Amazon Redshift dejará de admitir la creación de UDF de Python después del 30 de junio de 2026. Empezaremos a aplicarlo por fases. Para obtener más información sobre los detalles del fin de vida de Python y las opciones de migración, consulte la entrada del blog
Introducción a los almacenamientos de datos de Amazon Redshift sin servidor
Si es la primera vez que utiliza Amazon Redshift Serverless, recomendamos que lea las siguientes secciones como ayuda para comenzar a utilizar Amazon Redshift Serverless. El flujo básico de Amazon Redshift sin servidor consiste en crear recursos sin servidor, conectarse a Amazon Redshift sin servidor, cargar datos de muestra y, después, ejecutar consultas en los datos. En esta guía, puede elegir cargar los datos de muestra desde Amazon Redshift sin servidor o desde un bucket de Amazon S3. Los datos de muestra se utilizan en toda la documentación de Amazon Redshift para demostrar características. Para comenzar a utilizar los almacenamientos de datos aprovisionados de Amazon Redshift, consulte Introducción a los almacenamientos de datos aprovisionados de Amazon Redshift.
Cómo crear una Cuenta de AWS
Para empezar a utilizar AWS, necesita una Cuenta de AWS. Para obtener más información sobre cómo crear una Cuenta de AWS, consulte la sección Introducción a una Cuenta de AWS en la Guía de referencia de AWS Account Management.
Creación de un almacenamiento de datos con Amazon Redshift sin servidor
La primera vez que inicie sesión en la consola de Amazon Redshift sin servidor, se le pedirá que acceda a la experiencia de introducción, que puede utilizar para crear y administrar recursos sin servidor. En esta guía, creará recursos sin servidor mediante la configuración predeterminada de Amazon Redshift sin servidor.
Para obtener un control más detallado de su configuración, elija Customize settings (Personalizar configuración).
nota
Redshift sin servidor requiere una Amazon VPC con tres subredes en tres zonas de disponibilidad diferentes. Redshift sin servidor también requiere al menos tres direcciones IP disponibles. Asegúrese de que la Amazon VPC que utiliza para Redshift sin servidor tenga tres subredes en tres zonas de disponibilidad diferentes y al menos tres direcciones IP disponibles antes de continuar. Para obtener más información sobre cómo crear subredes en una Amazon VPC, consulte Creación de una subred en la Guía del usuario de Amazon Virtual Private Cloud. Para obtener más información sobre direcciones IP en una Amazon VPC, consulte Direcciones IP para las VPC y subredes.
Para configurar con los ajustes predeterminados:
Inicie sesión en la AWS Management Console y abra la consola de Amazon Redshift en https://console.aws.amazon.com/redshiftv2/
. Elija Prueba de la versión de prueba gratuita de Redshift sin servidor.
-
En Configuration (Configuración), elija Use default settings (Usar configuración predeterminada). Amazon Redshift sin servidor crea un espacio de nombres predeterminado con un grupo de trabajo predeterminado asociado con este espacio de nombres. Seleccione Guardar configuración.
nota
Un Espacio de nombres es una recopilación de objetos de base de datos y usuarios. Los espacios de nombres agrupan todos los recursos que se utilizan en Redshift sin servidor, como esquemas, tablas, usuarios, recursos compartidos de datos e instantáneas.
Un Grupo de trabajo es una recopilación de recursos informáticos. Los grupos de trabajo alojan recursos informáticos que Redshift sin servidor utiliza para ejecutar tareas informáticas.
En la siguiente captura de pantalla, se muestra la configuración predeterminada de Amazon Redshift sin servidor.
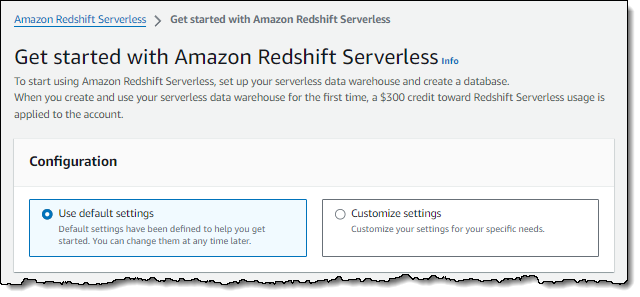
-
Una vez finalizada la configuración, elija Continue (Continuar) para ir al Serverless dashboard (Panel sin servidor). Puede ver que están disponibles el grupo de trabajo sin servidor y el espacio de nombres.
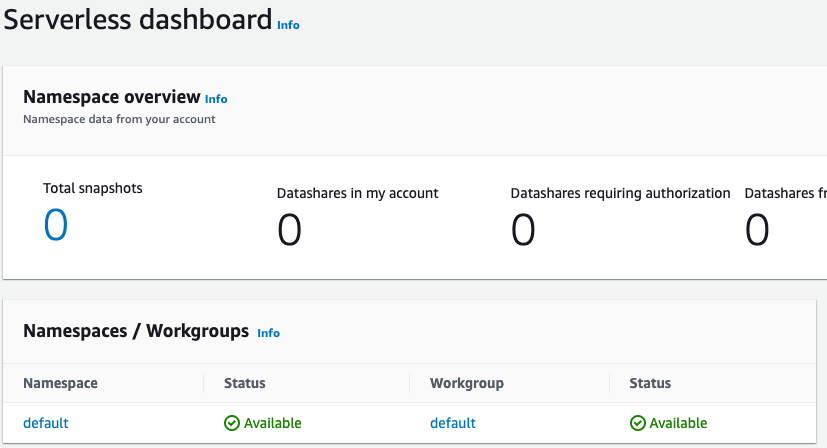
nota
Si Redshift sin servidor no crea el grupo de trabajo correctamente, puede hacer lo siguiente:
Solucione cualquier error del que informe Redshift sin servidor, como tener muy pocas subredes en la Amazon VPC.
Elimine el espacio de nombres eligiendo el espacio de nombres predeterminado en el panel de Redshift sin servidor y, a continuación, eligiendo Acciones, Eliminar espacio de nombres. La eliminación de un espacio de nombres tarda varios minutos.
Cuando vuelve a abrir la consola de Redshift sin servidor, aparece la pantalla de bienvenida.
Carga de datos de ejemplo
Ahora que ya ha configurado su almacenamiento de datos con Amazon Redshift sin servidor, puede utilizar el editor de consultas de Amazon Redshift v2 para cargar datos de muestra.
-
Para iniciar el editor de consultas v2 desde la consola de Amazon Redshift sin servidor, elija Consultar datos. Cuando se invoca el editor de consultas v2 desde la consola de Amazon Redshift Serverless, se abre una nueva pestaña del navegador con el editor de consultas. El editor de consultas v2 se conecta desde su máquina cliente al entorno de Amazon Redshift Serverless.
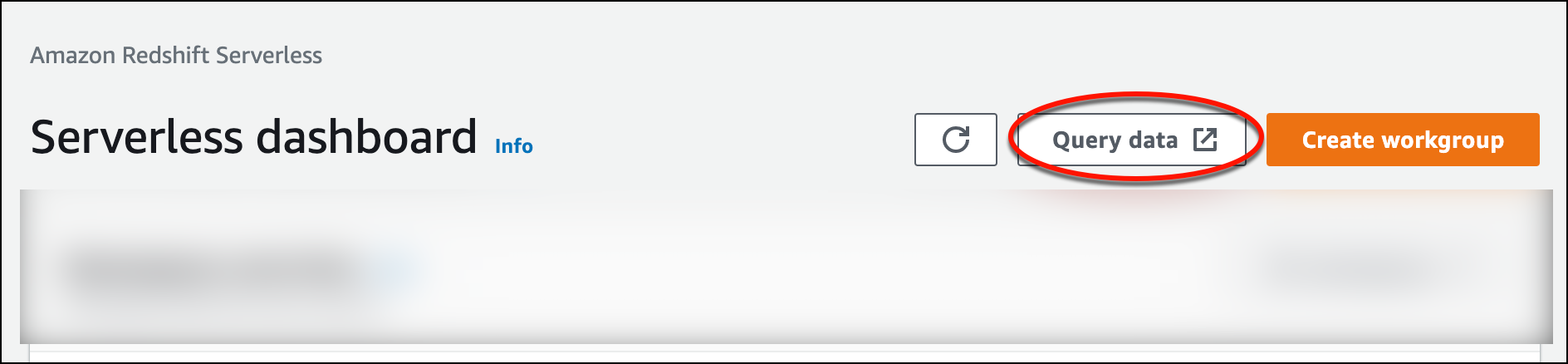
-
Para esta guía, utilizará la cuenta de administrador de AWS y la AWS KMS key predeterminada. Para obtener información sobre la configuración del editor de consultas v2, incluidos los permisos necesarios, consulte Configuración de la Cuenta de AWS en la Guía de administración de Amazon Redshift. Para obtener información sobre la configuración de Amazon Redshift para usar una clave administrada por el cliente o para cambiar la clave KMS que utiliza Amazon Redshift, consulte Cambio de la clave AWS KMS de un espacio de nombres.
-
Para conectarse a un grupo de trabajo, elija su nombre en el panel de vista de árbol.
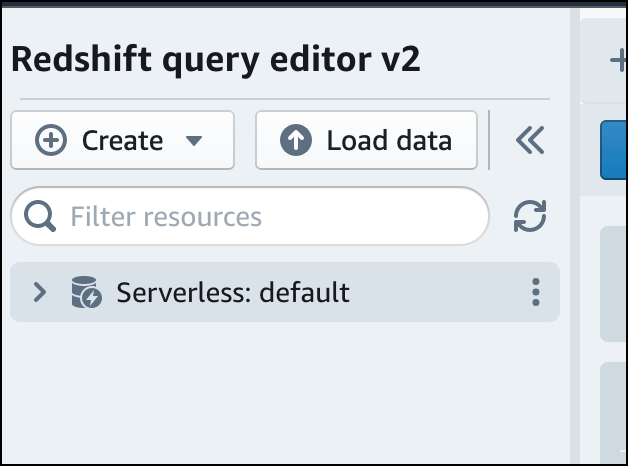
-
Cuando se conecte a un nuevo grupo de trabajo por primera vez en el editor de consultas v2, debe seleccionar el tipo de autenticación que utilizará para conectarse al grupo de trabajo. Para esta guía, deje seleccionado Usuario federado y elija Crear conexión.
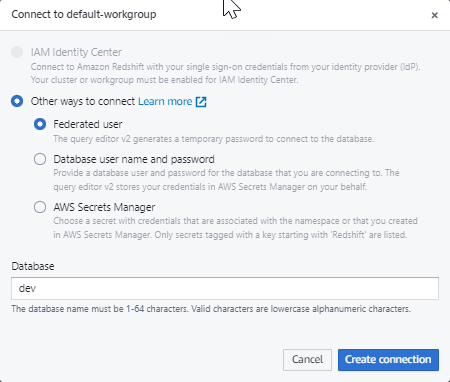
Después de conectarse, puede elegir cargar los datos de muestra desde Amazon Redshift sin servidor o desde un bucket de Amazon S3.
-
En el grupo de trabajo predeterminado de Amazon Redshift Serverless, expanda la base de datos sample_data_dev. Hay tres esquemas de muestra que corresponden a tres conjuntos de datos de muestra que se pueden cargar en la base de datos de Amazon Redshift sin servidor. Elija el conjunto de datos de ejemplo que desee cargar y elija Abrir blocs de notas de muestra.
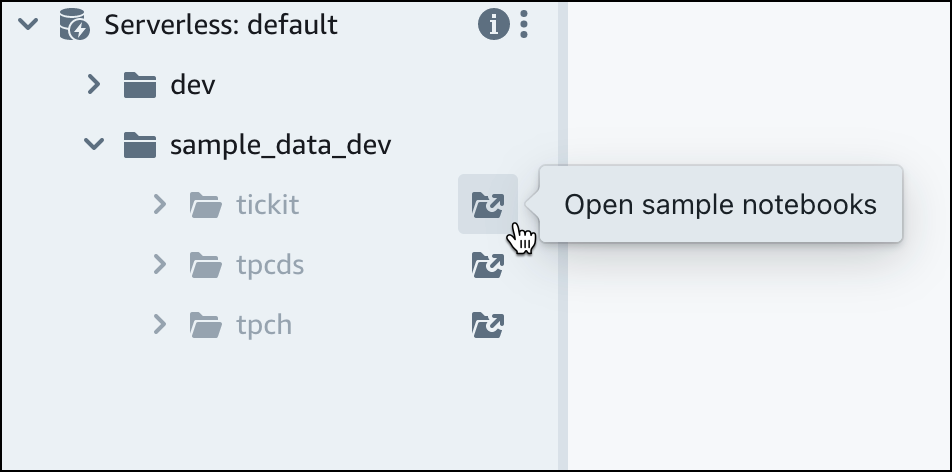
nota
Un SQL Notebook es un contenedor de celdas SQL y Markdown. Puede utilizar blocs de notas para organizar, anotar y compartir varios comandos SQL en un solo documento.
-
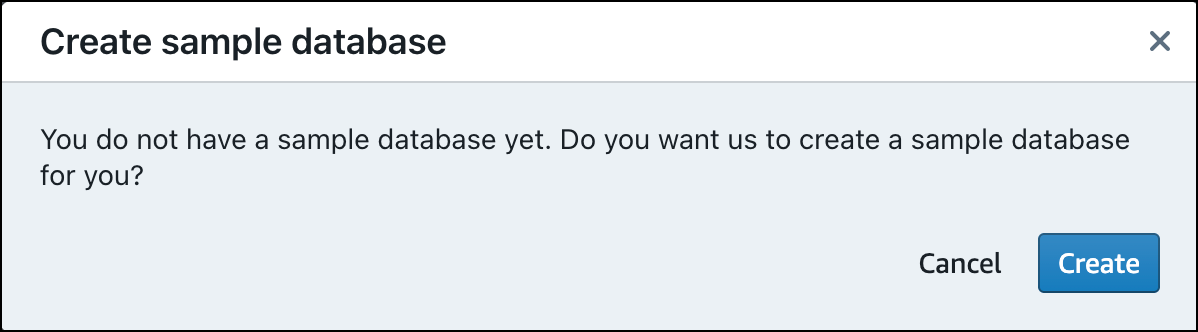
Cuando cargue datos por primera vez, el editor de consultas v2 le pedirá que cree una base de datos de muestra. Seleccione Crear.
Ejecución de consultas de ejemplo
Tras configurar Amazon Redshift sin servidor, puede comenzar a utilizar un conjunto de datos de muestra en Amazon Redshift sin servidor. Amazon Redshift sin servidor carga automáticamente el conjunto de datos de muestra, como el conjunto de datos tickit, y puede consultar inmediatamente los datos.
-
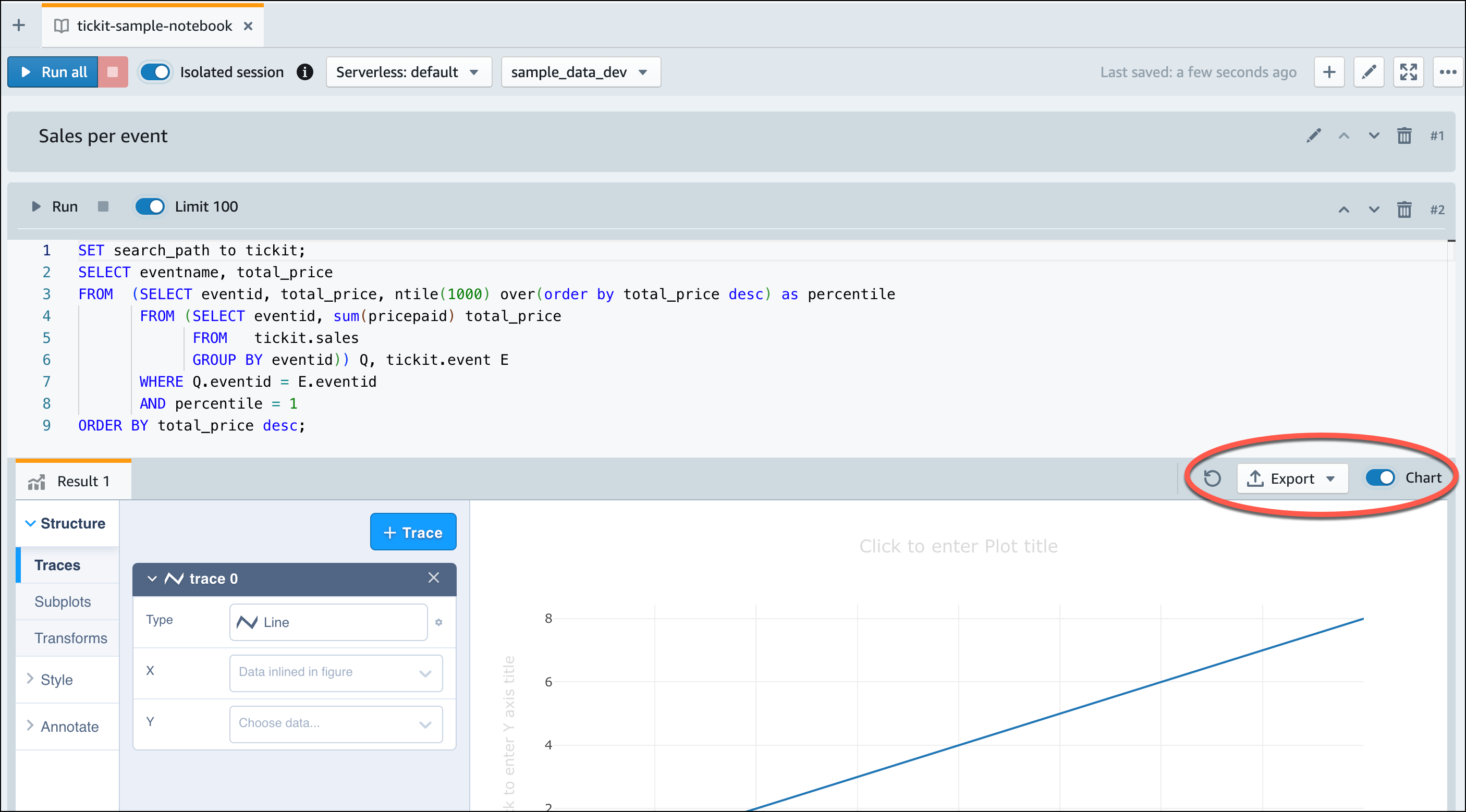
Cuando Amazon Redshift sin servidor termina de cargar los datos de muestra, todas las consultas de muestra se cargan en el editor. Puede elegir Ejecutar todo para ejecutar todas las consultas desde los cuadernos de muestra.
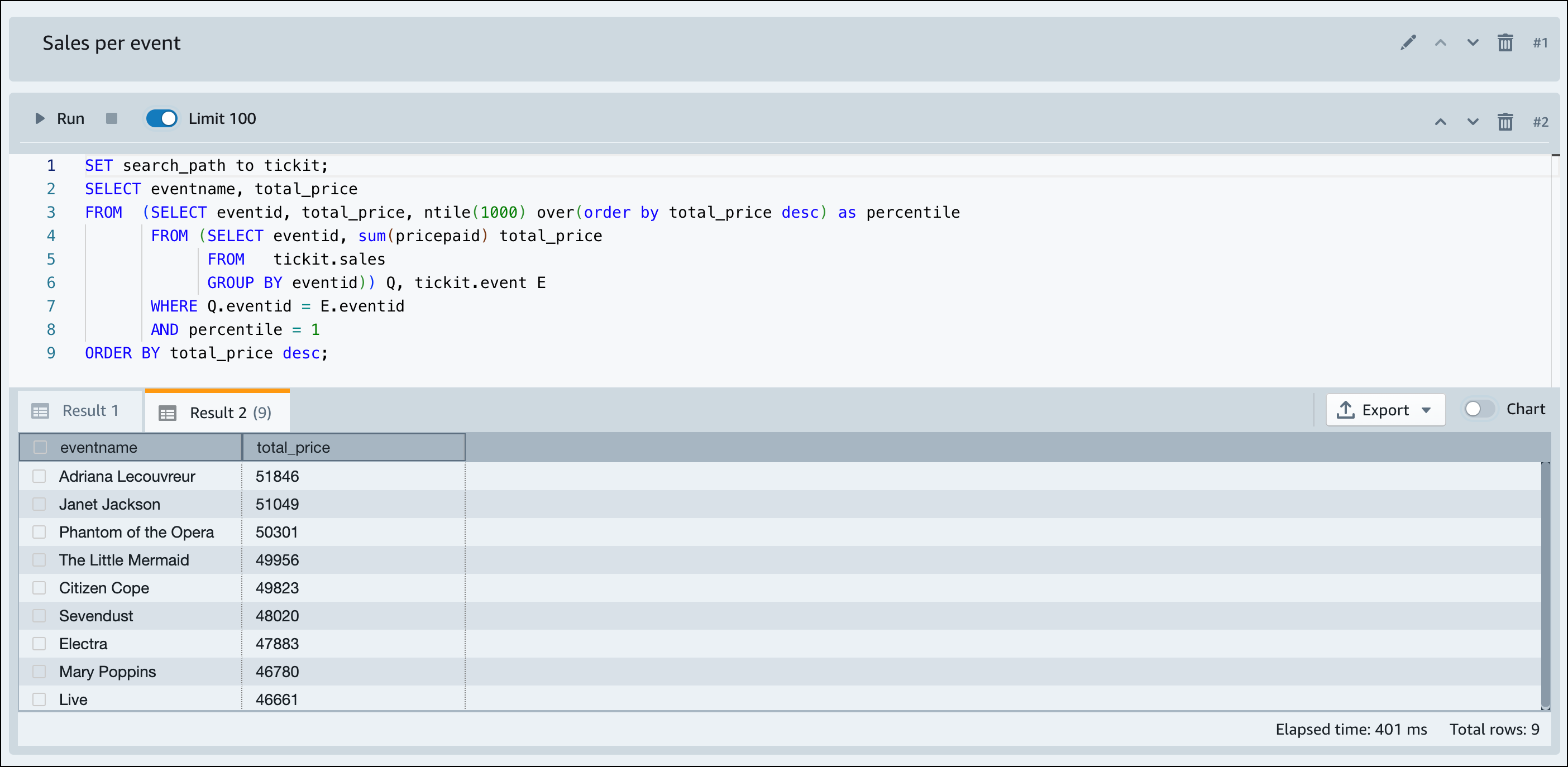
También puede exportar los resultados como un archivo JSON o CSV, o ver los resultados en un gráfico.
También puede cargar datos desde un bucket de Amazon S3. Consulte Carga de datos desde Amazon S3 para obtener más información.
Carga de datos desde Amazon S3
Después de crear el almacenamiento de datos, puede cargar los datos desde Amazon S3.
En este momento, tiene una base de datos denominada dev. Después, creará algunas tablas en la base de datos, cargará datos en ellas y probará una consulta. Para su comodidad, los datos de muestra que se cargan están disponibles en un bucket de Amazon S3.
-
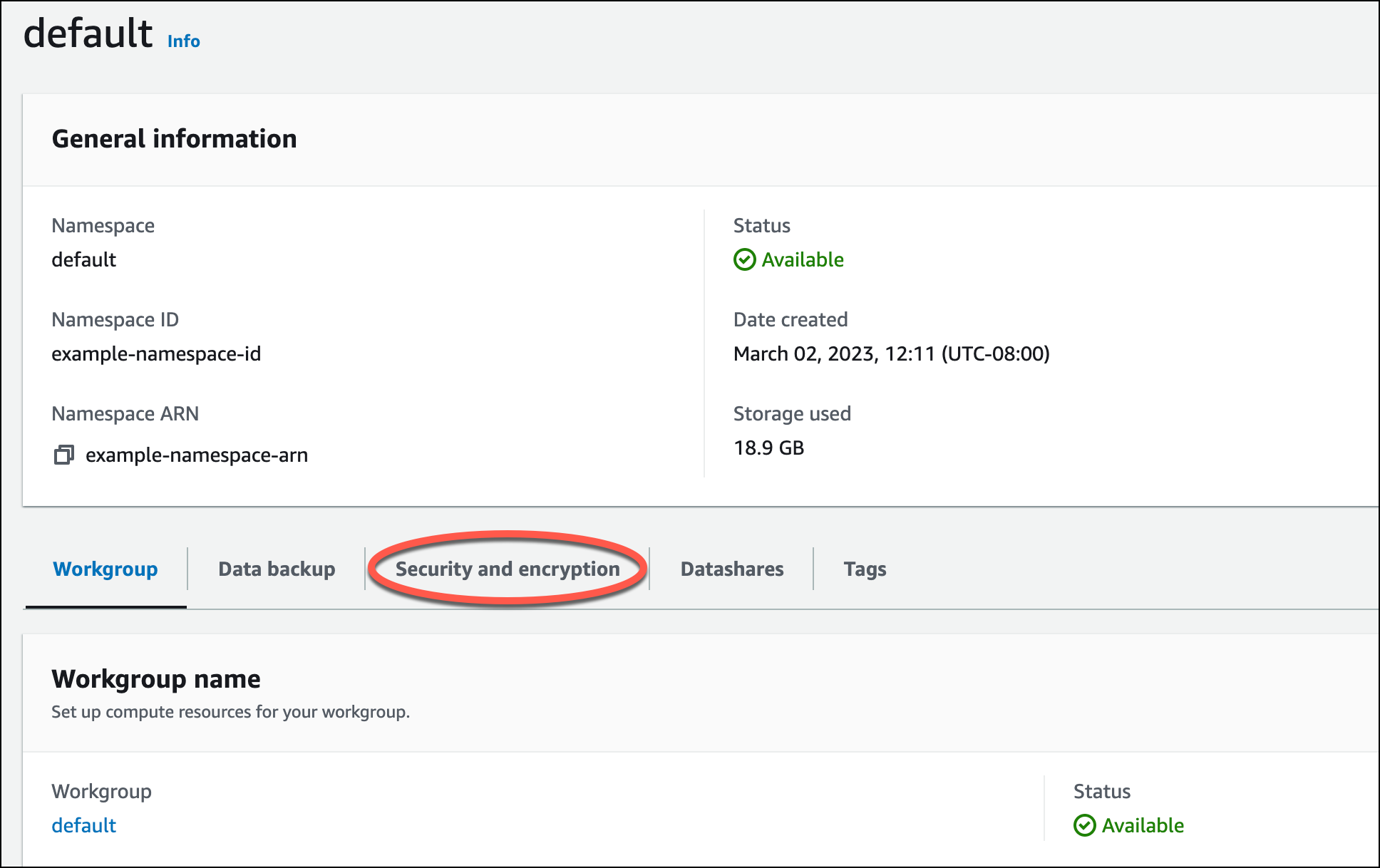
Para poder cargar datos de Amazon S3, primero debe crear un rol de IAM con los permisos necesarios y asociarlo a su espacio de nombres sin servidor. Para ello, regrese a la consola de Redshift sin servidor y seleccione Configuración del espacio de nombres. En el menú de navegación, seleccione su espacio de nombres y luego seleccione Seguridad y cifrado. A continuación, elija Administrar roles de IAM.
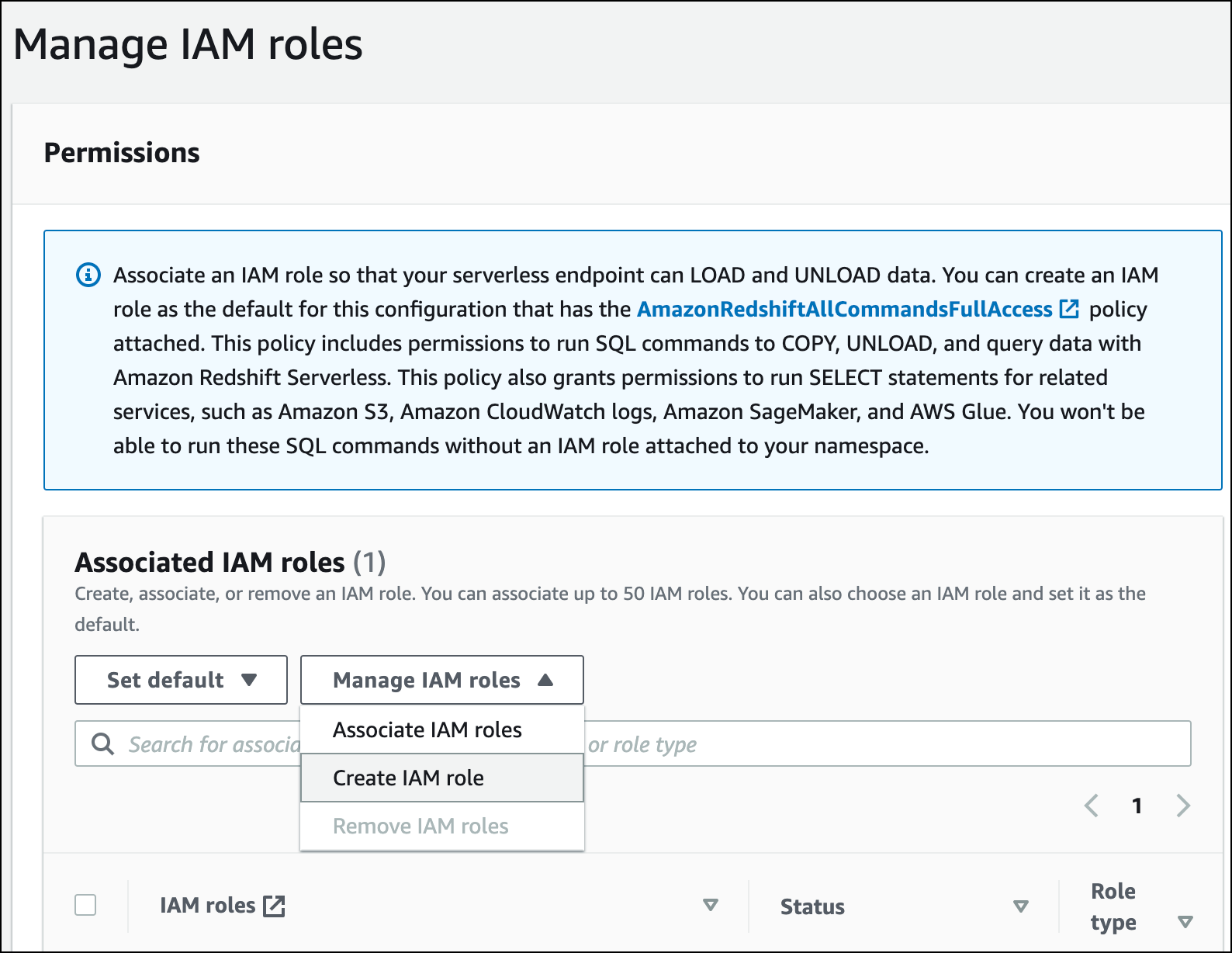
Expanda el menú Administrar roles de IAM y elija Crear rol de IAM.
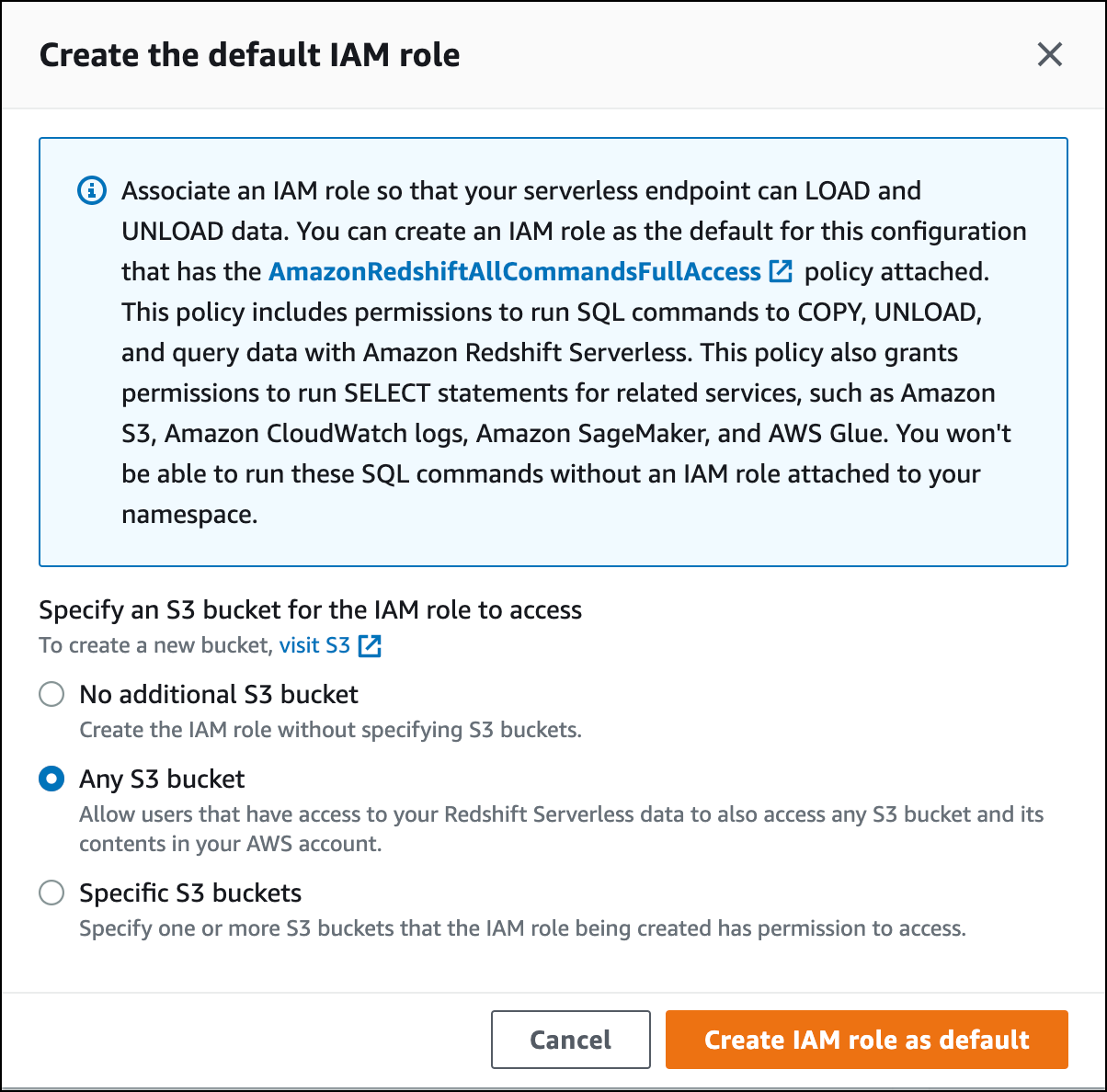
Elija el nivel de acceso al bucket de S3 que desea conceder a este rol y elija Crear un rol de IAM como predeterminado.
-
Seleccione Save changes (Guardar cambios). Ahora puede cargar datos de muestra de Amazon S3.
En los siguientes pasos, se utilizan datos en un bucket de S3 público de Amazon Redshift, pero puede replicar los mismos pasos con su propio bucket de S3 y comandos SQL.
Cargar datos de muestra de Amazon S3
-
En el editor de consultas v2, elija
 Agregar y, a continuación, Cuaderno para crear un nuevo cuaderno de SQL.
Agregar y, a continuación, Cuaderno para crear un nuevo cuaderno de SQL.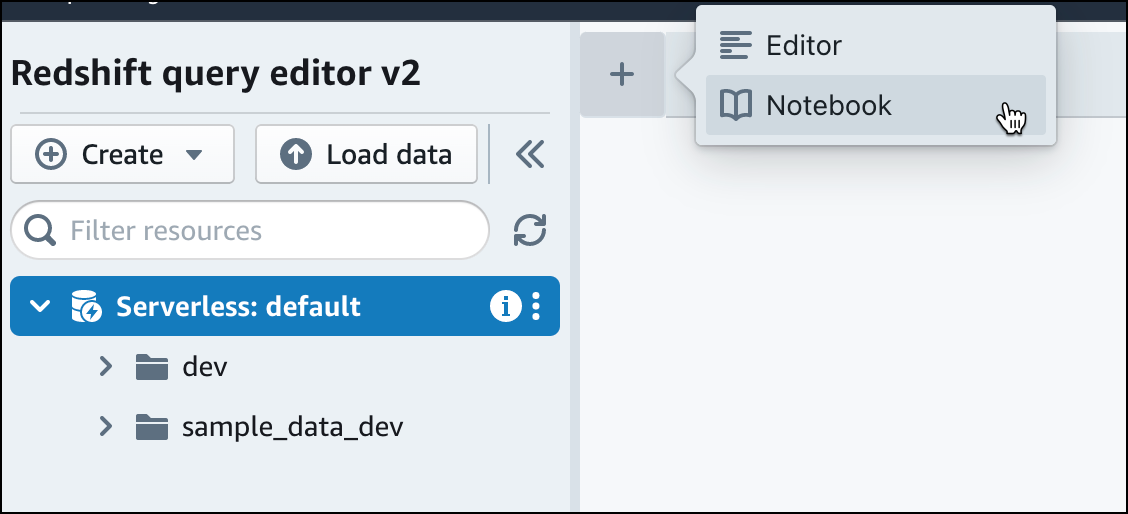
-
Cambie a la base de datos
dev.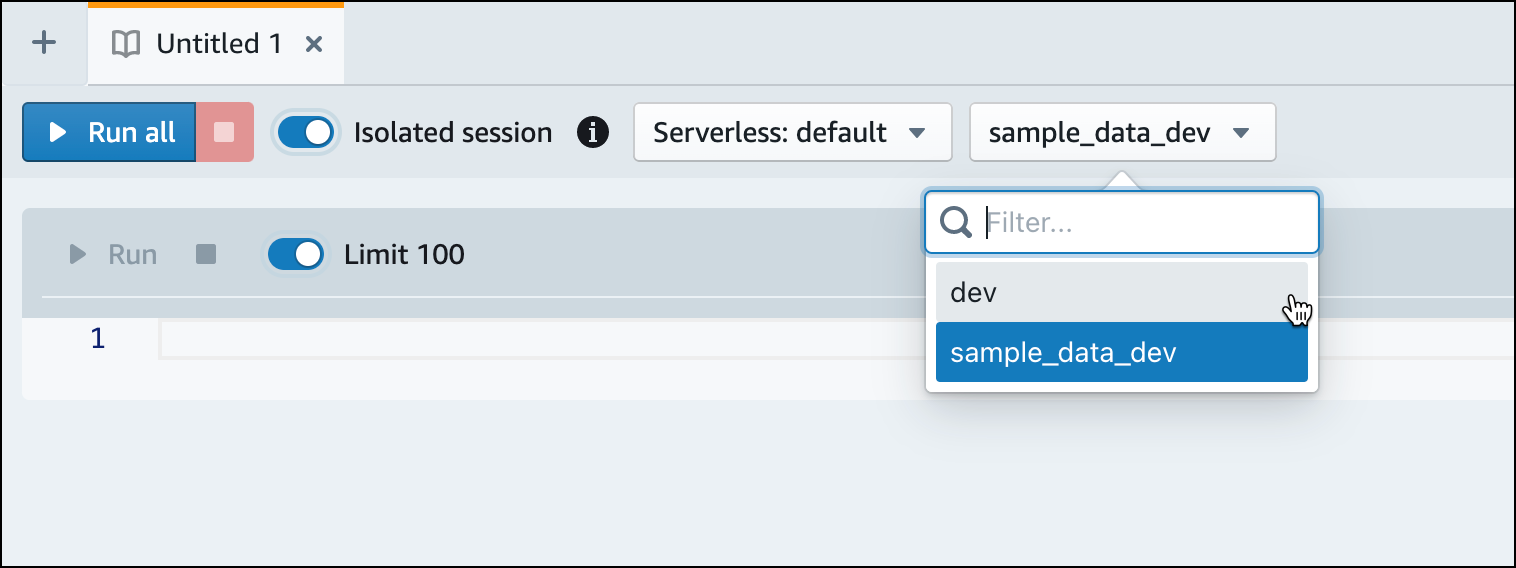
-
Cree tablas.
Si utiliza el editor de consultas v2, copie y ejecute las siguientes instrucciones de creación de tabla para crear tablas en la base de datos
dev. Para obtener más información acerca de la sintaxis, consulte CREATE TABLE en la Guía para desarrolladores de bases de datos de Amazon Redshift.create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean); create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp); create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp); -
En el editor de consultas v2, cree una nueva celda SQL en su cuaderno.
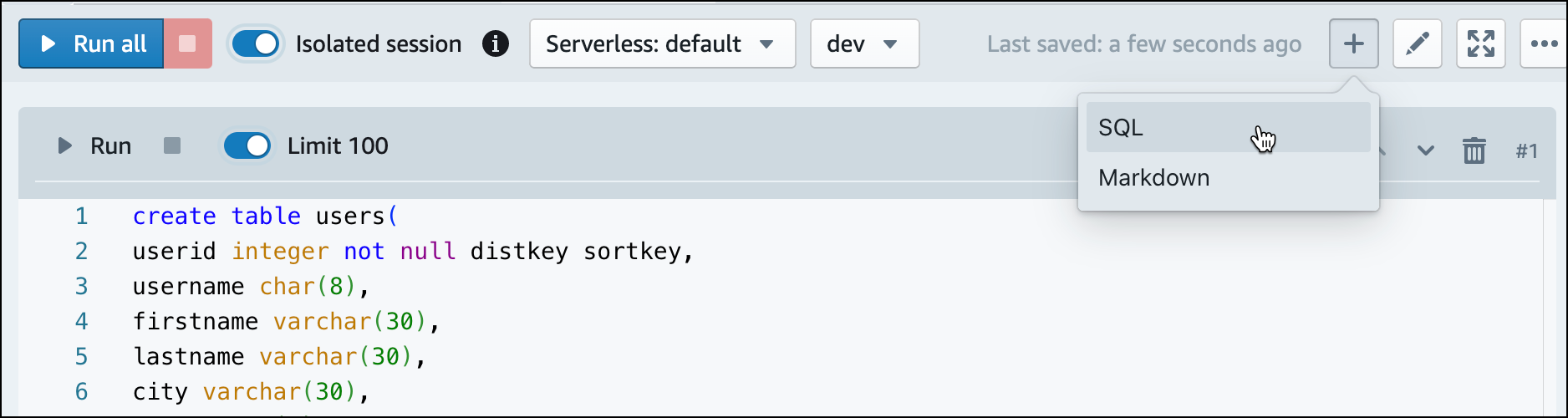
-
Ahora utilice el comando COPY en el editor de consultas v2 para cargar grandes conjuntos de datos de Amazon S3 o Amazon DynamoDB en Amazon Redshift. Para obtener más información acerca de la sintaxis de COPY, consulte COPY en la Guía para desarrolladores de bases de datos de Amazon Redshift.
Puede ejecutar el comando COPY con algunos datos de ejemplo disponibles en un bucket de S3 público. Ejecute los siguientes comandos SQL en el editor de consultas v2.
COPY users FROM 's3://redshift-downloads/tickit/allusers_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY event FROM 's3://redshift-downloads/tickit/allevents_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY sales FROM 's3://redshift-downloads/tickit/sales_tab.txt' DELIMITER '\t' TIMEFORMAT 'MM/DD/YYYY HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; -
Después de cargar los datos, cree otra celda SQL en el cuaderno y pruebe algunas consultas de ejemplo. Para obtener más información acerca de cómo trabajar con el comando SELECT, consulte SELECT en la Guía para desarrolladores de Amazon Redshift. Para entender la estructura y los esquemas de los datos de muestra, explore el uso del editor de consultas v2.
-- Find top 10 buyers by quantity. SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, users WHERE Q.buyerid = userid ORDER BY Q.total_quantity desc; -- Find events in the 99.9 percentile in terms of all time gross sales. SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1 ORDER BY total_price desc;
Ahora que ha cargado los datos y ha ejecutado algunas consultas de muestra, puede explorar otras áreas de Amazon Redshift sin servidor. Consulte la siguiente lista para obtener más información sobre cómo puede utilizar Amazon Redshift sin servidor.
-
Puede cargar datos desde un bucket de Amazon S3. Consulte Carga de datos desde Amazon S3 para obtener más información.
-
Puede utilizar el editor de consultas v2 para cargar datos de un archivo local separado por caracteres que ocupe menos de 5 MB. Para obtener más información, consulte Carga de datos desde un archivo local.
-
Puede conectarse a Amazon Redshift sin servidor con herramientas SQL de terceros con el controlador JDBC y ODBC. Consulte Conexión a Amazon Redshift sin servidor para obtener más información.
-
También puede utilizar la API de datos de Amazon Redshift para conectarse a Amazon Redshift sin servidor. Consulte Uso de la API de datos de Amazon Redshift
para obtener más información. -
Puede utilizar sus datos en Amazon Redshift sin servidor con Redshift ML para crear modelos de machine learning con el comando CREATE MODEL. Consulte Tutorial: Creación de modelos de deserción de clientes para aprender a crear un modelo de Redshift ML.
-
Puede consultar datos de un lago de datos de Amazon S3 sin cargar datos en Amazon Redshift sin servidor. Consulte Consulta de un lago de datos para obtener más información.
