Amazon Redshift will no longer support the use of Python UDFs after June 30, 2026.
We will start enforcing it in phases. For more information on the details of Python end of life
and migration options, see the
blog post
Get started with Amazon Redshift Serverless data warehouses
If you are a first-time user of Amazon Redshift Serverless, we recommend that you read the following sections to help you get started using Amazon Redshift Serverless. The basic flow of Amazon Redshift Serverless is to create serverless resources, connect to Amazon Redshift Serverless, load sample data, and then run queries on the data. In this guide, you can choose to load sample data from Amazon Redshift Serverless or from an Amazon S3 bucket. The sample data is used throughout the Amazon Redshift documentation to demonstrate features. To get started using Amazon Redshift provisioned data warehouses, see Get started with Amazon Redshift provisioned data warehouses.
Sign up for an AWS account
To get started with AWS, you need an AWS account. For information about creating an AWS account, see Getting started with an AWS account in the AWS Account Management Reference Guide.
Creating a data warehouse with Amazon Redshift Serverless
The first time you log in to the Amazon Redshift Serverless console, you are prompted to access the getting started experience, which you can use to create and manage serverless resources. In this guide, you'll create serverless resources using Amazon Redshift Serverless's default settings.
For more granular control of your setup, choose Customize settings.
Note
Redshift Serverless requires an Amazon VPC with three subnets in three different availability zones. Redshift Serverless also requires at least 3 available IP addresses. Make sure that the Amazon VPC that you use for Redshift Serverless has three subnets in three different availability zones, and at least 3 available IP addresses, before continuing. For more information about creating subnets in an Amazon VPC, see Create a subnet in the Amazon Virtual Private Cloud User Guide. For more information about IP addresses in an Amazon VPC, see IP addressing for your VPCs and subnets.
To configure with default settings:
Sign in to the AWS Management Console and open the Amazon Redshift console at https://console.aws.amazon.com/redshiftv2/
. Choose Try Redshift Serverless Free Trial.
-
Under Configuration, choose Use default settings. Amazon Redshift Serverless creates a default namespace with a default workgroup associated with this namespace. Choose Save configuration.
Note
A Namespace is a collection of database objects and users. Namespaces group together all of the resources you use in Redshift Serverless, such as schemas, tables, users, datashares, and snapshots.
A Workgroup is a collection of compute resources. Workgroups house compute resources that Redshift Serverless uses to run computational tasks.
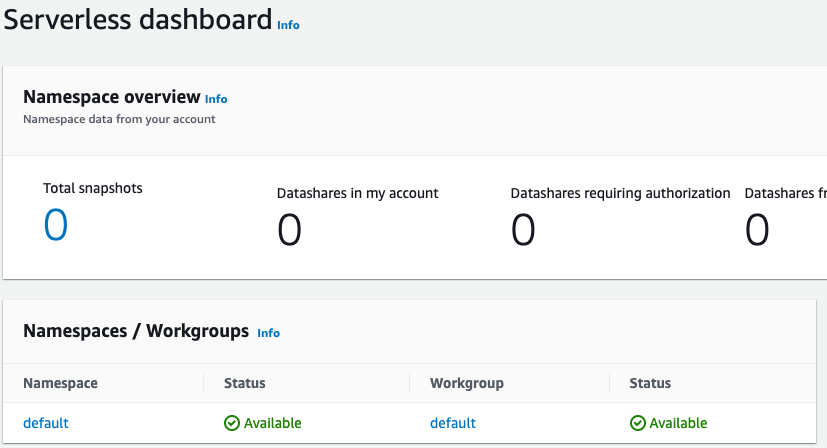
The following screenshot shows the default settings for Amazon Redshift Serverless.

-
After setup completes, choose Continue to go to your Serverless dashboard. You can see that the serverless workgroup and namespace are available.
Note
If Redshift Serverless doesn't create the workgroup successfully, you can do the following:
Address any errors that Redshift Serverless reports, such as having too few subnets in your Amazon VPC.
Delete the namespace by choosing default-namespace in the Redshift Serverless dashboard, and then choosing Actions, Delete namespace. Deleting a namespace takes several minutes.
When you open the Redshift Serverless console again, the welcome screen appears.
Loading sample data
Now that you've set up your data warehouse with Amazon Redshift Serverless, you can use the Amazon Redshift query editor v2 to load sample data.
-
To launch query editor v2 from the Amazon Redshift Serverless console, choose Query data. When you invoke query editor v2 from the Amazon Redshift Serverless console, a new browser tab opens with the query editor. The query editor v2 connects from your client machine to the Amazon Redshift Serverless environment.

-
For this guide, you'll use your AWS administrator account and the default AWS KMS key. For information about configuring the query editor v2, including which permissions are needed, see Configuring your AWS account in the Amazon Redshift Management Guide. For information about configuring Amazon Redshift to use a customer managed key, or to change the KMS key that Amazon Redshift uses, see Changing the AWS KMS key for a namespace.
-
To connect to a workgroup, choose the workgroup name in the tree-view panel.

-
When connecting to a new workgroup for the first time within query editor v2, you must select the type of authentication to use to connect to the workgroup. For this guide, leave Federated user selected, and choose Create connection.

Once you are connected, you can choose to load sample data from Amazon Redshift Serverless or from an Amazon S3 bucket.
-
Under the Amazon Redshift Serverless default workgroup, expand the sample_data_dev database. There are three sample schemas corresponding to three sample datasets that you can load into the Amazon Redshift Serverless database. Choose the sample dataset that you want to load, and choose Open sample notebooks.

Note
A SQL notebook is a container for SQL and Markdown cells. You can use notebooks to organize, annotate, and share multiple SQL commands in a single document.
-
When loading data for the first time, query editor v2 will prompt you to create a sample database. Choose Create.

Running sample queries
After setting up Amazon Redshift Serverless, you can start using a sample dataset in Amazon Redshift Serverless. Amazon Redshift Serverless automatically loads the sample dataset, such as the tickit dataset, and you can immediately query the data.
-
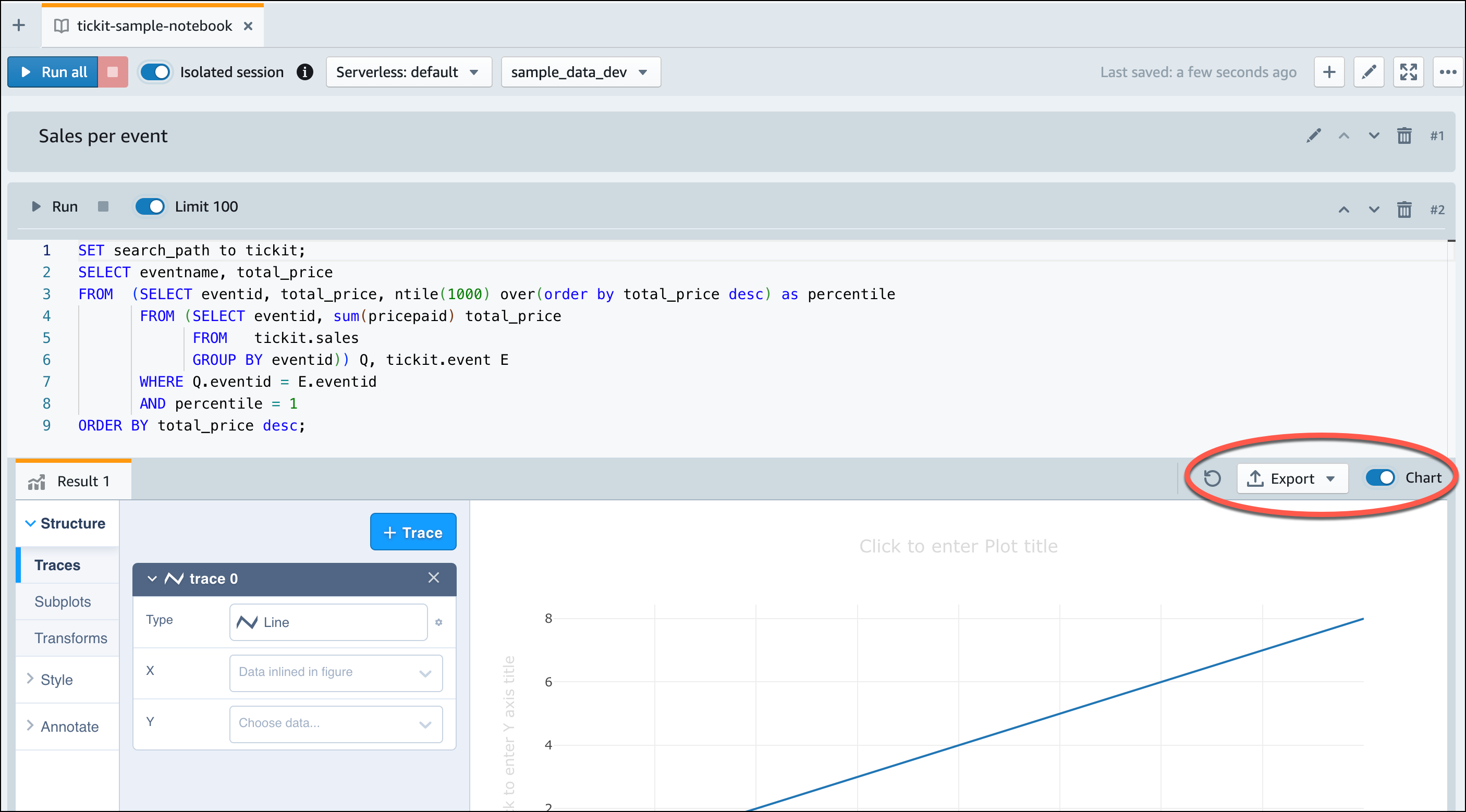
Once Amazon Redshift Serverless finishes loading the sample data, all of the sample queries are loaded in the editor. You can choose Run all to run all of the queries from the sample notebooks.

You can also export the results as a JSON or CSV file or view the results in a chart.
You can also load data from an Amazon S3 bucket. See Loading in data from Amazon S3 to learn more.
Loading in data from Amazon S3
After creating your data warehouse, you can load data from Amazon S3.
At this point, you have a database named dev.
Next, you will create some tables in the database, upload data to the tables, and try a query.
For your convenience, the sample data that you load is available in an Amazon S3 bucket.
-
Before you can load data from Amazon S3, you must first create an IAM role with the necessary permissions and attach it to your serverless namespace. To do so, return to the Redshift Serverless console and choose Namespace configuration. From the navigation menu, choose your namespace, and then choose Security and encryption. Then, choose Manage IAM roles.

Expand the Manage IAM roles menu, and choose Create IAM role.

Choose the level of S3 bucket access that you want to grant to this role, and choose Create IAM role as default.

-
Choose Save changes. You can now load sample data from Amazon S3.
The following steps use data within a public Amazon Redshift S3 bucket, but you can replicate the same steps using your own S3 bucket and SQL commands.
Load sample data from Amazon S3
-
In query editor v2, choose
 Add, then choose
Notebook to create a new SQL notebook.
Add, then choose
Notebook to create a new SQL notebook.
-
Switch to the
devdatabase.
-
Create tables.
If you are using the query editor v2, copy and run the following create table statements to create tables in the
devdatabase. For more information about the syntax, see CREATE TABLE in the Amazon Redshift Database Developer Guide.create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean); create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp); create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp); -
In the query editor v2, create a new SQL cell in your notebook.

-
Now use the COPY command in query editor v2 to load large datasets from Amazon S3 or Amazon DynamoDB into Amazon Redshift. For more information about COPY syntax, see COPY in the Amazon Redshift Database Developer Guide.
You can run the COPY command with some sample data available in a public S3 bucket. Run the following SQL commands in the query editor v2.
COPY users FROM 's3://redshift-downloads/tickit/allusers_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY event FROM 's3://redshift-downloads/tickit/allevents_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY sales FROM 's3://redshift-downloads/tickit/sales_tab.txt' DELIMITER '\t' TIMEFORMAT 'MM/DD/YYYY HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; -
After loading data, create another SQL cell in your notebook and try some example queries. For more information on working with the SELECT command, see SELECT in the Amazon Redshift Developer Guide. To understand the sample data's structure and schemas, explore using the query editor v2.
-- Find top 10 buyers by quantity. SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, users WHERE Q.buyerid = userid ORDER BY Q.total_quantity desc; -- Find events in the 99.9 percentile in terms of all time gross sales. SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1 ORDER BY total_price desc;
Now that you've loaded in data and ran some sample queries, you can explore other areas of Amazon Redshift Serverless. See the following list to learn more about how you can use Amazon Redshift Serverless.
-
You can load data from an Amazon S3 bucket. See Loading data from Amazon S3 for more information.
-
You can use the query editor v2 to load in data from a local character-separated file that is smaller than 5 MB. For more information, see Loading data from a local file.
-
You can connect to Amazon Redshift Serverless with third-party SQL tools with the JDBC and ODBC driver. See Connecting to Amazon Redshift Serverless for more information.
-
You can also use the Amazon Redshift Data API to connect to Amazon Redshift Serverless. See Using the Amazon Redshift Data API
for more information. -
You can use your data in Amazon Redshift Serverless with Redshift ML to create machine learning models with the CREATE MODEL command. See Tutorial: Building customer churn models to learn how to build a Redshift ML model.
-
You can query data from an Amazon S3 data lake without loading any data into Amazon Redshift Serverless. See Querying a data lake for more information.
