Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Preparación para incidentes en Incident Manager
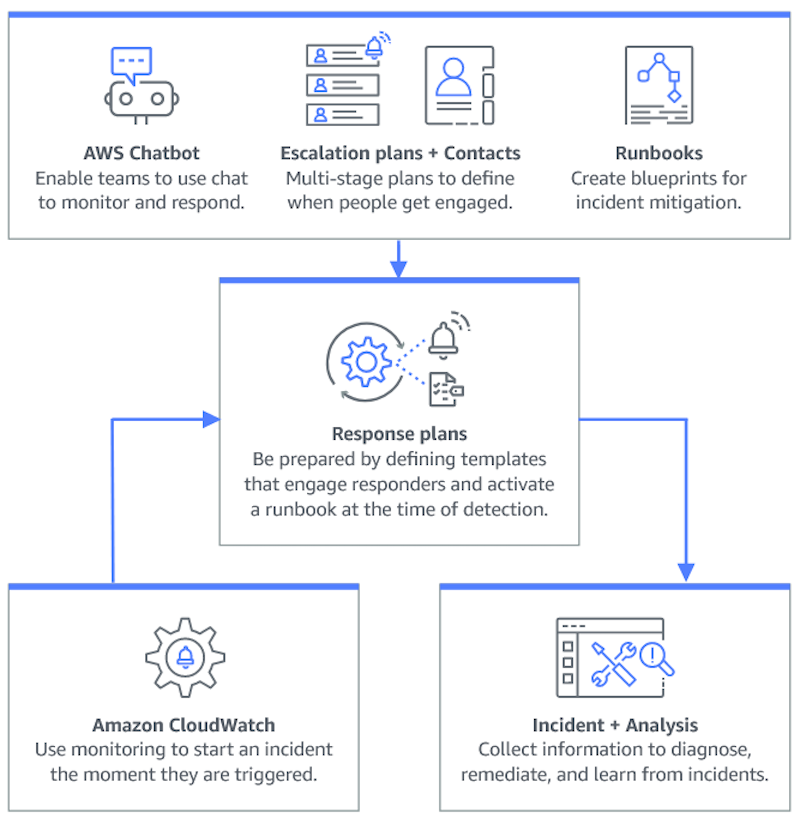
La planificación de un incidente comienza mucho antes del ciclo de vida del incidente. Como se muestra en la siguiente ilustración, antes de empezar a responder a los incidentes, hay que prepararse configurando los canales de chat, creando planes de escalamiento, especificando los contactos y determinando los manuales de automatización que se van a utilizar en la respuesta a los incidentes. A continuación, utilice un plan de respuesta que especifique cómo se lleva a cabo la supervisión y si las respuestas están automatizadas. Una vez completada la remediación, puede analizar el incidente y la respuesta al incidente para perfeccionar aún más su plan de respuesta para futuros incidentes.
Temas
- Monitorización
- Configuración de conjuntos de replicación y resultados en Incident Manager
- Creación y configuración de contactos en Incident Manager
- Gestión de las rotaciones de personal de respuesta con horarios de guardia en Incident Manager
- Creación de un plan de escalamiento para la participación del personal de respuesta en Incident Manager
- Creación e integración de canales de chat para el personal de respuesta en Incident Manager
- Integración de los manuales de automatización de Systems Manager en Incident Manager para la solución de incidentes
- Creación y configuración de planes de respuesta en Incident Manager
- Identificar las posibles causas de los incidentes de otros servicios como «hallazgos» en Incident Manager
Monitorización
Supervisar el estado de las aplicaciones AWS alojadas es clave para garantizar el tiempo de actividad y el rendimiento de las aplicaciones. A la hora de determinar las soluciones de monitoreo, tenga en cuenta lo siguiente:
-
Criticidad de la característica: si el sistema fallara, ¿cuán crítico sería el impacto para los usuarios intermedios?
-
Comunalidad de los fallos: con qué frecuencia falla un sistema; los sistemas que requieren una intervención frecuente deben ser monitoreados de cerca.
-
Aumento de la latencia: cuánto ha aumentado o disminuido el tiempo necesario para completar una tarea.
-
Métricas del lado del cliente vs. métricas del lado del servidor: si existe una discrepancia entre las métricas relacionadas en el cliente y en el servidor.
-
Fallos de dependencia: fallos para los que su equipo puede y debería prepararse.
Después de crear planes de respuesta, puede utilizar sus soluciones de monitoreo para hacer un seguimiento automático de los incidentes en el momento en que se produzcan en su entorno. Para obtener más información sobre el seguimiento y la creación de incidentes, consulte Visualización de los detalles del incidente en la consola de Incident Manager.
