Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Capacitación de un modelo
En este paso se elige un algoritmo de entrenamiento y se ejecuta un trabajo de entrenamiento para el modelo. El SDK de Amazon SageMaker Python
Elección del algoritmo de entrenamiento
Para elegir el algoritmo correcto para su conjunto de datos, normalmente necesitará evaluar diferentes modelos para encontrar los más adecuados para sus datos. Para simplificar, el algoritmo Algoritmo XGBoost con Amazon AI SageMaker integrado de SageMaker IA se utiliza a lo largo de este tutorial sin la evaluación previa de los modelos.
sugerencia
Si desea que la SageMaker IA encuentre un modelo adecuado para su conjunto de datos tabular, utilice Amazon SageMaker Autopilot, que automatiza una solución de aprendizaje automático. Para obtener más información, consulte SageMaker Piloto automático.
Creación y ejecución de un trabajo de entrenamiento
Una vez que haya decidido qué modelo usar, comience a construir un estimador de SageMaker IA para el entrenamiento. Este tutorial utiliza el algoritmo integrado XGBoost para el estimador genérico de SageMaker IA.
Para ejecutar un trabajo de entrenamiento de modelo
-
Importe el SDK de Amazon SageMaker Python
y comience por recuperar la información básica de su sesión de SageMaker IA actual. import sagemaker region = sagemaker.Session().boto_region_name print("AWS Region: {}".format(region)) role = sagemaker.get_execution_role() print("RoleArn: {}".format(role))Esto devuelve la siguiente información:
-
region— La AWS región actual en la que se ejecuta la instancia del bloc de notas de SageMaker IA. -
role: es el rol de IAM utilizado por la instancia del cuaderno.
nota
Compruebe la versión del SDK de SageMaker Python ejecutando
sagemaker.__version__. Este tutorial se basa ensagemaker>=2.20. Si el SDK está desactualizado, instale la versión más reciente ejecutando el comando siguiente:! pip install -qU sagemakerSi ejecutas esta instalación en las instancias de SageMaker Studio o Notebook que ya tienes, tendrás que actualizar manualmente el núcleo para terminar de aplicar la actualización de la versión.
-
-
Cree un estimador de XGBoost con la clase
sagemaker.estimator.Estimator. En el siguiente código de ejemplo, el estimador de XGBoost de llamaxgb_model.from sagemaker.debugger import Rule, ProfilerRule, rule_configs from sagemaker.session import TrainingInput s3_output_location='s3://{}/{}/{}'.format(bucket, prefix, 'xgboost_model') container=sagemaker.image_uris.retrieve("xgboost", region, "1.2-1") print(container) xgb_model=sagemaker.estimator.Estimator( image_uri=container, role=role, instance_count=1, instance_type='ml.m4.xlarge', volume_size=5, output_path=s3_output_location, sagemaker_session=sagemaker.Session(), rules=[ Rule.sagemaker(rule_configs.create_xgboost_report()), ProfilerRule.sagemaker(rule_configs.ProfilerReport()) ] )Para construir el estimador de SageMaker IA, especifique los siguientes parámetros:
-
image_uri: especifique el URI de la imagen del contenedor de entrenamiento. En este ejemplo, el URI del contenedor de entrenamiento SageMaker AI XGBoost se especifica mediante.sagemaker.image_uris.retrieve -
role— La función AWS Identity and Access Management (IAM) que la SageMaker IA utiliza para realizar tareas en su nombre (por ejemplo, leer los resultados de la formación, llamar a artefactos de modelos de Amazon S3 y escribir los resultados de la formación en Amazon S3). -
instance_countyinstance_type: el tipo y el número de instancias de computación de machine learning de Amazon EC2 que se deben usar para el entrenamiento de modelos. Para este ejercicio de entrenamiento, utilizará una sola instancia deml.m4.xlarge, que tiene 4 CPU, 16 GB de memoria, un almacenamiento en Amazon Elastic Block Store (Amazon EBS) y un alto rendimiento de red. Para obtener más información sobre los tipos de instancias, consulte Tipos de instancias de Amazon EC2. Para obtener más información sobre la facturación, consulta los SageMaker precios de Amazon . -
volume_size: el tamaño, en GB, del volumen de almacenamiento de EBS que se va a asociar a la instancia de entrenamiento. Debe ser lo suficientemente grande para almacenar datos de entrenamiento si utiliza el modoFile(el modoFilees el predeterminado). Si no especifica este parámetro, el valor predeterminado es de 30. -
output_path— El camino hacia el compartimento S3, donde la SageMaker IA almacena el artefacto del modelo y los resultados del entrenamiento. -
sagemaker_session— El objeto de sesión que gestiona las interacciones con las operaciones de la SageMaker API y otros AWS servicios que utiliza el trabajo de formación. -
rules— Especifique una lista de las reglas integradas del SageMaker Debugger. En este ejemplo, la reglacreate_xgboost_report()crea un informe de XGBoost que proporciona información sobre el progreso y los resultados del entrenamiento, y la reglaProfilerReport()crea un informe sobre la utilización de los recursos informáticos de EC2. Para obtener más información, consulte SageMaker Informe interactivo de Debugger para XGBoost.
sugerencia
Si desea realizar un entrenamiento distribuido de modelos de aprendizaje profundo de gran tamaño, como modelos de redes neuronales convolucionales (CNN) y modelos de procesamiento del lenguaje natural (NLP), utilice SageMaker AI Distributed para el paralelismo de datos o el paralelismo de modelos. Para obtener más información, consulte Capacitación distribuida en Amazon SageMaker AI.
-
-
Ajuste los valores de los hiperparámetros para el trabajo de entrenamiento de XGBoost llamando al método
set_hyperparametersdel estimador. Para obtener una lista completa de hiperparámetros de XGBoost, consulte Hiperparámetros de XGBoost.xgb_model.set_hyperparameters( max_depth = 5, eta = 0.2, gamma = 4, min_child_weight = 6, subsample = 0.7, objective = "binary:logistic", num_round = 1000 )sugerencia
También puede ajustar los hiperparámetros mediante la función de optimización de hiperparámetros de IA. SageMaker Para obtener más información, consulte Ajuste automático del modelo con IA SageMaker.
-
Utilice la clase
TrainingInputpara configurar un flujo de entrada de datos para el entrenamiento. El siguiente código de ejemplo muestra cómo configurar los objetosTrainingInputpara que usen los conjuntos de datos de entrenamiento y validación que cargó en Amazon S3 en la sección División de los datos en conjuntos de entrenamiento, validación y prueba..from sagemaker.session import TrainingInput train_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/train.csv"), content_type="csv" ) validation_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/validation.csv"), content_type="csv" ) -
Para iniciar el entrenamiento del modelo, llame al método
fitdel estimador con los conjuntos de datos de entrenamiento y validación. Al configurarwait=True, el métodofitmuestra los registros de progreso y espera hasta que el entrenamiento se complete.xgb_model.fit({"train": train_input, "validation": validation_input}, wait=True)Para obtener más información acerca del modelo de entrenamiento, consulte Entrena a un modelo con Amazon SageMaker. Este tutorial de un trabajo de entrenamiento puede llevar hasta 10 minutos.
Una vez finalizado el trabajo de formación, puede descargar un informe de formación de XGBoost y un informe de creación de perfiles generados por Debugger. SageMaker El informe de entrenamiento de XGBoost le ofrece información sobre el progreso y los resultados del entrenamiento, como la función de pérdida con respecto a la iteración, la importancia de las características, la matriz de confusión, las curvas de precisión y otros resultados estadísticos del entrenamiento. Por ejemplo, puede encontrar la siguiente curva de pérdidas en el informe de entrenamiento de XGBoost, lo que indica claramente que hay un problema de sobreajuste.
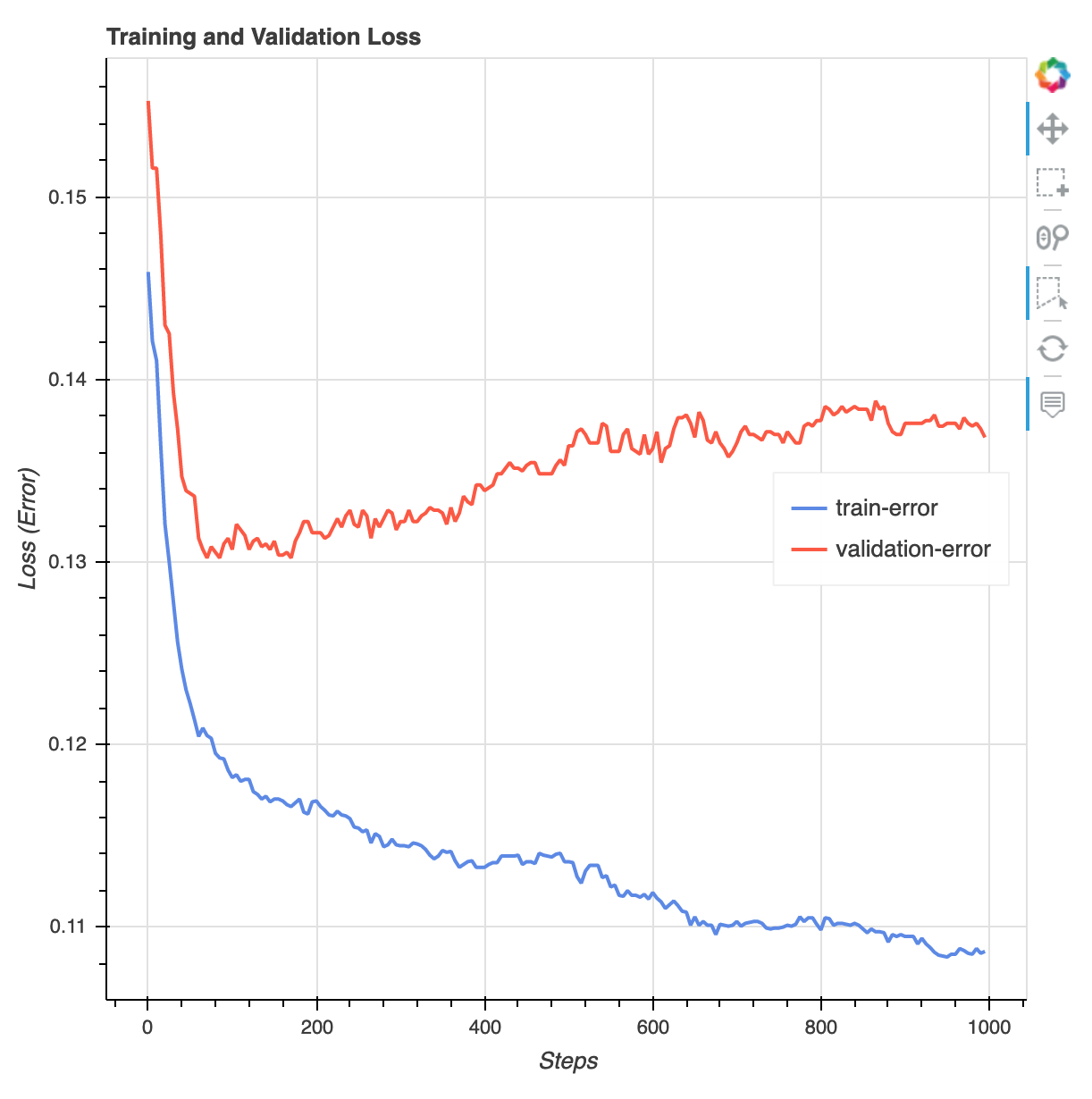
Ejecute el siguiente código para especificar el URI del bucket de S3 en el que se generan los informes de entrenamiento del depurador y compruebe si los informes existen.
rule_output_path = xgb_model.output_path + "/" + xgb_model.latest_training_job.job_name + "/rule-output" ! aws s3 ls {rule_output_path} --recursiveDescargue los informes de entrenamiento y creación de perfiles de XGBoost del depurador en el espacio de trabajo actual:
! aws s3 cp {rule_output_path} ./ --recursiveEjecute el siguiente script de iPython para obtener el enlace al archivo del informe de entrenamiento de XGBoost:
from IPython.display import FileLink, FileLinks display("Click link below to view the XGBoost Training report", FileLink("CreateXgboostReport/xgboost_report.html"))El siguiente script de iPython devuelve el enlace al archivo del informe de creación de perfiles del depurador, que muestra resúmenes y detalles del uso de los recursos de la instancia EC2, los resultados de la detección de cuellos de botella en el sistema y los resultados de la creación de perfiles de operaciones de Python:
profiler_report_name = [rule["RuleConfigurationName"] for rule in xgb_model.latest_training_job.rule_job_summary() if "Profiler" in rule["RuleConfigurationName"]][0] profiler_report_name display("Click link below to view the profiler report", FileLink(profiler_report_name+"/profiler-output/profiler-report.html"))sugerencia
Si los informes HTML no representan gráficos en la JupyterLab vista, debe elegir Confiar en HTML en la parte superior de los informes.
Para identificar los problemas de entrenamiento, como el sobreajuste, la desaparición de los gradientes y otros problemas que impiden la convergencia del modelo, utilice SageMaker Debugger y tome medidas automatizadas mientras crea prototipos y entrena sus modelos de aprendizaje automático. Para obtener más información, consulte Amazon SageMaker Debugger. Para obtener un análisis completo de los parámetros del modelo, consulte el cuaderno de ejemplo Explicability with Amazon SageMaker Debugger
.
Ahora tiene un modelo XGBoost entrenado. SageMaker La IA almacena el artefacto modelo en su depósito S3. Para encontrar la ubicación del artefacto modelo, ejecute el siguiente código para imprimir el atributo model_data del estimador xgb_model:
xgb_model.model_data
sugerencia
Para medir los sesgos que pueden producirse durante cada etapa del ciclo de vida del aprendizaje automático (recopilación de datos, entrenamiento y ajuste de los modelos y supervisión de los modelos de aprendizaje automático implementados para la predicción), utilice SageMaker Clarify. Para obtener más información, consulte Explicabilidad del modelo. Para ver un ejemplo integral, consulte el cuaderno de ejemplo Equidad y explicabilidad con SageMaker Clarify.
