Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Prueba de modelos con variantes de producción
En los flujos de trabajo de ML de producción, los ingenieros y científicos de datos tratan con frecuencia de mejorar los modelos de diversas maneras, por ejemplo Ajuste automático del modelo con IA SageMaker, realizando entrenamientos en datos adicionales o más recientes y mejorando la selección de características, utilizando instancias con mejor actualización y prestando servicio de contenedores. Puede utilizar las variantes de producción para comparar sus modelos, instancias y contenedores, y elegir el candidato con mejor rendimiento para responder a solicitudes de inferencia.
Con los puntos de enlace multivariantes de SageMaker IA, puede distribuir las solicitudes de invocación de puntos finales en varias variantes de producción proporcionando la distribución del tráfico para cada variante, o puede invocar una variante específica directamente para cada solicitud. En este tema, analizamos ambos métodos para probar modelos ML.
Temas
Probar modelos especificando la distribución del tráfico
Para probar varios modelos distribuyendo tráfico entre ellos, especifique el porcentaje del tráfico que se dirige a cada modelo indicando el peso de cada variante de producción en la configuración del punto de enlace. Para obtener información, consulte CreateEndpointConfig. El siguiente diagrama muestra con más detalle cómo funciona este proceso.
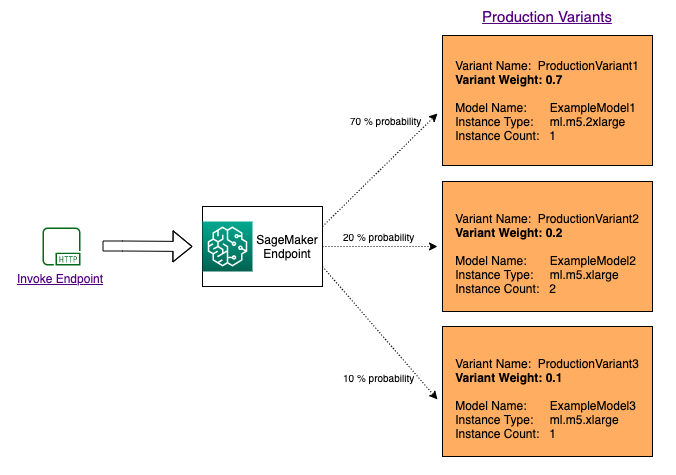
Probar modelos invocando variantes específicas
Para probar varios modelos invocando modelos específicos para cada solicitud, especifique la versión específica del modelo que desea invocar proporcionando un valor para el TargetVariant parámetro cuando llame. InvokeEndpoint SageMaker La IA se asegura de que la solicitud se procese según la variante de producción que especifique. Si ya ha proporcionado la distribución del tráfico y especificado un valor para el parámetro TargetVariant, el direccionamiento dirigido suplanta la distribución aleatoria del tráfico. El siguiente diagrama muestra con más detalle cómo funciona este proceso.
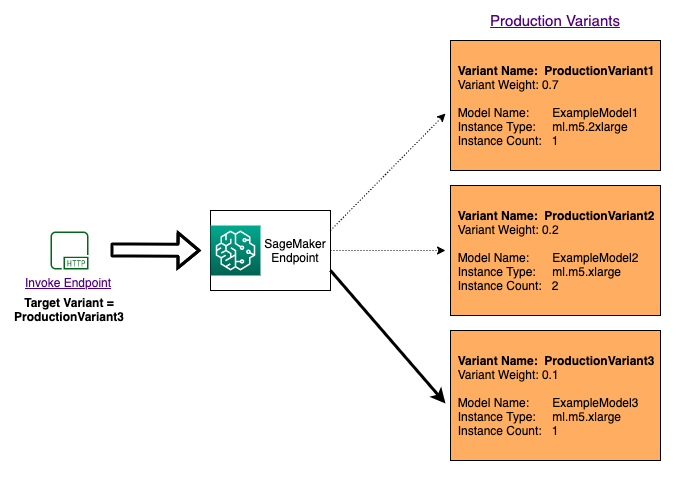
Ejemplo de A/B prueba de modelo
Realizar A/B pruebas entre un modelo nuevo y un modelo antiguo con tráfico de producción puede ser un paso final eficaz en el proceso de validación de un modelo nuevo. En A/B las pruebas, se prueban diferentes variantes de los modelos y se compara el rendimiento de cada variante. Si la versión más reciente del modelo ofrece un mejor rendimiento que la versión anterior, reemplace la versión anterior del modelo por la nueva versión en producción.
El siguiente ejemplo muestra cómo realizar las pruebas A/B del modelo. Para ver un ejemplo de cuaderno que implementa este ejemplo, consulte "A/B Probar modelos de aprendizaje automático en producción
Paso 1: Crear e implementar modelos
Primero, definimos dónde se encuentran los modelos en Amazon S3. Estas ubicaciones se utilizan al implementar los modelos en los siguientes pasos:
model_url = f"s3://{path_to_model_1}" model_url2 = f"s3://{path_to_model_2}"
A continuación, creamos los objetos del modelo con la imagen y los datos del modelo. Estos objetos del modelo se utilizan para implementar variantes de producción en un punto de enlace. Los modelos se desarrollan mediante el entrenamiento de modelos ML en diferentes conjuntos de datos, diferentes algoritmos o marcos ML y diferentes hiperparámetros:
from sagemaker.amazon.amazon_estimator import get_image_uri model_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" model_name2 = f"DEMO-xgb-churn-pred2-{datetime.now():%Y-%m-%d-%H-%M-%S}" image_uri = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-1') image_uri2 = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-2') sm_session.create_model( name=model_name, role=role, container_defs={ 'Image': image_uri, 'ModelDataUrl': model_url } ) sm_session.create_model( name=model_name2, role=role, container_defs={ 'Image': image_uri2, 'ModelDataUrl': model_url2 } )
Ahora creamos dos variantes de producción, cada una con sus propios requisitos de modelo y recursos diferentes (tipo de instancia y recuentos). De este modo, es posible probar modelos en diferentes tipos de instancia.
Definimos un peso inicial de 1 para ambas variantes. Esto significa que el 50 % de las solicitudes van a la Variant1 y el 50 % restante a la Variant2. La suma de pesos de ambas variantes es 2 y cada variante tiene una asignación de peso de 1. Esto significa que cada variante recibe 1/2, o sea, el 50% del tráfico total.
from sagemaker.session import production_variant variant1 = production_variant( model_name=model_name, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant1', initial_weight=1, ) variant2 = production_variant( model_name=model_name2, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant2', initial_weight=1, )
Por fin, estamos preparados para implementar estas variantes de producción en un terminal de SageMaker IA.
endpoint_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" print(f"EndpointName={endpoint_name}") sm_session.endpoint_from_production_variants( name=endpoint_name, production_variants=[variant1, variant2] )
Paso 2: Invocar los modelos implementados
Ahora enviamos las solicitudes a este punto de conexión para obtener inferencias en tiempo real. Utilizamos tanto la distribución de tráfico como el direccionamiento directo.
En primer lugar, utilizamos la distribución de tráfico que configuramos en el paso anterior. Cada respuesta de inferencia contiene el nombre de la variante de producción que procesa la solicitud, por lo que podemos ver que el tráfico a las dos variantes de producción es aproximadamente igual.
# get a subset of test data for a quick test !tail -120 test_data/test-dataset-input-cols.csv > test_data/test_sample_tail_input_cols.csv print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload ) time.sleep(0.5) print("Done!")
SageMaker La IA emite métricas como Latency y Invocations para cada variante en Amazon CloudWatch. Para ver una lista completa de las métricas que emite la SageMaker IA, consulta. Métricas de Amazon SageMaker AI en Amazon CloudWatch Hagamos una consulta CloudWatch para obtener el número de invocaciones por variante para mostrar cómo se dividen las invocaciones entre las variantes de forma predeterminada:
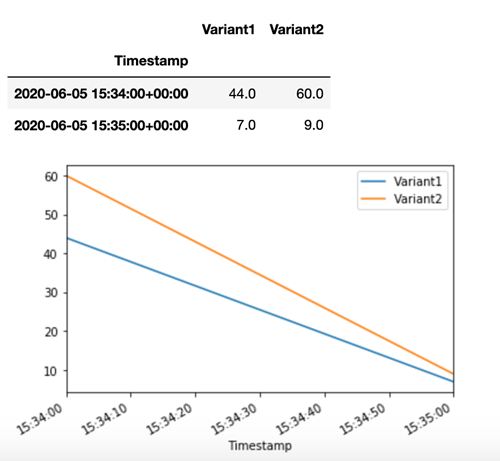
Ahora vamos a invocar una versión específica del modelo indicando Variant1 como TargetVariant en la llamada a invoke_endpoint.
print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, TargetVariant="Variant1" ) time.sleep(0.5)
Para confirmar que todas las nuevas invocaciones fueron procesadas porVariant1, podemos consultar CloudWatch el número de invocaciones por variante. Vemos que en las invocaciones más recientes (última marca de tiempo), todas las solicitudes fueron procesadas por la Variant1, como habíamos especificado. No hubo invocaciones para la Variant2.
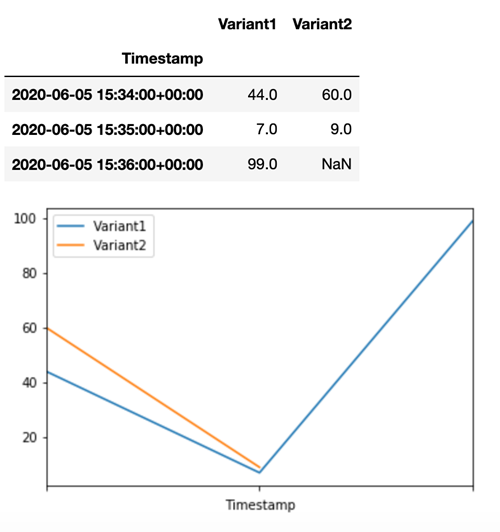
Paso 3: Evaluar el rendimiento del modelo
Para ver qué versión del modelo funciona mejor, evaluemos la precisión, la recuperación, la puntuación de F1 y el funcionamiento del receptor por charactersistic/Area debajo de la curva para cada variante. En primer lugar, veamos estas métricas para la Variant1:
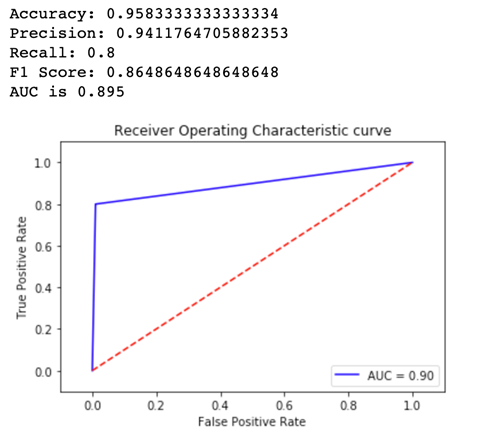
Ahora veamos las métricas de la Variant2:
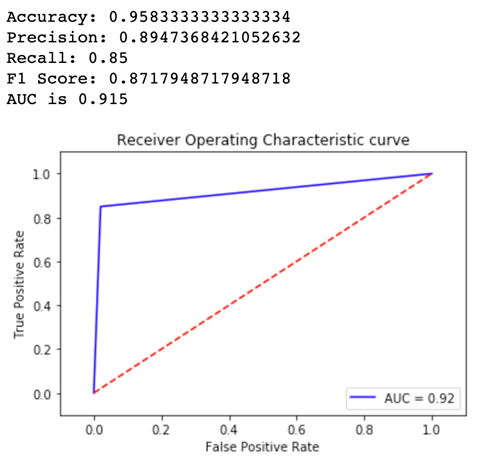
En la mayoría de las métricas definidas, funciona mejor la Variant2, por lo que esta es la que usaremos en producción.
Paso 4: Aumentar el tráfico al mejor modelo
Ahora que hemos determinado que la Variant2 funciona mejor que la Variant1, dirigimos más tráfico a esta variante. Podemos seguir utilizándola para TargetVariant invocar una variante de modelo específica, pero un enfoque más sencillo consiste en actualizar los pesos asignados a cada variante mediante una llamada UpdateEndpointWeightsAndCapacities. Esto cambia la distribución del tráfico a las variantes de producción sin necesidad de actualizaciones en el punto de conexión. Recuerda que en la sección de configuración establecemos los pesos de las variantes para dividir el tráfico 50/50. Las CloudWatch métricas del total de invocaciones de cada variante que aparecen a continuación nos muestran los patrones de invocación de cada variante:
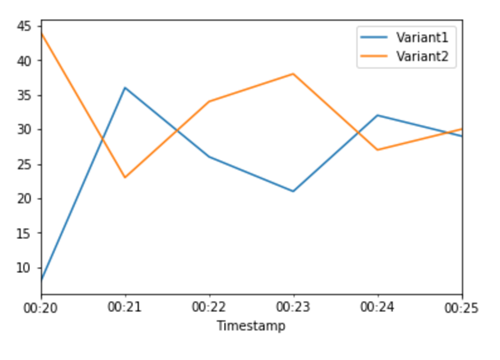
Ahora trasladamos el 75% del tráfico a Variant2 mediante la asignación de nuevos pesos a cada variante utilizando. UpdateEndpointWeightsAndCapacities SageMaker La IA ahora envía el 75% de las solicitudes de inferencia Variant2 y el 25% restante a. Variant1
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 25, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 75, "VariantName": variant2["VariantName"] } ] )
Las CloudWatch métricas del total de invocaciones de cada variante nos muestran un número mayor de invocaciones que deVariant2: Variant1
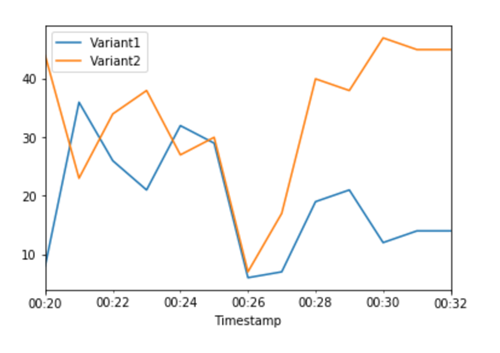
Podemos seguir monitoreando las métricas y, cuando estemos satisfechos con el rendimiento de una variante, dirigir el 100 % del tráfico a esa variante. Utilizamos UpdateEndpointWeightsAndCapacities para actualizar las asignaciones de tráfico para las variantes. El peso para Variant1 está establecido en 0 y el peso para Variant2 está establecido en 1. SageMaker La IA ahora envía el 100% de todas las solicitudes de inferencia aVariant2.
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 0, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 1, "VariantName": variant2["VariantName"] } ] )
Las CloudWatch métricas del total de invocaciones de cada variante muestran que todas las solicitudes de inferencia están siendo procesadas por Variant2 y no hay ninguna solicitud de inferencia procesada por. Variant1
Ahora puede actualizar de forma segura el punto de enlace y eliminar la Variant1 del punto de conexión. También puede continuar probando nuevos modelos en producción y agregar nuevas variantes al punto de conexión según los pasos 2 a 4.
