Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Evaluación del modelo
Ahora que ha entrenado e implementado un modelo con Amazon SageMaker AI, evalúe el modelo para asegurarse de que genera predicciones precisas a partir de nuevos datos. Para ello, utilice el conjunto de datos de prueba que ha creado en Preparación de un conjunto de datos.
Evalúe el modelo implementado en los servicios de alojamiento de SageMaker IA
Para evaluar el modelo y usarlo en producción, invoque el punto de conexión con el conjunto de datos de prueba y compruebe si las inferencias obtenidas arrojan la precisión deseada.
Para evaluar el modelo
-
Configure la siguiente función para predecir cada línea del conjunto de prueba. En el siguiente código de ejemplo, el argumento
rowssirve para especificar el número de líneas que se van a predecir a la vez. Puede cambiar su valor para realizar una inferencia por lotes que utilice al máximo los recursos de hardware de la instancia.import numpy as np def predict(data, rows=1000): split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1)) predictions = '' for array in split_array: predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')]) return np.fromstring(predictions[1:], sep=',') -
Ejecute el siguiente código para hacer predicciones del conjunto de datos de prueba y trazar un histograma. Debe tomar solo las columnas de características del conjunto de datos de prueba, excluyendo la columna 0 para los valores reales.
import matplotlib.pyplot as plt predictions=predict(test.to_numpy()[:,1:]) plt.hist(predictions) plt.show()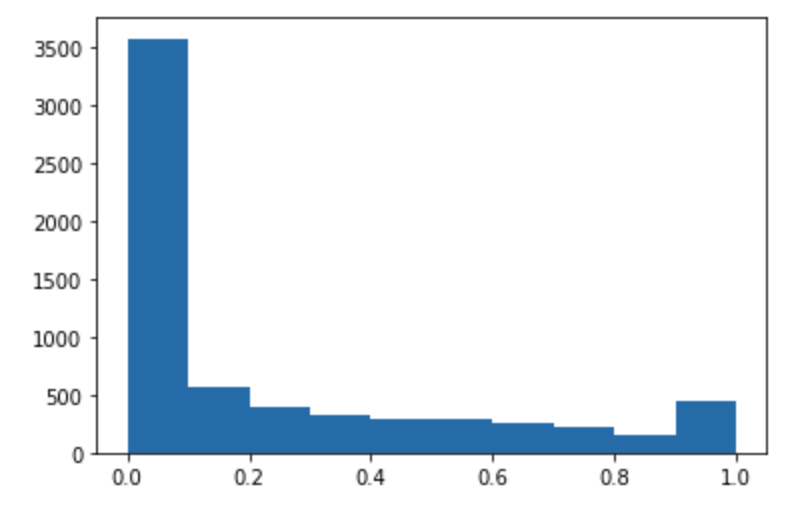
-
Los valores pronosticados son de tipo flotante. Para determinar
TrueoFalseen función de en los valores flotantes, debe establecer un valor límite. Como se muestra en el siguiente código de ejemplo, utilice la Scikit-learn biblioteca para devolver el informe de clasificación y las métricas de confusión de salida con un límite de 0,5.import sklearn cutoff=0.5 print(sklearn.metrics.confusion_matrix(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0))) print(sklearn.metrics.classification_report(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0)))Esto debe devolver la siguiente matriz de confusión:
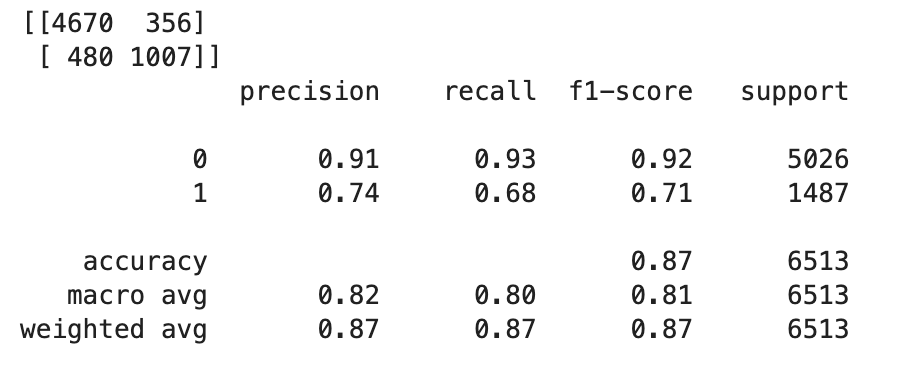
-
Para determinar el mejor límite con el conjunto de pruebas dado, calcule la función de pérdida logística de la regresión logística. La función de pérdida logística se define como la probabilidad logística negativa de un modelo logístico que devuelve probabilidades de predicción para sus etiquetas de verdad básica. El siguiente código de ejemplo calcula numérica e iterativamente los valores de pérdida logística (
-(y*log(p)+(1-y)log(1-p)), dondeyes la etiqueta verdadera ypes una estimación de probabilidad de la muestra de prueba correspondiente. Devuelve una gráfica de pérdida logística con respecto al límite.import matplotlib.pyplot as plt cutoffs = np.arange(0.01, 1, 0.01) log_loss = [] for c in cutoffs: log_loss.append( sklearn.metrics.log_loss(test.iloc[:, 0], np.where(predictions > c, 1, 0)) ) plt.figure(figsize=(15,10)) plt.plot(cutoffs, log_loss) plt.xlabel("Cutoff") plt.ylabel("Log loss") plt.show()Esto debería devolver la siguiente curva de pérdida logística.
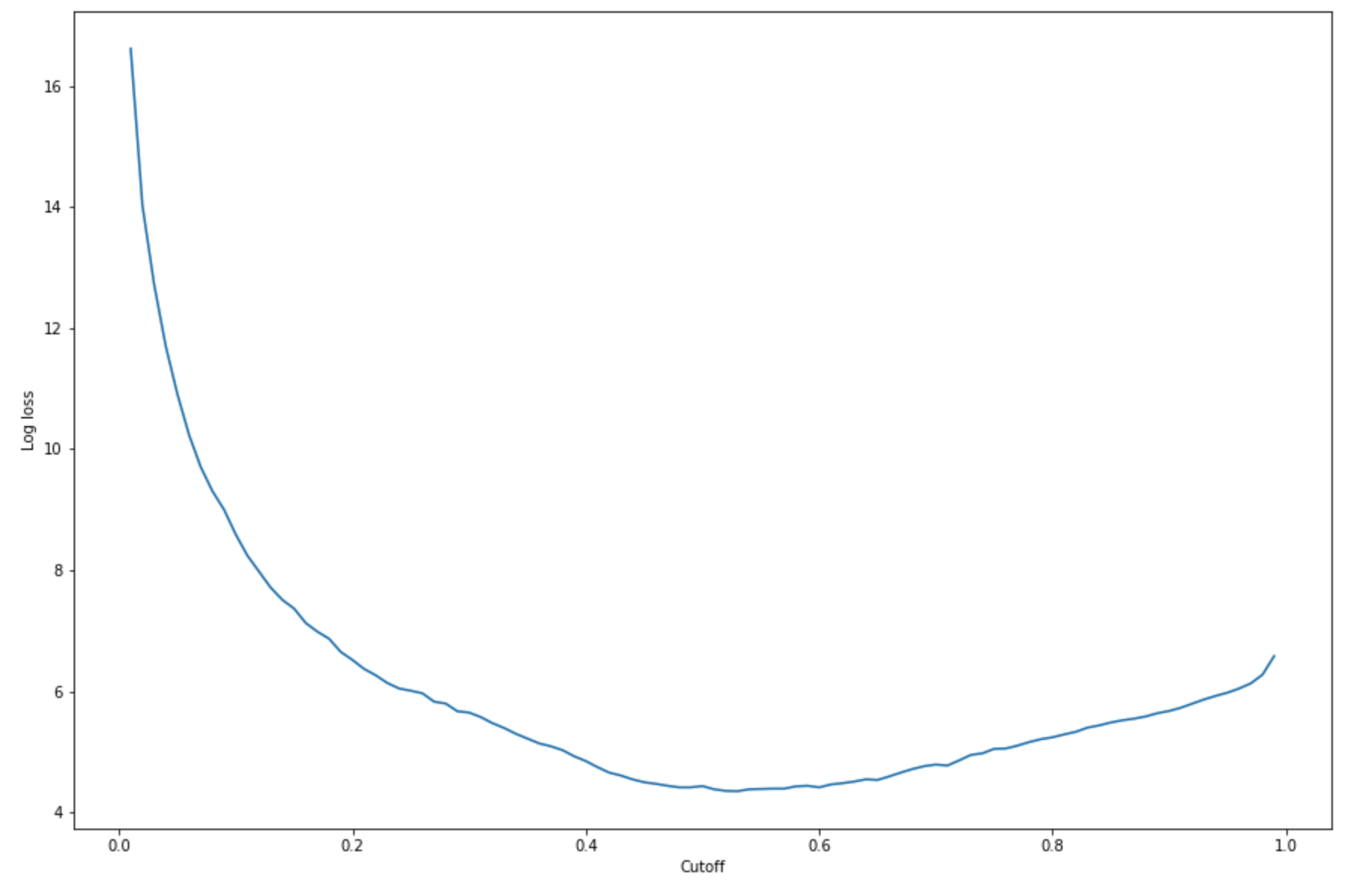
-
Encuentre los puntos mínimos de la curva de error mediante las funciones NumPy
argminymin:print( 'Log loss is minimized at a cutoff of ', cutoffs[np.argmin(log_loss)], ', and the log loss value at the minimum is ', np.min(log_loss) )Esto debería devolver:
Log loss is minimized at a cutoff of 0.53, and the log loss value at the minimum is 4.348539186773897.En lugar de calcular y minimizar la función de pérdida logística, puede estimar una función de costo como alternativa. Por ejemplo, si desea entrenar un modelo para realizar una clasificación binaria de un problema empresarial, como un problema de predicción de la pérdida de clientes, puede establecer ponderaciones para los elementos de la matriz de confusión y calcular la función de costo en consecuencia.
Ya ha entrenado, implementado y evaluado su primer modelo en SageMaker IA.
sugerencia
Para supervisar la calidad del modelo, la calidad de los datos y la desviación de sesgo, utilice Amazon SageMaker Model Monitor y SageMaker AI Clarify. Para obtener más información, consulte Amazon SageMaker Model Monitor, Monitor Data Quality, Monitor Model Quality, Monitor Bias Drift y Monitor Feature Attribution Drift.
sugerencia
Para obtener una revisión humana de las predicciones de machine learning de baja confianza o una muestra aleatoria de las predicciones, utilice los flujos de trabajo de revisión humana aumentados con IA de Amazon. Para obtener más información, consulte Uso de Amazon Augmented AI para la revisión humana.
