Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Grupos de disponibilidad distribuida
Un grupo de disponibilidad distribuida abarca dos grupos de disponibilidad independientes. Puede considerarlo como un grupo de disponibilidad de grupos de disponibilidad. Los grupos de disponibilidad subyacentes se configuran en dos clústeres WSFC distintos. Los grupos de disponibilidad que participan en un grupo de disponibilidad distribuida no tienen por qué compartir la misma ubicación. Pueden ser físicos o virtuales, en las instalaciones o en la nube pública. Los grupos de disponibilidad de un grupo de disponibilidad distribuida no tienen por qué ejecutar la misma versión de SQL Server. La instancia de base de datos de destino puede ejecutar una versión de SQL Server posterior a la de la instancia de base de datos de origen.
Una arquitectura de grupos de disponibilidad distribuida le ofrece una forma flexible de realojar una instancia o base de datos de SQL Server de vital importancia. AWS Proporciona una solución híbrida para migrar mediante lift-and-shift (o levantar y transformar) sus bases de datos críticas de SQL Server a AWS.
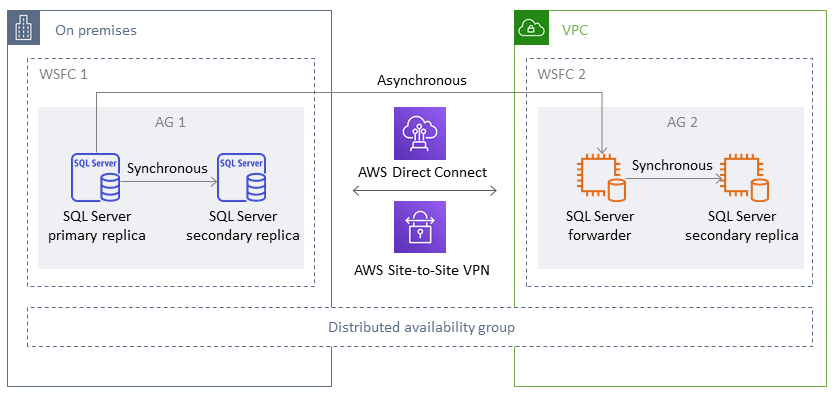
Utilizar una arquitectura de grupos de disponibilidad distribuida es más eficiente que ampliar los clústeres WFSC locales existentes. AWSLos datos solo se transfieren de la réplica principal local a una de las AWS réplicas (la reenviadora). El reenviador es responsable de enviar los datos a otras réplicas de lectura secundarias. AWS
En el siguiente diagrama, el primer clúster de WSFC (WSFC 1) está alojado en las instalaciones y tiene un grupo de disponibilidad en las instalaciones (AG 1). El segundo clúster de WSFC (WSFC 2) está alojado en un grupo de disponibilidad (AG 2) AWS y tiene un grupo de AWS disponibilidad. Direct Connect
nota
En cada momento habrá solo una base de datos disponible para las operaciones de escritura. Puede usar las réplicas secundarias restantes para las operaciones de lectura. Para escalar horizontalmente sus cargas de trabajo de lectura, puede añadir más réplicas de lectura en varias zonas de disponibilidad de AWS.
Para obtener más información acerca de los grupos de disponibilidad distribuida, consulte:
-
Cómo diseñar una solución híbrida de Microsoft SQL Server mediante grupos de disponibilidad distribuidos
en el blog de AWS bases de datos -
Migre SQL Server para AWS utilizar grupos de disponibilidad distribuidos en el sitio web de la Guía AWS prescriptiva
