Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Entrenamiento de modelos
La etapa de entrenamiento del ciclo de vida completo de machine learning (ML) abarca desde el acceso al conjunto de datos de entrenamiento hasta la generación de un modelo final y la selección del modelo con mejor rendimiento para su implementación. En las siguientes secciones se ofrece una descripción general de las funciones y los recursos de SageMaker formación disponibles, con información técnica detallada sobre cada uno de ellos.
La arquitectura básica de SageMaker Training
Si es la primera vez que utilizas la SageMaker IA y quieres encontrar una solución rápida de aprendizaje automático para entrenar un modelo en tu conjunto de datos, considera la posibilidad de utilizar una solución sin código o con poco código, como SageMaker Canvas, JumpStarten SageMaker Studio Classic, o SageMaker Autopilot.
Para experiencias de programación de nivel intermedio, considere la posibilidad de utilizar una libreta SageMaker Studio Classic o Notebook InstancesSageMaker . Para empezar, sigue las instrucciones de la guía Capacitación de un modelo de introducción a la SageMaker IA. Lo recomendamos para los casos de uso en los que cree su propio modelo y script de entrenamiento utilizando un marco de ML.
El núcleo de los trabajos de SageMaker IA es la contenedorización de las cargas de trabajo de aprendizaje automático y la capacidad de gestionar los recursos informáticos. La plataforma de SageMaker formación se encarga del trabajo pesado asociado a la configuración y la gestión de la infraestructura para las cargas de trabajo de formación en aprendizaje automático. Con SageMaker Training, puede centrarse en desarrollar, capacitar y ajustar su modelo.
El siguiente diagrama de arquitectura muestra cómo la SageMaker IA gestiona los trabajos de formación en aprendizaje automático y aprovisiona las instancias de Amazon EC2 en nombre de los usuarios de SageMaker IA. Como usuario de SageMaker IA, puede traer su propio conjunto de datos de entrenamiento y guardarlo en Amazon S3. Puede elegir un modelo de aprendizaje automático entre los algoritmos integrados de SageMaker IA disponibles, o bien utilizar su propio guion de entrenamiento con un modelo creado con los marcos de aprendizaje automático más populares.
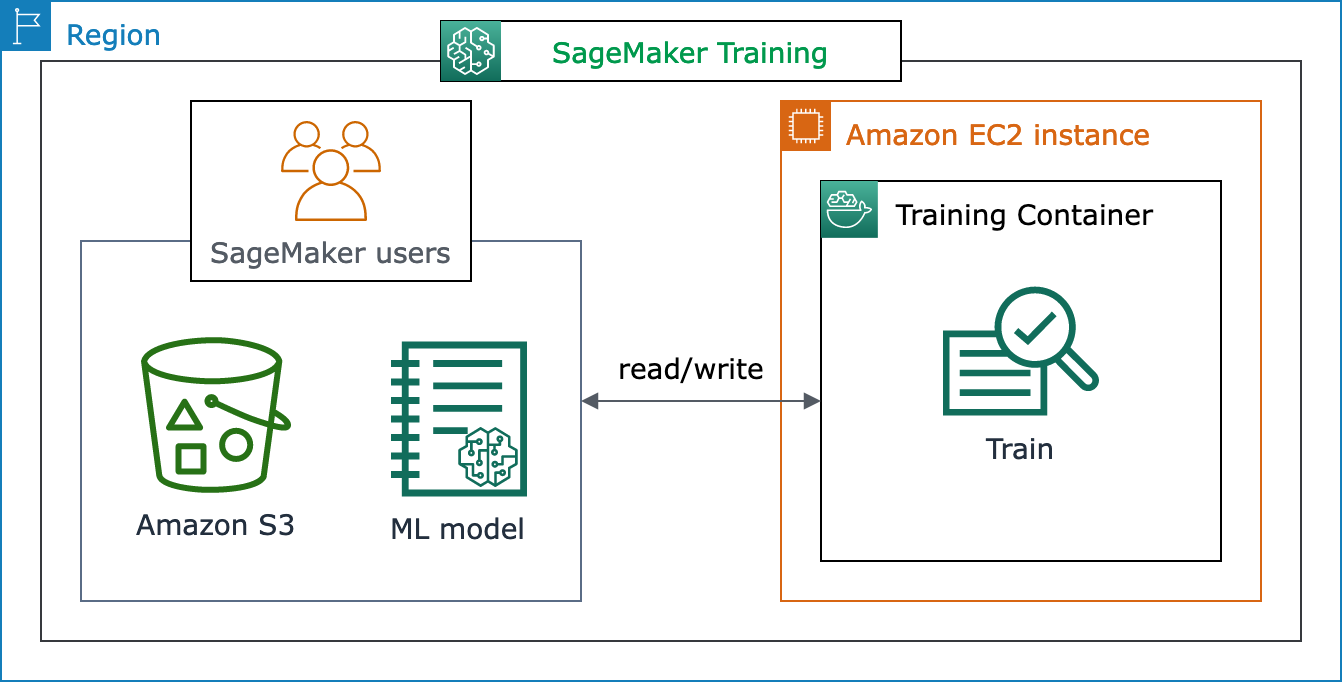
Vista completa del flujo de trabajo y las características de la SageMaker formación
El proceso completo de entrenamiento en ML incluye tareas que van más allá de la ingesta de datos para obtener modelos de ML, el entrenamiento de modelos en instancias de procesamiento y la obtención de artefactos y resultados de los modelos. Debe evaluar todas las fases de antes, durante y después del entrenamiento para asegurarse de que su modelo está bien entrenado para cumplir la precisión deseada para sus objetivos.
El siguiente diagrama de flujo muestra una descripción general de alto nivel de sus acciones (en recuadros azules) y las funciones de SageMaker capacitación disponibles (en recuadros de color azul claro) a lo largo de la fase de capacitación del ciclo de vida del aprendizaje automático.
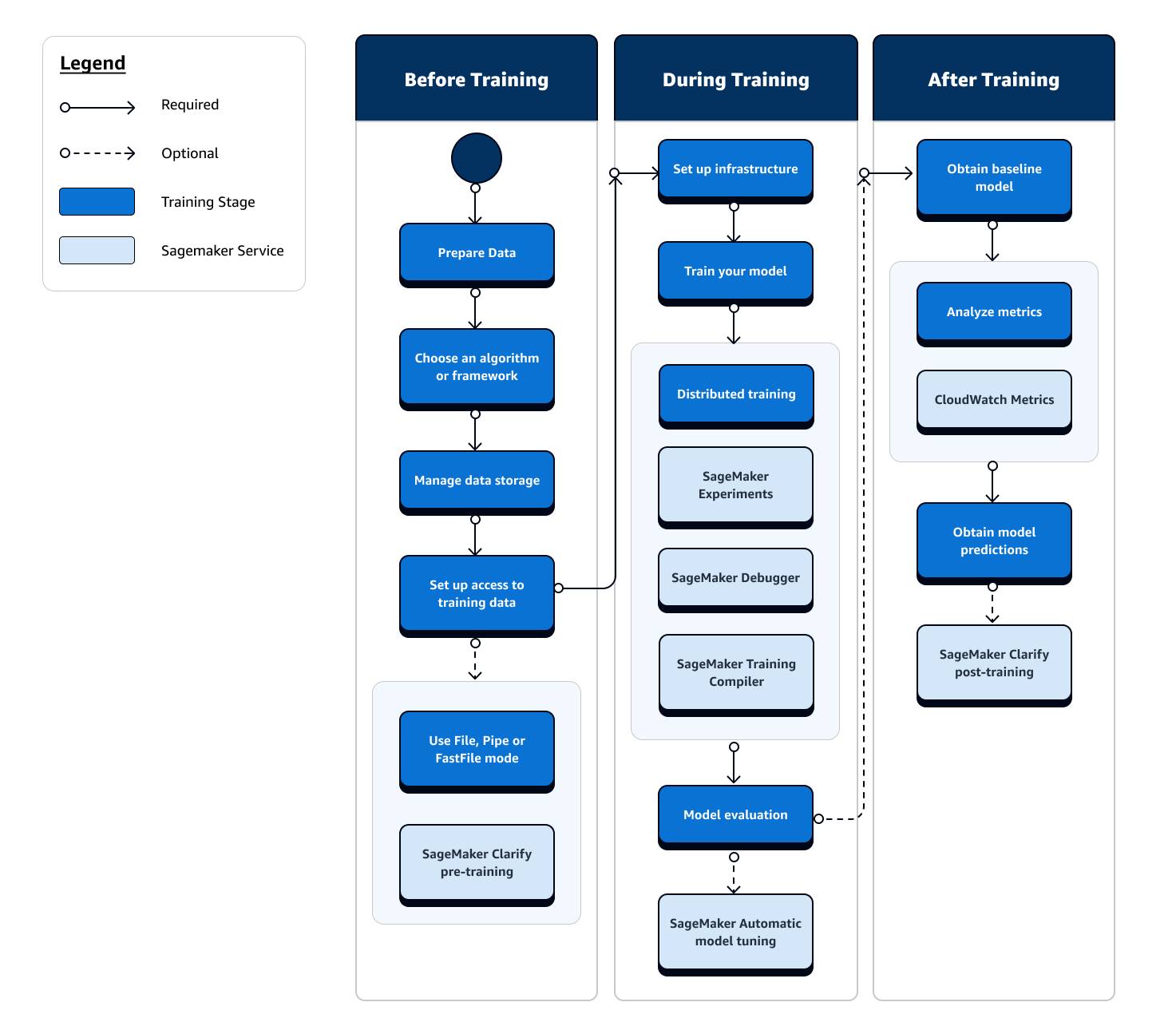
En las siguientes secciones, se explica cada una de las fases del entrenamiento, descritas en el diagrama de flujo anterior, así como las útiles funciones que ofrece la SageMaker IA a lo largo de las tres subetapas de la formación en aprendizaje automático.
Antes del entrenamiento
Hay varios escenarios de configuración de los recursos y el acceso a los datos que hay que tener en cuenta antes del entrenamiento. Consulte el siguiente diagrama y los detalles de cada etapa previa al entrenamiento para hacerse una idea de las decisiones que debe tomar.
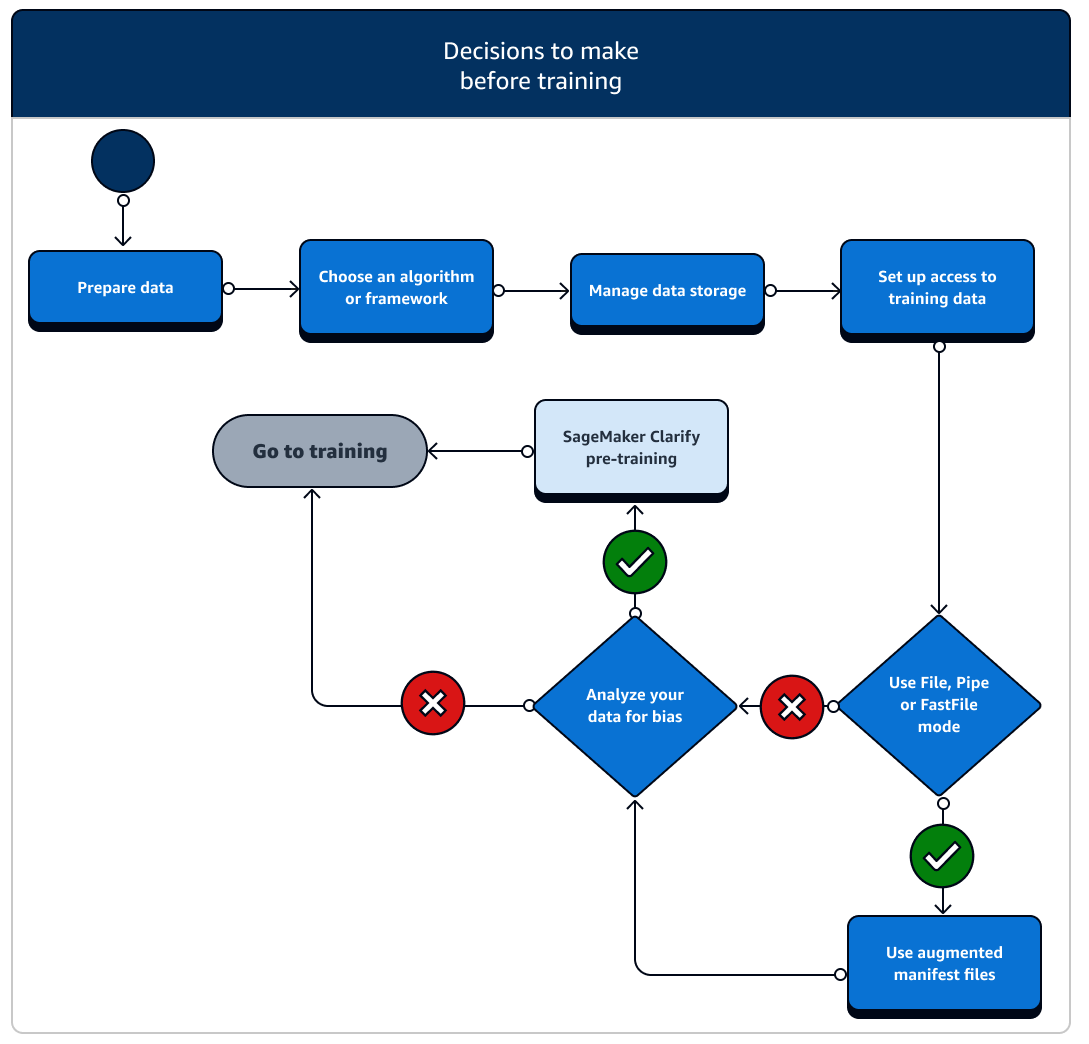
-
Prepare los datos: antes del entrenamiento, debe haber terminado de limpiar los datos y de diseñar las características durante la fase de preparación de los datos. SageMaker La IA cuenta con varias herramientas de etiquetado e ingeniería de funciones que le ayudarán. Consulte Etiquetar datos, Preparar y analizar conjuntos de datos, Procesar datos y Crear, almacenar y compartir funciones para obtener más información.
-
Elija un algoritmo o marco: según el grado de personalización que necesite, existen diferentes opciones de algoritmos y marcos.
-
Si prefieres implementar un algoritmo prediseñado con poco código, usa uno de los algoritmos integrados que ofrece la IA. SageMaker Para obtener más información, consulte Seleccionar un algoritmo.
-
Si necesitas más flexibilidad para personalizar tu modelo, ejecuta tu guion de entrenamiento con los marcos y conjuntos de herramientas que prefieras en IA. SageMaker Para obtener más información, consulte Marcos y conjuntos de herramientas de ML.
-
Para ampliar las imágenes de Docker de SageMaker IA prediseñadas como imagen base de su propio contenedor, consulte Usar imágenes de Docker de Pre-built SageMaker IA.
-
Para incorporar tu contenedor Docker personalizado a la SageMaker IA, consulta Cómo adaptar tu propio contenedor Docker para que funcione con la IA. SageMaker Debe instalar el kit de herramientas sagemaker-training
en su contenedor.
-
-
Gestione el almacenamiento de datos: comprenda el mapeo entre el almacenamiento de datos (como Amazon S3, Amazon EFS o Amazon FSx) y el contenedor de entrenamiento que se ejecuta en la instancia de procesamiento de Amazon EC2. SageMaker La IA ayuda a mapear las rutas de almacenamiento y las rutas locales en el contenedor de entrenamiento. También puede especificarlos manualmente. Una vez realizado el mapeo, considere la posibilidad de utilizar uno de los modos de transmisión de datos: archivo, canalización y FastFile modo. Para obtener información sobre cómo la SageMaker IA mapea las rutas de almacenamiento, consulte Capacitación sobre las carpetas de almacenamiento.
-
Configure el acceso a los datos de entrenamiento: utilice el dominio Amazon SageMaker AI, un perfil de usuario de dominio, IAM, Amazon VPC AWS KMS y cumpla con los requisitos de las organizaciones más sensibles a la seguridad.
-
Para la administración de la cuenta, consulta el dominio Amazon SageMaker AI.
-
Para obtener una referencia completa sobre las políticas y la seguridad de IAM, consulte Seguridad en Amazon SageMaker AI.
-
-
Transmita sus datos de entrada: la SageMaker IA proporciona tres modos de entrada de datos: File, Pipe y FastFile. El modo de entrada predeterminado es el modo File, que carga todo el conjunto de datos durante la inicialización del trabajo de entrenamiento. Para obtener información sobre las prácticas recomendadas generales para transmitir datos desde su almacenamiento de datos al contenedor de entrenamiento, consulte Acceder a datos de entrenamiento.
En el caso del modo Pipe, también puede considerar la posibilidad de utilizar un archivo de manifiesto aumentado para transmitir sus datos directamente desde Amazon Simple Storage Service (Amazon S3) y formar a su modelo. El uso del modo pipe reduce el espacio en disco, ya que Amazon Elastic Block Store solo necesita almacenar los artefactos finales del modelo, en lugar de almacenar todo el conjunto de datos de entrenamiento. Para obtener más información consulte Proporcionar metadatos del conjunto de datos a trabajos de entrenamiento con un archivo de manifiesto aumentado.
-
Analice sus datos para detectar sesgos: antes del entrenamiento, puede analizar su conjunto de datos y su modelo para detectar sesgos en relación con un grupo desfavorecido, de modo que pueda comprobar que su modelo aprende un conjunto de datos imparcial con SageMaker Clarify.
-
Elija qué SageMaker SDK utilizar: Hay dos formas de lanzar un trabajo de formación en SageMaker IA: utilizando el SDK Python para SageMaker IA de alto nivel o utilizando SageMaker las API de bajo nivel para el SDK para Python (Boto3) o el. AWS CLI El SDK de SageMaker Python abstrae la SageMaker API de bajo nivel para proporcionar herramientas prácticas. Como se mencionó anteriormenteLa arquitectura básica de SageMaker Training, también puede optar por opciones sin código o con un código mínimo utilizando SageMaker Canvas, JumpStart en SageMaker Studio Classic, o AI Autopilot. SageMaker
Durante el entrenamiento
Durante el entrenamiento, es necesario mejorar continuamente la estabilidad, la velocidad y la eficiencia de la misma, a la vez que se amplían los recursos de cómputo, se optimizan los costos y, lo que es más importante, el rendimiento del modelo. Sigue leyendo para obtener más información sobre las etapas de entrenamiento durante el entrenamiento y las funciones relevantes del entrenamiento. SageMaker
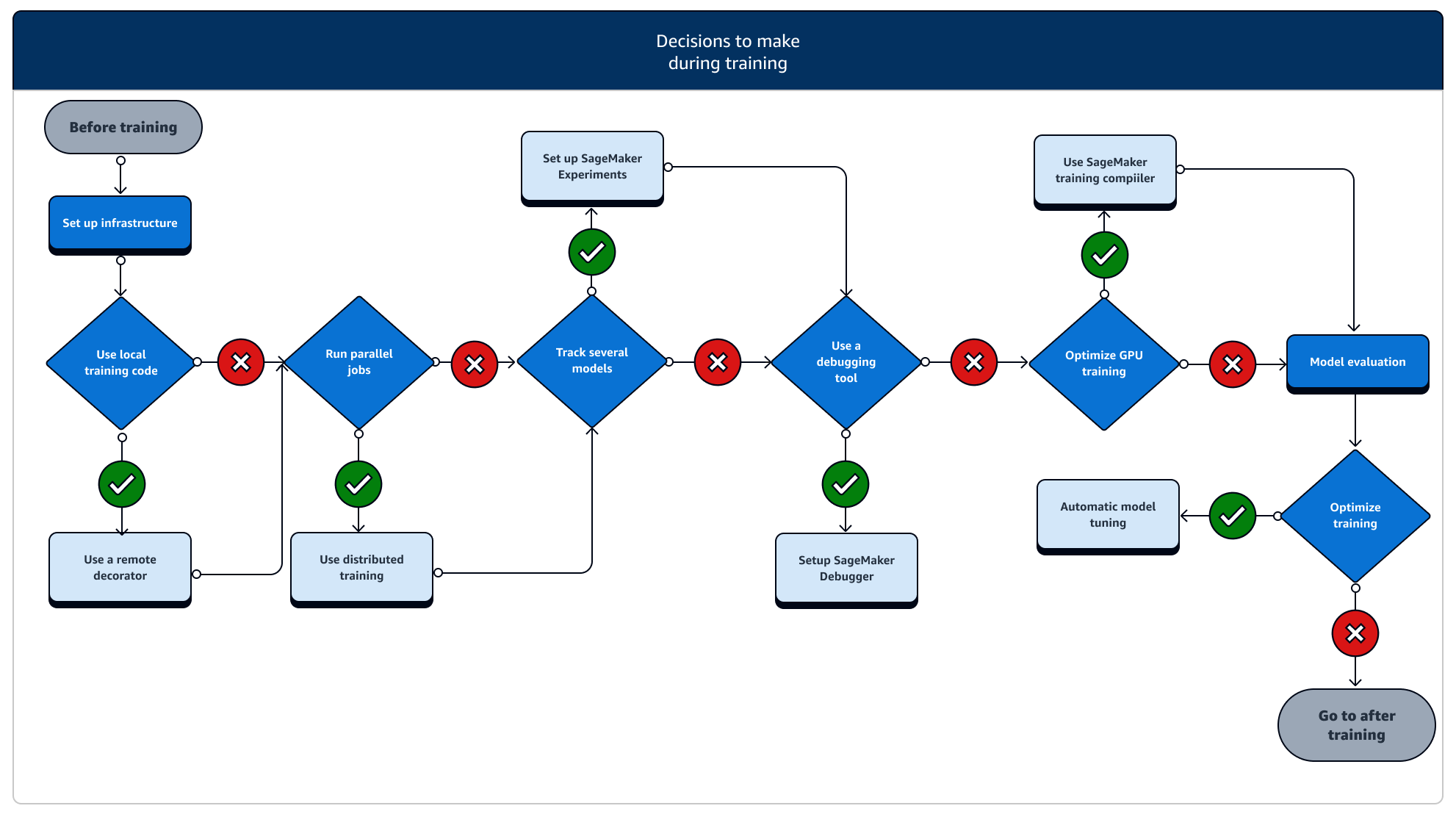
-
Configure la infraestructura: elija el tipo de instancia y las herramientas de administración de infraestructura adecuados para su caso de uso. Puede empezar desde una instancia pequeña y ampliarla en función de su carga de trabajo. Para formar un modelo en un conjunto de datos tabular, comience con la instancia de CPU más pequeña de las familias de instancias C4 o C5. Para formar un modelo grande para la visión artificial o el procesamiento del lenguaje natural, comience con la instancia de GPU más pequeña de las familias de instancias P2, P3, G4dn o G5. También puedes combinar distintos tipos de instancias en un clúster o mantener las instancias en grupos cálidos con las siguientes herramientas de administración de instancias que ofrece la SageMaker IA. También puede utilizar la caché persistente para reducir la latencia y el tiempo facturable en los trabajos de entrenamiento iterativos, en lugar de reducir la latencia únicamente en los grupos cálidos. Para obtener más información, consulte los temas siguientes.
Debe tener una cuota suficiente para realizar un trabajo de entrenamiento. Si realiza su trabajo de entrenamiento en una instancia en el que su cuota es insuficiente, recibirá un error
ResourceLimitExceeded. Para comprobar las cuotas actualmente disponibles en su cuenta, utilice la consola Service Quotas. Para obtener más información sobre cómo solicitar un aumento de cuotas, consulte Cuotas y regiones compatibles. Además, para encontrar información sobre los precios y los tipos de instancias disponibles en función de Regiones de AWS ellos, consulta las tablas de la página de SageMaker precios de Amazon . -
Ejecute un trabajo de formación desde un código local: puede anotar su código local con un decorador remoto para ejecutar el código como un trabajo de SageMaker formación desde Amazon SageMaker Studio Classic, un SageMaker bloc de notas de Amazon o desde su entorno de desarrollo integrado local. Para obtener más información, consulte Ejecuta tu código local como un trabajo SageMaker de formación.
-
Realice un seguimiento de los trabajos de formación: supervise y realice un seguimiento de sus trabajos de formación mediante SageMaker Experiments, SageMaker Debugger o Amazon CloudWatch. Puedes ver el rendimiento del modelo en términos de precisión y convergencia, y realizar un análisis comparativo de las métricas entre varios trabajos de formación mediante experimentos de SageMaker IA. Puede ver la tasa de utilización de los recursos informáticos utilizando las herramientas de creación de perfiles de SageMaker Debugger o Amazon. CloudWatch Para obtener más información, consulte los temas siguientes.
Además, para las tareas de aprendizaje profundo, utilice las herramientas de SageMaker depuración del modelo Amazon Debugger y las reglas integradas para identificar problemas más complejos en los procesos de convergencia de modelos y actualización de peso.
-
Entrenamiento distribuido: si su trabajo de entrenamiento va a pasar a una fase estable y no se interrumpe debido a una mala configuración de la infraestructura de entrenamiento o a problemas de memoria insuficiente, puede que desee buscar más opciones para escalar su trabajo y ejecutarlo durante un período prolongado, durante días e incluso meses. Cuando esté listo para escalar, considere la posibilidad de impartir una formación distribuida. SageMaker La IA ofrece varias opciones para la computación distribuida, desde cargas de trabajo ligeras de aprendizaje automático hasta cargas de trabajo pesadas de aprendizaje profundo.
Para las tareas de aprendizaje profundo que impliquen el entrenamiento de modelos muy grandes en conjuntos de datos muy grandes, considere la posibilidad de utilizar una de las estrategias de entrenamiento distribuido de la SageMaker IA para ampliar la escala y lograr el paralelismo de datos, el paralelismo de modelos o una combinación de ambos. También puedes usar SageMaker Training Compiler para compilar y optimizar gráficos de modelos en instancias de GPU. Estas funciones de SageMaker IA son compatibles con marcos de aprendizaje profundo como PyTorch TensorFlow, y Hugging Face Transformers.
-
Ajuste de hiperparámetros del modelo: ajuste los hiperparámetros de su modelo mediante el ajuste automático del modelo con IA. SageMaker SageMaker La IA proporciona métodos de ajuste de hiperparámetros, como la búsqueda en cuadrículas y la búsqueda bayesiana, y lanza trabajos de ajuste de hiperparámetros paralelos con una funcionalidad de parada temprana para trabajos de ajuste de hiperparámetros que no mejoran.
-
Control y ahorro de costos con instancias de Spot: si el tiempo de entrenamiento no es un problema importante, podría considerar la posibilidad de optimizar los costos de entrenamiento de modelos con instancias de Spot administradas. Tenga en cuenta que debe activar los puntos de control para que el entrenamiento de Spot siga recuperándose de las pausas intermitentes de los trabajos debidas a la sustitución de instancias de Spot. También puede utilizar la función de puntos de control para hacer copias de seguridad de sus modelos en caso de que termine inesperadamente su trabajo de entrenamiento. Para obtener más información, consulte los temas siguientes.
Después del entrenamiento
Tras el entrenamiento, se obtiene un artefacto del modelo final para utilizarlo en la implementación y la inferencia del modelo. Hay acciones adicionales en la fase posterior al entrenamiento, como se muestra en el siguiente diagrama.
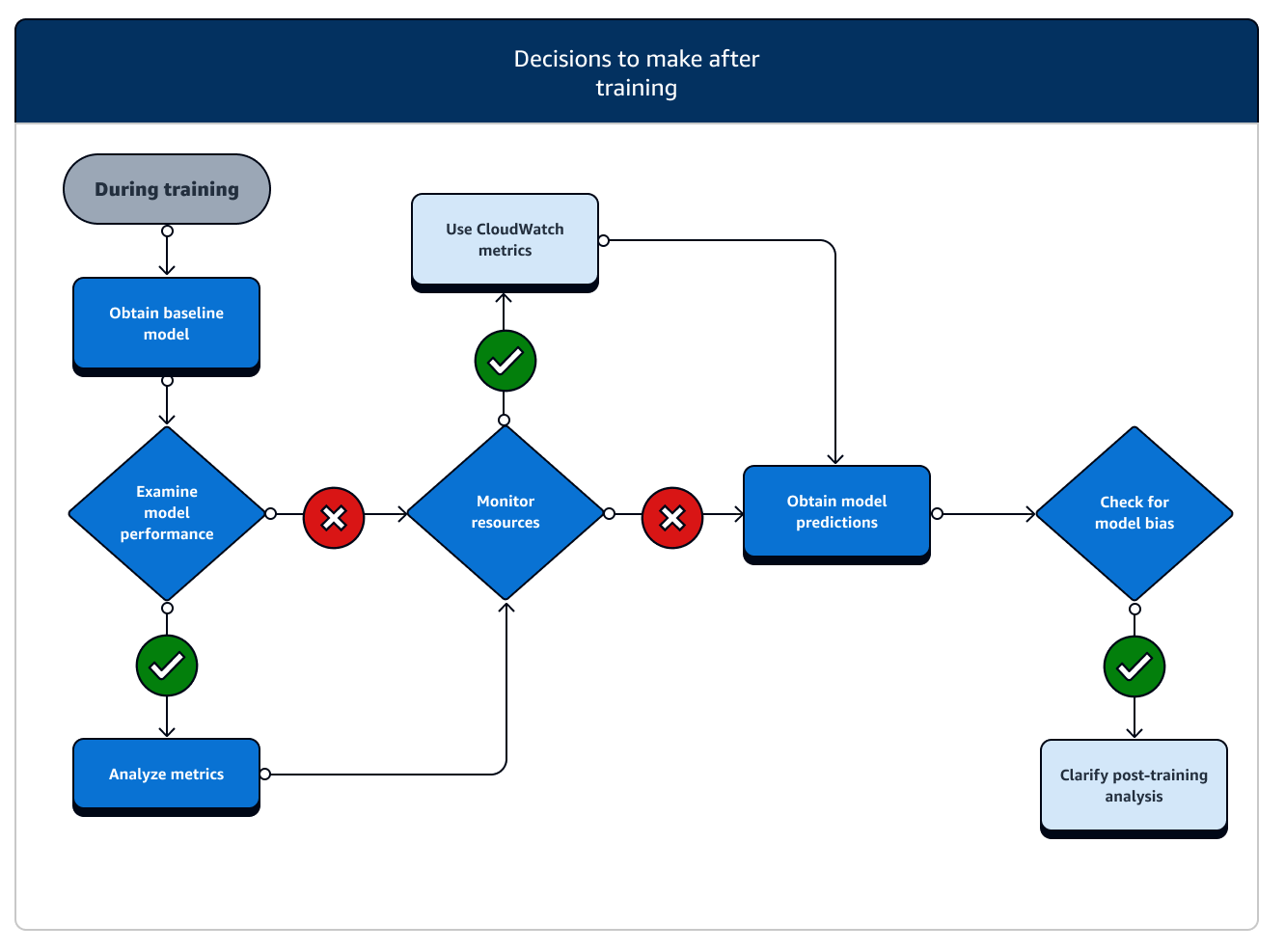
-
Obtenga el modelo de referencia: una vez que tenga el artefacto del modelo, puede configurarlo como modelo de referencia. Considere las siguientes acciones posteriores al entrenamiento y el uso de las funciones de SageMaker IA antes de pasar del despliegue del modelo a la producción.
-
Examine el rendimiento del modelo y compruebe si hay sesgos: utilice Amazon CloudWatch Metrics y SageMaker Clarify para detectar el sesgo posterior al entrenamiento para detectar cualquier sesgo en los datos entrantes y modelar a lo largo del tiempo con respecto a la línea base. Debe evaluar sus nuevos datos y modelar las predicciones comparándolos con los nuevos datos de forma regular o en tiempo real. Con estas funciones, puede recibir alertas sobre cualquier cambio o anomalía aguda, así como sobre cambios o desviaciones graduales en los datos y el modelo.
-
También puede utilizar la funcionalidad de entrenamiento incremental de la SageMaker IA para cargar y actualizar su modelo (o ajustarlo) con un conjunto de datos ampliado.
-
Puedes registrar el entrenamiento con modelos como parte de tu cartera de SageMaker IA o como parte de otras funciones de flujo de trabajo que ofrece la SageMaker IA para organizar todo el ciclo de vida del aprendizaje automático.
