Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Introducción a Data Wrangler
Amazon SageMaker Data Wrangler es una función de Amazon SageMaker Studio Classic. Utilice esta sección para obtener información sobre cómo acceder a Data Wrangler y empezar a usarlo. Haga lo siguiente:
-
Complete cada paso en Requisitos previos.
-
Siga el procedimiento indicado en Acceso a Data Wrangler para empezar a utilizar Data Wrangler.
Requisitos previos
Para utilizar Data Wrangler, debe completar los siguientes requisitos previos.
-
Para utilizar Data Wrangler, necesita tener acceso a una instancia de Amazon Elastic Compute Cloud (Amazon EC2). Para obtener más información acerca de las instancias de Amazon EC2 que puede utilizar, consulte instancias. Para obtener información sobre cómo ver sus cuotas y, si es necesario, solicitar un aumento de cuota, consulte AWS service quotas.
-
Configure los permisos requeridos descritos en Seguridad y permisos.
-
Si su organización utiliza un firewall que bloquea el tráfico de Internet, debe tener acceso a las siguientes direcciones URL:
-
https://ui.prod-1.data-wrangler.sagemaker.aws/ -
https://ui.prod-2.data-wrangler.sagemaker.aws/ -
https://ui.prod-3.data-wrangler.sagemaker.aws/ -
https://ui.prod-4.data-wrangler.sagemaker.aws/
-
Para utilizar Data Wrangler, necesita una instancia de Studio Classic activa. Para obtener información sobre cómo lanzar una nueva instancia, consulte Descripción general del dominio Amazon SageMaker AI. Cuando la instancia de Studio Classic esté Lista, siga las instrucciones de Acceso a Data Wrangler.
Acceso a Data Wrangler
En el siguiente procedimiento se supone que ya ha completado los Requisitos previos.
Para acceder a Data Wrangler en Studio Classic, haga lo siguiente.
-
Inicie sesión en Studio Classic. Para obtener más información, consulte Descripción general del dominio Amazon SageMaker AI.
-
Elija Studio.
-
Elija Lanzar aplicación.
-
En la lista desplegable, seleccione Studio.
-
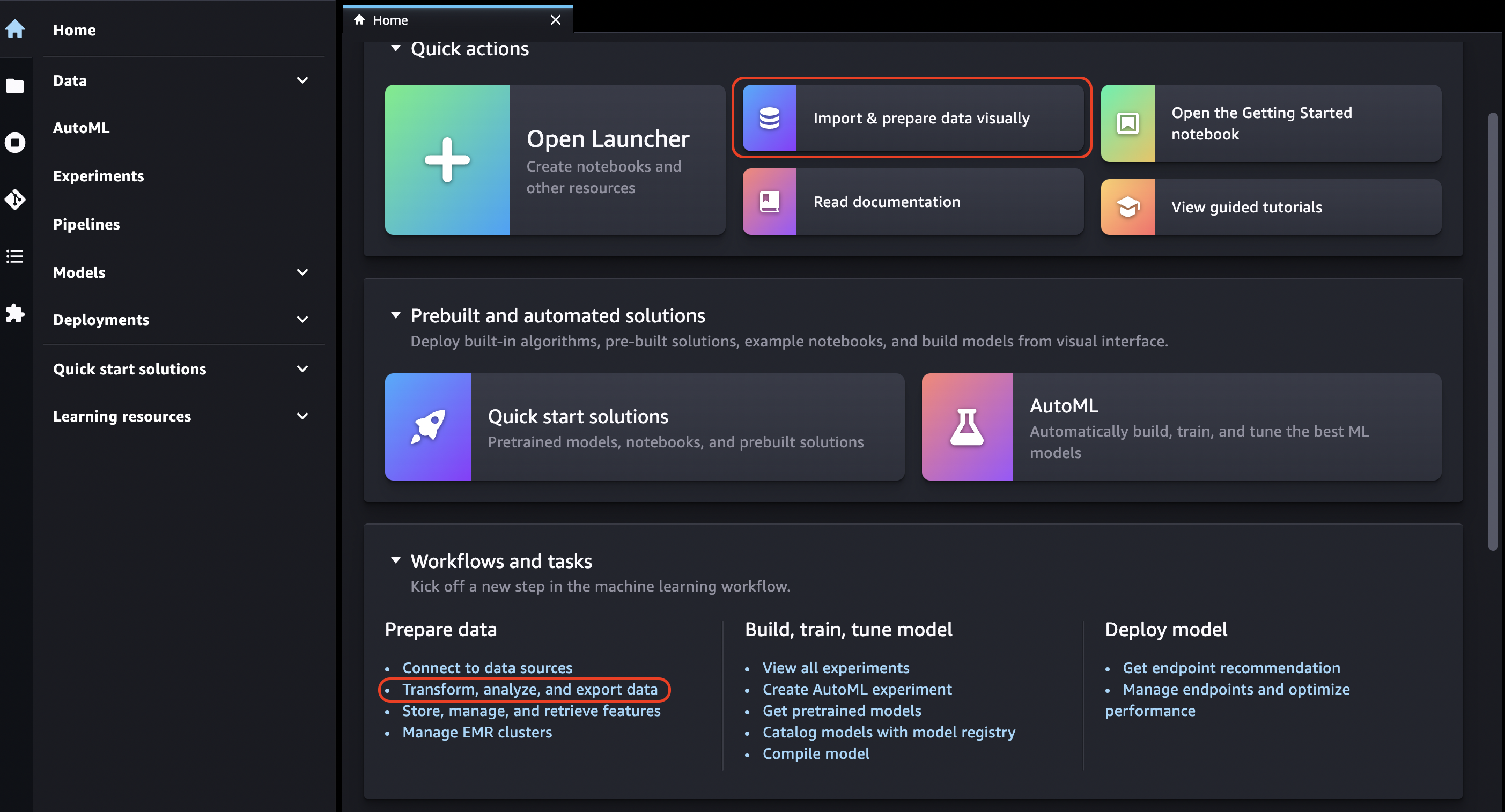
Elija el icono Inicio.
-
Elija Datos.
-
Elija Data Wrangler.
-
También puede crear un flujo de Data Wrangler de la siguiente manera.
-
En la barra de navegación superior, seleccione Archivo.
-
Seleccione Nueva.
-
Seleccione Flujo de Data Wrangler.
-
-
De forma opcional, puede cambiar el nombre del nuevo directorio y del archivo .flow.
-
Al crear un nuevo archivo .flow en Studio Classic, es posible que vea un carrusel que le presenta Data Wrangler.
Puede que tarde unos minutos.
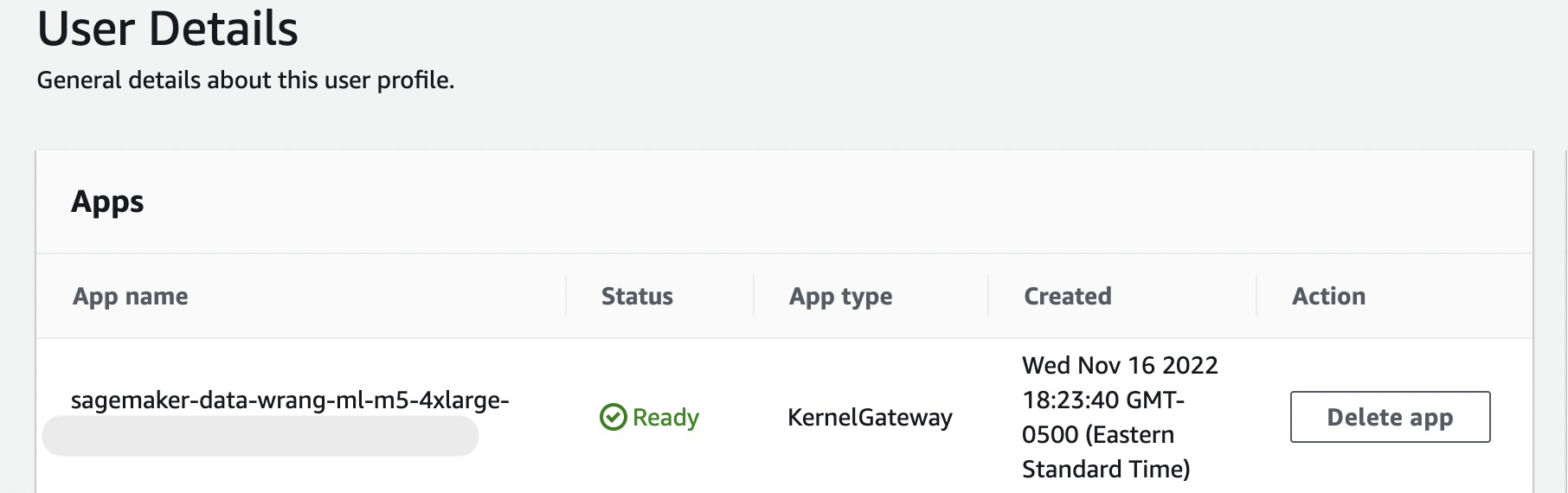
Este mensaje se conserva mientras la KernelGatewayaplicación de tu página de detalles de usuario esté pendiente. Para ver el estado de esta aplicación, en la consola SageMaker AI de la página Amazon SageMaker Studio Classic, seleccione el nombre del usuario que está utilizando para acceder a Studio Classic. En la página de detalles del usuario, verá una KernelGatewayaplicación en Aplicaciones. Espere hasta que el estado de la aplicación sea Listo para empezar a usar Data Wrangler. Esto puede tardar unos 5 minutos la primera vez que inicie Data Wrangler.
-
Para empezar, elija un origen de datos y úsela para importar un conjunto de datos. Consulte Importación para obtener más información.
Al importar un conjunto de datos, aparece en el flujo de datos. Para obtener más información, consulte Creación y uso de un flujo de Data Wrangler.
-
Después de importar un conjunto de datos, Data Wrangler infiere automáticamente el tipo de datos de cada columna. Seleccione + junto al paso Tipos de datos y seleccione Editar tipos de datos.
importante
Después de añadir las transformaciones al paso Tipos de datos, no puede realizar una actualización masiva de los tipos de columnas mediante la opción Actualizar tipos.
-
Utilice el flujo de datos para añadir transformaciones y análisis. Para obtener más información, consulte Datos de transformación y Análisis y visualización.
-
Para exportar un flujo de datos completo, elija Exportar y elija una opción de exportación. Para obtener más información, consulte Exportación.
-
Por último, elija el icono Componentes y registros y seleccione Data Wrangler en la lista desplegable para ver todos los archivos .flow que ha creado. Puede utilizar este menú para buscar flujos de datos y moverse entre ellos.
Una vez que haya lanzado Data Wrangler, puede utilizar la siguiente sección para ver cómo puede usar Data Wrangler para crear un flujo de preparación de datos de machine learning.
Actualización de Data Wrangler
Se recomienda actualizar periódicamente la aplicación de Data Wrangler Studio Classic para acceder a las características y actualizaciones más recientes. El nombre de la aplicación Data Wrangler comienza por sagemaker-data-wrang. Para obtener más información sobre cómo actualizar una aplicación de Studio Classic, consulte Cierre y actualice las aplicaciones clásicas de Amazon SageMaker Studio.
Demostración: tutorial del conjunto de datos del Titanic de Data Wrangler
En las secciones siguientes, encontrará un tutorial para comenzar a utilizar Data Wrangler. En este tutorial se supone que ya ha seguido los pasos descritos en Acceso a Data Wrangler y que tiene abierto un nuevo archivo de flujo de datos que va a utilizar en la demostración. Puede que desee cambiar el nombre de este archivo .flow por un nombre similar a titanic-demo.flow.
En este tutorial se utiliza el conjunto de datos del Titanic
En este tutorial, debe realizar los siguientes pasos.
-
Realice una de las siguientes acciones:
-
Abra su flujo de Data Wrangler y elija Usar conjunto de datos de muestra.
-
Cargue el conjunto de datos del Titanic
en Amazon Simple Storage Service (Amazon S3) y, a continuación, importe este conjunto de datos a Data Wrangler.
-
-
Analice este conjunto de datos mediante los análisis de Data Wrangler.
-
Defina un flujo de datos mediante las transformaciones de datos de Data Wrangler.
-
Exporte el flujo a un cuaderno de Jupyter que pueda usar para crear un trabajo de Data Wrangler.
-
Procese sus datos e inicie un trabajo de SageMaker formación para entrenar un clasificador binario XGBoost.
Carga del conjunto de datos a S3 e importación
Para comenzar, puede utilizar uno de los métodos siguientes para importar el conjunto de datos del Titanic a Data Wrangler:
-
Importar el conjunto de datos directamente desde el flujo de Data Wrangler
-
Cargar el conjunto de datos a Amazon S3 y, a continuación, importarlo a Data Wrangler
Para importar el conjunto de datos directamente a Data Wrangler, abra el flujo y elija Usar conjunto de datos de muestra.
La carga del conjunto de datos a Amazon S3 y la importación a Data Wrangler se parece más a la experiencia de importar sus propios datos. La siguiente información le indica cómo cargar su conjunto de datos e importarlo.
Antes de empezar a importar los datos a Data Wrangler, descargue el conjunto de datos del Titanic
Si es un usuario nuevo de Amazon S3, puede hacerlo mediante arrastrar y soltar en la consola de Amazon S3. Para obtener información al respecto, consulte Uploading Files and Folders by Using Drag and Drop en la Guía del usuario de Amazon Simple Storage Service.
importante
Cargue su conjunto de datos en un depósito de S3 en la misma AWS región que desee usar para completar esta demostración.
Cuando el conjunto de datos se haya cargado correctamente en Amazon S3, podrá importarlo a Data Wrangler.
Importación del conjunto de datos del Titanic a Data Wrangler
-
Elija el botón Importar datos en la pestaña Flujo de datos o elija la pestaña Importar.
-
Seleccione Amazon S3.
-
Use la tabla Importar un conjunto de datos de S3 para buscar el bucket en el que agregó el conjunto de datos del Titanic. Elija el archivo CSV del conjunto de datos del Titanic para abrir el panel Detalles.
-
En Detalles, el Tipo de archivo debe ser CSV. Marque la Primera fila es el encabezado para especificar que la primera fila del conjunto de datos es un encabezado. También puede asignar al conjunto de datos un nombre más descriptivo, como
Titanic-train. -
Elija el botón Importar.
Cuando el conjunto de datos se importa a Data Wrangler, aparece en la pestaña Flujo de datos. Puede hacer doble clic en un nodo para acceder a la vista de detalles del nodo, que le permite añadir transformaciones o análisis. Puede utilizar el icono con el signo más para acceder rápidamente a la navegación. En la siguiente sección, utilizará este flujo de datos para agregar pasos de análisis y transformación.
Flujo de datos
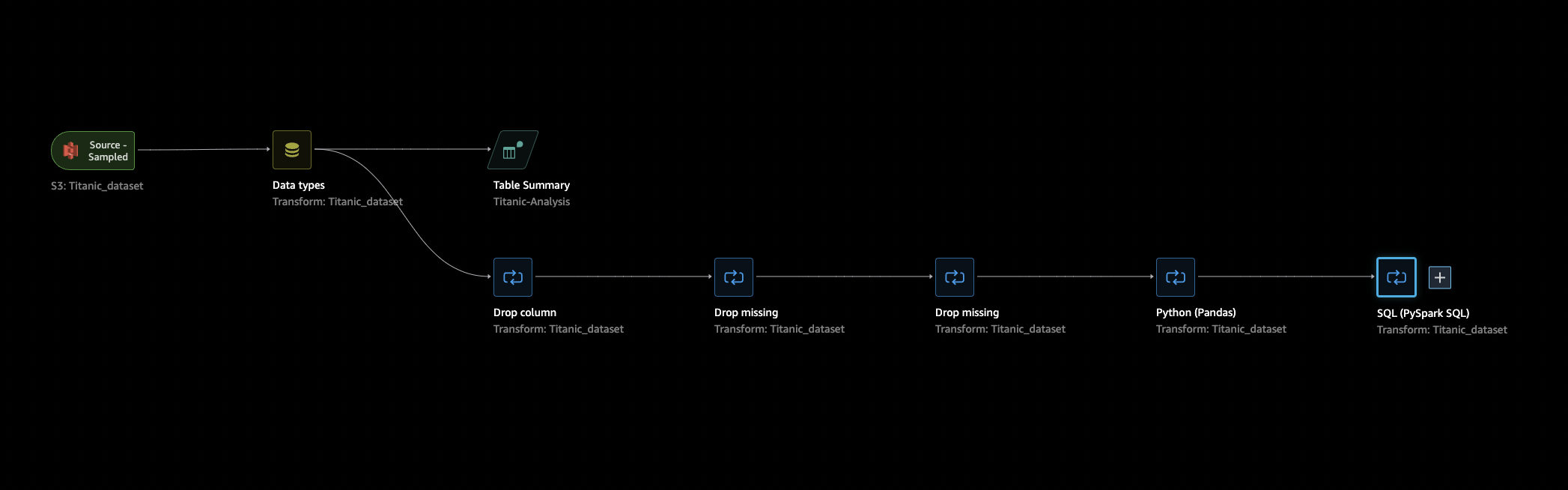
En la sección de flujo de datos, los únicos pasos del flujo de datos son el conjunto de datos recién importado y un paso de Tipo de datos. Tras aplicar las transformaciones, puede volver a esta pestaña y ver el aspecto del flujo de datos. Ahora, añada algunas transformaciones básicas en las pestañas Preparar y Analizar.
Preparación y visualización
Data Wrangler tiene transformaciones y visualizaciones integradas que puede utilizar para analizar, limpiar y transformar los datos.
La pestaña Datos de la vista detallada del nodo muestra todas las transformaciones integradas en el panel derecho, que también contiene un área en la que puede agregar transformaciones personalizadas. El siguiente caso de uso muestra cómo utilizar estas transformaciones.
Para obtener información que pueda ayudarle con la exploración de datos y la ingeniería de características, cree un informe de información y calidad de los datos. La información del informe puede ayudarle a limpiar y procesar los datos. Le proporciona información como el número de valores ausentes y el número de valores atípicos. Si tiene problemas con los datos, como una fuga de objetivos o un desequilibrio, el informe de información puede indicarle esos problemas. Para obtener más información acerca de la creación de un informe, consulte Información sobre los datos y la calidad de los datos.
Exploración de datos
En primer lugar, cree una tabla de resumen de los datos mediante un análisis. Haga lo siguiente:
-
Seleccione el signo + situado junto al paso Tipo de datos del flujo de datos y seleccione Agregar análisis.
-
En el área Análisis, seleccione Tabla de resumen en la lista desplegable.
-
Asigne un nombre a la tabla de resumen.
-
Seleccione Vista previa para obtener una vista previa de la tabla que se va a crear.
-
Elija Guardar para guardarla en su flujo de datos. Aparece en Todos los análisis.
Con las estadísticas que ve, puede realizar observaciones similares a las siguientes sobre este conjunto de datos:
-
La tarifa media (media) ronda los 33 USD, mientras que la máxima supera los 500 USD. Es probable que esta columna tenga valores atípicos.
-
Este conjunto de datos usa ? para indicar los valores ausentes. Faltan valores en varias columnas: cabin, embarked y home.dest
-
Faltan más de 250 valores en la categoría de edad.
A continuación, limpie los datos con la información obtenida de estas estadísticas.
Eliminación de columnas sin utilizar
Con el análisis de la sección anterior, limpie el conjunto de datos para prepararlo para el entrenamiento. Para añadir una nueva transformación al flujo de datos, seleccione el signo + junto al paso Tipo de datos del flujo de datos y seleccione Agregar transformación.
En primer lugar, elimine las columnas que no desee utilizar para el entrenamiento. Para ello, puede usar la biblioteca de análisis de datos de Pandas
Utilice el siguiente procedimiento para eliminar las columnas sin utilizar.
Para eliminar las columnas sin utilizar.
-
Abra el flujo de Data Wrangler.
-
Hay dos nodos en el flujo de Data Wrangler. Seleccione el signo + situado a la derecha del nodo Tipos de datos.
-
Seleccione Agregar transformación.
-
En la columna Todos los pasos, seleccione Agregar paso.
-
En la lista de transformaciones Estándar, elija Administrar columnas. Las transformaciones estándar son transformaciones integradas y listas para usar. Asegúrese de que esté seleccionado Eliminar columna.
-
En Columnas a eliminar, marque los siguientes nombres de columna:
-
cabin
-
ticket
-
name
-
sibsp
-
parch
-
home.dest
-
boat
-
cuerpo
-
-
Seleccione Preview (Versión preliminar).
-
Compruebe que se hayan eliminado las columnas y, a continuación, pulse Agregar.
Para hacer esto con Pandas, siga estos pasos.
-
En la columna Todos los pasos, seleccione Agregar paso.
-
En la lista de transformación Personalizada, elija Transformación personalizada.
-
Proporcione un nombre para la transformación y elija Python (Pandas) en la lista desplegable.
-
Introduzca el siguiente script de Python en el cuadro de código.
cols = ['name', 'ticket', 'cabin', 'sibsp', 'parch', 'home.dest','boat', 'body'] df = df.drop(cols, axis=1) -
Elija Vista previa para obtener una vista previa del cambio y, a continuación, elija Agregar para agregar la transformación.
Eliminación de los valores ausentes
Ahora, limpie los valores ausentes. Puede hacerlo con el grupo de transformación Manejo de valores ausentes.
Faltan valores en varias columnas. En las columnas restantes, faltan los valores age y fare. Inspeccione esto mediante una Transformación personalizada.
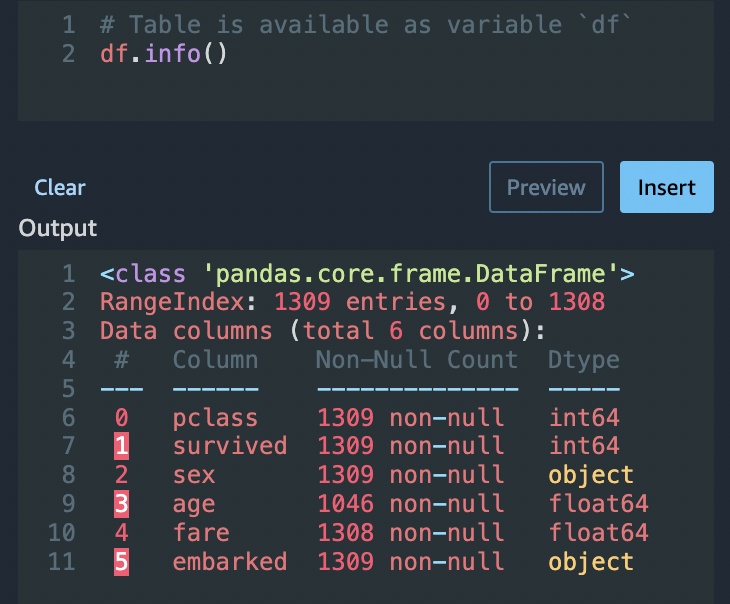
Con la opción Python (Pandas), utilice lo siguiente para revisar rápidamente el número de entradas en cada columna:
df.info()
Para eliminar las filas en las que falten valores en la categoría age, haga lo siguiente:
-
Elija Manejo de ausentes.
-
Elija Eliminar ausentes para el Transformador.
-
Elija age de la Columna de entrada.
-
Elija Vista previa para ver el nuevo marco de datos y, a continuación, elija Agregar para agregar la transformación a su flujo.
-
Repita el mismo proceso para fare.
Puede utilizar df.info() en la sección Transformación personalizada para confirmar que todas las filas tienen ahora 1045 valores.
Pandas personalizados: codificación
Pruebe la codificación plana con Pandas. La codificación de datos categóricos es el proceso de crear una representación numérica de las categorías. Por ejemplo, si las categorías son Dog y Cat, puede codificar esta información en dos vectores: [1,0] representar Dog y [0,1] para representar Cat.
-
En la sección Transformación personalizada, elija Python (Pandas) en la lista desplegable.
-
Introduzca lo siguiente en el cuadro de código.
import pandas as pd dummies = [] cols = ['pclass','sex','embarked'] for col in cols: dummies.append(pd.get_dummies(df[col])) encoded = pd.concat(dummies, axis=1) df = pd.concat((df, encoded),axis=1) -
Seleccione Vista previa para obtener una vista previa del cambio. La versión codificada de cada columna se añade al conjunto de datos.
-
Elija Agregar para agregar la transformación.
SQL personalizado: columnas SELECT
Ahora, seleccione las columnas que desea conservar mediante SQL. Para esta demostración, seleccione las columnas que aparecen en la siguiente instrucción SELECT. Como survived es su columna objetivo para el entrenamiento, coloque esa columna primero.
-
En la sección Transformación personalizada, selecciona SQL (PySpark SQL) en la lista desplegable.
-
Introduzca lo siguiente en el cuadro de código.
SELECT survived, age, fare, 1, 2, 3, female, male, C, Q, S FROM df; -
Seleccione Vista previa para obtener una vista previa del cambio. Las columnas que aparecen en la instrucción
SELECTson las únicas columnas restantes. -
Elija Agregar para agregar la transformación.
Exportación a un cuaderno de Data Wrangler
Cuando haya terminado de crear un flujo de datos, dispondrá de varias opciones de exportación. En la siguiente sección, se explica cómo exportar a un cuaderno de trabajo de Data Wrangler. Un trabajo de Data Wrangler se utiliza para procesar los datos según los pasos definidos en el flujo de datos. Para obtener más información sobre todas las opciones de exportación, consulte Exportación.
Exportación a un cuaderno de trabajo de Data Wrangler
Cuando exporta el flujo de datos mediante un Trabajo de Data Wrangler, el proceso crea automáticamente un cuaderno de Jupyter. Este bloc de notas se abre automáticamente en su instancia de Studio Classic y está configurado para ejecutar un trabajo de SageMaker procesamiento que ejecute su flujo de datos de Data Wrangler, lo que se denomina trabajo de Data Wrangler.
-
Guarde el flujo de datos. Seleccione Archivo y, a continuación, seleccione Guardar flujo de Data Wrangler.
-
Vuelva a la pestaña Flujo de datos, seleccione el último paso del flujo de datos (SQL) y, a continuación, elija el signo + para abrir la navegación.
-
Elija Exportar y Amazon S3 (a través del cuaderno de Jupyter). Esto abrirá un cuaderno de Jupyter.
-
Elija cualquier kernel de Python 3 (ciencia de datos) para Kernel.
-
Cuando se inicie el núcleo, ejecute las celdas del cuaderno hasta Kick off SageMaker Training Job (opcional).
-
Si lo desea, puede ejecutar las celdas en Kick off SageMaker Training Job (opcional) si desea crear un trabajo de entrenamiento de SageMaker IA para entrenar un clasificador XGBoost. Puedes encontrar el coste de realizar un trabajo de SageMaker formación en Amazon SageMaker Pricing
. Como alternativa, puede agregar los bloques de código que se encuentran en Clasificador XGBoost de entrenamiento al cuaderno y ejecutarlos para utilizar la biblioteca de código abierto de XGBoost
para entrenar un clasificador XGBoost. -
Elimine los comentarios y ejecute la celda en Cleanup y ejecútela para revertir el SDK de SageMaker Python a su versión original.
Puedes supervisar el estado de tu trabajo en Data Wrangler en la consola de SageMaker IA, en la pestaña Procesamiento. Además, puede supervisar su trabajo en Data Wrangler con Amazon. CloudWatch Para obtener información adicional, consulta Supervisar los trabajos SageMaker de procesamiento de Amazon con CloudWatch registros y métricas.
Si ha iniciado un trabajo de formación, puede supervisar su estado mediante la consola de SageMaker IA, en la sección Formación de tareas, en la sección Formación.
Clasificador XGBoost de entrenamiento
Puedes entrenar un clasificador binario XGBoost con un cuaderno Jupyter o un piloto automático de Amazon. SageMaker Puede usar el piloto automático para entrenar y ajustar modelos de forma automática en los datos que ha transformado directamente en su flujo de Data Wrangler. Para obtener más información acerca del piloto automático, consulte Entrenamiento automático de modelos en su flujo de datos.
En el mismo cuaderno en el que se inició el trabajo de Data Wrangler, puede extraer los datos y entrenar un clasificador binario XGBoost empleando los datos preparados con una preparación mínima de los datos.
-
En primer lugar, actualice los módulos necesarios mediante
pipy elimine el archivo _SUCCESS (este último archivo es problemático cuando se utilizaawswrangler).! pip install --upgrade awscli awswrangler boto sklearn ! aws s3 rm {output_path} --recursive --exclude "*" --include "*_SUCCESS*" -
Lea los datos de Amazon S3. Puede utilizar
awswranglerpara leer de forma recursiva todos los archivos CSV en el prefijo S3. A continuación, los datos se dividen en características y etiquetas. La etiqueta es la primera columna del marco de datos.import awswrangler as wr df = wr.s3.read_csv(path=output_path, dataset=True) X, y = df.iloc[:,:-1],df.iloc[:,-1]-
Por último, cree DMatrices (la estructura primitiva de datos de XGBoost) y realice una validación cruzada utilizando la clasificación binaria de XGBoost.
import xgboost as xgb dmatrix = xgb.DMatrix(data=X, label=y) params = {"objective":"binary:logistic",'learning_rate': 0.1, 'max_depth': 5, 'alpha': 10} xgb.cv( dtrain=dmatrix, params=params, nfold=3, num_boost_round=50, early_stopping_rounds=10, metrics="rmse", as_pandas=True, seed=123)
-
Apagado de Data Wrangler
Cuando termine de usar Data Wrangler, se recomienda apagar la instancia en la que se ejecuta para evitar incurrir en cargos adicionales. Para obtener información sobre cómo apagar la aplicación Data Wrangler y la instancia asociada, consulte Apagado de Data Wrangler.
