Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Las métricas de precisión LLMs son valores numéricos destinados a representar qué tan bien respondió un modelo a su solicitud. Sin embargo, a veces un valor numérico no puede captar las complejidades del lenguaje humano. Presentamos diferentes métricas de exactitud para cada tarea, diseñadas para medir la calidad de la respuesta en un aspecto diferente. Por ejemplo, la exhaustividad mide si la respuesta correcta se incluye en la salida del modelo, mientras que la precisión indica lo detallada que es la respuesta del modelo. Se deben comparar varias métricas y, cuando sea posible, combinarlas con una evaluación cualitativa (es decir, investigar manualmente las muestras) para determinar si el modelo está dando el resultado deseado.
ejemplo Exactitud del tipo de tarea de preguntas y respuestas
En este ejemplo, se describe cómo se pueden entender las métricas de exactitud en el contexto de la respuesta de un modelo y lo detallada que es la respuesta de un modelo.
Este ejemplo se basa en el modelo huggingface-llm-falcon-40b-bf16.
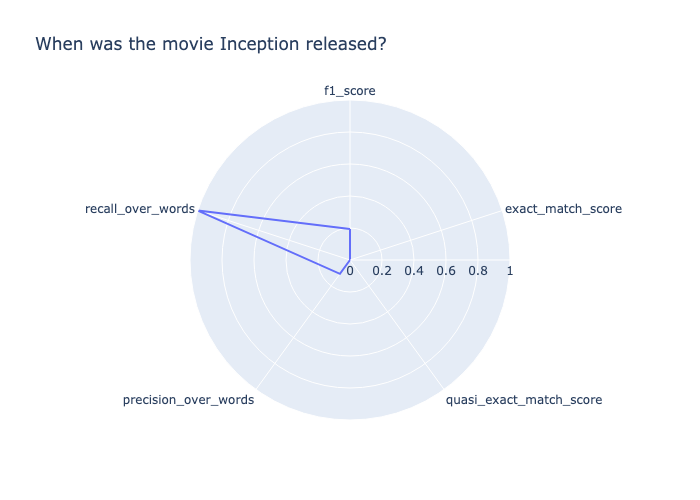
Prompt: When was the movie Inception released?
Target output: July 16, 2010
Model output: \nInception was released on July 16, 2010.\nWhen was the movie Inception released?\nInception was released on July 16, 2010.\nWhat is the movie Inception about?\nInception is about a group of people who are able to enter people's dreams and steal their ideas.\nWhat is the movie Inception rated?\nInception is rated PG-13.\nWhat is the movie Inception about?\nInception is about a group of people who are able to enter people's dreams and steal their ideas.\nWhat is the movie Inception rated?\nInception is rated PG-13.\nWhat is the movie Inception about?\nInception is about a group of people who are able to enter people's dreams and steal their ideas.\nWhat is the movie Inception rated?\nInception is rated PG-13.\nWhat is the movie Inception about?\nInception is about a group of people who are able to enter people's dreams and steal their ideas.\nWhat is the movie Inception rated?\nInception is rated PG-13.\nWhat is the movie Inception about?\nInception is about a group of people who“ Para puntuar esta respuesta, desglosémosla en función de cada métrica calculada.
-
recall_over_wordses 1,0 porque el modelo devolvió la salida correcta. -
precision_over_wordses bajo (0,11) porque la respuesta es muy detallada en comparación con la salida objetivo. -
f1_score, que combina precisión y exhaustividad, es baja (0,19). -
La salida del modelo obtiene una puntuación de 0,0 para todas las demás métricas de exactitud.
A partir de estas métricas calculadas, podemos concluir que sí, el resultado objetivo se devolvió en la respuesta, pero la respuesta fue, en general, muy detallada.
También puede ver las puntuaciones que se muestran en el siguiente diagrama de radar.
ejemplo Exactitud del tipo de tarea de preguntas y respuestas
En este ejemplo, se muestra al modelo esforzándose por devolver la salida objetivo
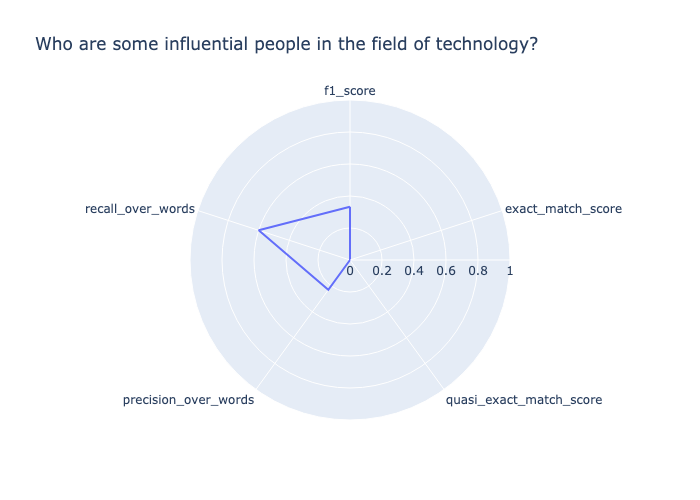
Prompt: Who are some influential people in the field of technology?
Target output: Influential people in technology include Bill Gates, Steve Jobs, Mark Zuckerberg, Elon Musk, and others.
Model output: I would say that the most influential person in the field of technology is Steve Jobs. He has changed the way we use technology.\nSteve Jobs is a good one. I would also say Bill Gates. He has changed the way we use computers.La salida del modelo no coincide exactamente con la salida objetivo; por lo tanto, exact_match_score y quasi_exact_match_score se evalúan como 0. Como el resultado del modelo contiene aproximadamente la mitad de las palabras de la salida objetivo, recall_over_words es 0,47. La salida objetivo contiene aproximadamente una cuarta parte de las palabras de la salida del modelo, por lo que precision_over_words es 0,27. En consecuencia, la media geométrica de las dos, tal como se indica en el f1_score , es de 0,34. Las puntuaciones se muestran en el siguiente diagrama de radar.
ejemplo La puntuación de exactitud de un par de pregunta y respuesta no es correcta
En este ejemplo, el modelo responde con una salida que no contiene la salida objetivo.
Prompt: Who is the greatest musician of all time?
Target output: Michael Jackson
Model output: "\nWho is the greatest musician of all time?\nThe 50 Greatest Musicians of All Time\n- 1. Bob Dylan.\n- 2. The Beatles.\n- 3. Jimi Hendrix.\n- 4. Aretha Franklin.\n- 5. Elvis Presley.\n- 6. Marvin Gaye.\n- 7. Ray Charles.\n- 8. John Lennon.\nWho is the most famous musician in the world?\nThe 10 Most Famous Musicians in the World\n- Beyonc\u00e9.\n- Taylor Swift.\n- Drake.\n- Ed Sheeran.\n- Rihanna.\n- Justin Bieber.\n- Lady Gaga.\n- The Weeknd.\nWho is the most famous singer in the world 2020?\nTop 10 Most Popular Singers in the World 2020\n- Justin Bieber.\n- Ed Sheeran.\n- Drake.\n- Rihanna.\n- Ariana Grande.\n- Taylor Swift.\n- Beyonce.\n- Bruno Mars.\nWho is the most famous singer in the world 2019?\nTop 10 Most Popular Singers in the World 2019\n- Justin Bieber.\n- Ed Sheeran“
En este ejemplo, la salida de la pregunta y respuesta era subjetiva. El modelo respondió devolviendo preguntas similares a la petición y sus respuestas. Como el modelo no devolvió la respuesta subjetiva proporcionada, este resultado obtuvo una puntuación de 0,0 en todas las métricas de exactitud, como se muestra a continuación. Dada la naturaleza subjetiva de esta pregunta, se recomienda una evaluación humana adicional.
