Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Multi-model puntos finales
Multi-model Los puntos finales proporcionan una solución escalable y rentable para implementar un gran número de modelos. Utilizan la misma flota de recursos y un contenedor de servicio compartido para alojar todos sus modelos. Esto reduce los costos de alojamiento al mejorar la utilización del punto de conexión en comparación con el uso de puntos de conexión de modelo único. También reduce la sobrecarga de implementación, ya que Amazon SageMaker AI gestiona la carga de modelos en la memoria y su escalado en función de los patrones de tráfico hacia su punto final.
El siguiente diagrama muestra cómo funcionan los puntos de conexión multimodelo en comparación con los puntos de conexión de un solo modelo.
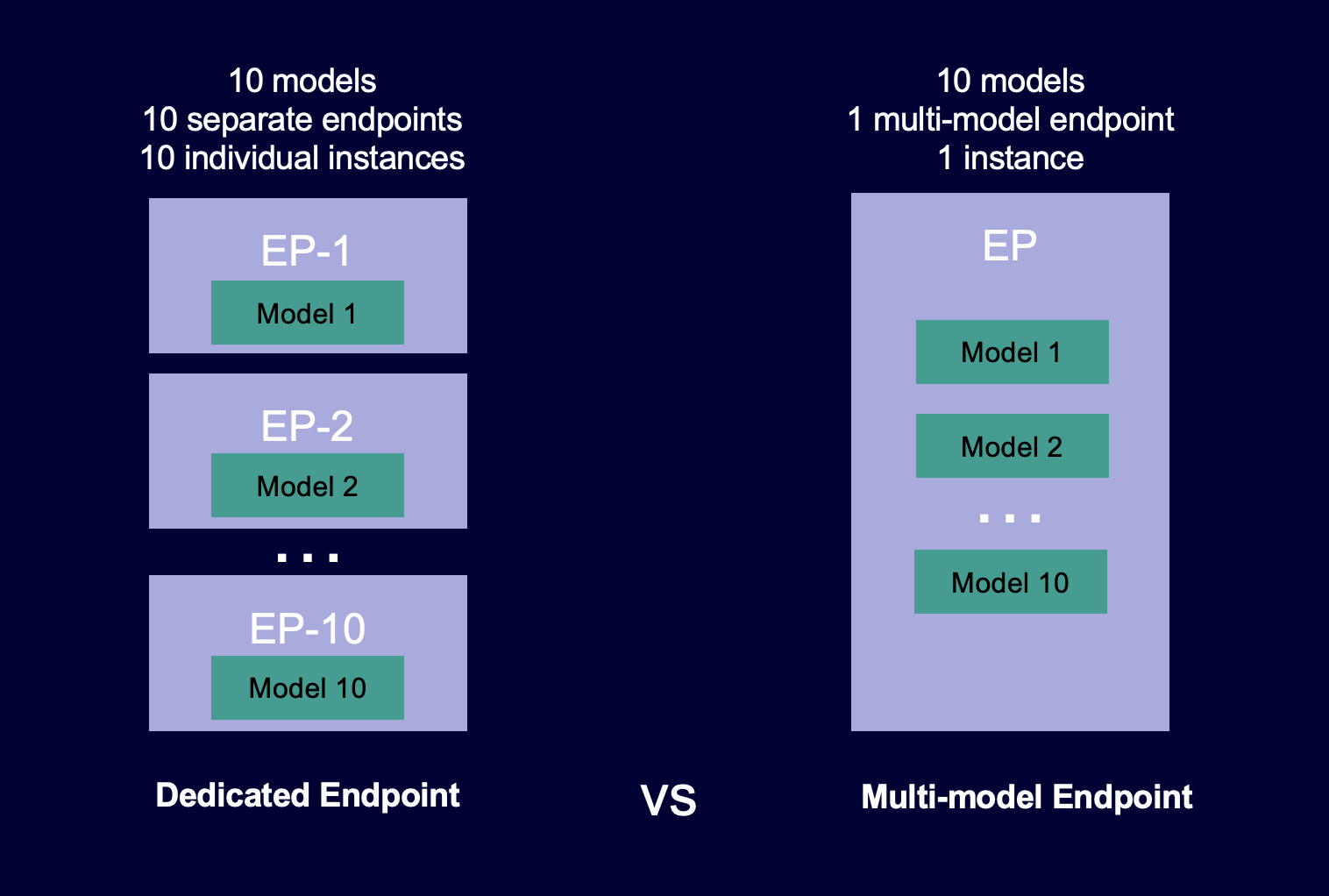
Multi-model Los puntos finales son ideales para alojar una gran cantidad de modelos que utilizan el mismo marco de aprendizaje automático en un contenedor de servidores compartido. Si tiene una combinación de modelos a los que se accede con frecuencia y con poca frecuencia, un punto de conexión multimodelo puede atender este tráfico de manera eficiente con menos recursos y un mayor ahorro de costos. Su aplicación debe tolerar las penalizaciones de latencia ocasionales relacionadas con el arranque en frío que se producen al invocar modelos que se utilizan con poca frecuencia.
Multi-model los terminales admiten el alojamiento de modelos respaldados por CPU y GPU. Al utilizar modelos respaldados por GPU, puede reducir los costos de implementación del modelo mediante un mayor uso del punto de conexión y sus instancias de computación acelerada subyacentes.
Multi-model Los puntos finales también permiten compartir el tiempo de los recursos de memoria entre sus modelos. Esto funciona mejor cuando los modelos son bastante similares en tamaño y latencia de invocación. Cuando es el caso, los puntos de conexión multimodelo pueden usar eficazmente instancias en todos los modelos. Si tiene modelos que tienen transacciones por segundo (TPS) o requisitos de latencia notablemente más altos, le recomendamos alojarlos en puntos de conexión dedicados.
Puede utilizar puntos de conexión multimodelo con las siguientes funciones:
-
AWS PrivateLinky VPC
-
Canalizaciones de inferencia en serie (pero solo se puede incluir un contenedor habilitado para varios modelos en una canalización de inferencia)
-
A/B probando
Puede utilizar la consola de IA AWS SDK para Python (Boto) o la consola de SageMaker IA para crear un punto final multimodelo. Puede utilizar puntos de conexión multimodelo con respaldo de CPU, puede crear su punto de conexión con contenedores personalizados integrando la biblioteca Multi Model Server
Temas
Algoritmos, marcos e instancias compatibles con puntos de conexión multimodelo
Recomendaciones de instancia para implementaciones de puntos de conexión multimodelo
Construya su propio contenedor para terminales de SageMaker IA Multi-Model
CloudWatch Métricas para despliegues de Multi-Model terminales
Establezca políticas de Auto Scaling para despliegues de Multi-Model terminales
Cómo funcionan los puntos de conexión multimodelo
SageMaker La IA gestiona el ciclo de vida de los modelos alojados en puntos finales multimodelo en la memoria del contenedor. En lugar de descargar todos los modelos de un bucket de Amazon S3 al contenedor al crear el punto de conexión, la SageMaker IA los carga y almacena en caché de forma dinámica cuando los invoca. Cuando la SageMaker IA recibe una solicitud de invocación para un modelo en particular, hace lo siguiente:
-
Enruta la solicitud a una instancia detrás del punto de conexión.
-
Descarga el modelo desde el bucket de S3 al volumen de almacenamiento de esa instancia.
-
Carga el modelo en la memoria del contenedor (CPU o GPU, dependiendo de si tiene instancias respaldadas por CPU o GPU) de esa instancia de computación acelerada. Si el modelo ya está cargado en la memoria del contenedor, la invocación es más rápida porque la SageMaker IA no necesita descargarlo ni cargarlo.
SageMaker La IA sigue dirigiendo las solicitudes de un modelo a la instancia en la que el modelo ya está cargado. Sin embargo, si el modelo recibe muchas solicitudes de invocación y hay instancias adicionales para el punto final multimodelo, la SageMaker IA enruta algunas solicitudes a otra instancia para acomodar el tráfico. Si el modelo aún no está cargado en la segunda instancia, el modelo se descarga en el volumen de almacenamiento de esa instancia y se carga en la memoria del contenedor.
Cuando el uso de memoria de una instancia es elevado y la SageMaker IA necesita cargar otro modelo en la memoria, descarga los modelos no utilizados del contenedor de esa instancia para garantizar que haya suficiente memoria para cargar el modelo. Los modelos que se descargan permanecen en el volumen de almacenamiento de la instancia y se pueden cargar en la memoria del contenedor más adelante sin volver a descargarse desde el bucket S3. Si el volumen de almacenamiento de la instancia alcanza su capacidad máxima, la SageMaker IA elimina los modelos no utilizados del volumen de almacenamiento.
Para eliminar un modelo, deja de enviar solicitudes y elimínalo del bucket de S3. SageMaker La IA proporciona una capacidad de punto final multimodelo en un contenedor de servicio. Al agregar modelos a un punto de conexión multimodelo y eliminarlos del mismo, no es necesario actualizar el punto de conexión en sí. Para añadir un modelo, se carga en el bucket S3 y se empieza a invocar. No necesita cambios de código para usarlo.
nota
Al actualizar un punto de conexión multimodelo, las solicitudes de invocación iniciales en el punto de conexión pueden experimentar latencias más altas, ya que Smart Routing en los puntos de conexión multimodelo se adapta a su patrón de tráfico. Sin embargo, una vez que conozca su patrón de tráfico, podrá experimentar latencias bajas en los modelos que utilice con más frecuencia. Los modelos que se utilizan con menos frecuencia pueden sufrir algunas latencias de arranque en frío, ya que los modelos se cargan dinámicamente en una instancia.
Cuadernos de ejemplo para puntos de conexión multimodelo
Para obtener más información sobre cómo usar puntos de conexión multimodelo, puede probar los siguientes cuadernos de ejemplo:
-
Ejemplos para puntos de conexión multimodelo que utilizan instancias respaldadas por CPU:
-
Multi-Model Ejemplo de portátil XGBoost para terminales
: en este portátil se muestra cómo implementar varios modelos de XGBoost en un terminal. -
Multi-Model Ejemplo de cuaderno BYOC de Endpoints
: este cuaderno muestra cómo configurar e implementar un contenedor de clientes que sea compatible con puntos finales multimodelo en IA. SageMaker
-
-
Ejemplo para puntos de conexión multimodelo que utilizan instancias respaldadas por GPU:
Para obtener instrucciones sobre cómo crear instancias de Jupyter Notebook y acceder a ellas, que puede utilizar para ejecutar los ejemplos anteriores en IA, consulte. SageMaker Instancias de Amazon SageMaker Notebook Una vez que hayas creado una instancia de bloc de notas y la hayas abierto, selecciona la pestaña Ejemplos de SageMaker IA para ver una lista de todos los ejemplos de SageMaker IA. Los cuadernos de punto de conexión multimodelo se encuentran en la sección FUNCIONALIDAD AVANZADA. Para abrir un bloc de notas, elija su pestaña Usar y, a continuación, Crear copia.
Para obtener más información sobre casos de uso de puntos de conexión multimodelo, consulte los siguientes blogs y recursos:
