Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Creación y uso de un flujo de Data Wrangler
Utilice un flujo de Amazon SageMaker Data Wrangler, o un flujo de datos, para crear y modificar una canalización de preparación de datos. El flujo de datos conecta los conjuntos de datos, las transformaciones y los análisis, o pasos, que cree, y puede usarse para definir su canalización.
instancias
Cuando crea un flujo de Data Wrangler en Amazon SageMaker Studio Classic, Data Wrangler utiliza una instancia de Amazon EC2 para ejecutar los análisis y las transformaciones de su flujo. De forma predeterminada, Data Wrangler usa la instancia m5.4xlarge. Las instancias m5 son instancias de uso general que proporcionan un equilibrio entre computación y memoria. Puede usar instancias m5 para una variedad de cargas de trabajo de computación.
Data Wrangler también le ofrece la opción de usar instancias r5. Las instancias r5 están diseñadas para ofrecer un rendimiento rápido al procesar grandes conjuntos de datos en la memoria.
Se recomienda elegir la instancia que esté mejor optimizada en función de sus cargas de trabajo. Por ejemplo, r5.8xlarge puede tener un precio más alto que m5.4xlarge, pero r5.8xlarge podría estar mejor optimizada para sus cargas de trabajo. Con instancias mejor optimizadas, puede ejecutar flujos de datos en menos tiempo y a un costo menor.
La siguiente tabla muestra las instancias que puede utilizar para ejecutar el flujo de Data Wrangler.
| Instancia estándar | vCPU | Memoria |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 GiB |
| ml.m5.8xlarge | 32 | 128 GiB |
| ml.m5.16xlarge | 64 |
256 GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
| r5.4xlarge | 16 | 128 GiB |
| r5.8xlarge | 32 | 256 GiB |
| r5.24xlarge | 96 | 768 GiB |
Para obtener más información acerca de las instancias r5, consulte Instancias R5 de Amazon EC2
Cada flujo de Data Wrangler tiene asociada una instancia de Amazon EC2. Es posible que tenga varios flujos asociados a una sola instancia.
Puede cambiar el tipo de instancia para cada archivo de flujo sin problemas. Si cambia el tipo de instancia, la instancia que utilizó para ejecutar el flujo seguirá ejecutándose.
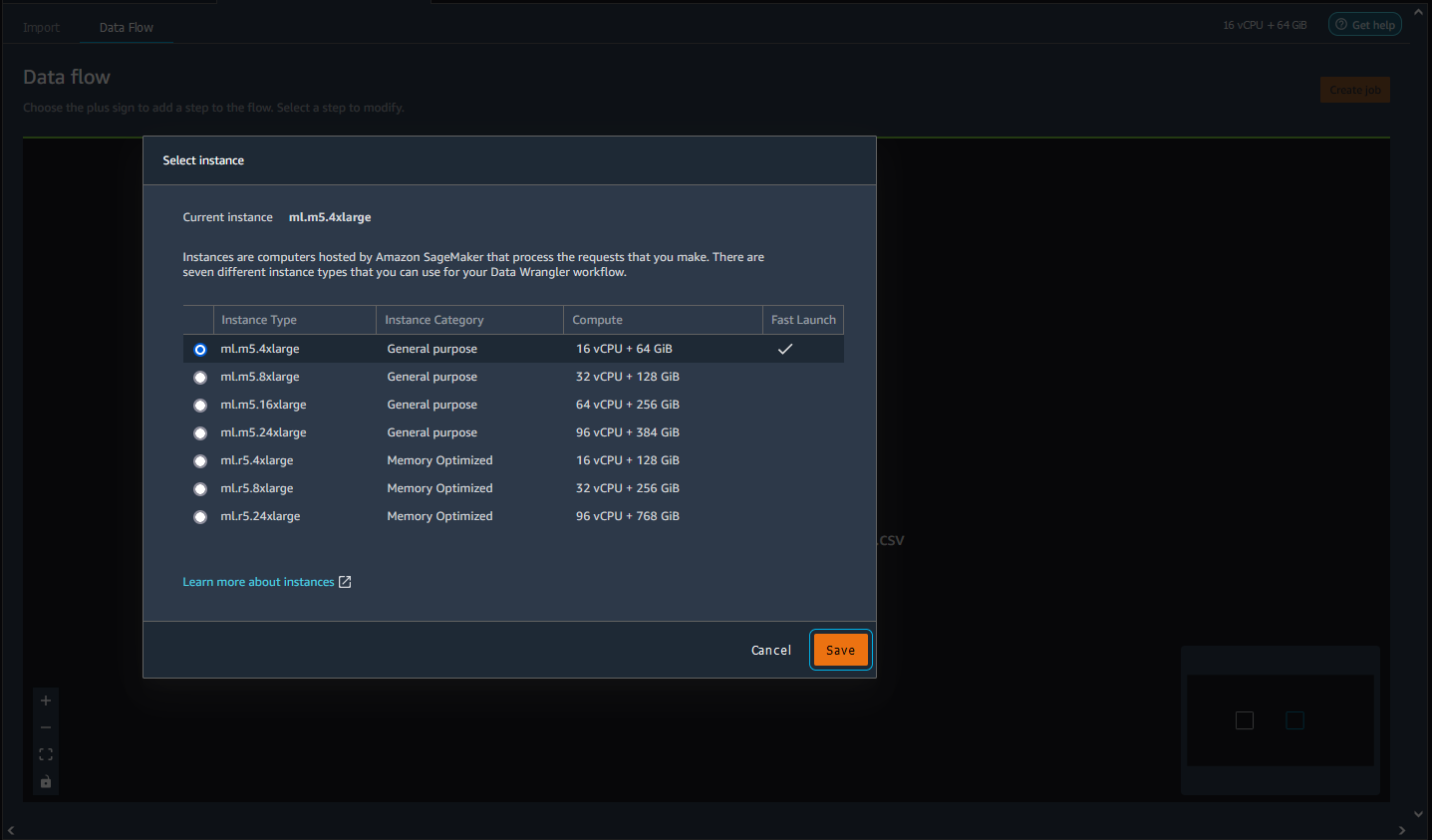
Para cambiar el tipo de instancia del flujo, haga lo siguiente.
-
Elija el icono de Terminales y kernels en ejecución (
 ).
). -
Vaya a la instancia que utiliza y elíjala.
-
Elija el tipo de instancia que desea utilizar.
-
Seleccione Save.
Se cobrará por todas las instancias en ejecución. Para evitar incurrir en cargos adicionales, apague manualmente las instancias que no utilice. Utilice el siguiente procedimiento para apagar una instancia en ejecución.
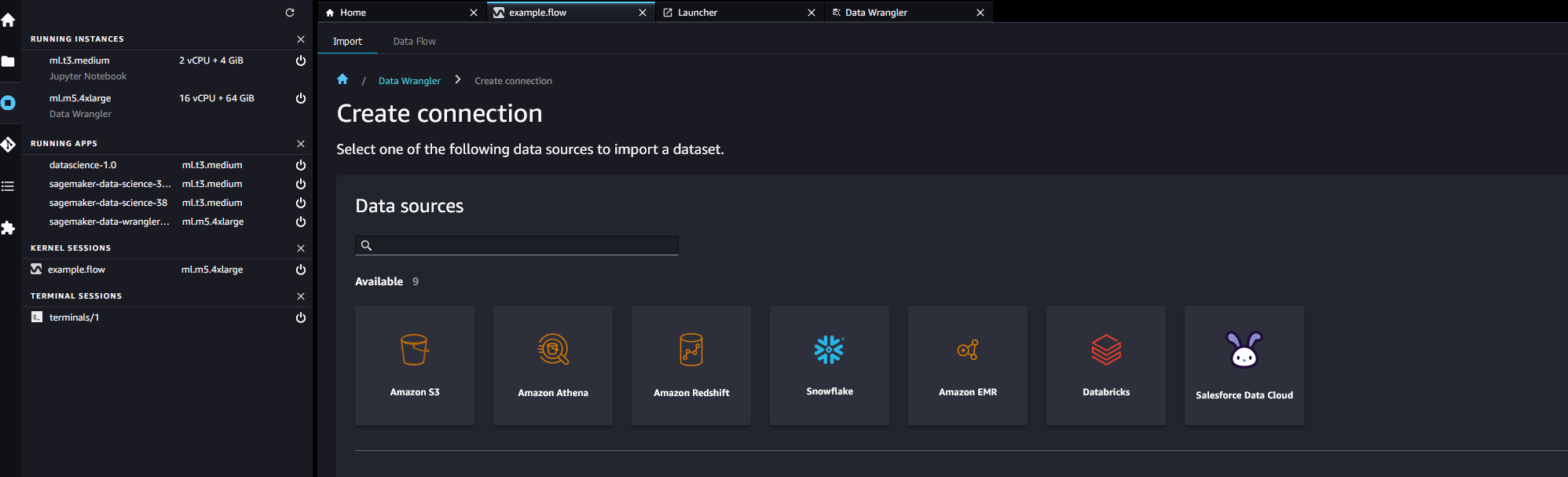
Para apagar una instancia en ejecución.
-
Elija el icono de instancia. La siguiente imagen muestra dónde seleccionar el icono de INSTANCIAS EN EJECUCIÓN.
-
Elija Apagar junto a la instancia que desee apagar.
Si apaga una instancia utilizada para ejecutar un flujo, no podrás acceder al flujo temporalmente. Si recibe un error al intentar abrir un flujo que ejecuta una instancia que apagó previamente, espere 5 minutos e intente abrirlo de nuevo.
Cuando exporta su flujo de datos a una ubicación como Amazon Simple Storage Service o Amazon SageMaker Feature Store, Data Wrangler ejecuta un trabajo de SageMaker procesamiento de Amazon. Puede utilizar una de las siguientes instancias para el trabajo de procesamiento. Para obtener más información sobre la exportación de datos, consulte Exportación.
| Instancia estándar | vCPU | Memoria |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 GiB |
| ml.m5.12xlarge | 48 |
192 GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
La interfaz de usuario del flujo de datos
Al importar un conjunto de datos, el conjunto de datos original aparece en el flujo de datos y se denomina Origen. Si activó el muestreo al importar los datos, este conjunto de datos se denomina Origen: muestreado. Data Wrangler infiere automáticamente los tipos de cada columna de su conjunto de datos y crea un nuevo marco de datos denominado Tipos de datos. Puede seleccionar este marco para actualizar los tipos de datos inferidos. Verá resultados similares a los que se muestran en la siguiente imagen después de cargar un conjunto de datos:
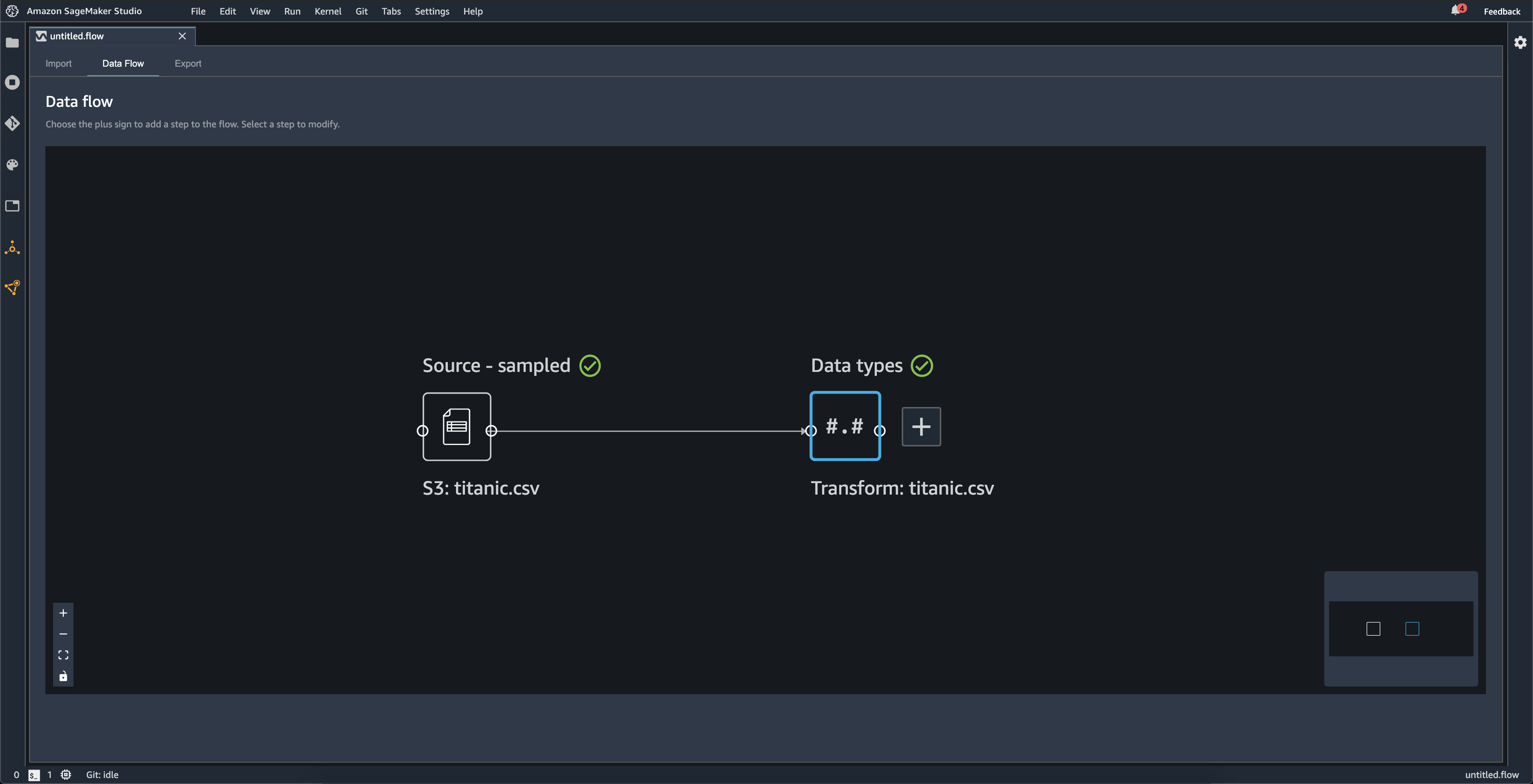
Cada vez que agregue un paso de transformación, creará un marco de datos nuevo. Cuando se agregan varios pasos de transformación (salvo Unir o Concatenar) al mismo conjunto de datos, estos se apilan.
Unir y Concatenar crean pasos independientes que contienen el nuevo conjunto de datos unido o concatenado.
El siguiente diagrama muestra un flujo de datos con una unión entre dos conjuntos de datos, así como dos pilas de pasos. La primera pila (Pasos [2]) agrega dos transformaciones al tipo inferido en el conjunto de datos de Tipos de datos. La pila descendente, o la pila de la derecha, agrega transformaciones al conjunto de datos resultantes de una unión denominada demo-join.
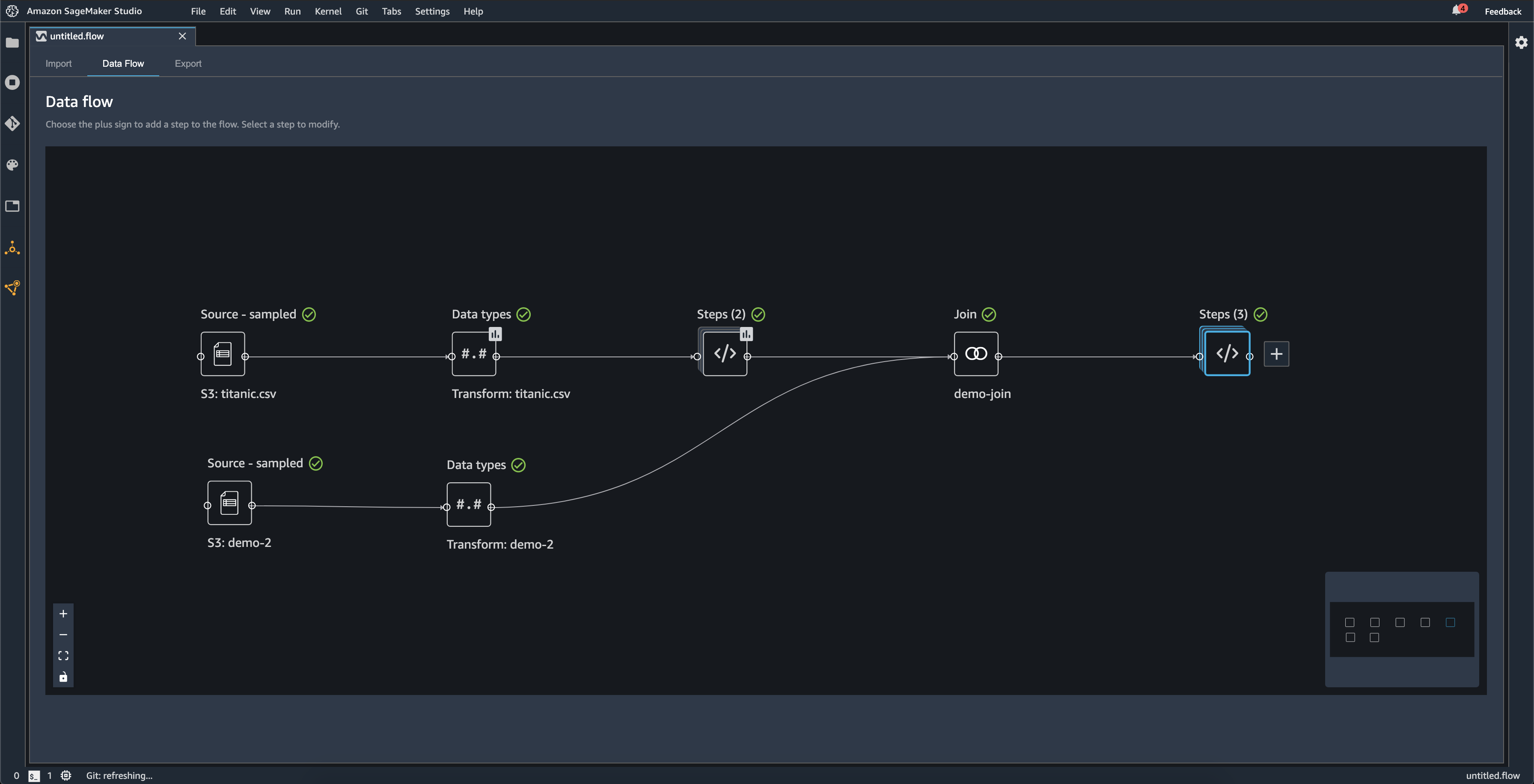
El pequeño cuadro gris situado en la esquina inferior derecha del flujo de datos proporciona una descripción general del número de pilas y pasos del flujo, así como del diseño del flujo. El cuadro más claro dentro del cuadro gris indica los pasos que se encuentran dentro de la vista de la interfaz de usuario. Puede usar este cuadro para ver las secciones del flujo de datos que quedan fuera de la vista de la interfaz de usuario. Use el icono de ajuste de pantalla (
 ) para incluir todos los pasos y conjuntos de datos en la vista de interfaz de usuario.
) para incluir todos los pasos y conjuntos de datos en la vista de interfaz de usuario.
La barra de navegación inferior izquierda incluye iconos que puede usar para acercar (
 ) y alejar (
) y alejar (
 ) el flujo de datos y cambiar el tamaño del flujo de datos para que se ajuste a la pantalla (
). Utilice el icono de bloqueo (
) el flujo de datos y cambiar el tamaño del flujo de datos para que se ajuste a la pantalla (
). Utilice el icono de bloqueo (
 ) para bloquear y desbloquear la ubicación de cada paso de la pantalla.
) para bloquear y desbloquear la ubicación de cada paso de la pantalla.
Adición de un paso al flujo de datos
Seleccione el signo + junto a cualquier conjunto de datos o paso agregado anteriormente y, a continuación, seleccione una de las siguientes opciones:
-
Editar tipos de datos (solo para un paso de Tipos de datos): si no ha agregado ninguna transformación a un paso de Tipos de datos, puede seleccionar Editar tipos de datos para actualizar los tipos de datos que Data Wrangler infirió al importar su conjunto de datos.
-
Agregar transformación: agrega un nuevo paso de transformación. Consulte Datos de transformación para obtener más información sobre las transformaciones de datos que puede agregar.
-
Agregar análisis: agrega un análisis. Puede utilizar esta opción para analizar los datos en cualquier punto del flujo de datos. Al agregar uno o más análisis a un paso, aparece un icono de análisis (
 ) en ese paso. Consulte Análisis y visualización para obtener más información sobre los análisis que puede agregar.
) en ese paso. Consulte Análisis y visualización para obtener más información sobre los análisis que puede agregar. -
Unir: une dos conjuntos de datos y agrega el conjunto de datos resultante al flujo de datos. Para obtener más información, consulte Unir conjuntos de datos.
-
Concatenar: concatena dos conjuntos de datos y agrega el conjunto de datos resultante al flujo de datos. Para obtener más información, consulte Concatenar conjuntos de datos.
Eliminación de un paso del flujo de datos
Para eliminar un paso, seleccione el paso y seleccione Eliminar. Si el nodo es un nodo que tiene una sola entrada, solo se elimina el paso que se seleccione. Cuando se elimina un paso que tiene una sola entrada, no se eliminan los pasos que le siguen. Si va a eliminar un paso de un nodo de origen, una unión o una concatenación, también se eliminarán todos los pasos siguientes.
Para eliminar un paso de una pila de pasos, seleccione la pila y, a continuación, seleccione el paso que desee eliminar.
Puede utilizar uno de los siguientes procedimientos para eliminar un paso sin eliminar los pasos posteriores.
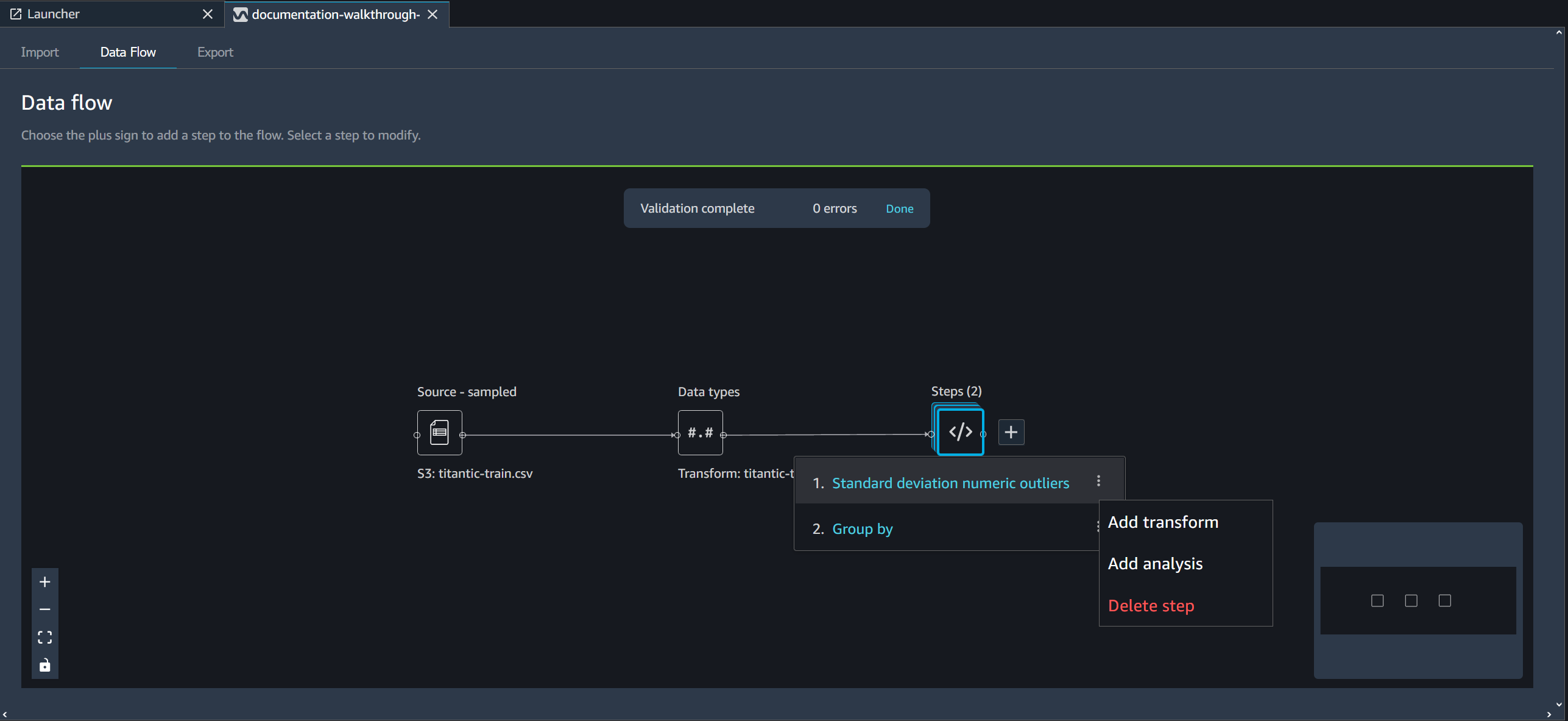
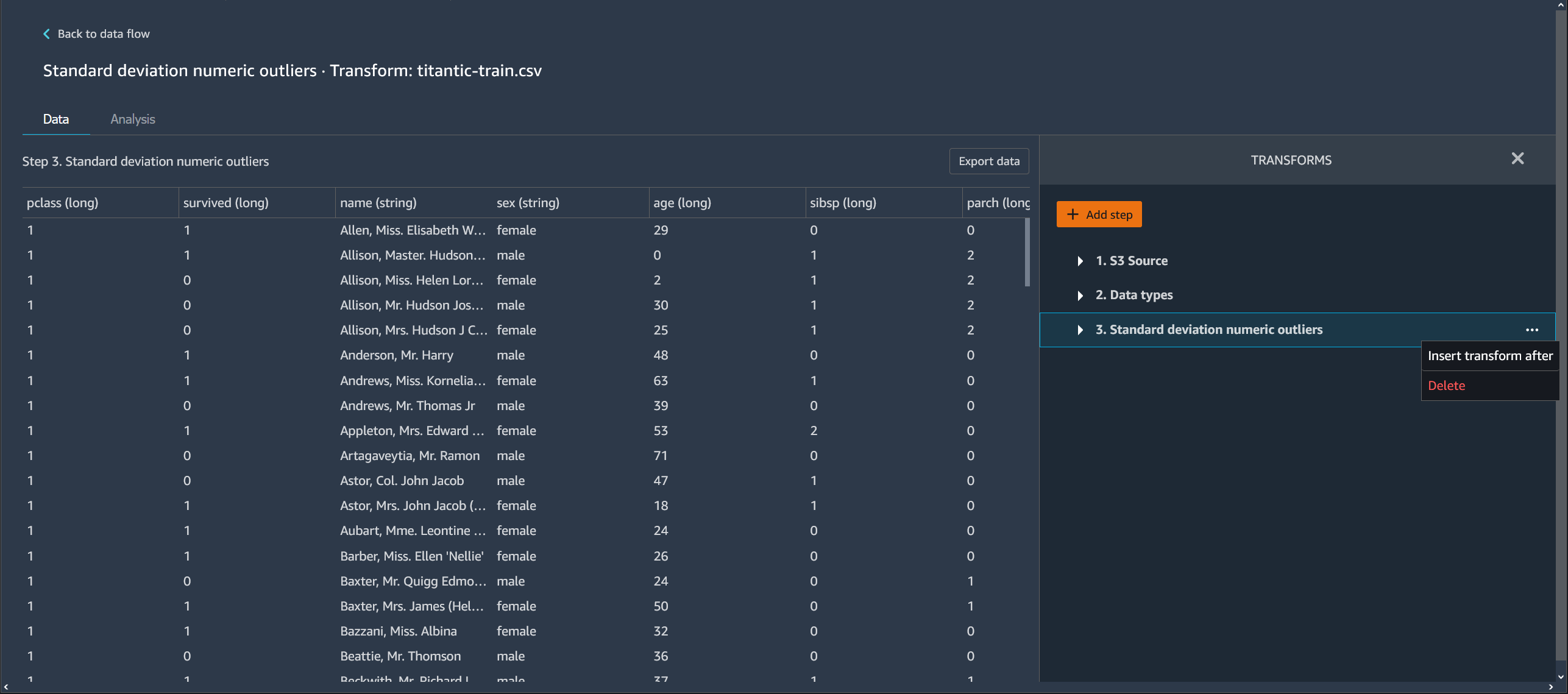
Edición de un paso del flujo de Data Wrangler
Puede editar cada paso que haya agregado al flujo de Data Wrangler. Al editar los pasos, puede cambiar las transformaciones o los tipos de datos de las columnas. Puede editar los pasos para realizar cambios que le permitan llevar a cabo mejores análisis.
Hay muchas maneras de editar un paso. Algunos ejemplos incluyen cambiar el método de imputación o cambiar el umbral para considerar que un valor es atípico.
Utilice el siguiente procedimiento para editar un paso.
Para editar un paso, haga lo siguiente.
-
Elija un paso del flujo de Data Wrangler para abrir la vista de tabla.
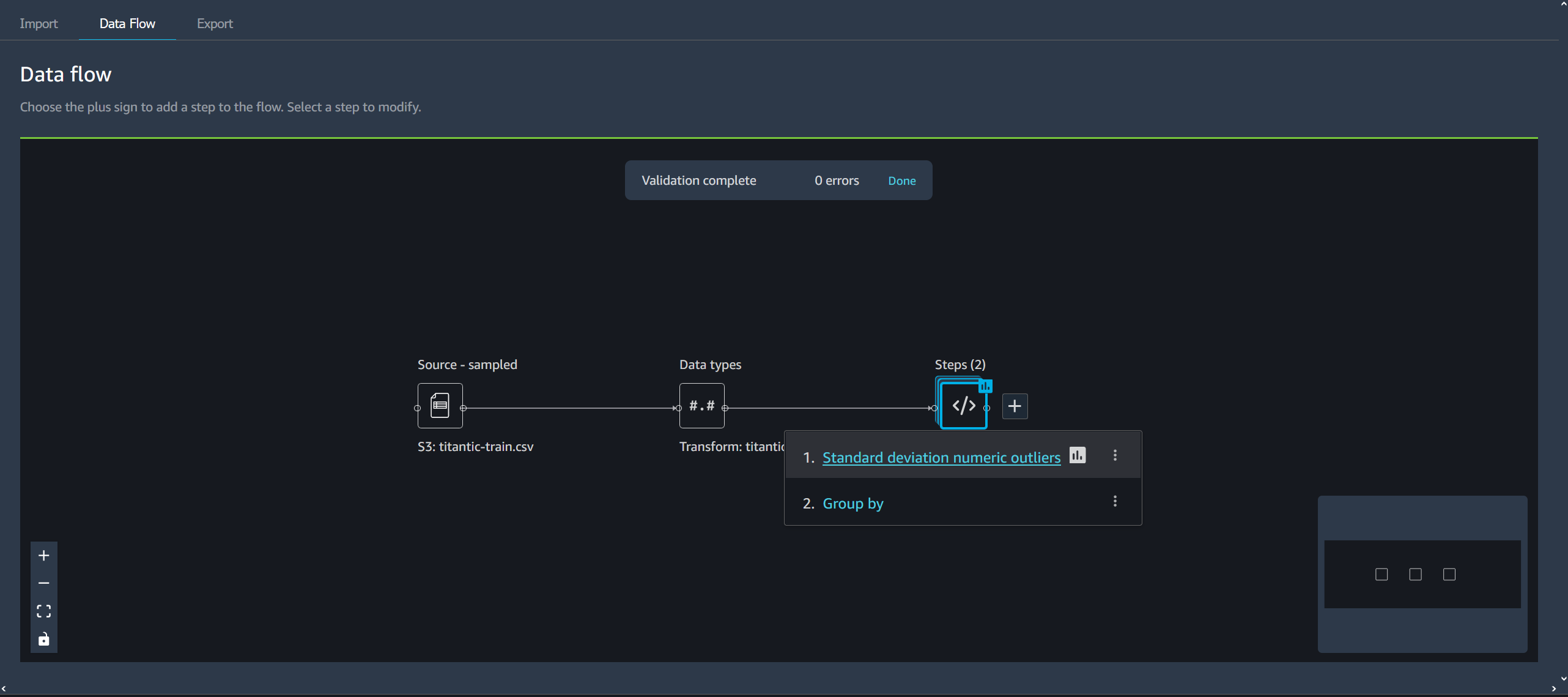
-
Elija un paso del flujo de datos.
-
Edite el paso.
En la siguiente imagen se muestra un ejemplo de edición de un paso.
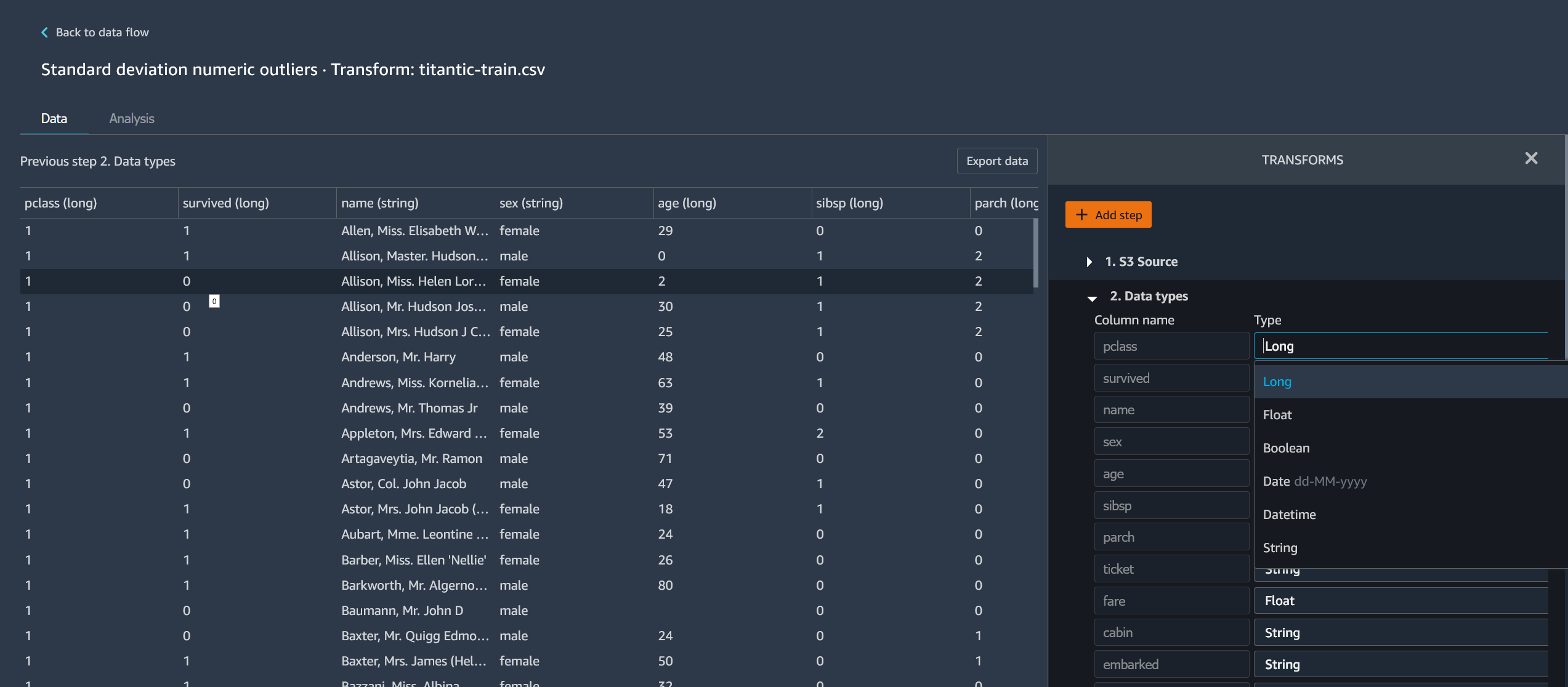
nota
Puedes usar los espacios compartidos de tu dominio de Amazon SageMaker AI para trabajar de forma colaborativa en tus flujos de Data Wrangler. Dentro de un espacio compartido, usted y sus colaboradores pueden editar un archivo de flujo en tiempo real. Sin embargo, ni usted ni sus colaboradores pueden ver los cambios en tiempo real. Cuando alguien realiza un cambio en el flujo de Data Wrangler, es preciso guardarlo inmediatamente. Cuando alguien guarde un archivo, un colaborador no podrá verlo a menos que cierre el archivo y lo vuelva a abrir. Los cambios que no guarde una persona los sobrescribirá otra persona que guarde sus propios cambios.
