
Esta solución crea y utiliza recursos en su espacio de trabajo. Se le cobrará por el uso estándar de los recursos creados, que incluyen:
-
Acceso de los usuarios al espacio de trabajo de Amazon Managed Grafana. Para obtener más información acerca de los precios, consulte Precios de Amazon Managed Grafana
. -
Amazon Managed Service para Prometheus: ingesta y almacenamiento de métricas, que incluye el uso del recopilador sin agente de Amazon Managed Service para Prometheus y el análisis de métricas (procesamiento de muestras de consulta). El número de métricas que utiliza esta solución depende de la configuración y el uso del clúster de Amazon EKS.
Puedes ver las métricas de ingesta y almacenamiento en Amazon Managed Service for Prometheus CloudWatch utilizando Para obtener más información, consulta las CloudWatchmétricas en la Guía del usuario de Amazon Managed Service for Prometheus.
Puede calcular el costo utilizando la calculadora de precios de la página Precios de Amazon Managed Service para Prometheus
. El número de métricas dependerá del número de nodos del clúster y de las métricas que generen las aplicaciones. -
CloudWatch Registra la ingesta, el almacenamiento y el análisis. De forma predeterminada, la retención de registros está configurada para que no caduque nunca. Puede ajustarlo en CloudWatch. Para obtener más información sobre los precios, consulta Amazon CloudWatch Pricing
. -
Costos de red. Puede incurrir en cargos de AWS red estándar por tráfico de zonas de disponibilidad cruzada, región u otro tipo de tráfico.
Las calculadoras de precios, disponibles en la página de precios de cada producto, pueden ayudarlo a comprender los posibles costos de su solución. La siguiente información puede ayudar a obtener un costo base de la solución que se ejecuta en la misma zona de disponibilidad que el clúster de Amazon EKS.
| Producto | Métrica de la calculadora | Valor |
|---|---|---|
Servicio administrado por Amazon para Prometheus |
Serie activa |
8000 (base) 15 000 (por nodo) |
Intervalo promedio de recopilación |
60 (segundos) |
|
Amazon Managed Service para Prometheus (recopilador administrado) |
Número de recopiladores |
1 |
Número de muestras |
15 (base) 150 (por nodo) |
|
Número de regalas |
161 |
|
Intervalo promedio de extracción de reglas |
60 (segundos) |
|
Amazon Managed Grafana |
Número de activos editors/administrators |
1 (o más, en función de sus usuarios) |
CloudWatch (Registros) |
Registros estándar: datos ingeridos |
24,5 GB (base) 0,5 GB (por nodo) |
Registro Storage/Archival (registros estándar y vendidos) |
Sí, para almacenar registros: suponiendo una retención de 1 mes |
|
Datos de registros esperados analizados |
Cada consulta de información de registros de Grafana analizará todo el contenido del registro del grupo durante el periodo de tiempo especificado. |
Estos números son los números base de una solución que ejecuta EKS sin software adicional. Esto le proporcionará una estimación de los costos base. También omite los costes de uso de la red, que variarán en función de si el espacio de trabajo de Grafana gestionado por Amazon, el espacio de trabajo de Amazon Managed Service for Prometheus y el clúster de Amazon EKS se encuentran en la misma zona de disponibilidad, y la misma VPN. Región de AWS
nota
Cuando un elemento de esta tabla incluye un valor (base) y un valor por recurso (por ejemplo, (per node)), debe sumar el valor base al valor por recurso multiplicado por el número de ese recurso del que disponga. Por ejemplo, en la serie temporal promedio activa, ingrese un número que sea 8000 + the number of nodes in your cluster * 15,000. Si tiene 2 nodos, debe ingresar 38,000, que es 8000 + ( 2 * 15,000 ).
Requisitos previos
Esta solución requiere que haya hecho lo siguiente antes de utilizarla.
-
Debe tener o crear un clúster de Amazon Elastic Kubernetes Service que desee supervisar y el clúster debe tener al menos un nodo. El clúster debe tener configurado el acceso al punto de conexión del servidor de API para incluir el acceso privado (también puede permitir el acceso público).
El modo de autenticación debe incluir el acceso a la API (se puede configurar en
APIoAPI_AND_CONFIG_MAP). Esto permite que la implementación de la solución utilice entradas de acceso.Se debe instalar lo siguiente en el clúster (es verdadero de forma predeterminada al crear el clúster a través de la consola, pero se debe agregar si se crea el clúster mediante la AWS API o AWS CLI): AWS CNI, CoreDNS y. Kube-proxy AddOns
Guarde el nombre del clúster para especificarlo más adelante. Puede consultarlo en los detalles del clúster en la consola de Amazon EKS.
nota
Para obtener más información sobre cómo crear un clúster de Amazon EKS, consulte Introducción a Amazon EKS.
-
Debe crear un espacio de trabajo de Amazon Managed Service for Prometheus en el mismo lugar que su clúster Cuenta de AWS de Amazon EKS. Para obtener más información, consulte Create a workspace en la Guía del usuario de Amazon Managed Service para Prometheus.
Guarde el ARN del espacio de trabajo de Amazon Managed Service para Prometheus para especificarlo más adelante.
-
Debe crear un espacio de trabajo de Grafana gestionado por Amazon con Grafana versión 9 o posterior, al igual que Región de AWS su clúster de Amazon EKS. Para obtener más información sobre la creación de un nuevo espacio de trabajo, consulte Creación de un espacio de trabajo de Amazon Managed Grafana.
El rol de espacio de trabajo debe tener permisos para acceder a Amazon Managed Service for Prometheus y CloudWatch a las API de Amazon. La forma más sencilla de hacerlo es utilizar Service-managedlos permisos y seleccionar Amazon Managed Service for CloudWatch Prometheus y. También puedes añadir manualmente AmazonGrafanaCloudWatchAccesslas políticas AmazonPrometheusQueryAccessy a la función de IAM de tu espacio de trabajo.
Guarde el ID y el punto de conexión del espacio de trabajo de Amazon Managed Grafana para especificarlos más adelante. El ID tiene el formato
g-123example. El ID y el punto de conexión se encuentran en la consola de Amazon Managed Grafana. El punto de conexión es la URL del espacio de trabajo e incluye el ID. Por ejemplo,https://g-123example.grafana-workspace.<region>.amazonaws.com/. -
Si va a implementar la solución con Terraform, debe crear un bucket de Amazon S3 al que pueda acceder desde su cuenta. Se utilizará para almacenar los archivos de estado de Terraform para la implementación.
Guarde el ID del bucket de Amazon S3 para especificarlo más adelante.
-
Para ver las reglas de alertas de Amazon Managed Service para Prometheus, debe habilitar las alertas de Grafana para el espacio de trabajo de Amazon Managed Grafana.
Amazon Managed Grafana debe tener los siguientes permisos para acceder los recursos de Prometheus. Debe agregarlos a las políticas administradas por el servicio o administradas por el cliente que se describen en Amazon gestionó los permisos y las políticas de Grafana para las fuentes de datos AWS.
aps:ListRulesaps:ListAlertManagerSilencesaps:ListAlertManagerAlertsaps:GetAlertManagerStatusaps:ListAlertManagerAlertGroupsaps:PutAlertManagerSilencesaps:DeleteAlertManagerSilence
nota
Si bien no es estrictamente obligatorio configurar la solución, debe configurar la autenticación de usuario en su espacio de trabajo de Amazon Managed Grafana antes de que los usuarios puedan acceder a los paneles creados. Para obtener más información, consulte Autenticación de usuarios en los espacios de trabajo de Amazon Managed Grafana.
Uso de esta solución
Esta solución configura la AWS infraestructura para admitir las métricas de informes y monitoreo de un clúster de Amazon EKS. Puede instalarla mediante AWS Cloud Development Kit (AWS CDK) o con Terraform
Lista de métricas rastreadas
Esta solución crea un recopilador que reúne métricas del clúster de Amazon EKS. Estas métricas se almacenan en Amazon Managed Service para Prometheus y, después, se muestran en los paneles de Amazon Managed Grafana. De forma predeterminada, el raspador recopila todas Prometheus-compatible las métricas expuestas por el clúster. Si instala un software en su clúster que produce más métricas, aumentarán las métricas recopiladas. Si lo desea, puede reducir la cantidad de métricas actualizando el recopilador con una configuración que filtre las métricas.
Con esta solución se hace un seguimiento de las siguientes métricas, en una configuración de clúster base de Amazon EKS sin necesidad de instalar ningún software adicional.
| Métrica | Descripción o finalidad |
|---|---|
|
|
Indicador de los servicios de API que están marcados como no disponibles desglosados por nombre de servicio de API. |
|
|
Histograma de latencia de webhook de admisión en segundos, identificado por su nombre y desglosado para cada operación, recurso de API y tipo (validar o admitir). |
|
|
Número máximo de solicitudes en curso utilizadas actualmente por este apiserver por tipo de solicitud en el último segundo. |
|
|
Porcentaje de las ranuras de caché ocupadas actualmente por DEK en caché. |
|
|
Número de solicitudes en la fase de ejecución inicial (para una operación WATCH) o en cualquier fase de ejecución (para una operación que no sea WATCH) en el subsistema de prioridad y equidad de la API. |
|
|
Número de solicitudes en la fase de ejecución inicial (para una operación WATCH) o en cualquier fase de ejecución (para una operación que no sea WATCH) en el subsistema de prioridad y equidad de la API que se rechazaron. |
|
|
Número nominal de puestos de ejecución configurados para cada nivel de prioridad. |
|
|
Histograma agrupado en buckets de la fase inicial (para una operación WATCH) o en cualquier fase de ejecución de solicitudes (para una operación que no sea WATCH) en el subsistema de prioridad y equidad de la API. |
|
|
Recuento de la fase inicial (para una operación WATCH) o en cualquier fase de ejecución de solicitudes (para una operación que no sea WATCH) en el subsistema de prioridad y equidad de la API. |
|
|
Indica una solicitud de servidor de API. |
|
|
Indicador de las API obsoletas que se han solicitado, desglosadas por grupo de API, versión, recurso, subrecurso y removed_release. |
|
|
Distribución de la latencia de respuesta en segundos para cada verbo, valor de ensayo, grupo, versión, recurso, subrecurso, ámbito y componente. |
|
|
Histograma agrupado en buckets de la distribución de la latencia de respuesta en segundos para cada verbo, valor de ensayo, grupo, versión, recurso, subrecurso, ámbito y componente. |
|
|
Distribución de la latencia de respuesta del objetivo de nivel de servicio (SLO) en segundos para cada verbo, valor de ensayo, grupo, versión, recurso, subrecurso, ámbito y componente. |
|
|
Número de solicitudes que apiserver canceló en defensa propia. |
|
|
Contador de solicitudes de apiserver desglosadas por verbo, valor de ensayo, grupo, versión, recurso, ámbito, componente y código de respuesta HTTP. |
|
|
Tiempo acumulado de CPU consumido. |
|
|
Recuento acumulado de bytes leídos. |
|
|
Recuento acumulado de lecturas completadas. |
|
|
Recuento acumulado de bytes escritos. |
|
|
Recuento acumulado de escrituras completadas. |
|
|
Memoria caché del total de páginas. |
|
|
Tamaño de RSS. |
|
|
Uso de cambios de contenedores. |
|
|
Conjunto de trabajo actual. |
|
|
Recuento acumulado de bytes recibidos. |
|
|
Recuento acumulado de paquetes descartados durante la recepción. |
|
|
Recuento acumulado de paquetes recibidos. |
|
|
Recuento acumulado de bytes transmitidos. |
|
|
Recuento acumulado de paquetes descartados durante la transmisión. |
|
|
Recuento acumulado de paquetes transmitidos. |
|
|
El histograma agrupado en buckets de latencia de solicitudes de etcd en segundos para cada operación y tipo de objeto. |
|
|
Número de gorrutinas que existen actualmente. |
|
|
Número de subprocesos del sistema operativo creados. |
|
|
Histograma agrupado en buckets de la duración en segundos de las operaciones del administrador de cgroup. Desglosado por método. |
|
|
Duración en segundos de las operaciones del administrador de cgroup. Desglosado por método. |
|
|
Esta métrica es verdadera (1) si el nodo está experimentando un error relacionado con la configuración y falsa (0) en caso contrario. |
|
|
Nombre del nodo. El recuento siempre es 1. |
|
|
Histograma agrupado en buckets de la duración en segundos para volver a enumerar los pods en PLEG. |
|
|
Recuento en segundos de la duración correspondiente a volver a enumerar los pods en PLEG. |
|
|
Histograma agrupado en buckets del intervalo en segundos entre la nueva enumeración en PLEG. |
|
|
Recuento en segundos de la duración desde que Kubelet ve un pod por primera vez hasta que el pod empieza a ejecutarse. |
|
|
Histograma agrupado en buckets de la duración en segundos para sincronizar un solo pod. Desglosado por tipo de operación: crear, actualizar o sincronizar. |
|
|
Recuento de la duración en segundos para sincronizar un solo pod. Desglosado por tipo de operación: crear, actualizar o sincronizar. |
|
|
Número de contenedores en ejecución actualmente. |
|
|
Número de pods que tienen un entorno de pruebas limitado de pods en funcionamiento. |
|
|
Histograma agrupado en buckets de la duración en segundos de las operaciones del tiempo de ejecución. Desglosado por tipo de operación. |
|
|
Número acumulado de errores de operaciones en tiempo de ejecución por tipo de operación. |
|
|
Número acumulado de operaciones en tiempo de ejecución por tipo de operación. |
|
|
Cantidad de recursos que se pueden asignar a los pods (después de reservar algunos para los daemons del sistema). |
|
|
Cantidad total de recursos disponibles para un nodo. |
|
|
Cantidad de recursos límite solicitados por contenedor. |
|
|
Cantidad de recursos límite solicitados por contenedor. |
|
|
Número de recursos de solicitud solicitados por un contenedor. |
|
|
Número de recursos de solicitud solicitados por un contenedor. |
|
|
Información sobre el propietario del pod. |
|
|
Las cuotas de recursos en Kubernetes imponen límites de uso de recursos como la CPU, la memoria y el almacenamiento dentro de los espacios de nombres. |
|
|
Métricas de uso de la CPU de un nodo, incluido el uso por núcleo y el uso total. |
|
|
Segundos que las CPU gastan en cada modo. |
|
|
La cantidad acumulada de tiempo que un nodo dedica a realizar I/O operaciones en el disco. |
|
|
La cantidad total de tiempo que el nodo dedica a realizar I/O operaciones en el disco. |
|
|
Número total de bytes que el nodo leyó de los discos. |
|
|
Número total de bytes que el nodo escribió en los discos. |
|
|
Cantidad de espacio disponible en bytes en el sistema de archivos de un nodo de un clúster de Kubernetes. |
|
|
Tamaño total del sistema de archivos del nodo. |
|
|
Promedio de carga de 1 minuto del uso de la CPU de un nodo. |
|
|
Promedio de carga de 15 minutos del uso de la CPU de un nodo. |
|
|
Promedio de carga de 5 minutos del uso de la CPU de un nodo. |
|
|
Cantidad de memoria utilizada por el sistema operativo del nodo para el almacenamiento en la caché del búfer. |
|
|
Cantidad de memoria utilizada por el sistema operativo del nodo para el almacenamiento en la caché del disco. |
|
|
Cantidad de memoria disponible para que las aplicaciones y las cachés la utilicen. |
|
|
Cantidad de memoria libre disponible en el nodo. |
|
|
Cantidad total de memoria física disponible en el nodo. |
|
|
Número total de bytes que recibe el nodo a través de la red. |
|
|
Número total de bytes que transmite el nodo a través de la red. |
|
|
Tamaño total de uso de la CPU del usuario y del sistema en segundos. |
|
|
Tamaño de la memoria residente en bytes. |
|
|
Número de solicitudes HTTP, fragmentadas por código de estado, método y host. |
|
|
Histograma agrupado en buckets de la latencia de solicitudes en segundos. Desglosado por verbo y host. |
|
|
Histograma agrupado en buckets de la duración en segundos de las operaciones de almacenamiento. |
|
|
Recuento de la duración de las operaciones de almacenamiento. |
|
|
Número acumulado de errores durante las operaciones de almacenamiento. |
|
|
Métrica que indica si el objetivo supervisado (por ejemplo, el nodo) está en funcionamiento. |
|
|
Número total de volúmenes administrados por el administrador de volúmenes. |
|
|
Número total de adiciones gestionadas por cola de trabajo. |
|
|
Profundidad actual de la cola de trabajo. |
|
|
Histograma agrupado en buckets que muestra el tiempo (en segundos) que un elemento permanece en la cola de trabajo antes de ser solicitado. |
|
|
Histograma agrupado en buckets que muestra el tiempo en segundos que se tarda en procesar un elemento de la cola de trabajo. |
Lista de alertas creadas
En las tablas siguientes se enumeran las alertas que crea esta solución. Las alertas se crean como reglas en Amazon Managed Service para Prometheus y se muestran en su espacio de trabajo de Amazon Managed Grafana.
Puede modificar las reglas, incluida la adición o eliminación de reglas, editando el archivo de configuración de reglas en su espacio de trabajo de Amazon Managed Service para Prometheus.
Estas dos alertas son alertas especiales que se administran de forma ligeramente diferente a las alertas habituales. En lugar de avisarle de un problema, le proporcionan información que se utiliza para supervisar el sistema. La descripción incluye detalles sobre cómo utilizar estas alertas.
| Alerta | Descripción y uso |
|---|---|
|
Se trata de una alerta destinada a garantizar que todo el proceso de alertas funcione. Esta alerta siempre se está activando, por lo que siempre debería activarse en Alertmanager y dirigirse siempre a un receptor. Puede integrarla con su mecanismo de notificación para enviar una notificación cuando la alerta no se active. Por ejemplo, puede utilizar la DeadMansSnitchintegración en PagerDuty. |
|
Se trata de una alerta que se utiliza para inhibir las alertas de información. Por sí solas, las alertas de nivel de información pueden ser muy ruidosas, pero son pertinentes cuando se combinan con otras alertas. Esta alerta se activa siempre que hay una alerta |
Las siguientes alertas proporcionan información o advertencias sobre el sistema.
| Alerta | Gravedad | Description (Descripción) |
|---|---|---|
|
|
warning |
La interfaz de red cambia su estado con frecuencia |
|
|
warning |
Se prevé que el sistema de archivos se quede sin espacio en las próximas 24 horas. |
|
|
critical |
Se prevé que el sistema de archivos se quede sin espacio en las próximas 4 horas. |
|
|
warning |
Al sistema de archivos le queda menos del 5 % de espacio. |
|
|
critical |
Al sistema de archivos le queda menos del 3 % de espacio. |
|
|
warning |
Se prevé que el sistema de archivos se quede sin inodos en las próximas 24 horas. |
|
|
critical |
Se prevé que el sistema de archivos se quede sin inodos en las próximas 4 horas. |
|
|
warning |
Al sistema de archivos le quedan menos del 5 % de inodos. |
|
|
critical |
Al sistema de archivos le quedan menos del 3 % de inodos. |
|
|
warning |
La interfaz de red informa de muchos errores de recepción. |
|
|
warning |
La interfaz de red informa de muchos errores de transmisión. |
|
|
warning |
El número de entradas de conntrack se acerca al límite. |
|
|
warning |
El recopilador de archivos de texto de Node Exporter no se pudo extraer. |
|
|
warning |
Se detectó un sesgo en el reloj. |
|
|
warning |
El reloj no se sincroniza. |
|
|
critical |
La matriz RAID está degradada. |
|
|
warning |
Dispositivo con errores en la matriz RAID. |
|
|
warning |
Se prevé que el núcleo agote pronto el límite de descriptores de archivos. |
|
|
critical |
Se prevé que el núcleo agote pronto el límite de descriptores de archivos. |
|
|
warning |
El nodo no está listo. |
|
|
warning |
No se puede acceder al nodo. |
|
|
info |
Kubelet está funcionando al máximo de su capacidad. |
|
|
warning |
El estado de preparación del nodo es inestable. |
|
|
warning |
El generador de eventos del ciclo de vida de Kubelet Pod tarda demasiado en volver a publicarse. |
|
|
warning |
La latencia de inicio de Kubelet Pod es demasiado alta. |
|
|
warning |
El certificado de cliente de Kubelet está a punto de caducar. |
|
|
critical |
El certificado de cliente de Kubelet está a punto de caducar. |
|
|
warning |
El certificado del servidor de Kubelet está a punto de caducar. |
|
|
critical |
El certificado del servidor de Kubelet está a punto de caducar. |
|
|
warning |
Kubelet no ha podido renovar su certificado de cliente. |
|
|
warning |
Kubelet no ha podido renovar su certificado de servidor. |
|
|
critical |
El objetivo desapareció de la detección del objetivo de Prometheus. |
|
|
warning |
Se están ejecutando diferentes versiones semánticas de los componentes de Kubernetes. |
|
|
warning |
El cliente del servidor de API de Kubernetes está experimentando errores. |
|
|
warning |
El certificado de cliente está a punto de caducar. |
|
|
critical |
El certificado de cliente está a punto de caducar. |
|
|
warning |
La API agregada de Kubernetes ha notificado errores. |
|
|
warning |
La API agregada de Kubernetes está inactiva. |
|
|
critical |
El objetivo desapareció de la detección del objetivo de Prometheus. |
|
|
warning |
El apiserver de Kubernetes ha cancelado las solicitudes entrantes de {{ $value | humanizePercentage }}. |
|
|
critical |
El volumen persistente se está llenando. |
|
|
warning |
El volumen persistente se está llenando. |
|
|
critical |
Los inodos de volumen persistente se están llenando. |
|
|
warning |
Los inodos de volumen persistente se están llenando. |
|
|
critical |
El volumen persistente tiene problemas con el aprovisionamiento. |
|
|
warning |
El clúster tiene un exceso de solicitudes de recursos de CPU comprometidas. |
|
|
warning |
El clúster tiene un exceso de solicitudes de recursos de memoria comprometidas. |
|
|
warning |
El clúster tiene un exceso de solicitudes de recursos de CPU comprometidas. |
|
|
warning |
El clúster tiene un exceso de solicitudes de recursos de memoria comprometidas. |
|
|
info |
La cuota de espacio de nombres se va a llenar. |
|
|
info |
La cuota de espacio de nombres se ha utilizado en su totalidad. |
|
|
warning |
La cuota de espacio de nombres ha superado los límites. |
|
|
info |
Los procesos experimentan una limitación elevada de la CPU. |
|
|
warning |
El pod se bloquea en bucle. |
|
|
warning |
El pod lleva más de 15 minutos sin estar preparado. |
|
|
warning |
La generación de implementaciones no coincide debido a una posible reversión. |
|
|
warning |
La implementación no ha coincidido con el número de réplicas esperado. |
|
|
warning |
StatefulSet no ha coincidido con el número esperado de réplicas. |
|
|
warning |
StatefulSet discordancia generacional debido a una posible reversión |
|
|
warning |
StatefulSet la actualización no se ha lanzado. |
|
|
warning |
DaemonSet el lanzamiento está bloqueado. |
|
|
warning |
El contenedor de pods lleva en espera más de 1 hora. |
|
|
warning |
DaemonSet los pods no están programados. |
|
|
warning |
DaemonSet los pods están mal programados. |
|
|
warning |
El trabajo no se completó a tiempo. |
|
|
warning |
No se pudo completar el trabajo. |
|
|
warning |
El HPA no ha coincidido con el número de réplicas deseado. |
|
|
warning |
El HPA se ejecuta al máximo de réplicas |
|
|
critical |
kube-state-metrics está experimentando errores en las operaciones de enumeración. |
|
|
critical |
kube-state-metrics está experimentando errores en las operaciones de observación. |
|
|
critical |
La partición de kube-state-metrics está mal configurada. |
|
|
critical |
Faltan las particiones de kube-state-metrics. |
|
|
critical |
El servidor de API está consumiendo demasiados errores presupuestados. |
|
|
critical |
El servidor de API está consumiendo demasiados errores presupuestados. |
|
|
warning |
El servidor de API está consumiendo demasiados errores presupuestados. |
|
|
warning |
El servidor de API está consumiendo demasiados errores presupuestados. |
|
|
warning |
Uno o más objetivos están inactivos. |
|
|
critical |
El clúster Etcd tiene miembros insuficientes. |
|
|
warning |
Número elevado de cambios de líder en el clúster de etcd. |
|
|
critical |
El clúster de etcd no tiene líder. |
|
|
warning |
Número elevado de solicitudes de gRPC fallidas en el clúster de etcd. |
|
|
critical |
Las solicitudes de gRPC del clúster de etcd son lentas. |
|
|
warning |
La comunicación entre los miembros del clúster de etcd es lenta. |
|
|
warning |
Número elevado de propuestas fallidas en el clúster de etcd. |
|
|
warning |
El clúster de etcd tiene altas duraciones de sincronización. |
|
|
warning |
El clúster de etcd tiene duraciones de confirmación superiores a las esperadas. |
|
|
warning |
El clúster de etcd tiene solicitudes HTTP fallidas. |
|
|
critical |
Número elevado de solicitudes HTTP fallidas en el clúster de etcd. |
|
|
warning |
Las solicitudes de HTTP del clúster de etcd son lentas. |
|
|
warning |
El reloj de host no se sincroniza. |
|
|
warning |
Se detectó la eliminación de la OOM del host. |
Resolución de problemas
Hay algunas cosas que pueden provocar un error en la configuración del proyecto. Asegúrese de revisar lo siguiente.
-
Debe cumplir todos los requisitos previos antes de instalar la solución.
-
El clúster debe tener al menos un nodo antes de intentar crear la solución o acceder a las métricas.
-
Su clúster de Amazon EKS debe tener instalados los complementos
AWS CNI,CoreDNSykube-proxy. Si no están instalados, la solución no funcionará correctamente. Se instalan de forma predeterminada al crear el clúster a través de la consola. Es posible que tengas que instalarlos si el clúster se creó mediante un AWS SDK. -
Se agotó el tiempo de espera para la instalación de los pods de Amazon EKS. Esto puede ocurrir si no hay suficiente capacidad de nodos disponible. Estos problemas se deben a varias causas, entre las que se incluyen las siguientes:
-
El clúster de Amazon EKS se inicializó con Fargate y no con Amazon EC2. Este proyecto requiere Amazon EC2.
-
Los nodos tienen taints y, por lo tanto, no están disponibles.
Puede utilizar
kubectl describe nodepara comprobar las taints. Luego,NODENAME| grep Taintskubectl taint nodepara eliminar las taints. Asegúrese de incluirNODENAMETAINT_NAME--después del nombre de la taint. -
Los nodos han alcanzado el límite de capacidad. En este caso, puede crear un nodo nuevo o aumentar la capacidad.
-
-
No ve ningún panel en Grafana: está utilizando un ID de espacio de trabajo de Grafana incorrecto.
Ejecute el siguiente comando para obtener información acerca de Grafana:
kubectl describe grafanas external-grafana -n grafana-operatorPuede comprobar los resultados para ver la URL del espacio de trabajo correcta. Si no es la que esperaba, vuelva a implementarla con el ID de espacio de trabajo correcto.
Spec: External: API Key: Key: GF_SECURITY_ADMIN_APIKEY Name: grafana-admin-credentials URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Status: Admin URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Dashboards: ... -
No ve ningún panel en Grafana: está utilizando una clave de API caducada.
Para detectar esto, tendrá que usar el operador grafana y comprobar si hay errores en los registros. Obtenga el nombre del operador de Grafana con este comando:
kubectl get pods -n grafana-operatorEsto devolverá el nombre del operador, por ejemplo:
NAME READY STATUS RESTARTS AGEgrafana-operator-1234abcd5678ef901/1 Running 0 1h2mUtilice el nombre del operador en el siguiente comando:
kubectl logsgrafana-operator-1234abcd5678ef90-n grafana-operatorLos mensajes de error como los siguientes indican que la clave de API ha caducado:
ERROR error reconciling datasource {"controller": "grafanadatasource", "controllerGroup": "grafana.integreatly.org", "controllerKind": "GrafanaDatasource", "GrafanaDatasource": {"name":"grafanadatasource-sample-amp","namespace":"grafana-operator"}, "namespace": "grafana-operator", "name": "grafanadatasource-sample-amp", "reconcileID": "72cfd60c-a255-44a1-bfbd-88b0cbc4f90c", "datasource": "grafanadatasource-sample-amp", "grafana": "external-grafana", "error": "status: 401, body: {\"message\":\"Expired API key\"}\n"} github.com/grafana-operator/grafana-operator/controllers.(*GrafanaDatasourceReconciler).ReconcileEn este caso, cree una nueva clave de API y vuelva a implementar la solución. Si el problema persiste, puede forzar la sincronización mediante el siguiente comando antes de volver a implementarlo:
kubectl delete externalsecret/external-secrets-sm -n grafana-operator -
Instalaciones de CDK: falta el parámetro SSM. Si ve un error similar al siguiente, ejecute
cdk bootstrapy vuelva a intentarlo.Deployment failed: Error: aws-observability-solution-eks-infra-$EKS_CLUSTER_NAME: SSM parameter /cdk-bootstrap/xxxxxxx/version not found. Has the environment been bootstrapped? Please run 'cdk bootstrap' (see https://docs.aws.amazon.com/cdk/latest/ guide/bootstrapping.html) -
La implementación puede fallar si el proveedor de OIDC ya existe. Aparecerá un error como el siguiente (en este caso, para las instalaciones de CDK):
| CREATE_FAILED | Custom::AWSCDKOpenIdConnectProvider | OIDCProvider/Resource/Default Received response status [FAILED] from custom resource. Message returned: EntityAlreadyExistsException: Provider with url https://oidc.eks.REGION.amazonaws.com/id/PROVIDER IDalready exists.En ese caso, vaya al portal de IAM, elimine el proveedor de OIDC e inténtelo de nuevo.
-
Instalaciones de Terraform: aparece un mensaje de error que incluye
cluster-secretstore-sm failed to create kubernetes rest client for update of resourceyfailed to create kubernetes rest client for update of resource.Este error suele indicar que el operador de secretos externos no está instalado o habilitado en su clúster de Kubernetes. Se instala como parte de la implementación de la solución, pero a veces no está listo cuando la solución lo necesita.
Puede verificar que está instalado mediante el siguiente comando:
kubectl get deployments -n external-secretsSi está instalado, el operador puede tardar algún tiempo en estar completamente listo para usarse. Puede comprobar el estado de las definiciones de recursos personalizadas (CRD) necesarias mediante la ejecución del siguiente comando:
kubectl get crds|grep external-secretsEste comando debería enumerar las CRD relacionadas con el operador de secretos externos, incluidos
clustersecretstores.external-secrets.ioyexternalsecrets.external-secrets.io. Si no aparecen en la lista, espere unos minutos y revise de nuevo.Una vez registradas las CRD, puede volver a ejecutar
terraform applypara implementar la solución.
