Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Casos de uso
A continuación se presentan algunos casos de uso de búsqueda vectorial.
Generación aumentada de recuperación (RAG)
La generación aumentada de recuperación (RAG) aprovecha la búsqueda vectorial para recuperar pasajes relevantes de un gran corpus de datos para aumentar modelo de lenguaje grande (LLM). En concreto, un codificador incrusta el contexto de entrada y la consulta de búsqueda en vectores y, a continuación, utiliza la búsqueda aproximada de vecino más cercano para encontrar pasajes semánticamente similares. Estos pasajes recuperados se concatenan con el contexto original para proporcionar información adicional pertinente al LLM y devolver una respuesta más precisa al usuario.

Caché semántica duradera
El almacenamiento en caché semántico es un proceso para reducir los costos computacionales mediante el almacenamiento de los resultados anteriores de la FM. Al reutilizar los resultados anteriores de inferencias anteriores en lugar de volver a calcularlos, el almacenamiento semántico en caché reduce la cantidad de cálculos necesarios durante la inferencia mediante el. FMs MemoryDB permite un almacenamiento en caché semántico duradero, lo que evita la pérdida de datos de inferencias anteriores. Esto permite que sus aplicaciones de IA generativa respondan en cuestión de milisegundos de un solo dígito a preguntas anteriores semánticamente similares, al tiempo que reduce los costes al evitar inferencias de LLM innecesarias.

Resultado de la búsqueda semántica: si la consulta de un cliente es semánticamente similar en función de una puntuación de similitud definida con una pregunta anterior, la memoria intermedia del FM (MemoryDB) devolverá la respuesta a la pregunta anterior en el paso 4 y no llamará al FM en los pasos 3. Esto evitará la latencia del modelo fundacional (FM) y los costos incurridos, lo que permitirá al cliente disfrutar de una experiencia más rápida.
Fallo en la búsqueda semántica: si la consulta de un cliente no es semánticamente similar en función de una puntuación de similitud definida con respecto a una consulta anterior, el cliente llamará al FM para responderle en el paso 3a. La respuesta generada por el FM se almacenará luego como vector en MemoryDB para consultas futuras (paso 3b) a fin de minimizar los costos del FM en preguntas semánticamente similares. En este flujo, no se invocaría el paso 4 porque no había una pregunta semánticamente similar para la consulta original.
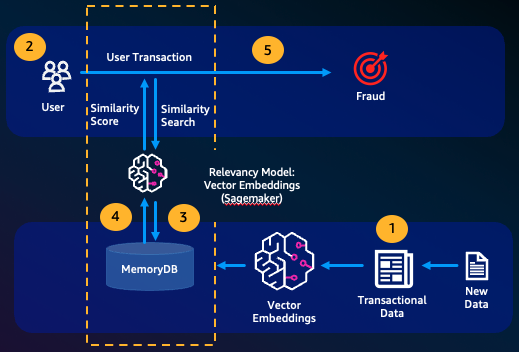
Detección de fraudes
La detección de fraudes, una forma de detección de anomalías, representa las transacciones válidas como vectores al tiempo que compara las representaciones vectoriales de las nuevas transacciones netas. El fraude se detecta cuando estas nuevas transacciones netas tienen una baja similitud con los vectores que representan los datos transaccionales válidos. Esto permite detectar el fraude al modelar el comportamiento normal, en lugar de intentar predecir todas las posibles instancias de fraude. MemoryDB permite a las organizaciones hacerlo en períodos de alto rendimiento, con un mínimo de falsos positivos y una latencia de milisegundos de un solo dígito.
Otros casos de uso
Los motores de recomendación pueden encontrar productos o contenidos similares para los usuarios al representar los elementos como vectores. Los vectores se crean mediante el análisis de atributos y patrones. Según los patrones y atributos del usuario, se pueden recomendar nuevos elementos invisibles a los usuarios al encontrar los vectores más similares que ya hayan sido puntuados positivamente y alineados con el usuario.
Los motores de búsqueda de documentos representan los documentos de texto como vectores densos de números que capturan su significado semántico. En el momento de la búsqueda, el motor convierte una consulta de búsqueda en un vector y encuentra los documentos con los vectores más similares a la consulta mediante una búsqueda aproximada del vecino más cercano. Este enfoque de similitud vectorial permite coincidir los documentos en función del significado en lugar de simplemente hacer coincidir las palabras clave.
