Realización de una prueba de concepto (POC) de Amazon Redshift
Amazon Redshift es un popular almacenamiento de datos en la nube, que ofrece un servicio basado en la nube totalmente administrado que se integra con el lago de datos de Amazon Simple Storage Service de una organización, flujos en tiempo real, flujos de trabajo de machine learning (ML), flujos de trabajo transaccionales y mucho más. En las siguientes secciones, se le guiará a través del proceso de realización de una prueba de concepto (POC) en Amazon Redshift. Esta información le ayudará a establecer objetivos para su POC y a aprovechar las herramientas que pueden automatizar el aprovisionamiento y la configuración de los servicios para su POC.
nota
Para obtener una copia de esta información en formato PDF, elija el enlace Ejecute su propio POC de Redshift en la página de recursos de Amazon Redshift
Al realizar un POC de Amazon Redshift, usted prueba, comprueba y adopta características que van desde las mejores capacidades de seguridad de su clase, escalado elástico, fácil integración e ingestión hasta opciones flexibles de arquitecturas de datos descentralizadas.

Siga estos pasos para realizar el POC correctamente.
Paso 1: defina el alcance del POC

A la hora de realizar un POC, puede optar por utilizar sus propios datos o puede usar conjuntos de datos de referencia. Cuando elige sus propios datos, ejecuta sus propias consultas en ellos. Con los datos de evaluación de referencia, se proporcionan consultas de ejemplo con la referencia. Consulte Uso de conjuntos de datos de muestra para obtener más información si aún no está preparado para realizar una POC con sus propios datos.
En general, recomendamos utilizar dos semanas de datos para un POC de Amazon Redshift.
Para empezar, haga lo siguiente:
Identifique sus requisitos empresariales y funcionales y, a continuación, trabaje en sentido inverso. Los ejemplos más comunes son: un rendimiento más rápido, costos más bajos, probar una nueva carga de trabajo o característica, o comparar Amazon Redshift con otro almacenamiento de datos.
Establezca objetivos específicos que se conviertan en los criterios de éxito del POC. Por ejemplo, si busca un rendimiento más rápido, elabore una lista de los cinco procesos principales que desee acelerar e incluya los tiempos de ejecución actuales junto con el tiempo de ejecución requerido. Pueden ser informes, consultas, procesos de ETL, ingesta de datos o cualquiera que sea su punto débil actual.
Identifique el alcance específico y los artefactos necesarios para ejecutar las pruebas. ¿Qué conjuntos de datos necesita migrar o ingerir de forma continua en Amazon Redshift y qué consultas y procesos se necesitan para ejecutar las pruebas y compararlas con los criterios de éxito? Hay dos formas de hacer esto:
Uso de sus propios datos
Para probar sus propios datos, elabore la lista mínima viable de artefactos de datos necesaria para probar sus criterios de éxito. Por ejemplo, si su almacenamiento de datos actual tiene 200 tablas, pero los informes que desea probar solo necesitan 20, su POC se puede ejecutar más rápido si utiliza solo el subconjunto de tablas más pequeño.
Uso de conjuntos de datos de muestra
Si no tiene sus propios conjuntos de datos preparados, puede empezar a realizar un POC en Amazon Redshift utilizando los conjuntos de datos de referencia estándares del sector, como TPC-DS
o TPC-H , y ejecutar ejemplos de consultas de referencia para aprovechar el potencial de Amazon Redshift. Se puede acceder a estos conjuntos de datos desde su almacenamiento de datos de Amazon Redshift después de crearlos. Para obtener instrucciones detalladas sobre cómo acceder a estos conjuntos de datos y ejemplos de consultas, consulte Paso 2: inicie Amazon Redshift.
Paso 2: inicie Amazon Redshift

Amazon Redshift acelera la obtención de información con un almacenamiento de datos en la nube rápido, sencillo y seguro a escala. Puede empezar rápidamente iniciando su almacén en la consola de Redshift sin servidor
Configuración de Amazon Redshift sin servidor
La primera vez que utilice Redshift sin servidor, la consola le guiará por los pasos necesarios para iniciar su almacén. También podría optar a un crédito para el uso de Redshift sin servidor en su cuenta. Para obtener más información sobre la elección de una prueba gratuita, consulte Prueba gratuita de Amazon Redshift
Si ya ha iniciado Redshift sin servidor en su cuenta, siga los pasos que se indican en Creación de un grupo de trabajo con un espacio de nombres en la Guía de administración de Amazon Redshift. Cuando su almacén esté disponible, puede optar por cargar los datos de ejemplo disponibles en Amazon Redshift. Para obtener información sobre el uso del editor de consultas v2 de Amazon Redshift para cargar datos, consulte Carga de datos de ejemplo en la Guía de administración de Amazon Redshift.
Si va a traer sus propios datos en lugar de cargar el conjunto de datos de ejemplo, consulte Paso 3: cargue los datos.
Paso 3: cargue los datos

Tras iniciar Redshift sin servidor, el siguiente paso es cargar los datos para el POC. Tanto si va a cargar un simple archivo CSV, ingiriendo datos semiestructurados desde S3 o transmitiendo en streaming datos directamente, Amazon Redshift proporciona la flexibilidad necesaria para trasladar los datos de forma rápida y sencilla a las tablas de Amazon Redshift desde el origen.
Elija uno de los siguientes métodos para cargar los datos.
Carga de un archivo local
Para una ingesta y un análisis rápidos, puede utilizar el editor de consultas de Amazon Redshift v2 para cargar fácilmente los archivos de datos desde su escritorio local. Tiene la capacidad de procesar archivos en varios formatos, como CSV, JSON, AVRO, PARQUET, ORC y muchos más. Para que sus usuarios, como administradores, puedan cargar datos desde un escritorio local utilizando el editor de consultas v2, debe especificar un bucket común de Amazon S3 y la cuenta de usuario debe estar configurada con los permisos adecuados. Puede seguir el proceso de Data load made easy and secure in Amazon Redshift using Query Editor V2
Carga de un archivo de Amazon S3
Para cargar datos desde un bucket de Amazon S3 en Amazon Redshift, comience por utilizar el comando COPY y especifique la ubicación de Amazon S3 de origen y la tabla de Amazon Redshift de destino. Asegúrese de que los permisos y los roles de IAM estén configurados correctamente para permitir el acceso de Amazon Redshift al bucket de Amazon S3 designado. Siga el Tutorial: carga de datos desde Amazon S3 para obtener instrucciones paso a paso. También puede elegir la opción Cargar datos en el editor de consultas v2 para cargar datos directamente desde su bucket de S3.
Ingesta de datos continua
La copia automática (en versión preliminar) es una extensión del comando COPY y automatiza la carga continua de datos desde los buckets de Amazon S3. Al crear un trabajo de copia, Amazon Redshift detecta cuándo se crean nuevos archivos de Amazon S3 en una ruta especificada y, a continuación, los carga automáticamente sin su intervención. Amazon Redshift realiza un seguimiento de los archivos cargados para verificar que se cargan solo una vez. Para obtener instrucciones sobre cómo crear trabajos de copia, consulte COPY JOB (versión preliminar)
nota
La copia automática se encuentra actualmente en versión preliminar y solo se admite en clústeres aprovisionados en Regiones de AWS específicas. Para crear un clúster de la versión preliminar para la copia automática, consulte Carga de archivos con ingesta continua de archivos desde Amazon S3 (versión preliminar).
Carga de datos en streaming
La ingesta en streaming proporciona una ingesta de alta velocidad y baja latencia de datos de flujos de Amazon Kinesis Data Streams
Paso 4: analice sus datos

Tras crear el grupo de trabajo y el espacio de nombres de Redshift sin servidor y cargar los datos, puede ejecutar consultas inmediatamente. Para ello, abra el editor de consultas v2 desde el panel de navegación de la consola de Redshift sin servidor
Consulta utilizando el editor de consultas de Amazon Redshift v2
Puede acceder al editor de consultas v2 desde la consola de Amazon Redshift. Consulte Simplify your data analysis with Amazon Redshift query editor v2
Como alternativa, si desea ejecutar una prueba de carga como parte de su POC, puede hacerlo siguiendo estos pasos para instalar y ejecutar Apache JMeter.
Ejecución de una prueba de carga con Apache JMeter
Para realizar una prueba de carga que simule que “N” usuarios envían consultas de forma simultánea a Amazon Redshift, puede utilizar Apache JMeter
Para instalar y configurar Apache JMeter para que se ejecute en su grupo de trabajo de Redshift sin servidor, siga las instrucciones de Automate Amazon Redshift load testing with the AWS Analytics Automation Toolkit
Tras completar la personalización de las instrucciones SQL y finalizar el plan de pruebas, guarde y ejecute el plan de pruebas en su grupo de trabajo de Redshift sin servidor. Para monitorear el progreso de su prueba, abra la consola de Redshift sin servidor
Para ver las métricas de rendimiento, elija la pestaña Rendimiento de la base de datos en la consola de Redshift sin servidor y podrá monitorear métricas como Conexiones de la base de datos y Uso de la CPU. Aquí puede ver un gráfico para monitorear la capacidad de la RPU utilizada y observar cómo Redshift sin servidor se escala automáticamente para satisfacer las demandas de carga de trabajo simultáneas mientras se ejecuta la prueba de carga en su grupo de trabajo.
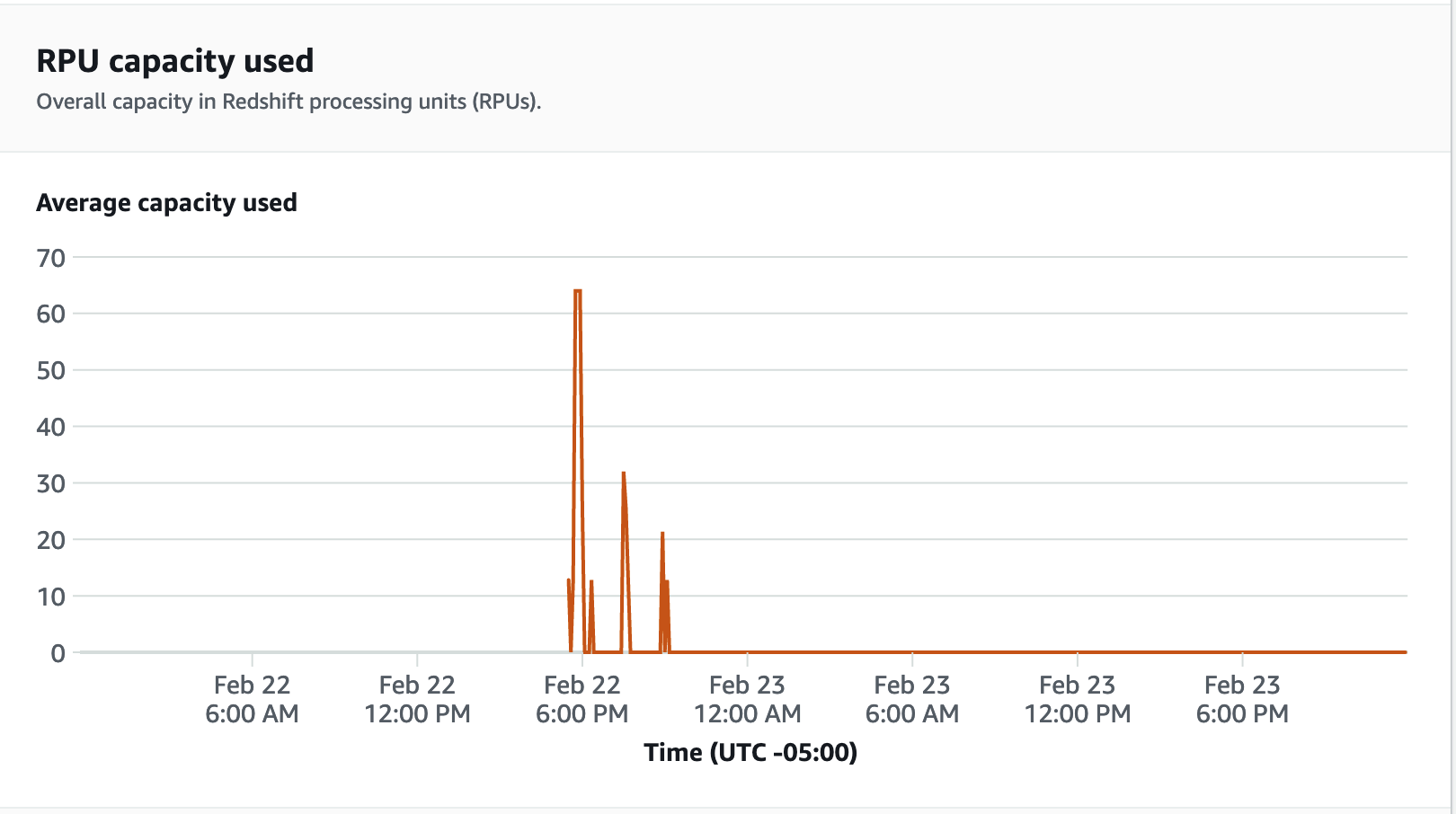
Las conexiones de las bases de datos son otra métrica útil que se debe monitorear al ejecutar la prueba de carga para ver cómo su grupo de trabajo gestiona numerosas conexiones simultáneas en un momento dado para satisfacer las crecientes demandas de carga de trabajo.
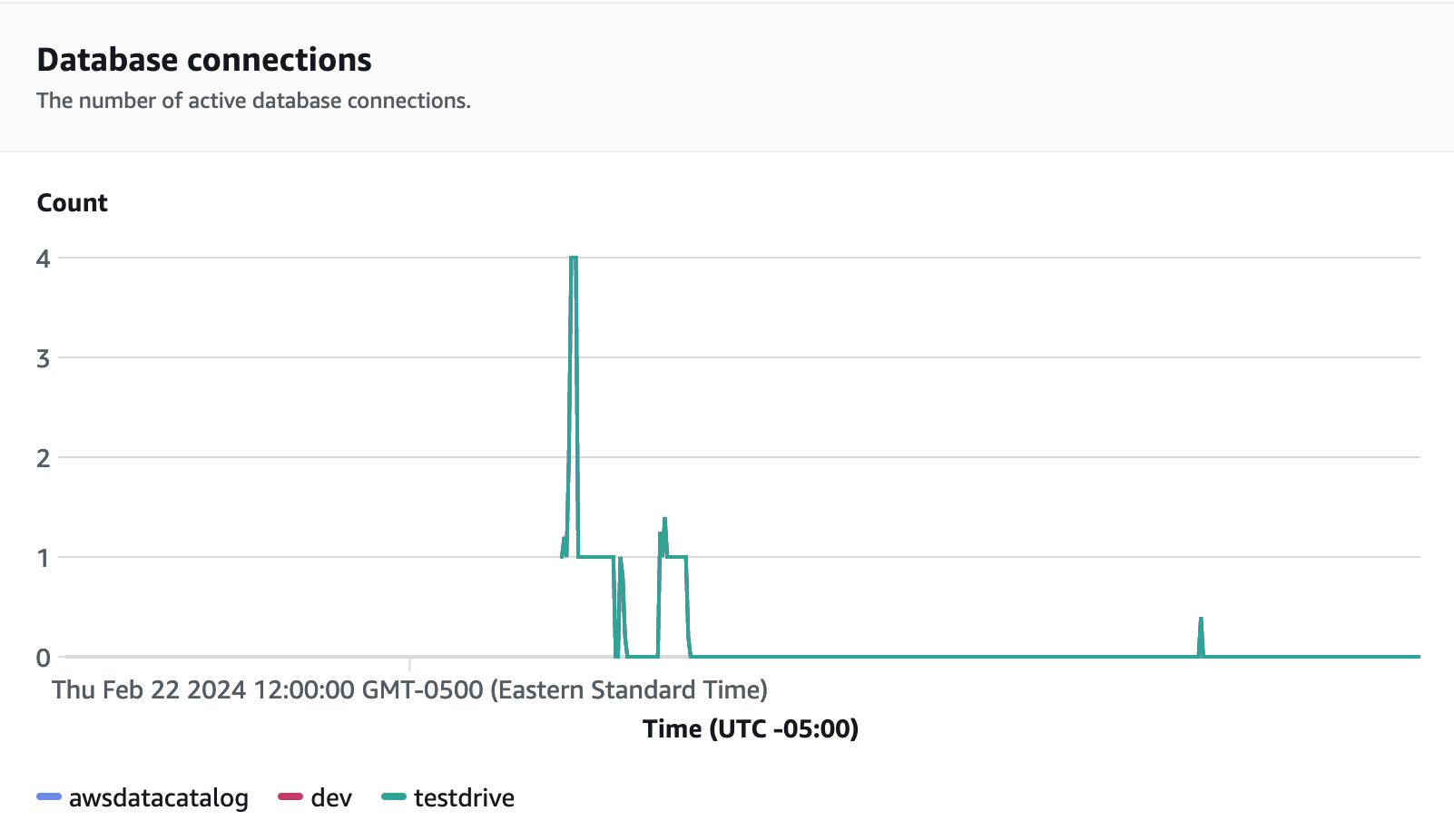
Paso 5: optimice

Amazon Redshift permite a decenas de miles de usuarios procesar exabytes de datos todos los días y potenciar sus cargas de trabajo de análisis al ofrecer una variedad de configuraciones y características para admitir casos de uso individuales. Al elegir entre estas opciones, los clientes buscan herramientas que les ayuden a determinar la configuración de almacenamiento de datos más óptimo para admitir su carga de trabajo de Amazon Redshift.
Versiones de prueba
Puede utilizar Versiones de prueba
