Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Exportación
En el flujo de Data Wrangler, puede exportar algunas o todas las transformaciones que haya realizado a sus canalizaciones de procesamiento de datos.
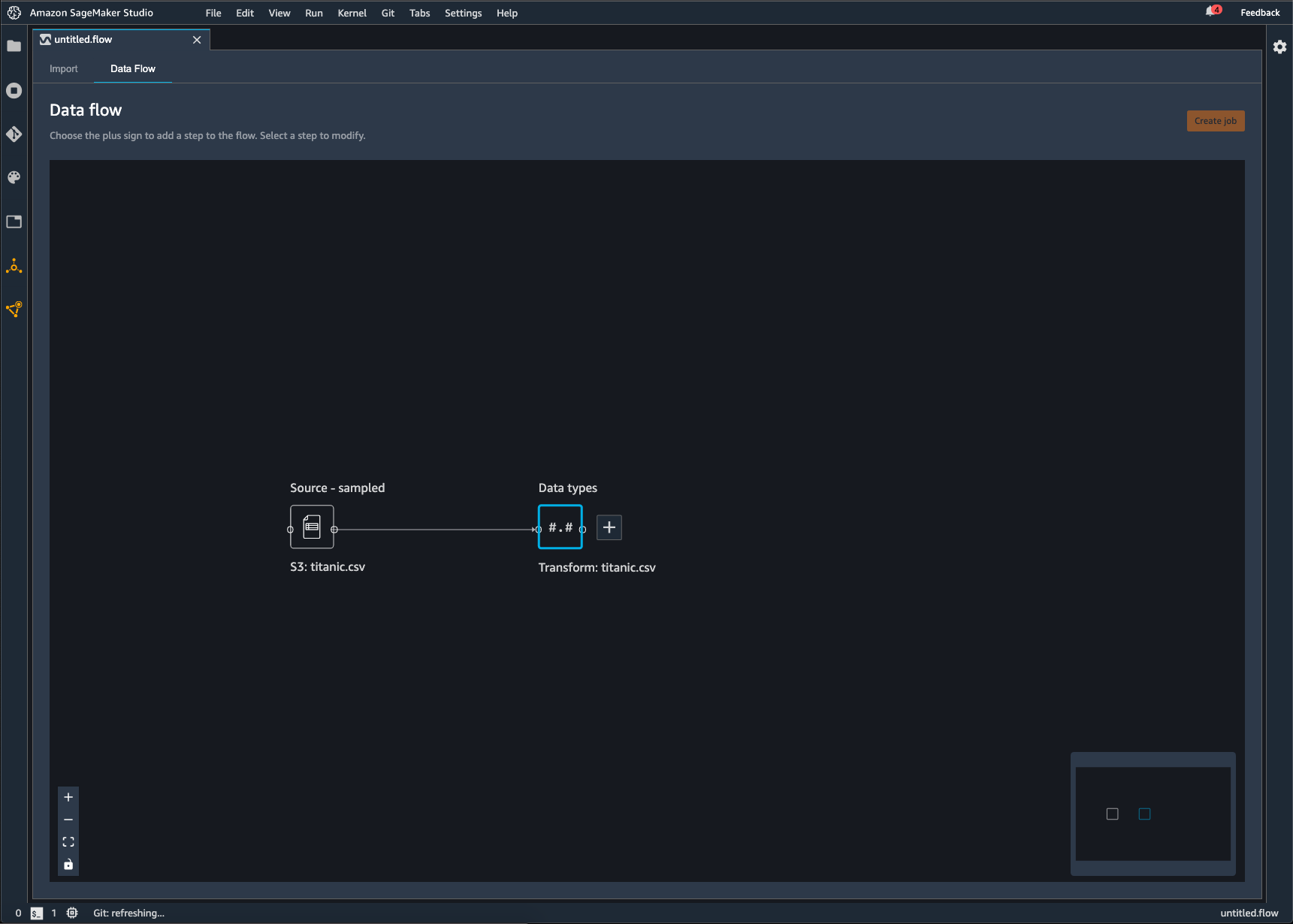
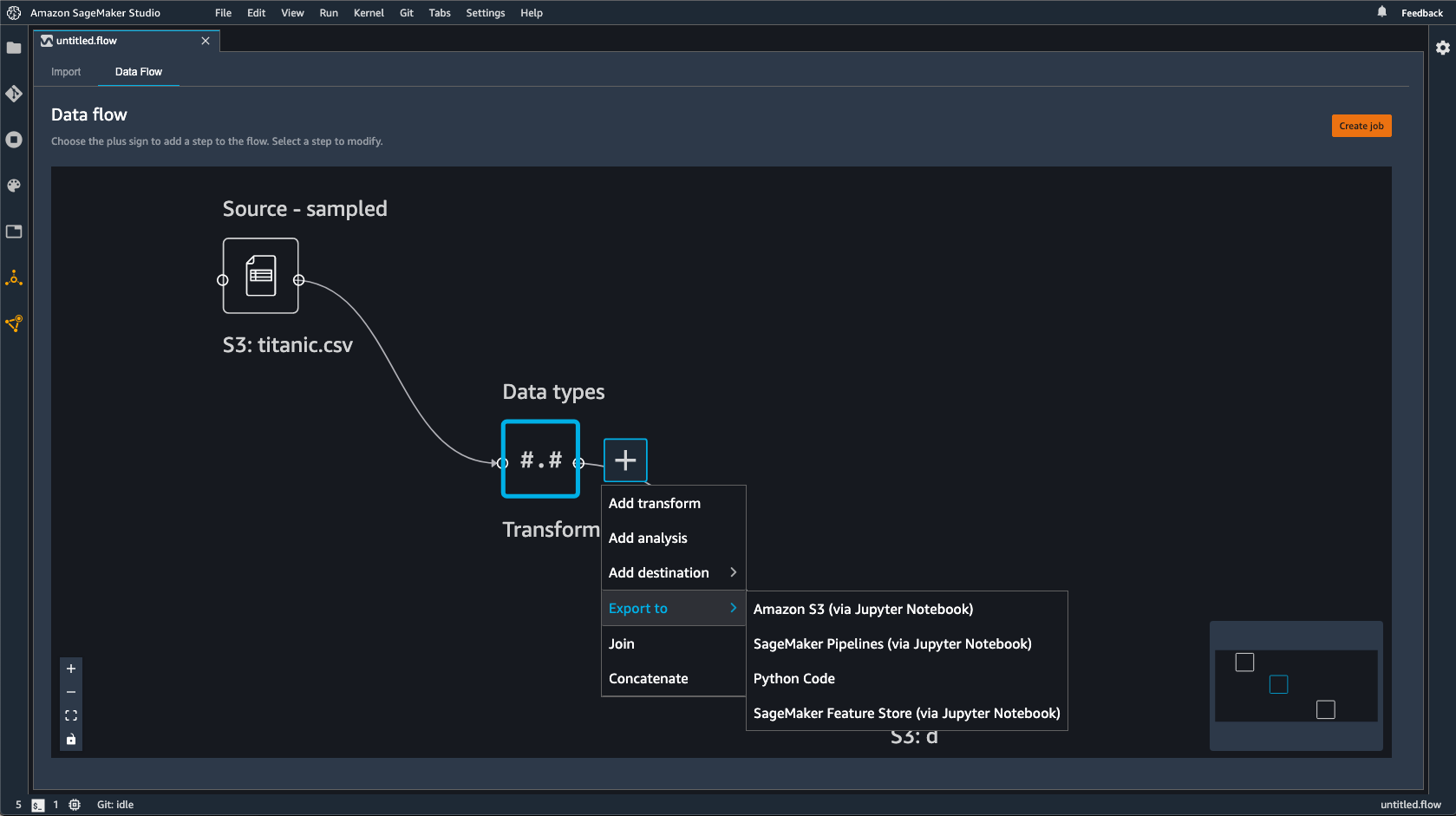
Un flujo de Data Wrangler es la serie de pasos de preparación de datos que ha realizado en sus datos. En la preparación de los datos, se llevan a cabo una o más transformaciones en los datos. Cada transformación se realiza mediante un paso de transformación. El flujo tiene una serie de nodos que representan la importación de los datos y las transformaciones que se han hecho. Para ver un ejemplo de nodos, consulte la siguiente imagen.
La imagen anterior muestra un flujo de Data Wrangler con dos nodos. El nodo Origen: muestreado muestra el origen de datos desde el que ha importado los datos. El nodo Tipos de datos indica que Data Wrangler ha realizado una transformación para convertir el conjunto de datos en un formato utilizable.
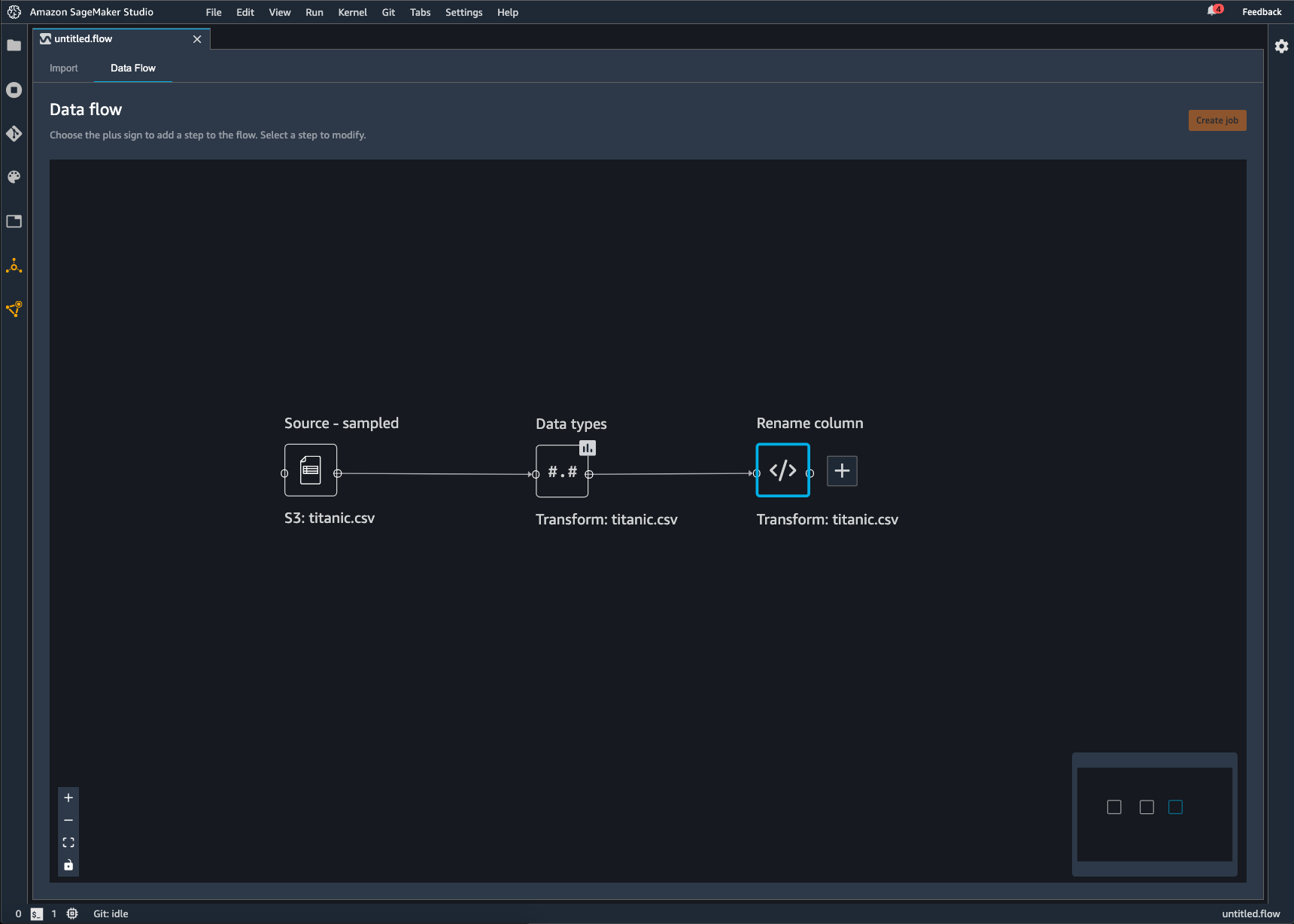
Cada transformación que agregue al flujo de Data Wrangler aparece como un nodo adicional. Para obtener información acerca de las transformaciones que puede agregar, consulte Datos de transformación. La siguiente imagen muestra un flujo de Data Wrangler que tiene un Rename-columnnodo para cambiar el nombre de una columna de un conjunto de datos.
Puede exportar las transformaciones de datos a lo siguiente:
Le recomendamos que utilice la política AmazonSageMakerFullAccess gestionada por IAM para conceder el AWS permiso de uso de Data Wrangler. Si no utiliza la política administrada, puede usar una política de IAM que permita a Data Wrangler acceder a un bucket de Amazon S3. Para obtener más información acerca de la política, consulte Seguridad y permisos.
Al exportar el flujo de datos, se le cobrará por los AWS recursos que utilice. Puede utilizar etiquetas de asignación de costos para organizar y administrar los costos de esos recursos. Usted crea estas etiquetas para su perfil de usuario y Data Wrangler las aplica automáticamente a los recursos utilizados para exportar el flujo de datos. Para obtener más información, consulte Uso de etiquetas de asignación de costes.
Exportar a Amazon S3.
Data Wrangler le permite exportar sus datos a una ubicación dentro de un bucket de Amazon S3. Puede especificar la ubicación mediante uno de los siguientes métodos:
-
Nodo de destino: donde Data Wrangler almacena los datos después de haberlos procesado.
-
Exportar a: exporta los datos resultantes de una transformación a Amazon S3.
-
Exportación de datos: en el caso de conjuntos de datos pequeños, puede exportar rápidamente los datos que ha transformado.
Utilice las siguientes secciones para obtener más información sobre cada uno de estos métodos.
- Destination Node
-
Si desea enviar una serie de pasos de procesamiento de datos que ha realizado a Amazon S3, debe crear un nodo de destino. Un nodo de destino indica a Data Wrangler dónde debe almacenar los datos después de haberlos procesado. Después de crear un nodo de destino, se crea un trabajo de procesamiento para generar los datos. Un trabajo de procesamiento es un trabajo de SageMaker procesamiento de Amazon. Cuando utiliza un nodo de destino, este ejecuta los recursos computacionales necesarios para enviar los datos que ha transformado a Amazon S3.
Puede utilizar un nodo de destino para exportar algunas de las transformaciones o todas las transformaciones que haya realizado en su flujo de Data Wrangler.
Puede utilizar varios nodos de destino para exportar diferentes transformaciones o conjuntos de transformaciones. El siguiente ejemplo muestra dos nodos de destino en un único flujo de Data Wrangler.
Puede utilizar el siguiente procedimiento para crear nodos de destino y exportarlos a un bucket de Amazon S3.
Para exportar el flujo de datos, debe crear nodos de destino y un trabajo de Data Wrangler para exportar los datos. Al crear un trabajo de Data Wrangler, se inicia un trabajo SageMaker de procesamiento para exportar el flujo. Puede elegir los nodos de destino que desea exportar después de haberlos creado.
Puede elegir Crear trabajo en el flujo de Data Wrangler para ver las instrucciones para utilizar un trabajo de procesamiento.
Utilice el siguiente procedimiento para crear nodos de destino.
-
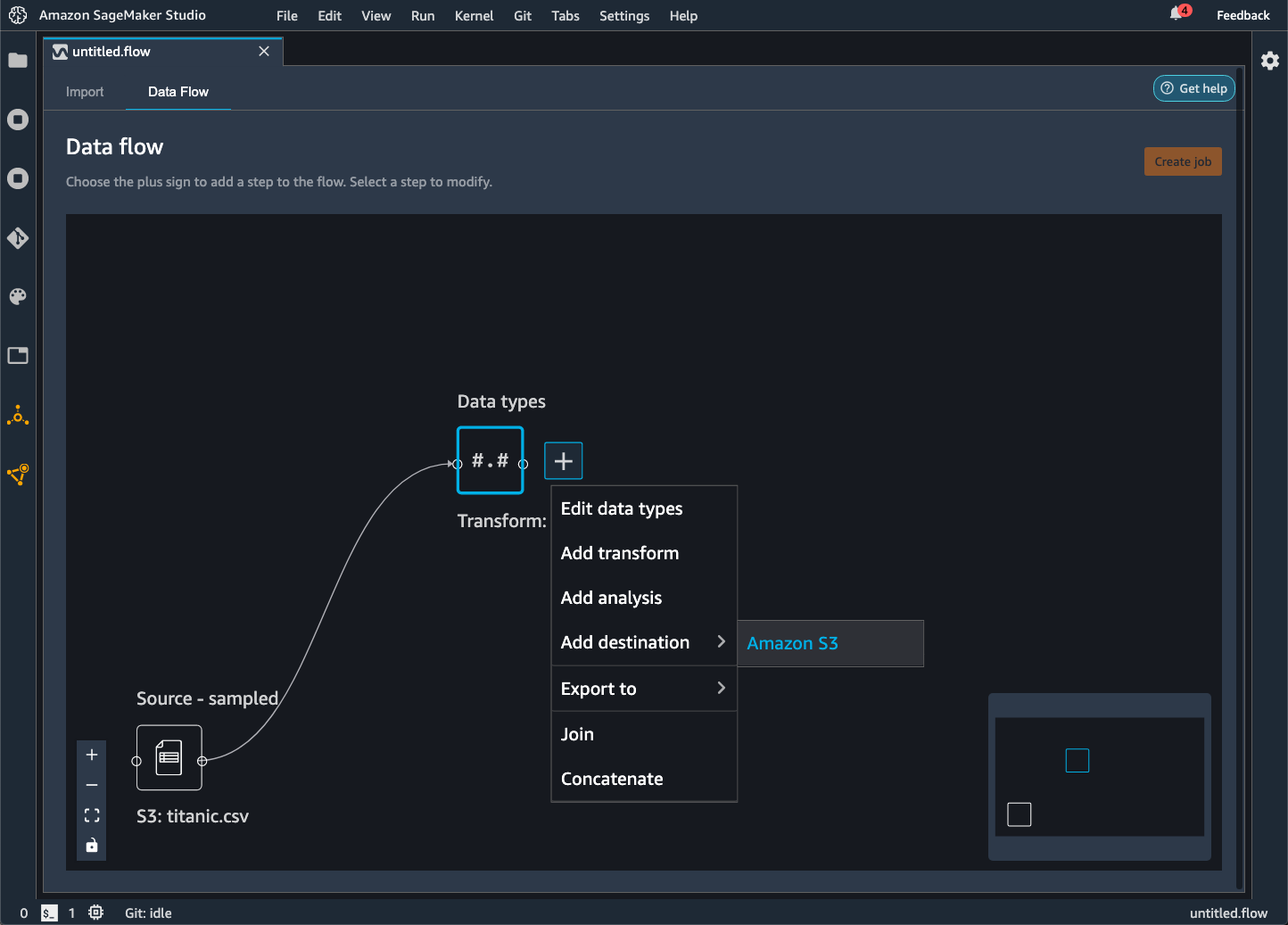
Seleccione el signo + situado junto a los nodos que representan las transformaciones que desee exportar.
-
Elija Add destination.
-
Seleccione Amazon S3.
-
Especifique los siguientes campos.
-
Nombre del conjunto de datos: el nombre que especifique para el conjunto de datos que va a exportar.
-
Tipo de archivo: el formato del archivo que va a exportar.
-
Delimitador (solo archivos CSV y Parquet): el valor que se utiliza para separar otros valores.
-
Compresión (solo archivos CSV y Parquet): método de compresión utilizado para reducir el tamaño del archivo. Puede usar los siguientes métodos de compresión:
-
(Opcional) Ubicación de Amazon S3: la ubicación de S3 que utiliza para enviar los archivos.
-
(Opcional) Número de particiones: el número de conjuntos de datos que escribe como salida del trabajo de procesamiento.
-
(Opcional) Partición por columna: escribe todos los datos de la columna con el mismo valor único.
-
(Opcional) Parámetros de inferencia: si selecciona Generar artefacto de inferencia, se aplican todas las transformaciones que haya utilizado en el flujo de Data Wrangler a los datos que llegan a su canalización de inferencia. El modelo en su canalización hace predicciones sobre los datos transformados.
-
Elija Add destination.
Use el procedimiento siguiente para crear un trabajo de procesamiento.
Cree un trabajo desde la página Flujo de datos y elija los nodos de destino que desee exportar.
Puede elegir Crear trabajo en el flujo de Data Wrangler para ver las instrucciones para crear un trabajo de procesamiento.
-
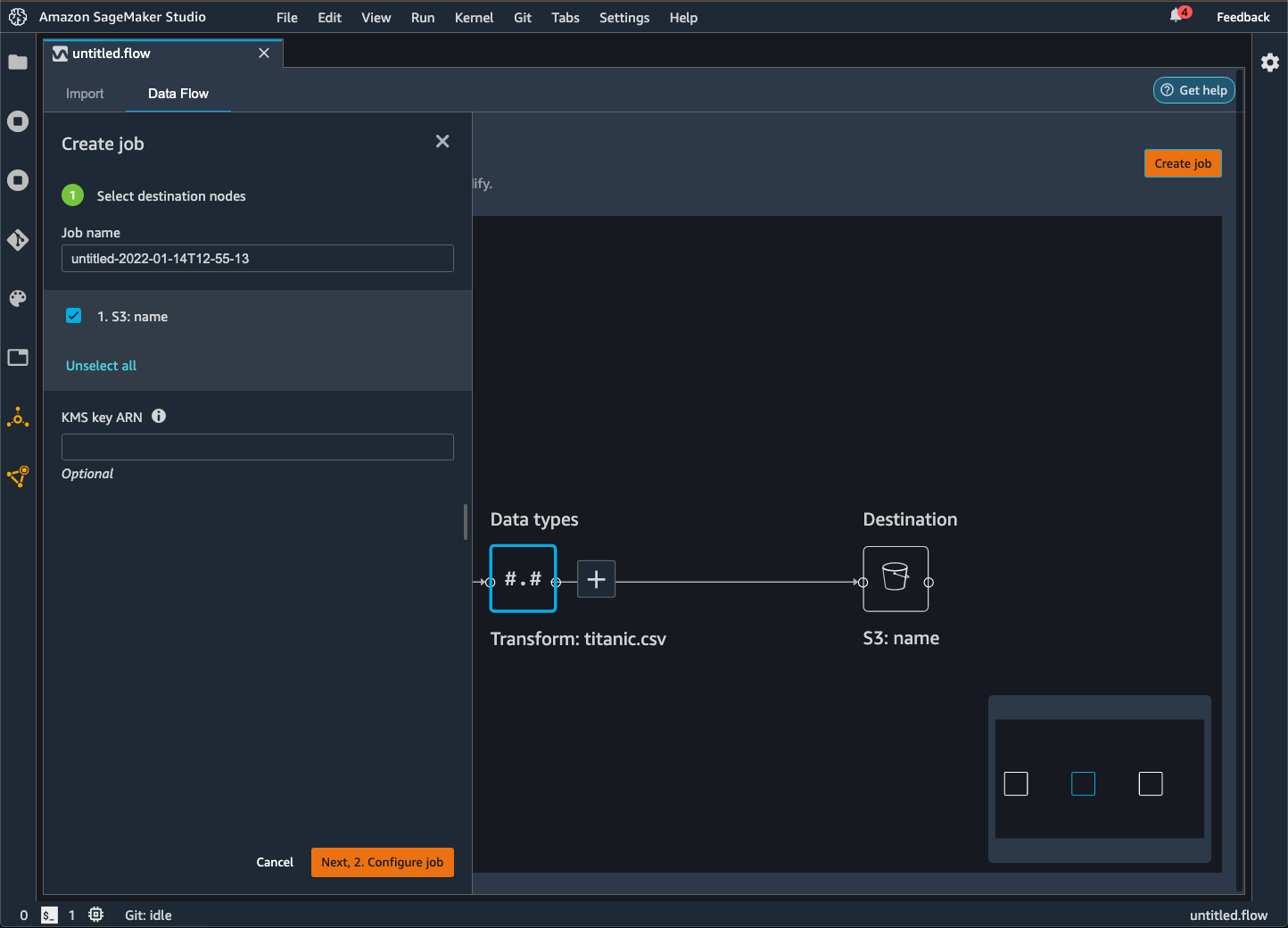
Seleccione Crear tarea. La siguiente imagen muestra el panel que aparece después de seleccionar Crear trabajo.
-
En Nombre del trabajo, especifique el nombre del trabajo de exportación.
-
Elija los nodos de destino que desea exportar.
-
(Opcional) Especifique un AWS KMS ARN clave. Una AWS KMS clave es una clave criptográfica que puede usar para proteger sus datos. Para obtener más información sobre AWS KMS las claves, consulte AWS Key Management Service.
-
De forma opcional, en Parámetros entrenados, elija Reajustar si ha hecho lo siguiente:
Para obtener más información sobre cómo reajustar las transformaciones que ha realizado a un conjunto de datos completo, consulte Reajuste de las transformaciones a todo el conjunto de datos y exportación.
Para los datos de imagen, Data Wrangler exporta las transformaciones que ha llevado a cabo a todas las imágenes. El reajuste de las transformaciones no es aplicable a su caso de uso.
-
Elija Configurar trabajo. La siguiente imagen muestra la página Configuración del trabajo.
-
De forma opcional, configure el trabajo de Data Wrangler. Puede hacer las siguientes configuraciones:
-
Configuración del trabajo
-
Configuración de memoria Spark
-
Configuración de red
-
Etiquetas
-
Parámetros
-
Horarios de los asociados
-
Seleccione Ejecutar.
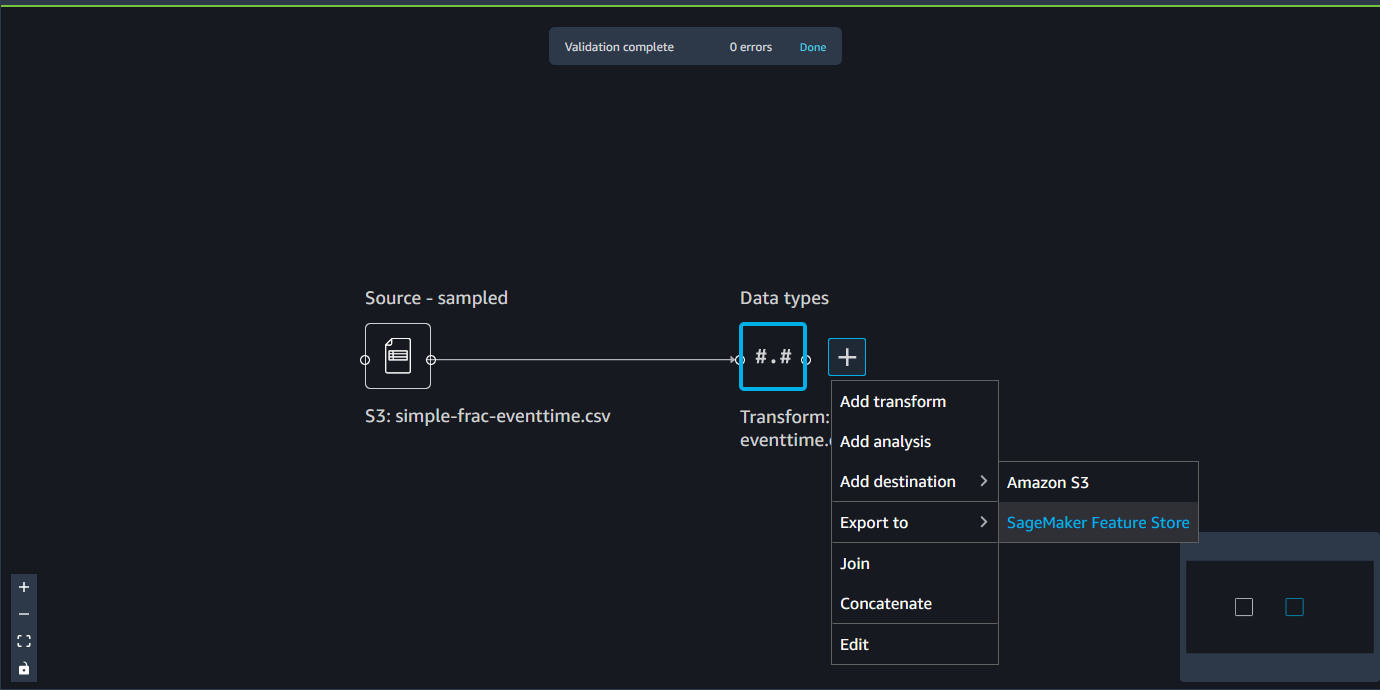
- Export to
-
Como alternativa al uso de un nodo de destino, puede utilizar la opción Exportar a para exportar el flujo de Data Wrangler a Amazon S3 mediante un cuaderno de Jupyter. Puede elegir cualquier nodo de datos del flujo de Data Wrangler y exportarlo. Al exportar el nodo de datos, se exporta la transformación que representa el nodo y las transformaciones que la preceden.
Utilice el siguiente procedimiento para generar un cuaderno de Jupyter y ejecútelo para exportar el flujo de Data Wrangler a Amazon S3.
-
Elija el signo + junto al nodo que desea exportar.
-
Elija Exportar a.
-
Elija Amazon S3 (a través del cuaderno de Jupyter).
-
Ejecute el cuaderno de Jupyter.
Cuando ejecuta el bloc de notas, exporta su flujo de datos (archivo.flow) de la Región de AWS misma manera que el flujo de Data Wrangler.
El cuaderno ofrece opciones que puede utilizar para configurar el trabajo de procesamiento y los datos que envía.
Le proporcionamos configuraciones de trabajo para configurar la salida de los datos. En cuanto a las opciones de particionamiento y memoria del controlador, se recomienda encarecidamente que no especifique ninguna configuración a menos que tenga conocimientos sobre ellas.
En Configuraciones del trabajo, puede configurar lo siguiente:
-
output_content_type: el tipo de contenido del archivo de salida. Se utiliza CSV como formato predeterminado, pero puede especificar Parquet.
-
delimiter: el carácter que se utiliza para separar los valores del conjunto de datos al escribir en un archivo CSV.
-
compression: si se ha definido, comprime el archivo de salida. Se utiliza el formato de compresión gzip de forma predeterminada.
-
num_partitions: el número de particiones o archivos que Data Wrangler escribe como salida.
-
partition_by: los nombres de las columnas que se utilizan para particionar la salida.
Para cambiar el formato del archivo de salida de CSV a Parquet, cambie el valor de "CSV" a "Parquet". En el resto de los campos anteriores, quite los comentarios de las líneas que contienen los campos que desee especificar.
En Configurar la memoria del controlador de clúster de Spark (opcional), puede configurar las propiedades de Spark para el trabajo, como la memoria del controlador de Spark, en el diccionario config.
A continuación se muestra el diccionario config.
config = json.dumps({
"Classification": "spark-defaults",
"Properties": {
"spark.driver.memory": f"{driver_memory_in_mb}m",
}
})
Para aplicar la configuración al trabajo de procesamiento, quite los comentarios de las siguientes líneas:
# data_sources.append(ProcessingInput(
# source=config_s3_uri,
# destination="/opt/ml/processing/input/conf",
# input_name="spark-config",
# s3_data_type="S3Prefix",
# s3_input_mode="File",
# s3_data_distribution_type="FullyReplicated"
# ))
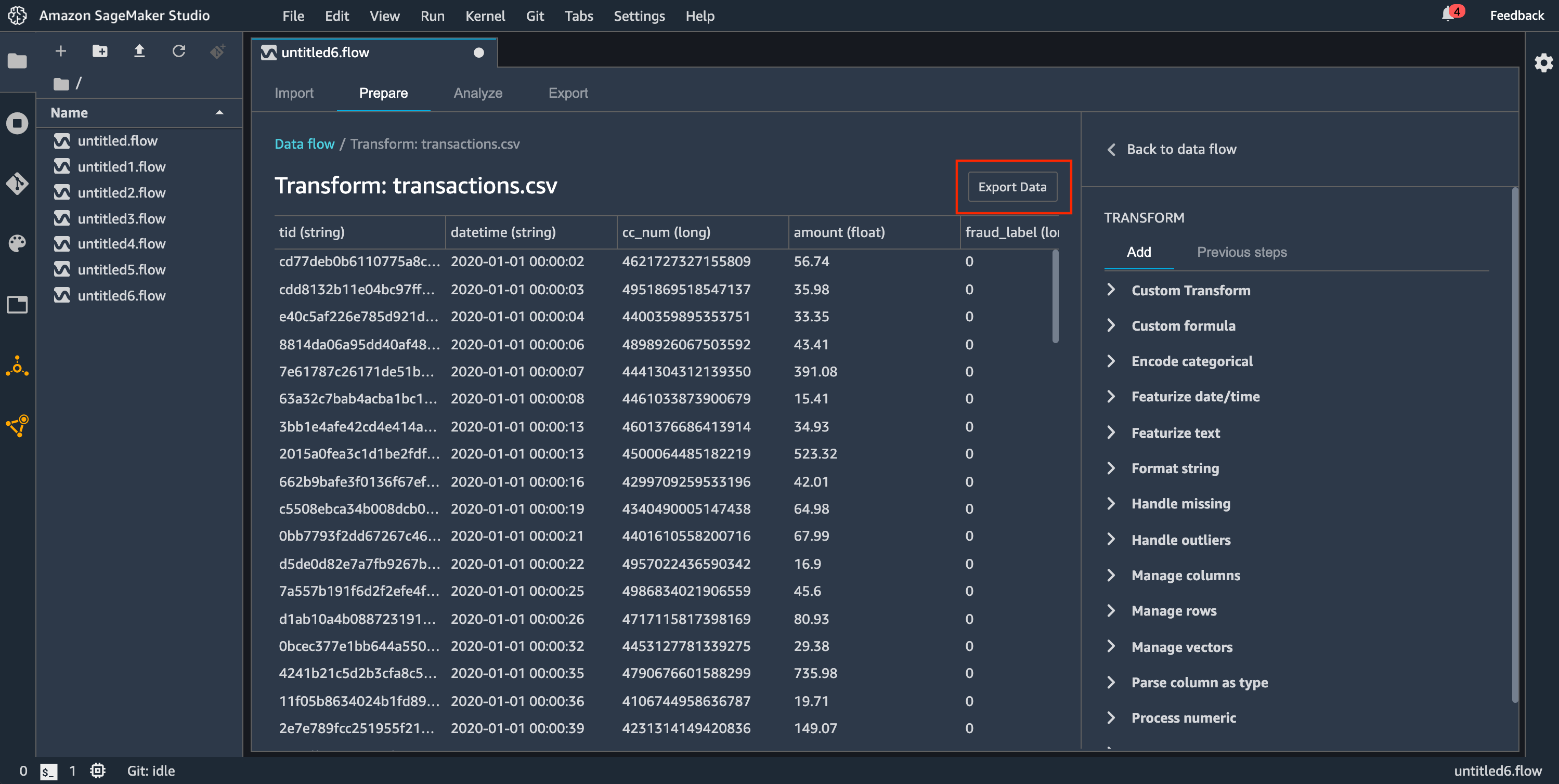
- Export data
-
Si tiene una transformación en un conjunto de datos pequeño que desea exportar rápidamente, puede utilizar el método Exportar datos. Cuando elige Exportar datos, Data Wrangler trabaja de forma sincrónica para exportar los datos que haya transformado a Amazon S3. No puede utilizar Data Wrangler hasta que termine de exportar los datos o hasta que cancele la operación.
Para obtener información sobre el uso del método Exportar datos en el flujo de Data Wrangler, consulte el siguiente procedimiento.
Para utilizar el método Exportar datos:
-
Elija un nodo en el flujo de Data Wrangler abriéndolo (haga doble clic en él).
-
Configure cómo quiere exportar los datos.
-
Elija Exportar datos.
Cuando exporta el flujo de datos a un bucket de Amazon S3, Data Wrangler almacena una copia del archivo de flujo en el bucket de S3. El archivo de flujo se almacena con el prefijo data_wrangler_flows. Si utiliza el bucket de Amazon S3 predeterminado para almacenar los archivos de flujo, se utiliza la siguiente convención de nomenclatura: sagemaker-region-account
number. Por ejemplo, si su número de cuenta es 111122223333 y utiliza Studio Classic en us-east-1, los conjuntos de datos importados se almacenan en sagemaker-us-east-1-111122223333. En este ejemplo, los archivos .flow creados en us-east-1 se almacenan en s3://sagemaker-region-account
number/data_wrangler_flows/.
Exportación a canalizaciones
Si quieres crear e implementar flujos de trabajo de aprendizaje automático (ML) a gran escala, puedes usar Pipelines para crear flujos de trabajo que gestionen e implementen trabajos de IA. SageMaker Con Pipelines, puedes crear flujos de trabajo que gestionen la preparación de datos de SageMaker IA, la formación de modelos y los trabajos de despliegue de modelos. Puedes usar los algoritmos propios que ofrece la SageMaker IA mediante Pipelines. Para obtener más información sobre Pipelines, consulta Pipelines. SageMaker
Cuando exporta uno o más pasos de su flujo de datos a Canalizaciones, Data Wrangler crea un cuaderno de Jupyter que puede utilizar para definir, instanciar, ejecutar y administrar una canalización.
Uso de un cuaderno de Jupyter para crear una canalización
Utilice el siguiente procedimiento para crear un cuaderno de Jupyter para exportar el flujo de Data Wrangler a Canalizaciones.
Utilice el siguiente procedimiento para generar un cuaderno de Jupyter y ejecutarlo para exportar el flujo de Data Wrangler a Canalizaciones.
-
Elija el signo + junto al nodo que desea exportar.
-
Elija Exportar a.
-
Elija Canalizaciones (a través del cuaderno de Jupyter).
-
Ejecute el cuaderno de Jupyter.
Puede utilizar el cuaderno de Jupyter que produce Data Wrangler para definir una canalización. La canalización incluye los pasos de procesamiento de datos definidos por el flujo de Data Wrangler.
Puede agregar pasos adicionales a la canalización si agrega pasos a la lista steps que aparece en el siguiente código del cuaderno:
pipeline = Pipeline(
name=pipeline_name,
parameters=[instance_type, instance_count],
steps=[step_process], #Add more steps to this list to run in your Pipeline
)
Para obtener más información sobre la definición de canalizaciones, consulta Definir SageMaker canalización de IA.
Exportación a un punto de conexión de inferencia
Utilice su flujo de Data Wrangler para procesar los datos en el momento de la inferencia creando una canalización de inferencia en serie de SageMaker IA a partir de su flujo de Data Wrangler. Una canalización de inferencia es una serie de pasos que dan como resultado que un modelo entrenado haga predicciones a partir de nuevos datos. Una canalización de inferencia en serie dentro de Data Wrangler transforma los datos sin procesar y los proporciona al modelo de machine learning para que realice una predicción. La canalización de inferencia se crea, ejecuta y administra desde un cuaderno de Jupyter en Studio Classic. Para obtener más información acerca de cómo acceder al cuaderno, consulte Uso de un cuaderno de Jupyter para crear un punto de conexión de inferencia.
En el cuaderno, puede entrenar un modelo de machine learning o especificar uno que ya haya entrenado. Puedes usar Amazon SageMaker Autopilot o XGBoost para entrenar el modelo con los datos que has transformado en tu flujo de Data Wrangler.
La canalización permite realizar inferencias por lotes o en tiempo real. También puede añadir el flujo de Data Wrangler a Model Registry. SageMaker Para obtener más información acerca de los modelos de alojamiento, consulte Multi-model puntos finales.
No puede exportar el flujo de Data Wrangler a un punto de conexión de inferencia si tiene las siguientes transformaciones:
-
Join
-
Concatenar
-
Agrupación por
Si tiene que usar las transformaciones anteriores para preparar los datos, use el siguiente procedimiento.
Para preparar los datos para la inferencia con transformaciones no compatibles
-
Cree un flujo de Data Wrangler.
-
Aplique las transformaciones anteriores que no son compatibles.
-
Exporte los datos a un bucket de Amazon S3.
-
Cree un flujo de Data Wrangler independiente.
-
Importe los datos que haya exportado del flujo anterior.
-
Aplique el resto de las transformaciones.
-
Cree una canalización de inferencia en serie con el cuaderno de Jupyter que le proporcionamos.
Para obtener información sobre la exportación de datos a un bucket de Amazon S3, consulte Exportar a Amazon S3.. Para obtener información sobre cómo abrir el cuaderno de Jupyter utilizado para crear la canalización de inferencia en serie, consulte Uso de un cuaderno de Jupyter para crear un punto de conexión de inferencia.
Data Wrangler hace caso omiso de las transformaciones que eliminan datos en el momento de la inferencia. Por ejemplo, Data Wrangler hace caso omiso de la transformación Gestión de valores que faltan si utiliza la configuración Eliminar ausentes.
Si ha modificado las transformaciones de todo el conjunto de datos, las transformaciones se aplicarán a la canalización de inferencia. Por ejemplo, si empleó el valor de la mediana para imputar los valores ausentes, el valor de la mediana resultante del reajuste de la transformada se aplica a las solicitudes de inferencia. Puede reajustar las transformaciones del flujo de Data Wrangler cuando utilice el cuaderno de Jupyter o cuando exporte los datos a una canalización de inferencia. Para obtener información acerca del reajuste de las transformaciones, consulte Reajuste de las transformaciones a todo el conjunto de datos y exportación.
La canalización de inferencia en serie admite los siguientes tipos de datos para las cadenas de entrada y salida. Cada tipo de datos tiene un conjunto de requisitos.
Tipos de datos admitidos
-
text/csv: el tipo de datos de las cadenas CSV.
-
La cadena no puede tener un encabezado.
-
Las características utilizadas para la canalización de inferencia deben estar en el mismo orden que las características del conjunto de datos de entrenamiento.
-
Debe haber un delimitador de coma entre las características.
-
Los registros deben estar delimitados por un carácter de nueva línea.
A continuación, se muestra un ejemplo de una cadena CSV con un formato válido que puede proporcionar en una solicitud de inferencia.
abc,0.0,"Doe, John",12345\ndef,1.1,"Doe, Jane",67890
-
application/json: el tipo de datos de las cadenas JSON.
-
Las características utilizadas para la canalización de inferencia deben estar en el mismo orden que las características del conjunto de datos de entrenamiento.
-
Los datos deben tener un esquema específico. El esquema se define como un objeto instances único que tiene un conjunto de features. Cada objeto features representa una observación.
A continuación, se muestra un ejemplo de una cadena JSON con un formato válido que puede proporcionar en una solicitud de inferencia.
{
"instances": [
{
"features": ["abc", 0.0, "Doe, John", 12345]
},
{
"features": ["def", 1.1, "Doe, Jane", 67890]
}
]
}
Uso de un cuaderno de Jupyter para crear un punto de conexión de inferencia
Utilice el siguiente procedimiento para exportar el flujo de Data Wrangler y crear una canalización de inferencia.
Para crear una canalización de inferencia con un cuaderno de Jupyter, haga lo siguiente.
-
Elija el signo + junto al nodo que desea exportar.
-
Elija Exportar a.
-
Elija SageMaker AI Inference Pipeline (a través de Jupyter Notebook).
-
Ejecute el cuaderno de Jupyter.
Al ejecutar el cuaderno de Jupyter, se crea un artefacto de flujo de inferencia. Un artefacto de flujo de inferencia es un archivo de flujo de Data Wrangler con metadatos adicionales que se utiliza para crear la canalización de inferencia en serie. El nodo que exporta incluye todas las transformaciones de los nodos anteriores.
Data Wrangler necesita el artefacto del flujo de inferencia para ejecutar la canalización de inferencia. No puede usar su propio archivo de flujo como artefacto. Debe crearlo mediante el procedimiento anterior.
Exportación a código Python
Para exportar todos los pasos del flujo de datos a un archivo de Python que pueda integrar manualmente en cualquier flujo de trabajo de procesamiento de datos, utilice el siguiente procedimiento.
Utilice el siguiente procedimiento para generar un cuaderno de Jupyter y ejecútelo para exportar el flujo de Data Wrangler a Python.
-
Elija el signo + junto al nodo que desea exportar.
-
Elija Exportar a.
-
Elija Código Python.
-
Ejecute el cuaderno de Jupyter.
Es posible que tenga que configurar el script de Python para que se ejecute en su canalización. Por ejemplo, si ejecutas un entorno de Spark, asegúrate de ejecutar el script desde un entorno que tenga permiso para acceder a los recursos. AWS
Exportar a Amazon SageMaker Feature Store
Puedes usar Data Wrangler para exportar las funciones que has creado a Amazon SageMaker Feature Store. Una característica es una columna de su conjunto de datos. El almacén de características es un almacén centralizado de las características y sus metadatos asociados. Puede usar el almacén de características para crear, compartir y administrar datos seleccionados para el desarrollo de machine learning (ML). Los almacenes centralizados hacen que los datos sean más fáciles de localizar y reutilizables. Para obtener más información sobre Feature Store, consulta Amazon SageMaker Feature Store.
Un concepto fundamental del almacén de características es el grupo de características. Un grupo de características es una colección de características, sus registros (observaciones) y los metadatos asociados. Es similar a una tabla de una base de datos.
Puede utilizar Data Wrangler para realizar una de las siguientes acciones:
-
Actualice un grupo de características existente con nuevos registros. Un registro es una observación en el conjunto de datos.
-
Cree un nuevo grupo de características a partir de un nodo en su flujo de Data Wrangler. Data Wrangler agrega las observaciones de sus conjuntos de datos como registros en su grupo de características.
Si va a actualizar un grupo de características existente, el esquema de su conjunto de datos debe coincidir con el esquema del grupo de características. Todos los registros del grupo de características se reemplazan por las observaciones del conjunto de datos.
Puede usar un cuaderno de Jupyter o un nodo de destino para actualizar su grupo de características con las observaciones del conjunto de datos.
Si tus grupos de funciones con el formato de tabla Iceberg tienen una clave de cifrado de tienda fuera de línea personalizada, asegúrate de conceder al IAM que estás utilizando para el trabajo de Amazon SageMaker Processing los permisos para usarla. Como mínimo, debe otorgarle permisos para cifrar los datos que escribe en Amazon S3. Para conceder los permisos, asigne a la función de IAM la posibilidad de utilizar la. GenerateDataKey Para obtener más información sobre cómo conceder permisos a los roles de IAM para usar AWS KMS claves, consulte https://docs.aws.amazon.com/kms/latest/developerguide/key-policies.html
- Destination Node
-
Si desea enviar una serie de pasos de procesamiento de datos que ha realizado a un grupo de características, debe crear un nodo de destino. Cuando crea y ejecuta un nodo de destino, Data Wrangler actualiza un grupo de características con sus datos. También puede crear un nuevo grupo de características desde la interfaz de usuario del nodo de destino. Después de crear un nodo de destino, se crea un trabajo de procesamiento para generar los datos. Un trabajo de procesamiento es un trabajo de SageMaker procesamiento de Amazon. Cuando utiliza un nodo de destino, este ejecuta los recursos computacionales necesarios para enviar los datos que ha transformado al grupo de características.
Puede utilizar un nodo de destino para exportar algunas de las transformaciones o todas las transformaciones que haya realizado en su flujo de Data Wrangler.
Utilice el siguiente procedimiento para crear un nodo de destino para actualizar un grupo de características con las observaciones de su conjunto de datos.
Para actualizar un grupo de características mediante un nodo de destino, haga lo siguiente.
Puede elegir Crear trabajo en el flujo de Data Wrangler para ver las instrucciones para utilizar un trabajo de procesamiento para actualizar un grupo de características.
-
Elija el símbolo + junto al nodo que contiene el conjunto de datos que desea exportar.
-
En Añadir destino, selecciona SageMaker AI Feature Store.
-
Elija (haga doble clic) el grupo de características. Data Wrangler comprueba si el esquema del grupo de características coincide con el esquema de los datos que se utilizan para actualizar el grupo de características.
-
De forma opcional, seleccione Exportar a un almacenamiento sin conexión solo para los grupos de características que tengan un almacenamiento en línea y un almacenamiento sin conexión. Esta opción solo actualiza el almacenamiento sin conexión con las observaciones de su conjunto de datos.
-
Después de que Data Wrangler valide el esquema de su conjunto de datos, elija Agregar.
Utilice el siguiente procedimiento para crear un nuevo grupo de características con los datos del conjunto de datos.
Puede almacenar el grupo de características de una de las siguientes formas:
-
Low-latencyEn línea: caché de alta disponibilidad para un grupo de funciones que proporciona búsquedas de registros en tiempo real. El almacenamiento en línea permite acceder rápidamente al último valor de un registro de un grupo de características.
-
Sin conexión: almacena datos de su grupo de características en un bucket de Amazon S3. Puede almacenar sus datos sin conexión cuando no necesite lecturas de baja latencia (inferiores a un segundo). Puede utilizar un almacenamiento sin conexión para las características que se utilizan en la exploración de datos, el entrenamiento de modelos y la inferencia por lotes.
-
Tanto en línea como sin conexión: almacena sus datos tanto en un almacenamiento en línea como en un almacenamiento sin conexión.
Para crear un grupo de características mediante un nodo de destino, haga lo siguiente.
-
Elija el símbolo + junto al nodo que contiene el conjunto de datos que desea exportar.
-
En Añadir destino, selecciona SageMaker AI Feature Store.
-
Elija Crear grupo de características.
-
En el siguiente cuadro de diálogo, si su conjunto de datos no tiene una columna de hora del evento, seleccione Crear columna EventTime «».
-
Elija Siguiente.
-
Elija Copiar esquema de JSON. Al crear un grupo de características, pega el esquema en las definiciones de características.
-
Seleccione Crear.
-
En Nombre del grupo de características, especifique un nombre para su grupo de características.
-
En Descripción (opcional), especifique una descripción para que su grupo de características sea más fácil de localizar.
-
Para crear un grupo de características para un almacenamiento en línea, haga lo siguiente.
-
Seleccione Habilitar el almacenamiento en línea.
-
En el caso de la clave de cifrado de la tienda online, especifique una clave de cifrado AWS gestionada o una clave de cifrado propia.
-
Para crear un grupo de características para un almacenamiento sin conexión, haga lo siguiente.
-
Seleccione Habilitar el almacenamiento sin conexión. Especifique los valores en los siguientes campos:
-
Nombre del bucket de S3: el nombre del bucket de Amazon S3 que almacena el grupo de características.
-
(Opcional) Nombre del directorio del conjunto de datos: el prefijo de Amazon S3 que utiliza para almacenar el grupo de características.
-
ARN del rol de IAM: el rol de IAM que tiene acceso al almacén de características.
-
Formato de tabla: formato de la tabla del almacenamiento sin conexión. Puede especificar Glue o Iceberg. El formato predeterminado es Glue.
-
Clave de cifrado del almacenamiento sin conexión: de forma predeterminada, el almacén de características utiliza una clave administrada de AWS Key Management Service , pero puede utilizar el campo para especificar una clave propia.
-
Especifique los valores en los siguientes campos:
-
Nombre del bucket de S3: el nombre del bucket que almacena el grupo de características.
-
(Opcional) Nombre del directorio del conjunto de datos: el prefijo de Amazon S3 que utiliza para almacenar el grupo de características.
-
ARN del rol de IAM: el rol de IAM que tiene acceso al almacén de características.
-
Clave de cifrado del almacenamiento sin conexión: de forma predeterminada, el almacén de características utiliza una clave administrada de AWS , pero puede utilizar el campo para especificar una clave propia.
-
Elija Continuar.
-
Elija JSON.
-
Elimine los corchetes de los marcadores de posición de la ventana.
-
Pegue el texto JSON del paso 6.
-
Elija Continuar.
-
En NOMBRE DE CARACTERÍSTICA DE IDENTIFICADOR DE REGISTRO, elija la columna del conjunto de datos que tenga identificadores únicos para cada registro del conjunto de datos.
-
En NOMBRE DE CARACTERÍSTICA DE HORA DEL EVENTO, elija la columna con los valores de la marca temporal.
-
Elija Continuar.
-
De forma opcional, agregue etiquetas para que su grupo de características sea más fácil de localizar.
-
Elija Continuar.
-
Elija Crear grupo de características.
-
Vuelva al flujo de Data Wrangler y elija el icono de actualización situado junto a la barra de búsqueda del Grupo de características.
Si ya ha creado un nodo de destino para un grupo de características dentro de un flujo, no podrá crear otro nodo de destino para el mismo grupo de características. Si desea crear otro nodo de destino para el mismo grupo de características, debe crear otro archivo de flujo.
Utilice el siguiente procedimiento para crear un trabajo de Data Wrangler.
Cree un trabajo desde la página Flujo de datos y elija los nodos de destino que desee exportar.
-
Seleccione Crear tarea. La siguiente imagen muestra el panel que aparece después de seleccionar Crear trabajo.
-
En Nombre del trabajo, especifique el nombre del trabajo de exportación.
-
Elija los nodos de destino que desea exportar.
-
(Opcional) En la clave KMS de salida, especifique un ARN, un ID o un alias de una AWS KMS clave. Una clave de KMS es una clave criptográfica. Puede usar la clave para cifrar los datos de salida del trabajo. Para obtener más información sobre AWS KMS las claves, consulte AWS Key Management Service.
-
La siguiente imagen muestra la página Configurar trabajo con la pestaña Configuración del trabajo abierta.
De forma opcional, en Parámetros entrenados, elija Reajustar si ha hecho lo siguiente:
Para obtener más información sobre cómo reajustar las transformaciones que ha realizado a un conjunto de datos completo, consulte Reajuste de las transformaciones a todo el conjunto de datos y exportación.
-
Elija Configurar trabajo.
-
De forma opcional, configure el trabajo de Data Wrangler. Puede hacer las siguientes configuraciones:
-
Configuración del trabajo
-
Configuración de memoria Spark
-
Configuración de red
-
Etiquetas
-
Parámetros
-
Horarios de los asociados
-
Seleccione Ejecutar.
- Jupyter notebook
-
Usa el siguiente procedimiento con un bloc de notas de Jupyter para exportarlo a Amazon SageMaker Feature Store.
Utilice el siguiente procedimiento para generar un cuaderno de Jupyter y ejecútelo para exportar el flujo de Data Wrangler al almacén de características.
-
Elija el signo + junto al nodo que desea exportar.
-
Elija Exportar a.
-
Elige Amazon SageMaker Feature Store (a través de Jupyter Notebook).
-
Ejecute el cuaderno de Jupyter.
Al ejecutar un cuaderno de Jupyter, se ejecuta un trabajo de Data Wrangler. Al ejecutar un trabajo de Data Wrangler, se inicia un SageMaker trabajo de procesamiento de IA. El trabajo de procesamiento incorpora el flujo a un almacén de características en línea y sin conexión.
El rol de IAM que utilice debe tener asociadas las siguientes políticas administradas por AWS : AmazonSageMakerFullAccess y AmazonSageMakerFeatureStoreAccess.
Solo necesita habilitar un almacén de características en línea o sin conexión al crear un grupo de características. También puede habilitar ambos. Para deshabilitar la creación de un almacenamiento en línea, establezca EnableOnlineStore en False:
# Online Store Configuration
online_store_config = {
"EnableOnlineStore": False
}
El cuaderno utiliza los nombres de las columnas y los tipos del marco de datos que exporta para crear un esquema de grupo de características, que se utiliza para crear un grupo de características. Un grupo de características es un conjunto de características definidas en el almacén de características para describir un registro. El grupo de características define el esquema y las características contenidas en el grupo de características. La definición de un grupo de características se compone de una lista de características, un nombre de característica de identificador de registro, un nombre de característica de hora del evento y configuraciones para su almacenamiento en línea y almacenamiento sin conexión.
Cada característica de un grupo de características puede tener uno de los siguientes tipos: cadena, fracción o entero. Si una columna del marco de datos exportado no es uno de estos tipos, el valor predeterminado es String.
A continuación se muestra un ejemplo de un esquema de grupo de características.
column_schema = [
{
"name": "Height",
"type": "long"
},
{
"name": "Input",
"type": "string"
},
{
"name": "Output",
"type": "string"
},
{
"name": "Sum",
"type": "string"
},
{
"name": "Time",
"type": "string"
}
]
Además, tiene que especificar un nombre de identificador de registro y un nombre de característica de hora del evento:
-
El nombre de identificador de registro es el nombre de la característica cuyo valor identifica de forma exclusiva un registro definido en el almacén de características. En el almacenamiento en línea solo se almacena el registro más reciente por valor del identificador. El nombre de característica de identificador de registro debe ser uno de los nombres de las definiciones de características.
-
El nombre de característica de hora del evento es el nombre de la característica que almacena la EventTime de un registro en un grupo de características. Una EventTime es un momento en el tiempo en el que se produce un nuevo evento que corresponde a la creación o actualización de una característica. Todos los registros del grupo de características deben tener una EventTime correspondiente.
El cuaderno utiliza estas configuraciones para crear un grupo de características, procesar los datos a escala y, a continuación, incorporar los datos procesados a los almacenes de características en línea y sin conexión. Para obtener más información, consulte Data Sources and Ingestion.
El cuaderno utiliza estas configuraciones para crear un grupo de características, procesar los datos a escala y, a continuación, incorporar los datos procesados a los almacenes de características en línea y sin conexión. Para obtener más información, consulte Data Sources and Ingestion.
Al importar datos, Data Wrangler utiliza una muestra de los datos para aplicar las codificaciones. De forma predeterminada, Data Wrangler usa las primeras 50 000 filas como muestra, pero puede importar todo el conjunto de datos o usar un método de muestreo diferente. Para obtener más información, consulte Importación.
Las siguientes transformaciones utilizan sus datos para crear una columna en el conjunto de datos:
Si empleó el muestreo para importar los datos, las transformaciones anteriores solo usan los datos de la muestra para crear la columna. Es posible que la transformación no haya utilizado todos los datos pertinentes. Por ejemplo, si usa la transformación Codificación categórica, podría haber una categoría en todo el conjunto de datos que no esté presente en la muestra.
Puede usar un nodo de destino o un cuaderno de Jupyter para reajustar las transformaciones a todo el conjunto de datos. Cuando Data Wrangler exporta las transformaciones del flujo, crea una tarea de procesamiento. SageMaker Cuando finaliza el trabajo de procesamiento, Data Wrangler guarda los siguientes archivos en la ubicación predeterminada de Amazon S3 o en una ubicación S3 que usted especifique:
Puede abrir un archivo de flujo de Data Wrangler en Data Wrangler y aplicar las transformaciones a un conjunto de datos diferente. Por ejemplo, si ha aplicado las transformaciones a un conjunto de datos de entrenamiento, puede abrir y usar el archivo de flujo de Data Wrangler para aplicar las transformaciones a un conjunto de datos utilizado para la inferencia.
Para obtener información sobre el uso de nodos de destino para reajustar las transformaciones y exportar, consulte las siguientes páginas:
Utilice el siguiente procedimiento para ejecutar un cuaderno de Jupyter para reajustar las transformaciones y exportar los datos.
Para ejecutar un cuaderno de Jupyter, reajustar las transformaciones y exportar el flujo de Data Wrangler, haga lo siguiente.
-
Elija el signo + junto al nodo que desea exportar.
-
Elija Exportar a.
-
Elija la ubicación a la que va a exportar los datos.
-
En el objeto refit_trained_params, establezca refit en True.
-
Para el campo output_flow, especifique el nombre del archivo de flujo de salida con las transformaciones de reajuste.
-
Ejecute el cuaderno de Jupyter.
Creación de una programación para procesar automáticamente los datos nuevos
Si procesa datos periódicamente, puede crear una programación para ejecutar el trabajo de procesamiento de forma automática. Por ejemplo, puede crear una programación que ejecute un trabajo de procesamiento automáticamente cuando obtenga datos nuevos. Para obtener más información acerca de estos trabajos de procesamiento, consulte Exportar a Amazon S3. y Exportar a Amazon SageMaker Feature Store.
Al crear un trabajo, debe especificar un rol de IAM que tenga permisos para crear el trabajo. De forma predeterminada, el rol de IAM que utiliza para acceder a Data Wrangler es SageMakerExecutionRole.
Los siguientes permisos permiten a Data Wrangler acceder a los trabajos de procesamiento EventBridge y EventBridge ejecutarlos:
-
Añada la siguiente política AWS gestionada a la función de ejecución de Amazon SageMaker Studio Classic que proporciona a Data Wrangler permisos de uso: EventBridge
arn:aws:iam::aws:policy/AmazonEventBridgeFullAccess
Para obtener más información sobre la política, consulte las políticas AWS administradas de. EventBridge
-
Agregue la siguiente política al rol de IAM que especifica al crear un trabajo en Data Wrangler:
- JSON
-
-
{
"Version":"2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sagemaker:StartPipelineExecution",
"Resource": "arn:aws:sagemaker:us-east-1:111122223333:pipeline/data-wrangler-*"
}
]
}
Si utiliza la función de IAM predeterminada, añada la política anterior a la función de ejecución de Amazon SageMaker Studio Classic.
Añada la siguiente política de confianza al rol para poder EventBridge asumirlo.
{
"Effect": "Allow",
"Principal": {
"Service": "events.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
Al crear una programación, Data Wrangler crea una eventRule entrada. EventBridge Se le cobrará tanto por las reglas de eventos que cree como por las instancias que utilice para ejecutar el trabajo de procesamiento.
Para obtener información sobre EventBridge los precios, consulta los EventBridge precios de Amazon. Para obtener información sobre cómo procesar los precios de los trabajos, consulta Amazon SageMaker Pricing.
Utilice uno de los métodos siguientes para definir una programación:
-
Expresiones CRON
Data Wrangler no admite las siguientes expresiones:
-
LW#
-
Abreviaturas para días
-
Abreviaturas para días
-
Expresiones de frecuencia
-
Recurrente: establece un intervalo de una hora o un día para ejecutar el trabajo.
-
Hora específica: establece días y horas concretos para ejecutar el trabajo.
En las siguientes secciones se presentan procedimientos para crear trabajos.
- CRON
-
Utilice el siguiente procedimiento para crear una programación con una expresión CRON.
Para especificar una programación con una expresión CRON, haga lo siguiente.
-
Abra el flujo de Data Wrangler.
-
Seleccione Crear tarea.
-
(Opcional) En la clave KMS de salida, especifique una AWS KMS clave para configurar la salida del trabajo.
-
Elija Siguiente, 2. Configurar el trabajo.
-
Seleccione Horarios de los asociados.
-
Elija Crear una nueva programación.
-
En Nombre de la programación, especifique el nombre de la programación.
-
En Frecuencia de ejecución, elija CRON.
-
Especifique una expresión CRON válida.
-
Seleccione Crear.
-
De forma opcional, elija Agregar otra programación para ejecutar el trabajo según una programación adicional.
Puede asociar un máximo de dos programaciones. Las programaciones son independientes y no se afectan entre sí a menos que los horarios se superpongan.
-
Seleccione una de las siguientes opciones:
-
Programar y ejecutar ahora: el trabajo se ejecuta inmediatamente en Data Wrangler y, posteriormente, se ejecuta según las programaciones.
-
Solo programar: el trabajo de Data Wrangler solo se ejecuta en los horarios que usted especifique.
-
Elija Ejecutar.
- RATE
-
Utilice el siguiente procedimiento para crear una programación con una expresión de frecuencia.
Para especificar una programación con una expresión de frecuencia, haga lo siguiente.
-
Abra el flujo de Data Wrangler.
-
Seleccione Crear tarea.
-
(Opcional) En la clave KMS de salida, especifique una AWS KMS clave para configurar la salida del trabajo.
-
Elija Siguiente, 2. Configurar el trabajo.
-
Seleccione Horarios de los asociados.
-
Elija Crear una nueva programación.
-
En Nombre de la programación, especifique el nombre de la programación.
-
En Frecuencia de ejecución, elija Velocidad.
-
En Valor, especifique un valor entero.
-
En Unidad, seleccione una de las opciones siguientes:
-
Seleccione Crear.
-
De forma opcional, elija Agregar otra programación para ejecutar el trabajo según una programación adicional.
Puede asociar un máximo de dos programaciones. Las programaciones son independientes y no se afectan entre sí a menos que los horarios se superpongan.
-
Seleccione una de las siguientes opciones:
-
Programar y ejecutar ahora: el trabajo se ejecuta inmediatamente en Data Wrangler y, posteriormente, se ejecuta según las programaciones.
-
Solo programar: el trabajo de Data Wrangler solo se ejecuta en los horarios que usted especifique.
-
Elija Ejecutar.
- Recurring
-
Utilice el siguiente procedimiento para crear un programa que ejecute un trabajo de forma recurrente.
Para especificar una programación con una expresión CRON, haga lo siguiente.
-
Abra el flujo de Data Wrangler.
-
Seleccione Crear tarea.
-
(Opcional) En la clave KMS de salida, especifique una AWS KMS clave para configurar la salida del trabajo.
-
Elija Siguiente, 2. Configurar el trabajo.
-
Seleccione Horarios de los asociados.
-
Elija Crear una nueva programación.
-
En Nombre de la programación, especifique el nombre de la programación.
-
En Frecuencia de ejecución, asegúrese de que esté seleccionada la opción Recurrente de forma predeterminada.
-
En Cada x horas, especifique la frecuencia horaria con la que se ejecuta el trabajo durante el día. Los valores válidos son enteros en el rango inclusivo de 1 a23.
-
Para En días, seleccione una de las siguientes opciones:
-
Todos los días
-
Fines de semana
-
Días laborales
-
Seleccionar días
-
De forma opcional, si eligió Seleccionar días, elija los días de la semana en los que se ejecutará el trabajo.
El horario se restablece cada día. Si programa un trabajo para que se ejecute cada cinco horas, se ejecutará en los siguientes momentos del día:
-
00:00
-
05:00
-
10:00
-
15:00
-
20:00
-
Seleccione Crear.
-
De forma opcional, elija Agregar otra programación para ejecutar el trabajo según una programación adicional.
Puede asociar un máximo de dos programaciones. Las programaciones son independientes y no se afectan entre sí a menos que los horarios se superpongan.
-
Seleccione una de las siguientes opciones:
-
Programar y ejecutar ahora: el trabajo se ejecuta inmediatamente en Data Wrangler y, posteriormente, se ejecuta según las programaciones.
-
Solo programar: el trabajo de Data Wrangler solo se ejecuta en los horarios que usted especifique.
-
Elija Ejecutar.
- Specific time
-
Utilice el siguiente procedimiento para crear una programación que ejecute un trabajo en momentos concretos.
Para especificar una programación con una expresión CRON, haga lo siguiente.
-
Abra el flujo de Data Wrangler.
-
Seleccione Crear tarea.
-
(Opcional) En la clave KMS de salida, especifique una AWS KMS clave para configurar la salida del trabajo.
-
Elija Siguiente, 2. Configurar el trabajo.
-
Seleccione Horarios de los asociados.
-
Elija Crear una nueva programación.
-
En Nombre de la programación, especifique el nombre de la programación.
-
Seleccione Crear.
-
De forma opcional, elija Agregar otra programación para ejecutar el trabajo según una programación adicional.
Puede asociar un máximo de dos programaciones. Las programaciones son independientes y no se afectan entre sí a menos que los horarios se superpongan.
-
Seleccione una de las siguientes opciones:
-
Programar y ejecutar ahora: el trabajo se ejecuta inmediatamente en Data Wrangler y, posteriormente, se ejecuta según las programaciones.
-
Solo programar: el trabajo de Data Wrangler solo se ejecuta en los horarios que usted especifique.
-
Elija Ejecutar.
Puede utilizar Amazon SageMaker Studio Classic para ver los trabajos que están programados para ejecutarse. Sus trabajos de procesamiento se ejecutan en Canalizaciones. Cada trabajo de procesamiento tiene su propia canalización. Se ejecuta como un paso de procesamiento dentro de la canalización. Puede ver las programaciones que ha creado dentro de una canalización. Para obtener información acerca de cómo visualizar una canalización, consulte Visualización de los detalles de una canalización.
Utilice el siguiente procedimiento para ver los trabajos que ha programado.
Para ver los trabajos que ha programado, haga lo siguiente.
-
Abre Amazon SageMaker Studio Classic.
-
Apertura de canalizaciones
-
Vea las canalizaciones de los trabajos que ha creado.
La canalización que ejecuta el trabajo usa el nombre del trabajo como prefijo. Por ejemplo, si ha creado un trabajo denominado housing-data-feature-enginnering, el nombre de la canalización es data-wrangler-housing-data-feature-engineering.
-
Elija la canalización que contiene su trabajo.
-
Vea el estado de las canalizaciones. Las canalizaciones con un Estado Correcto han ejecutado el trabajo de procesamiento correctamente.
Para detener la ejecución del trabajo de procesamiento, haga lo siguiente:
Para detener la ejecución de un trabajo de procesamiento, elimine la regla de eventos que especifica la programación. Al eliminar una regla de eventos, se detiene la ejecución de todos los trabajos asociados a la programación. Para obtener información sobre cómo eliminar una regla, consulta Cómo deshabilitar o eliminar una EventBridge regla de Amazon.
También puede detener y eliminar las canalizaciones asociadas a las programaciones. Para obtener información sobre cómo detener una canalización, consulta StopPipelineExecution. Para obtener información sobre la eliminación de una canalización, consulte DeletePipeline.