Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Automatice el etiquetado de datos
Si lo deseas, Amazon SageMaker Ground Truth puede utilizar el aprendizaje activo para automatizar el etiquetado de los datos de entrada para determinados tipos de tareas integradas. El aprendizaje activo es una técnica de machine learning que identifica los datos que los trabajadores deben etiquetar. En Ground Truth, esta funcionalidad se denomina etiquetado de datos automatizado. El etiquetado de datos automatizado permite reducir los costos y el tiempo necesarios para etiquetar el conjunto de datos en comparación a cuando esta tarea la realizan exclusivamente humanos. Cuando utiliza el etiquetado automatizado, incurre en costes de SageMaker formación e inferencia.
Es recomendable utilizar el etiquetado de datos automatizado en conjuntos de datos grandes, ya que las redes neuronales que se utilizan con el aprendizaje activo requieren una cantidad significativa de datos en cada nuevo conjunto de datos. Normalmente, a medida que se proporcionan más datos, aumenta la probabilidad de obtener predicciones con una elevada precisión. Los datos solo se etiquetarán automáticamente si la red neuronal que se utiliza en el modelo de etiquetado automático puede lograr un nivel de precisión aceptablemente alto. Por lo tanto, en conjuntos de datos más grandes, la probabilidad de que los datos se etiqueten automáticamente es mayor, ya que la red neuronal puede lograr una precisión lo suficientemente alta. El etiquetado de datos automatizado resulta más apropiado cuando se tienen miles de objetos de datos. El número mínimo de objetos permitidos para el etiquetado de datos automatizado es de 1250, pero recomendamos encarecidamente proporcionar un mínimo de 5000 objetos.
El etiquetado de datos automatizado solo está disponible para los siguientes tipos de tareas integradas en Ground Truth:
Los trabajos de etiquetado en streaming no admiten etiquetado de datos automatizado.
Para aprender a crear un flujo de trabajo de aprendizaje activo personalizado utiilizando su propio modelo, consulte Configurar un flujo de trabajo de aprendizaje activo con su propio modelo.
Las cuotas de datos de entrada se aplican a los trabajos de etiquetado automatizados. Consulte Cuotas de datos de entrada para obtener información sobre el tamaño del conjunto de datos, el tamaño de los datos de entrada y los límites de resolución.
nota
Antes de utilizar el modelo de etiquetado automático en producción, debe realizar ajustes, pruebas o ambas cosas. Puede ajustar el modelo del conjunto de datos generado por el trabajo de etiquetado (o crear y ajustar otro modelo supervisado que elija) para optimizar la arquitectura y los hiperparámetros del modelo. Si decide utilizar el modelo para realizar inferencias sin ajustarlo, le recomendamos encarecidamente que se asegure de evaluar su precisión en un subconjunto representativo del conjunto de datos (por ejemplo, un subconjunto seleccionado aleatoriamente) etiquetado con Ground Truth para confirmar que se ajusta a sus expectativas.
Funcionamiento
El etiquetado de datos automatizado se habilita cuando se crea un trabajo de etiquetado. Así es como funciona:
-
Cuando Ground Truth inicia un trabajo de etiquetado de datos automatizado, selecciona una muestra aleatoria de objetos de datos de entrada y los envía a trabajadores humanos. Si más del 10 % de estos objetos de datos producen error, el trabajo de etiquetado fallará. Si el trabajo de etiquetado falla, además de revisar los mensajes de error que devuelva Ground Truth, compruebe que los datos de entrada se muestran correctamente en la interfaz de usuario del trabajador, que las instrucciones son claras y que ha dado a los trabajadores tiempo suficiente para completar las tareas.
-
Cuando se devuelven los datos etiquetados, se utilizan para crear un conjunto de entrenamiento y un conjunto de validación. Ground Truth utiliza estos conjuntos de datos para entrenar y validar el modelo utilizado para etiquetado automático.
-
Ground Truth ejecuta un trabajo de transformación por lotes utilizando el modelo validado para inferencia en los datos de validación. La inferencia por lotes produce una puntuación de confianza y una métrica de calidad para cada objeto de los datos de validación.
-
El componente de etiquetado automático utilizará estas métricas de calidad y estas puntuaciones de confianza para crear un umbral de puntuación de confianza que garantice etiquetas de calidad.
-
Ground Truth ejecuta un trabajo de transformación por lotes en los datos sin etiquetar del conjunto de datos utilizando el mismo modelo que se validó para la inferencia. De este modo, se genera una puntuación de confianza para cada objeto.
-
El componente de etiquetado automático de Ground Truth determina si la puntuación de confianza generada en el paso 5 para cada objeto cumple el umbral requerido que se determinó en el paso 4. Si la puntuación de confianza satisface este umbral, la calidad esperada del etiquetado automático excede el nivel de precisión solicitado y se considera que ese objeto se etiquetó automáticamente.
-
El paso 6 produce un conjunto de datos sin etiquetar con puntuaciones de confianza. Ground Truth selecciona puntos de datos con puntuaciones de confianza bajas de este conjunto de datos y los envía a trabajadores humanos.
-
Ground Truth utiliza los datos existentes etiquetados por humanos y estos datos adicionales etiquetados procedentes de trabajadores humanos para actualizar el modelo.
-
El proceso se repite hasta que el conjunto de datos está completamente etiquetado o hasta que se cumple otra condición de detención. Por ejemplo, el etiquetado automático se detiene si se alcanza el presupuesto asignado a la anotación por humanos.
Los pasos anteriores se realizan en iteraciones. Seleccione cada pestaña de la tabla siguiente para ver un ejemplo de los procesos que se producen en cada iteración para un trabajo de etiquetado automatizado de detección de objetos. El número de objetos de datos utilizados en un paso determinado en estas imágenes (por ejemplo, 200) es específico de este ejemplo. Si hay menos de 5000 objetos para etiquetar, el tamaño del conjunto de validación es el 20 % de todo el conjunto de datos. Si hay menos de 5000 objetos en el conjunto de datos de entrada, el tamaño del conjunto de validación es el 10 % de todo el conjunto de datos. Puede controlar la cantidad de etiquetas humanas recopiladas por iteración de aprendizaje activa cambiando el valor MaxConcurrentTaskCountal utilizar la operación. API CreateLabelingJob Este valor se establece en 1000 al crear un trabajo de etiquetado mediante la consola. En el flujo de aprendizaje activo que se muestra en la pestaña Aprendizaje activo, este valor se establece en 200.
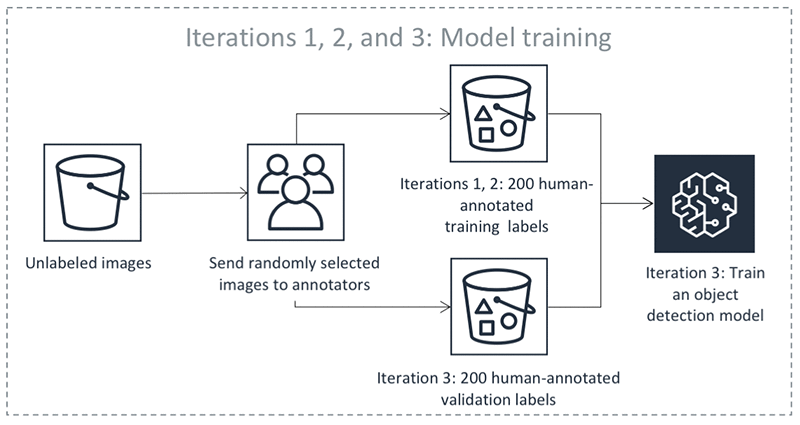
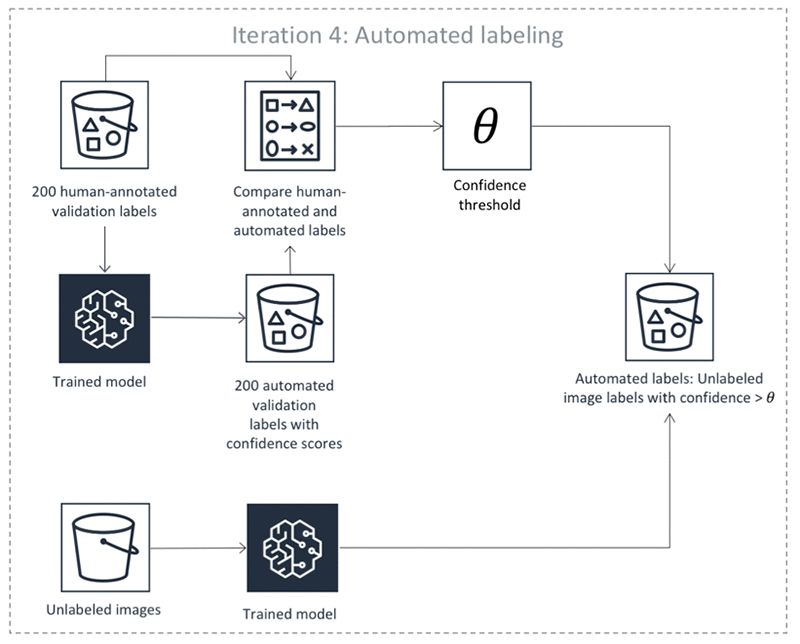
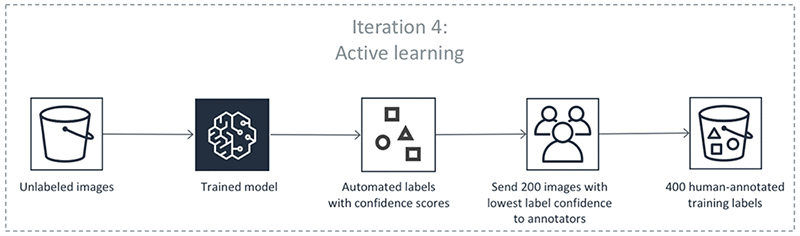
Precisión de las etiquetas automatizadas
La definición de precisión depende del tipo de tarea integrada que utiliza con etiquetado automatizado. Para todos los tipos de tareas, Ground Truth predetermina estos requisitos de precisión, que no se pueden configurar manualmente.
-
Para clasificación de imágenes y clasificación de textos, Ground Truth utiliza la lógica para buscar un nivel de confianza en la predicción de etiquetas que corresponda a una precisión mínima de etiquetas del 95 %. Esto significa que Ground Truth espera que la precisión de las etiquetas automatizadas sea como mínimo del 95 % en comparación con las etiquetas que proporcionarían los etiquetadores humanos para esos ejemplos.
-
Para los cuadros delimitadores, la intersección sobre la unión (IoU)
media esperada de las imágenes etiquetadas automáticamente es 0,6. Para hallar la IoU media, Ground Truth calcula la IoU media de todos los cuadros previstos y omitidos en la imagen para cada clase y, a continuación, calcula el promedio de estos valores entre las clases. -
Para segmentación semántica, la IoU media esperada de las imágenes etiquetadas automáticamente es 0,7. Para hallar la IoU media, Ground Truth toma la media de los valores de IoU de todas las clases de la imagen (excluido el fondo).
En cada iteración de aprendizaje activo (pasos 3-6 de la lista anterior), el umbral de confianza se encuentra utilizando el conjunto de validación anotado por humanos, de modo que la precisión esperada de los objetos etiquetados automáticamente satisfaga determinados requisitos de precisión predefinidos.
Cree un trabajo de etiquetado de datos automatizado (consola)
Para crear un trabajo de etiquetado que utilice el etiquetado automatizado en la SageMaker consola, utilice el siguiente procedimiento.
Para crear un trabajo de etiquetado de datos automatizado (consola)
-
Abra la sección de trabajos de Ground Truth Labeling de la SageMaker consola:https://console.aws.amazon.com/sagemaker/groundtruth
. -
Utilizando Crear un trabajo de etiquetado (consola) como guía, complete las secciones Descripción general del trabajo y Tipo de tarea. Tenga en cuenta que el etiquetado automático no es compatible con los tipos de tareas personalizados.
-
En Empleados, elija el tipo de trabajadores.
-
En la misma sección, elija Etiquetado automatizado de datos.
-
Configura la herramienta Bounding BoxUtilizándolo como guía, cree instrucciones para el trabajador en la sección
Task Typeherramienta de etiquetado. Por ejemplo, si eligió Segmentación semántica como tipo de trabajo de etiquetado, esta sección se llama Herramienta de etiquetado para segmentación semántica. -
Para obtener una vista previa de las instrucciones de trabajo y del panel, elija Vista previa.
-
Seleccione Crear. Se creará e iniciará el trabajo de etiquetado y el proceso de etiquetado automático.
Puede ver que su trabajo de etiquetado aparece en la sección Trabajos de etiquetado de la SageMaker consola. Los datos de salida aparecen en el bucket de Amazon S3 que especificó al crear el trabajo de etiquetado. Para obtener más información sobre el formato y la estructura de archivos de los datos de salida de un trabajo de etiquetado, consulte Etiquetar los datos de salida del trabajo.
Cree un trabajo de etiquetado de datos automatizado (API)
Para crear un trabajo de etiquetado de datos automatizado mediante el SageMaker API, utilice el LabelingJobAlgorithmsConfigparámetro de la CreateLabelingJoboperación. Para obtener información sobre cómo iniciar un trabajo de etiquetado mediante la operación CreateLabelingJob, consulte Crear un trabajo de etiquetado (API).
Especifique el nombre del recurso de Amazon (ARN) del algoritmo que está utilizando para el etiquetado automatizado de datos en el LabelingJobAlgorithmSpecificationArnparámetro. Elija uno de los cuatro algoritmos integrados en Ground Truth que son compatibles con el etiquetado automatizado:
Cuando finaliza un trabajo de etiquetado de datos automatizado, Ground Truth devuelve el ARN modelo que utilizó para el trabajo de etiquetado de datos automatizado. Utilice este modelo como modelo de partida para tipos de trabajos de etiquetado automático similares proporcionando el InitialActiveLearningModelArnparámetroARN, en formato de cadena. Para recuperar el modeloARN, utilice un comando AWS Command Line Interface (AWS CLI) similar al siguiente.
# Fetch the mARN of the model trained in the final iteration of the previous labeling job.Ground Truth pretrained_model_arn = sagemaker_client.describe_labeling_job(LabelingJobName=job_name)['LabelingJobOutput']['FinalActiveLearningModelArn']
Para cifrar los datos del volumen de almacenamiento adjunto a las instancias de procesamiento de aprendizaje automático que se utilizan en el etiquetado automatizado, incluya una clave AWS Key Management Service (AWS KMS) en el VolumeKmsKeyId parámetro. Para obtener información sobre AWS KMS las claves, consulte ¿Qué es el servicio de administración de AWS claves? en la Guía para desarrolladores del servicio de administración de AWS claves.
Para ver un ejemplo en el que se usa la CreateLabelingJoboperación para crear un trabajo de etiquetado de datos automatizado, consulta el ejemplo object_detection_tutorial en la sección Examples, SageMaker Ground Truth Labeling Jobs de una instancia de notebook. SageMaker Para obtener información acerca de cómo crear y abrir una instancia de bloc de notas, consulte Crear una instancia de Amazon SageMaker Notebook. Para obtener información sobre cómo acceder a cuadernos de ejemplo, consulte SageMaker . Accede a cuadernos de ejemplo
Se requieren EC2 instancias de Amazon para el etiquetado automatizado de datos
En la siguiente tabla se enumeran las instancias de Amazon Elastic Compute Cloud (AmazonEC2) que necesita para ejecutar el etiquetado de datos automatizado para trabajos de formación e inferencia por lotes.
| Tipo de trabajo de etiquetado de datos automatizado | Tipo de instancia de entrenamiento | Tipo de instancia de inferencia |
|---|---|---|
|
Clasificación de imágenes |
ml.p3.2xlarge* |
ml.c5.xlarge |
|
Detección de objetos (cuadro delimitador) |
ml.p3.2xlarge* |
ml.c5.4xlarge |
|
Clasificación de textos |
ml.c5.2xlarge |
ml.m4.xlarge |
|
Segmentación semántica |
ml.p3.2xlarge* |
ml.p3.2xlarge* |
* En la región Asia-Pacífico (Bombay) (ap-south-1), utilice ml.p2.8xlarge en su lugar.
Ground Truth administra las instancias que se utilizan para trabajos de etiquetado de datos automatizados. Este servicio crea, configura y termina las instancias según sea necesario para realizar el trabajo. Estas instancias no aparecen en tu panel de EC2 instancias de Amazon.
Configurar un flujo de trabajo de aprendizaje activo con su propio modelo
Puede crear un flujo de trabajo de aprendizaje activo con su propio algoritmo para ejecutar el entrenamiento y las inferencias en ese flujo de trabajo y etiquetar automáticamente sus datos. El cuaderno bring_your_own_model_for_sagemaker_labeling_workflows_with_active_learning.ipynb lo demuestra mediante el algoritmo incorporado,. SageMaker BlazingText Este cuaderno proporciona una pila que puede utilizar para ejecutar este flujo de trabajo. AWS CloudFormation AWS Step Functions Puede encontrar el cuaderno y los archivos auxiliares en este GitHub repositorio
También puede encontrar este cuaderno en el repositorio de SageMaker ejemplos. Consulta Utilizar cuadernos de ejemplo para obtener información sobre cómo encontrar un SageMaker ejemplo de bloc de notas de Amazon.
