Administrador de incidentes de AWS Systems Manager ya no está abierto a nuevos clientes. Los clientes existentes pueden seguir utilizando el servicio con normalidad. Para obtener más información, consulte Cambio en la disponibilidad de Administrador de incidentes de AWS Systems Manager.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Ciclo de vida del incidente en Incident Manager
Administrador de incidentes de AWS Systems Manager proporciona un step-by-step marco basado en las mejores prácticas para identificar incidentes y reaccionar ante ellos, como las interrupciones del servicio o las amenazas a la seguridad. El objetivo principal de Incident Manager es ayudar a restablecer la normalidad de los servicios o aplicaciones afectados lo antes posible mediante una solución completa de administración del ciclo de vida de los incidentes.
Como se muestra en la siguiente ilustración, Incident Manager proporciona herramientas y mejores prácticas para cada fase del ciclo de vida de los incidentes:
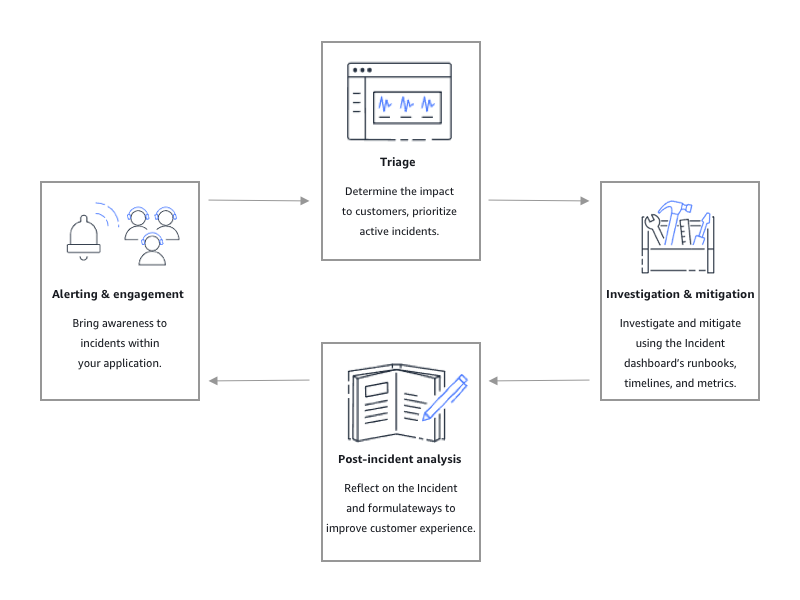
Alerta e intervención
La fase de alerta e intervención del ciclo de vida del incidente se centra en dar a conocer los incidentes dentro de sus aplicaciones y servicios. Esta fase comienza antes de que se detecte un incidente y requiere un profundo conocimiento de sus aplicaciones. Puedes usar CloudWatchlas métricas de Amazon para monitorear los datos sobre el rendimiento de tus aplicaciones o usar Amazon EventBridge para agregar alertas de diferentes fuentes, aplicaciones y servicios. Después de haber configurado el monitoreo de sus aplicaciones, puede comenzar a alertar sobre las métricas que se desvían de la norma histórica. Para obtener más información sobre las prácticas recomendadas de monitoreo, consulte Supervisión.
Para apoyar el diagnóstico de incidentes de los respondedores, puede habilitar la característica Resultados en Incident Manager. Los resultados son información sobre AWS CodeDeploy las implementaciones y las actualizaciones de la AWS CloudFormation pila que se produjeron en torno al momento de un incidente. Disponer de esta información reduce el tiempo necesario para evaluar las causas potenciales, lo que puede reducir el tiempo medio de recuperación (MTTR) de un incidente.
Ahora que está monitoreando los incidentes en sus aplicaciones, puede definir un plan de respuesta a incidentes a fin de utilizarlo durante un incidente. Para obtener más información sobre la creación de planes de respuesta, consulte Creación y configuración de planes de respuesta en Incident Manager. EventBridge Los eventos o CloudWatch alarmas de Amazon pueden crear automáticamente un incidente utilizando planes de respuesta como plantilla. Para obtener más información sobre la creación de incidentes, consulte Crear incidentes de forma automática o manual en Incident Manager.
Los planes de respuesta lanzan planes de escalada y planes de participación relacionados para atraer a los primeros respondedores al incidente. Para obtener más información sobre la creación de planes de escalada, consulte Creación de un plan de escalada. Simultáneamente, Amazon Q Developer en las aplicaciones de chat notifica a los socorristas mediante un canal de chat que los dirige a la página de detalles del incidente. Mediante el canal de chat y los detalles del incidente, el equipo puede comunicar y clasificar un incidente. Para obtener más información sobre la configuración de canales de chat en Incident Manager, consulte Tarea 2: Crear un canal de chat en Amazon Q Developer en aplicaciones de chat.
Triaje
El triaje es cuando los primeros respondedores intentan determinar el impacto para los clientes. La vista de detalles del incidente en la consola de Incident Manager proporciona a los respondedores líneas temporales y métricas para ayudarles a evaluar el incidente. La evaluación del impacto de un incidente también sienta las bases para el tiempo de respuesta, la resolución y la comunicación del incidente. Los respondedores priorizan los incidentes utilizando clasificaciones de impacto del 1 (Crítico) al 5 (Sin impacto).
Su organización puede definir el alcance exacto de cada clasificación de impacto como prefiera. En la tabla siguiente se ofrecen ejemplos de cómo podría definirse normalmente cada nivel de impacto.
| Código del impacto | Nombre del impacto | Ejemplo de alcance definido |
|---|---|---|
1 |
Critical |
Fallo total de una aplicación que repercute en la mayoría de los clientes. |
2 |
High |
Fallo total de una aplicación que repercute en un subconjunto de clientes. |
3 |
Medium |
Fallo parcial de una aplicación que repercute en los clientes. |
4 |
Low |
Fallos intermitentes que tienen un impacto limitado en los clientes. |
5 |
No Impact |
Los clientes no se ven actualmente afectados, pero es necesario tomar medidas urgentes para evitar el impacto. |
Investigación y mitigación
La vista de detalles del incidente proporciona a su equipo manuales de procedimientos, líneas temporales y métricas. Para obtener información sobre cómo puede trabajar con un incidente, consulte Visualización de los detalles del incidente en la consola.
Los manuales de procedimientos suelen proporcionar pasos de investigación y pueden extraer datos o intentar soluciones de uso común de forma automática. Los manuales de procedimientos también proporcionan pasos claros y repetibles que su equipo ha encontrado útiles para mitigar incidentes. La pestaña “Manual de procedimientos” se centra en el paso actual del manual de procedimientos y muestra los pasos pasados y futuros.
Incident Manager se integra con Systems Manager Automation para crear manuales de procedimientos. Utilice los manuales de procedimientos para realizar cualquiera de las siguientes acciones:
-
Gestione las instancias y los recursos AWS
-
Ejecutar scripts de forma automática
-
Administre CloudFormation los recursos
Para obtener más información sobre los tipos de acciones admitidos, consulte Referencia de acciones de Systems Manager Automation en la Guía del usuario de AWS Systems Manager .
La pestaña Línea temporal muestra las acciones que se han realizado. La línea temporal registra cada acción con una marca de tiempo y detalles creados automáticamente. Para añadir eventos personalizados a la línea temporal, consulte la sección Plazo en la página Detalles del incidente de esta guía del usuario.
La pestaña Diagnóstico muestra métricas introducidas tanto de forma automática como manual. Esta vista proporciona información valiosa sobre las actividades de su aplicación durante un incidente.
La pestaña Participaciones le permite añadir contactos adicionales al incidente y ayuda a proporcionar los recursos para que el contacto implicado se ponga al día rápidamente una vez involucrado en el incidente. Los contactos se comprometen a través de planes de escalada o planes de participación personal definidos.
Mediante un canal de chat, puede interactuar directamente con su incidente y con otros respondedores de su equipo. Al utilizar Amazon Q Developer en las aplicaciones de chat, puede configurar los canales de chat en. Slack, Microsoft Teamsy Amazon Chime. In Slack y Microsoft Teams canales, los socorristas pueden interactuar con los incidentes directamente desde el canal de chat mediante una serie de ssm-incidents comandos. Para obtener más información, consulte Interacción a través del canal de chat.
Análisis post-incidente
Incident Manager proporciona un marco para reflexionar sobre un incidente, tomar las medidas necesarias para evitar que se repita en el futuro y mejorar las actividades de respuesta a incidentes en general. Las mejoras pueden incluir:
-
Cambios en las aplicaciones implicadas en un incidente. Su equipo puede utilizar este tiempo para mejorar el sistema y hacerlo más tolerante a los fallos.
-
Cambios en un plan de respuesta a incidentes. Tómese el tiempo necesario para incorporar las lecciones aprendidas.
-
Cambios en los manuales de procedimientos. Su equipo puede profundizar en los pasos necesarios para la resolución y en los pasos que usted puede automatizar.
-
Cambios en las alertas. Tras un incidente, su equipo podría haber observado puntos críticos en las métricas que puede utilizar para alertar con antelación al equipo sobre un incidente.
Incident Manager facilita estas mejoras potenciales a través de un conjunto de preguntas de análisis post-incidente y elementos de acción junto con la línea temporal del incidente. Para obtener más información sobre la mejora a través del análisis, consulte Realización de un análisis post-incidente en Incident Manager.
