Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
El mejor origen de datos para su trabajo de entrenamiento depende de las características de la carga de trabajo, como el tamaño del conjunto de datos, el formato del archivo, el tamaño medio de los archivos, la duración del entrenamiento, un patrón de lectura secuencial o aleatorio del cargador de datos y la rapidez con la que el modelo puede consumir los datos de entrenamiento. En las siguientes prácticas recomendadas se proporcionan pautas para comenzar con el modo de entrada y el almacenamiento de datos más adecuados para el caso de uso.
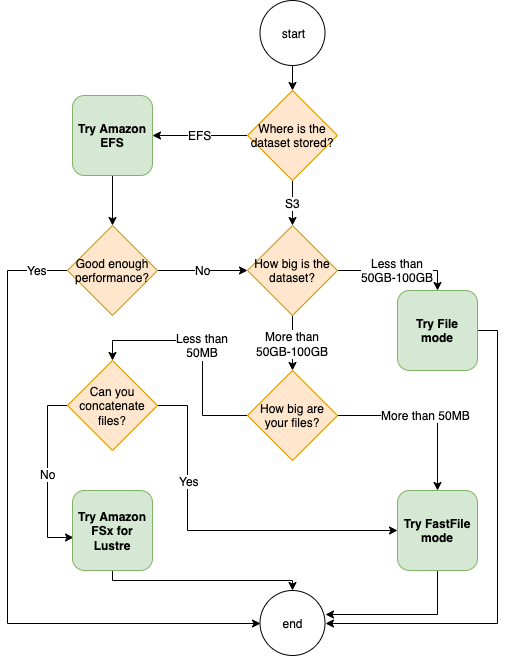
Cuándo usar Amazon EFS
Si su conjunto de datos está almacenado en Amazon Elastic File System, es posible que tenga una aplicación de preprocesamiento o anotaciones que utilice Amazon EFS para el almacenamiento. Puede ejecutar un trabajo de entrenamiento configurado con un canal de datos que apunte al sistema de archivos Amazon EFS. Para obtener más información, consulte Acelere la formación en Amazon SageMaker AI con los sistemas de archivos Amazon FSx for Lustre y Amazon EFS
Utilice el modo de archivo para conjuntos de datos pequeños
Si el conjunto de datos está almacenado en Amazon Simple Storage Service y su volumen total es relativamente pequeño (por ejemplo, menos de 50 a 100 GB), intente utilizar el modo de archivo. La sobrecarga que supone descargar un conjunto de datos de 50 GB puede variar en función del número total de archivos. Por ejemplo, tarda unos 5 minutos si un conjunto de datos está dividido en fragmentos de 100 MB. Que esta sobrecarga inicial sea aceptable depende principalmente de la duración total del trabajo de entrenamiento, ya que una fase de entrenamiento más larga implica una fase de descarga proporcionalmente más pequeña.
Serialización de varios archivos pequeños
Si el tamaño del conjunto de datos es pequeño (menos de 50 a 100 GB), pero está compuesto por muchos archivos pequeños (menos de 50 MB por archivo), la sobrecarga de descarga del modo de archivo aumenta, ya que cada archivo debe descargarse individualmente desde Amazon Simple Storage Service al volumen de la instancia de entrenamiento. Para reducir esta sobrecarga y el tiempo de recorrido de los datos en general, considere la posibilidad de serializar grupos de archivos tan pequeños en menos contenedores de archivos más grandes (como 150 MB por archivo) mediante formatos de archivo, como TFRecord
Cuándo usar el modo de archivo rápido
Para conjuntos de datos más grandes con archivos más grandes (más de 50 MB por archivo), la primera opción es probar el modo de archivos rápido, que es más sencillo de usar que FSx con Lustre porque no requiere crear un sistema de archivos ni conectarse a una VPC. El modo de archivos rápido es ideal para contenedores de archivos grandes (más de 150 MB) y también puede funcionar bien con archivos de más de 50 MB. Como el modo de archivo rápido proporciona una interfaz POSIX, admite lecturas aleatorias (lectura de rangos de bytes no secuenciales). Sin embargo, este no es el caso de uso ideal y su rendimiento podría ser inferior al de las lecturas secuenciales. Sin embargo, si tiene un modelo de ML relativamente grande y con un uso intensivo de recursos computacionales, es posible que el modo de archivos rápido pueda saturar el ancho de banda efectivo del proceso de entrenamiento y no provocar un cuello de botella de E/S. Tendrá que experimentar y comprobar. Para cambiar del modo de archivo al modo de archivo rápido (y viceversa), basta con añadir (o eliminar) el input_mode='FastFile' parámetro mientras se define el canal de entrada mediante el SDK de SageMaker Python:
sagemaker.inputs.TrainingInput(S3_INPUT_FOLDER, input_mode = 'FastFile')Cuándo usar Amazon FSx for Lustre
Si su conjunto de datos es demasiado grande para el modo archivo, tiene muchos archivos pequeños que no puede serializar fácilmente o utiliza un patrón de acceso de lectura aleatorio, FSx considerar Lustre es una buena opción. Su sistema de archivos se escala a cientos de gigabytes por segundo (GB/s) de rendimiento y millones de IOPS, lo que resulta ideal cuando se tienen muchos archivos pequeños. Sin embargo, ten en cuenta que es posible que se produzca un problema de arranque en frío debido a la carga diferida y a la sobrecarga que supone configurar e inicializar el sistema de archivos FSx de Lustre.
sugerencia
Para obtener más información, consulta Elige la mejor fuente de datos para tu trabajo de SageMaker formación en Amazon
