Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Mejores prácticas operativas para Amazon OpenSearch Service
Este capítulo proporciona las mejores prácticas para operar los dominios de Amazon OpenSearch Service e incluye pautas generales que se aplican a muchos casos de uso. Cada carga de trabajo es única, con características únicas, por lo que ninguna recomendación genérica es exactamente adecuada para cada caso de uso. La práctica general más importante consiste en implementar, probar y ajustar sus dominios en un ciclo continuo para encontrar la configuración, la estabilidad y el costo óptimos para su carga de trabajo.
Temas
Monitorización y alertas
Las siguientes prácticas recomendadas se aplican a la supervisión de sus dominios OpenSearch de servicio.
Configure CloudWatch las alarmas
OpenSearch El servicio emite métricas de rendimiento a Amazon CloudWatch. Revisa periódicamente las métricas de tu clúster e instancia y configura las CloudWatch alarmas recomendadas en función del rendimiento de tu carga de trabajo.
Habilitación de la publicación de registros
OpenSearch El servicio expone los registros de OpenSearch errores, los registros lentos de búsqueda, los registros lentos de indexación y los registros de auditoría en Amazon CloudWatch Logs. Los registros lentos de búsqueda, los registros lentos de índice y los registros de errores son útiles para la resolución de problemas de rendimiento y estabilidad. Los registros de auditoría, que solo están disponibles si habilita control de acceso preciso, realizan un seguimiento de la actividad del usuario. Para obtener más información, consulte los registros
Los registros lentos de búsqueda e indexación de registros lentos son una herramienta importante para comprender y solucionar problemas del rendimiento de sus operaciones de búsqueda e indexación. Habilite la entrega lenta de registros de búsqueda e índice para todos los dominios de producción. También debe configurar los umbrales de registro; de lo contrario, CloudWatch no capturará los registros.
Estrategia de particiones
Los fragmentos distribuyen la carga de trabajo entre los nodos de datos de su OpenSearch dominio de servicio. Los índices configurados correctamente pueden ayudar a mejorar el rendimiento general del dominio.
Cuando envías datos al OpenSearch Servicio, los envías a un índice. Un índice es análogo a una tabla de base de datos, con documentos como las filas y campos como las columnas. Al crear el índice, indica OpenSearch cuántos fragmentos principales desea crear. Los fragmentos principales son particiones independientes del conjunto de datos completo. OpenSearch El servicio distribuye automáticamente los datos entre los fragmentos principales de un índice. También puede configurar réplicas del índice. Cada partición de réplica incluye un conjunto completo de copias de las particiones principales de ese índice.
OpenSearch El servicio mapea los fragmentos de cada índice en los nodos de datos del clúster. Garantiza que las particiones principales y de réplica del índice residan en nodos de datos diferentes. La primera réplica garantiza que tenga dos copias de los datos en el índice. Siempre debe usar al menos una réplica. Las réplicas adicionales proporcionan redundancia y capacidad de lectura adicionales.
OpenSearch envía solicitudes de indexación a todos los nodos de datos que contienen fragmentos que pertenecen al índice. Envía solicitudes de indexación primero a los nodos de datos que contienen particiones principales y, después, a los nodos de datos que contienen particiones de réplica. El nodo coordinador dirige las solicitudes de búsqueda, ya sea a una partición principal o a una réplica, para todas las particiones que pertenecen al índice.
Por ejemplo, para un índice con cinco fragmentos principales y una réplica para cada uno, cada solicitud de indexación afecta a 10 fragmentos. En contraste, las solicitudes de búsqueda se envían a las particiones n, donde n es el número de particiones principales. Para un índice con cinco particiones principales y una réplica, cada consulta de búsqueda toca cinco particiones (principales o réplicas) de ese índice.
Determinar los recuentos de particiones y nodos de datos
Utilice las siguientes prácticas recomendadas para determinar los recuentos de nodos de datos y particiones para su dominio.
Tamaño de las particiones: el tamaño de los datos en el disco es un resultado directo del tamaño de los datos de origen y cambia a medida que se indexan más datos. La relación de fuente a índice puede variar enormemente, de 1:10 a 10:1 o más, pero por lo general es de alrededor de 1:1.10. Puede usar esa relación para predecir el tamaño del índice en el disco. Puede también indexar algunos datos y recuperar los tamaños reales del índice para determinar la relación de la carga de trabajo. Después de tener un tamaño de índice previsto, establezca un recuento de particiones para que cada partición tenga entre 10 y 30 GiB (para cargas de trabajo de búsqueda) o entre 30 y 50 GiB (para cargas de trabajo de registros). 50 GiB debería ser el máximo; asegúrese de planificar el crecimiento.
Recuento de particiones: la distribución de particiones a los nodos de datos tiene un gran impacto en el rendimiento de un dominio. Cuando tenga índices con múltiples particiones, procure que la cantidad de particiones sea un múltiplo de la cantidad de nodos de datos. Esto ayuda a garantizar que las particiones se distribuyan de manera uniforme entre los nodos de datos y evita los nodos activos. Por ejemplo, si tiene 12 particiones principales, el recuento de nodos de datos debe ser 2, 3, 4, 6 o 12. Sin embargo, el recuento de particiones es secundario al tamaño de la partición; si tiene 5 GiB de datos, debe seguir utilizando una sola partición.
Particiones por nodo de datos: el número total de particiones que puede contener un nodo es proporcional a la memoria en montón de máquina virtual Java (JVM) del nodo. Trate de obtener 25 particiones o menos por GiB de memoria en montón. Por ejemplo, un nodo con 32 GiB de memoria en montón no debe contener más de 800 particiones. Si bien la distribución de las particiones puede variar en función de los patrones de carga de trabajo, hay un límite de 1000 particiones por nodo para Elasticsearch y de OpenSearch 1,1 a 2,15 y 4000 para las versiones de 2,17 o superiores. OpenSearch La cat/allocation
Proporción de partición a CPU: cuando una partición participa en una solicitud de indexación o búsqueda, utiliza una vCPU para procesar la solicitud. Como práctica recomendada, utilice un punto de escala inicial de 1,5 vCPU por partición. Si su tipo de instancia tiene 8 vCPU, configure el recuento de nodos de datos para que cada nodo no tenga más de seis particiones. Tenga en cuenta que se trata de una aproximación. Asegúrese de probar la carga de trabajo y escalar el clúster en consecuencia.
Para obtener recomendaciones sobre el volumen de almacenamiento, el tamaño de las particiones y el tipo de instancia, consulte los recursos siguientes:
Evite el sesgo de almacenamiento
El sesgo de almacenamiento ocurre cuando uno o más nodos de un clúster contienen una mayor proporción de almacenamiento para uno o más índices que los demás. Los indicios de que hay sesgo de almacenamiento incluyen utilización desigual de la CPU, latencia intermitente y desigual, y colocación en cola desigual en los nodos de datos. Para determinar si tiene problemas de sesgo, consulte las siguientes secciones de solución de problemas:
Stability
Las siguientes prácticas recomendadas se aplican para mantener un dominio de OpenSearch servicio estable y en buen estado.
Manténgase al día con OpenSearch
Actualizaciones del software del servicio
OpenSearch El servicio publica periódicamente actualizaciones de software que añaden funciones o mejoran sus dominios. Las actualizaciones no cambian la versión del motor de búsqueda OpenSearch ni la de Elasticsearch. Te recomendamos programar una hora periódica para ejecutar la operación de la DescribeDomainAPI e iniciar una actualización del software del UpdateStatus servicio, si es así. ELIGIBLE Si no actualizas tu dominio dentro de un período de tiempo determinado (normalmente dos semanas), el OpenSearch Servicio realizará la actualización automáticamente.
OpenSearch actualizaciones de versión
OpenSearch El servicio añade periódicamente soporte para las versiones mantenidas por la comunidad de OpenSearch. Actualice siempre a las OpenSearch versiones más recientes cuando estén disponibles.
OpenSearch El servicio actualiza simultáneamente OpenSearch tanto los OpenSearch paneles como los de Elasticsearch (o Elasticsearch y Kibana si tu dominio ejecuta un motor antiguo). Si el clúster tiene nodos maestros dedicados, las actualizaciones se completan sin tiempo de inactividad. De lo contrario, es posible que el clúster deje de responder durante varios segundos después de la actualización mientras elige un nodo principal. OpenSearch Es posible que los paneles no estén disponibles durante una parte o durante toda la actualización.
Hay dos formas de actualizar un dominio:
-
In-place actualización: esta opción es más sencilla porque se mantiene el mismo clúster.
-
Snapshot/restore actualización: esta opción es adecuada para probar nuevas versiones en un clúster nuevo o para migrar entre clústeres.
Independientemente del proceso de actualización que utilice, recomendamos mantener un dominio que sea únicamente para desarrollo y pruebas y actualizarlo a la nueva versión antes de actualizar el dominio de producción. Para el tipo de implementación, seleccione Desarrollo y pruebas cuando cree el dominio de prueba. Asegúrese de actualizar todos los clientes a versiones compatibles inmediatamente después de la actualización del dominio.
Cómo mejorar el rendimiento de las instantáneas
Para evitar que la instantánea se bloquee durante el procesamiento, el tipo de instancia del nodo maestro dedicado debe coincidir con el número de particiones. Para más información, consulte Elección de tipos de instancias para nodos principales dedicados. Además, cada nodo no debe tener más de las 25 particiones recomendadas por cada GiB de memoria dinámica de Java. Para más información, consulte Selección del número de particiones.
Habilite los nodos maestros dedicados
Nodos maestros dedicados para mejorar la estabilidad de los clústeres. Un nodo maestro dedicado realiza tareas de administración de clústeres, pero no contiene datos de índice ni responde a las solicitudes de los clientes. Al asumir de este modo las tareas de administración de clústeres, aumenta la estabilidad de su dominio y hace posible que se lleven a cabo algunos cambios de configuración sin tiempo de inactividad.
Habilite y utilice tres nodos maestros dedicados para lograr una estabilidad óptima del dominio en tres zonas de disponibilidad. Al realizar la implementación Multi-AZ con Standby, se configuran tres nodos maestros dedicados por usted. Para obtener recomendaciones de tipos de instancias, consulte Elección de tipos de instancias para nodos principales dedicados.
Implemente en varias zonas de disponibilidad
Para evitar que se pierdan datos y minimizar el tiempo de inactividad del clúster en caso de que se produzca una interrupción del servicio, puede distribuir los nodos en dos o tres zonas de disponibilidad de la misma Región de AWS. La mejor práctica es realizar la implementación Multi-AZ con Standby, que configura tres zonas de disponibilidad, con dos zonas activas y una en espera, y con dos fragmentos de réplica por índice. Esta configuración permite a OpenSearch Service distribuir los fragmentos de réplica en zonas de disponibilidad distintas a las de sus fragmentos principales correspondientes. No hay cargos por transferencia de datos entre zonas de disponibilidad para las comunicaciones de clústeres entre zonas de disponibilidad.
Las zonas de disponibilidad son ubicaciones aisladas dentro de cada región. Con una configuración de dos zonas de disponibilidad, perder una zona de disponibilidad significa que se pierde la mitad de toda la capacidad del dominio. El cambio a tres zonas de disponibilidad reduce aún más el impacto de perder una sola zona de disponibilidad.
Controle el flujo de incorporación y el almacenamiento en búfer
Recomendamos que se limite el recuento total de solicitudes mediante la operación de la API _bulk_bulk que contiene 5000 documentos que enviar 5000 solicitudes que contienen un solo documento.
Para lograr una estabilidad operativa óptima, a veces es necesario limitar o incluso detener el flujo ascendente de las solicitudes de indexación. Limitar la tasa de solicitudes de índices es un mecanismo importante para hacer frente a picos inesperados u ocasionales en las solicitudes que, de otro modo, podrían abrumar al clúster. Considere la posibilidad de crear un mecanismo de control de flujo en su arquitectura ascendente.
El siguiente diagrama muestra varias opciones de componentes para una arquitectura de incorporación de registros. Configure la capa de agregación para dejar espacio suficiente para almacenar en búfer los datos entrantes para picos de tráfico repentinos y un breve mantenimiento del dominio.
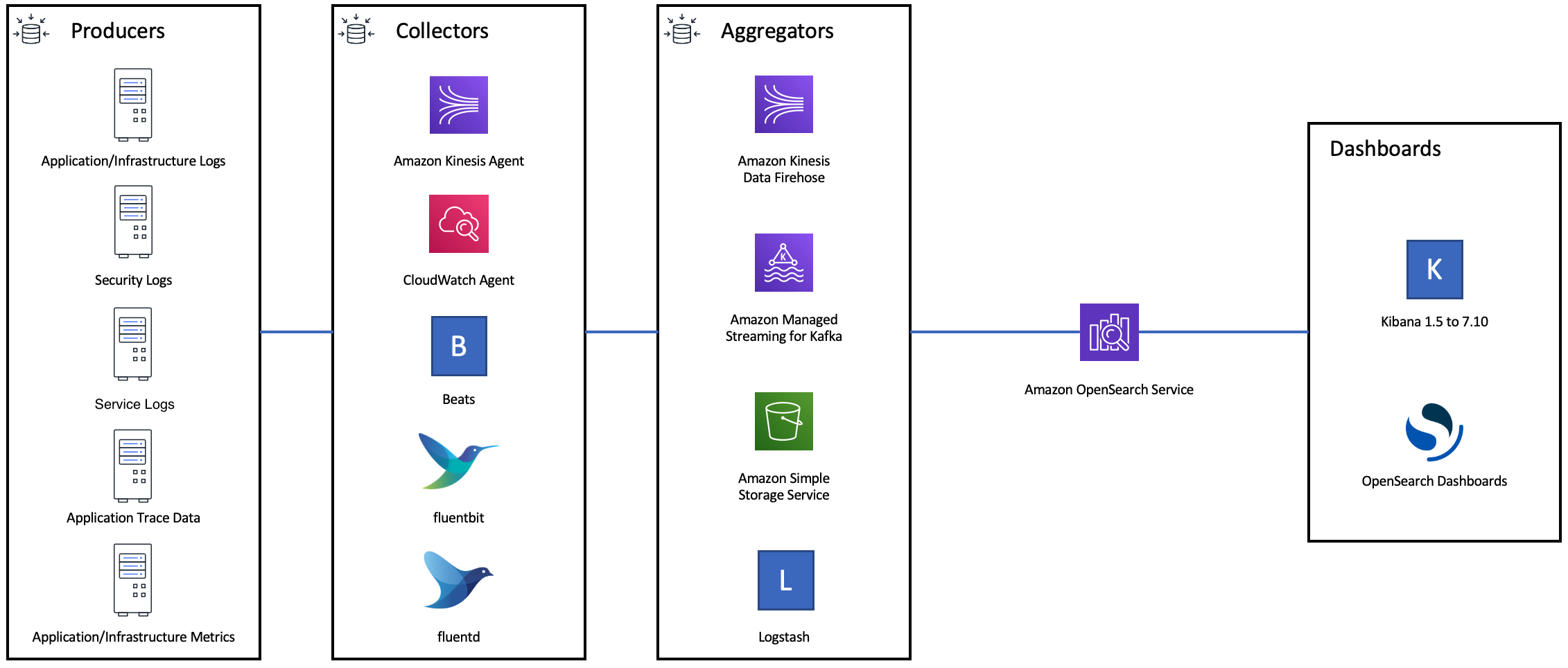
Cree asignaciones para cargas de trabajo de búsqueda
Para las cargas de trabajo de búsqueda, cree mapeosdynamic en strict para evitar la adición accidental de nuevos campos.
PUT my-index { "mappings": { "dynamic": "strict", "properties": { "title": { "type" : "text" }, "author": { "type" : "integer" }, "year": { "type" : "text" } } } }
Utilice plantillas de índice
Puedes usar una plantilla de índice
Los siguientes parámetros son útiles para configurar en plantillas:
-
Número total de particiones primarias y de réplicas
-
Intervalo de actualización (frecuencia con la que se actualizan y se realizan cambios recientes en el índice disponibles para la búsqueda)
-
Control de mapeo dinámico
-
Asignaciones de campo explícito
La siguiente plantilla de ejemplo contiene cada una de estas configuraciones:
{ "index_patterns":[ "index-*" ], "order": 0, "settings": { "index": { "number_of_shards": 3, "number_of_replicas": 1, "refresh_interval": "60s" } }, "mappings": { "dynamic": false, "properties": { "field_name1": { "type": "keyword" } } } }
Aunque cambien con poca frecuencia, tener la configuración y los mapeos definidos de forma centralizada OpenSearch es más fácil de administrar que actualizar varios clientes anteriores.
Administre los índices con la administración de estado de índice
Si administra registros o datos de serie temporal, le recomendamos que utilice Administración de estados de índice (ISM). ISM le permite automatizar las tareas regulares de administración del ciclo de vida. Con ISM, puede crear políticas que invoquen la renovación de alias de índice, tomen instantáneas de índices, muevan índices entre niveles de almacenamiento y eliminen índices antiguos. Incluso puede usar la operación sustitución
En primer lugar, establezca una política de ISM. Por ejemplo, consulte Ejemplos de política. A continuación, puede adjuntar la política a uno o más índices. Si incluye un campo de plantilla de ISM en la política, OpenSearch Service aplicará automáticamente la política a cualquier índice que coincida con el patrón especificado.
Eliminar los índices que no se utilizan
Revise periódicamente los índices de su clúster e identifique los que no estén en uso. Tome una instantánea de esos índices para que se almacenen en S3 y, a continuación, elimínelos. Cuando se eliminan los índices no utilizados, se reduce el recuento de particiones y se permite una distribución del almacenamiento de información y una utilización de recursos más equilibradas entre los nodos. Incluso cuando están inactivos, los índices consumen algunos recursos durante las actividades de mantenimiento de índices internos.
En lugar de eliminar manualmente los índices no utilizados, puede usar ISM para tomar automáticamente una instantánea y eliminar los índices después de un periodo de tiempo determinado.
Utilice varios dominios para disfrutar de una alta disponibilidad
Para lograr una alta disponibilidad más allá del 99,9 % de tiempo de actividad
Diseñe sus aplicaciones ascendentes y descendentes teniendo en cuenta la conmutación por error. Asegúrese de probar el proceso de conmutación por error junto con otros procesos de recuperación de desastres.
Desempeño
Las siguientes prácticas recomendadas se aplican para ajustar sus dominios para lograr un rendimiento óptimo.
Optimice el tamaño y la compresión de solicitudes
El tamaño masivo depende de los datos, el análisis y la configuración del clúster, pero un buen punto de partida es de 3 a 5 MiB por solicitud masiva.
Envíe solicitudes y reciba respuestas de sus OpenSearch dominios mediante la compresión gzip para reducir el tamaño de la carga útil de las solicitudes y respuestas. Puedes usar la compresión gzip con el cliente OpenSearch Python o incluir los siguientes encabezados desde el lado del cliente:
-
'Accept-Encoding': 'gzip' -
'Content-Encoding': 'gzip'
Para optimizar el tamaño de las solicitudes, comience con un tamaño de solicitud de 3 MiB. Luego, aumente lentamente el tamaño de la solicitud hasta que el desempeño de la indexación deje de mejorar.
nota
Para habilitar la compresión gzip en dominios que ejecutan Elasticsearch versión 6.x, debe establecer http_compression.enabled a nivel de clúster. Esta configuración se cumple de forma predeterminada en las versiones 7.x de Elasticsearch y en todas las versiones de. OpenSearch
Reduzca el tamaño de las respuestas de solicitudes masivas
Para reducir el tamaño de OpenSearch las respuestas, excluya los campos innecesarios con el parámetro. filter_path Asegúrese de no filtrar ningún campo que sea necesario para identificar o reintentar las solicitudes fallidas. Para obtener más información y ejemplos, consulta Reducción del tamaño de la respuesta.
Ajuste intervalos de actualización
OpenSearch los índices tienen una coherencia de lectura eventual. Una operación de actualización hace que todas las actualizaciones que se realizan en un índice estén disponibles para la búsqueda. El intervalo de actualización predeterminado es de un segundo, lo que OpenSearch significa que se actualiza cada segundo mientras se escribe en un índice.
Cuando menos frecuente sea la actualización de un índice (mayor intervalo de actualización), mejor será el rendimiento general de la indexación. La desventaja de aumentar el intervalo de actualización es que hay un retraso mayor entre la actualización del índice y el momento en que los nuevos datos están disponibles para la búsqueda. Establezca el intervalo de actualización tan alto como pueda tolerar para mejorar el rendimiento general.
Recomendamos configurar el parámetro refresh_interval para todos los índices a 30 segundos o más.
Habilitar Auto-Tune
Auto-Tuneutiliza las métricas de rendimiento y uso del OpenSearch clúster para sugerir cambios en el tamaño de las colas, el tamaño de la caché y la configuración de la máquina virtual Java (JVM) en los nodos. Estos cambios opcionales mejoran la velocidad y la estabilidad del clúster. Puede volver a la configuración predeterminada del OpenSearch servicio en cualquier momento. Auto-Tune está activado de forma predeterminada en los dominios nuevos, a menos que lo desactive de forma explícita.
Le recomendamos que lo active Auto-Tune en todos los dominios y que establezca un período de mantenimiento periódico o que revise periódicamente sus recomendaciones.
Seguridad
Las siguientes prácticas recomendadas se aplican a la protección de sus dominios.
Cómo habilitar el control de acceso detallado
Fine-grained el control de acceso le permite controlar quién puede acceder a determinados datos dentro de un dominio OpenSearch de servicio. En comparación con el control de acceso generalizado, el control de acceso detallado proporciona a cada clúster, índice, documento y campo su propia política de acceso especificada. Los criterios de acceso pueden basarse en una serie de factores, incluido el rol de la persona quien solicita el acceso y la acción que pretende realizar con los datos. Por ejemplo, puede dar a un usuario acceso para escribir en un índice, y a otra se le puede dar acceso solo para leer los datos del índice sin realizar cambios.
Fine-grained el control de acceso permite que los datos con diferentes requisitos de acceso estén en el mismo espacio de almacenamiento sin problemas de seguridad o cumplimiento.
Se recomienda habilitar un control de acceso detallado para sus dominios.
Implemente dominios dentro de una VPC
Colocar su dominio de OpenSearch servicio en una nube privada virtual (VPC) permite una comunicación segura entre el OpenSearch Servicio y otros servicios dentro de la VPC, sin necesidad de una puerta de enlace a Internet, un dispositivo NAT o una conexión VPN. Todo el tráfico permanece seguro dentro de la nube. AWS Debido a su aislamiento lógico, los dominios que residen dentro de una VPC tienen una capa adicional de seguridad en comparación con los dominios que utilizan puntos de conexión públicos.
Le recomendamos que utilice crear sus dominios dentro de una VPC.
Aplique una política de acceso restrictivo
Incluso si su dominio se implementa dentro de una VPC, es una práctica recomendada la implementación de la seguridad en capas. Asegúrese de comprobar la configuración de sus políticas de acceso actuales.
Aplica a tus dominios una política de acceso restrictiva basada en los recursos y sigue el principio de privilegios mínimos al conceder acceso a la API de configuración y a las operaciones de la OpenSearch API. Como regla general, evite usar la entidad principal de usuario anónimo "Principal": {"AWS": "*" } en sus políticas de acceso.
Sin embargo, hay algunas situaciones en las que es aceptable usar una política de acceso abierto, como cuando se habilita un control de acceso detallado. Una política de acceso abierto puede permitirle acceder al dominio en los casos en que la firma de solicitudes sea difícil o imposible, por ejemplo, desde ciertos clientes y herramientas.
Habilite el cifrado en reposo
OpenSearch Los dominios de servicio ofrecen el cifrado de los datos en reposo para evitar el acceso no autorizado a los datos. El cifrado en reposo utiliza AWS Key Management Service (AWS KMS) para almacenar y administrar las claves de cifrado, y el algoritmo estándar de cifrado avanzado con claves de 256 bits (AES-256) para realizar el cifrado.
Si el dominio almacena información confidencial, habilite el cifrado de datos en reposo.
Habilite el cifrado de nodo a nodo
Node-to-node El cifrado proporciona un nivel de seguridad adicional además de las funciones de seguridad predeterminadas del OpenSearch Servicio. Implementa la seguridad de la capa de transporte (TLS) para todas las comunicaciones entre los nodos que están aprovisionados. OpenSearch Node-to-node cifrado: todos los datos que se envíen a su dominio de OpenSearch servicio a través de HTTPS permanecen cifrados en tránsito mientras se distribuyen y replican entre los nodos.
Si el dominio almacena información confidencial, habilite el cifrado de nodo a nodo.
Supervise con AWS Security Hub CSPM
Supervise su uso del OpenSearch Servicio en relación con las mejores prácticas de seguridad mediante el uso de AWS Security Hub CSPM. Security Hub CSPM utiliza controles de seguridad para evaluar las configuraciones de los recursos y los estándares de seguridad para cumplir con varios marcos de conformidad. Para obtener más información sobre el uso de Security Hub CSPM para evaluar los recursos del OpenSearch servicio, consulte los Amazon OpenSearch Service controles en la Guía del AWS Security Hub usuario.
Optimización de costos
Las siguientes prácticas recomendadas se aplican a la optimización y el ahorro de los costes del OpenSearch servicio.
Use los tipos de instancia de última generación
OpenSearch El servicio siempre adopta nuevos tipos de instancias de Amazon EC2 que ofrecen un mejor rendimiento a un coste menor. Recomendamos usar siempre las instancias de última generación.
Evite usar instancias T2 o t3.small para dominios de producción, ya que pueden volverse inestables bajo una carga pesada sostenida. Las instancias r6g.large son una opción para cargas de trabajo de producción pequeñas (tanto como nodos de datos, como nodos maestros dedicados).
Use los volúmenes gp3 de Amazon EBS más recientes
OpenSearch los nodos de datos requieren un almacenamiento de baja latencia y alto rendimiento para proporcionar una indexación y consultas rápidas. Utilizando volúmenes gp3 de Amazon EBS, se obtiene un mayor rendimiento de referencia (IOPS y rendimiento) a un costo un 9,6 % inferior que con el tipo de volumen gp2 de Amazon EBS que se ofrecía anteriormente. Puede aprovisionar IOPS y rendimiento adicionales independientemente del tamaño de los volúmenes mediante gp3. Además, estos volúmenes son más estables que los de la generación anterior, ya que no utilizan créditos de ráfaga. Asimismo, el tipo de volumen gp3 duplica los límites de tamaño de volumen por nodo de datos en comparación con el tipo de volumen gp2. Con estos volúmenes de mayor tamaño, puede reducir el costo de los datos pasivos mediante el incremento de la cantidad de almacenamiento por nodo de datos.
Utilice UltraWarm y almacene en frío los datos de registro de series temporales
Si lo utiliza OpenSearch para el análisis de registros, traslade sus datos a un UltraWarm almacenamiento en frío para reducir los costes. Utilice la Administración de estado de índices (ISM) para migrar datos entre niveles de almacenamiento y administrar la retención de datos.
UltraWarmproporciona una forma rentable de almacenar grandes cantidades de datos de solo lectura en OpenSearch Service. UltraWarm utiliza Amazon S3 para el almacenamiento, lo que significa que los datos son inmutables y solo se necesita una copia. Solo paga por un almacenamiento que es equivalente al tamaño de las particiones principales de sus índices. Las latencias de las UltraWarm consultas aumentan con la cantidad de datos de S3 que se necesitan para atender la consulta. Una vez que los datos se han almacenado en caché en los nodos, las consultas a los UltraWarm índices tienen un rendimiento similar al de las consultas a los índices activos.
El almacenamiento en frío también cuenta con el respaldo de S3. Cuando necesite consultar datos inactivos, puede adjuntarlos de forma selectiva a los nodos existentes. UltraWarm Los datos inactivos incurren en el mismo coste de almacenamiento gestionado que los objetos almacenados en frío UltraWarm, pero los objetos almacenados en frío no consumen recursos de los UltraWarm nodos. Por lo tanto, el almacenamiento en frío proporciona una cantidad significativa de capacidad de almacenamiento sin afectar al tamaño o al recuento de los UltraWarm nodos.
UltraWarm se vuelve rentable cuando tiene que migrar aproximadamente 2,5 TiB de datos desde un almacenamiento activo. Supervise su tasa de llenado y planifique trasladar los índices a ellos UltraWarm antes de alcanzar ese volumen de datos.
Revise las recomendaciones para instancias reservadas
Considere comprar instancias reservadas (RI) después de contar con una buena referencia sobre el rendimiento y el consumo de cómputos. Los descuentos comienzan en torno al 30 % para reservas sin pago anticipado de 1 año y pueden aumentar hasta un 50 % para todos los compromisos de pagos iniciales de 3 años.
Después de observar un funcionamiento estable durante al menos 14 días, revise Acceder a las recomendaciones de reservas en la Guía del usuario de AWS Cost Management . El encabezado Amazon OpenSearch Service muestra recomendaciones de compra específicas de RI y ahorros proyectados.
