Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Una vez SageMaker finalizado un trabajo de procesamiento de Clarify, puede descargar los archivos de salida para inspeccionarlos o puede visualizar los resultados en SageMaker Studio Classic. En el siguiente tema se describen los resultados del análisis que SageMaker genera Clarify, como el esquema y el informe que se generan mediante el análisis de sesgos, el análisis SHAP, el análisis de explicabilidad mediante visión artificial y el análisis de gráficas de dependencia parcial ()PDPs. Si el análisis de configuración contiene parámetros para calcular varios análisis, los resultados se agregan en un análisis y un archivo de informe.
El directorio de salida de los trabajos de procesamiento de SageMaker Clarify contiene los siguientes archivos:
-
analysis.json: un archivo que contiene las métricas de sesgo y la importancia de las características en formato JSON. -
report.ipynb: un cuaderno estático que contiene código para ayudarle a visualizar las métricas de sesgo y la importancia de las características. -
explanations_shap/out.csv: un directorio que se crea y contiene archivos generados automáticamente en función de sus configuraciones de análisis específicas. Por ejemplo, si activa el parámetrosave_local_shap_values, los valores SHAP locales por instancia se guardarán en el directorioexplanations_shap. Como otro ejemplo, sianalysis configurationno contiene un valor para el parámetro de referencia de SHAP, el trabajo de explicabilidad de SageMaker Clarify calcula una línea de base agrupando el conjunto de datos de entrada. A continuación, guarda la referencia generada en el directorio.
Para obtener más información, consulte las siguientes secciones.
Temas
Análisis del sesgo
Amazon SageMaker Clarify utiliza la terminología documentada Amazon SageMaker aclara los términos de sesgo y equidad para hablar sobre los prejuicios y la imparcialidad.
Esquema del archivo de análisis
El archivo de análisis está en formato JSON y está organizado en dos secciones: métricas de sesgo previas al entrenamiento y métricas de sesgo posteriores al entrenamiento. Los parámetros de las métricas de sesgo antes y después del entrenamiento son los siguientes.
-
pre_training_bias_metrics: parámetros para las métricas de sesgo previas al entrenamiento. Para obtener más información, consulte Métricas de sesgo previas al entrenamiento y Archivos de configuración del análisis.
-
label: el nombre de la etiqueta de verdad fundamental definido por el parámetro de configuración del análisis
label. -
label_value_or_threshold: cadena que contiene los valores de etiqueta o el intervalo definidos por el parámetro de configuración del análisis
label_values_or_threshold. Por ejemplo, si se proporciona un valor de1para un problema de clasificación binaria, la cadena será1. Si se proporcionan varios valores[1,2]para un problema multiclase, entonces la cadena será1,2. Si se proporciona un umbral de40para un problema de regresión, la cadena será interna, como(40, 68]donde68es el valor máximo de la etiqueta en el conjunto de datos de entrada. -
facets: la sección contiene varios pares clave-valor, donde la clave corresponde al nombre de la faceta definido por el parámetro
name_or_indexde la configuración de la faceta, y el valor es una matriz de objetos facetados. Cada objeto facetado tiene los siguientes miembros:-
value_or_threshold: cadena que contiene los valores de la faceta o el intervalo definidos por el parámetro de configuración del análisis
value_or_threshold. -
metrics: la sección contiene una matriz de elementos de métrica de sesgo y cada elemento de métrica de sesgo tiene los siguientes atributos:
-
name: el nombre abreviado de la métrica de sesgo. Por ejemplo,
CI. -
description: el nombre completo de la métrica de sesgo. Por ejemplo,
Class Imbalance (CI). -
value: el valor de la métrica de sesgo o el valor nulo de JSON si la métrica de sesgo no se calcula por un motivo concreto. Los valores ±∞ se representan como cadenas
∞y-∞respectivamente. -
error: mensaje de error opcional que explica por qué no se calculó la métrica de sesgo.
-
-
-
-
post_training_bias_metrics: la sección contiene las métricas de sesgo posteriores al entrenamiento y sigue un diseño y una estructura similares a los de la sección previa al entrenamiento. Para obtener más información, consulte Métricas del sesgo de los datos y el modelo posterior al entrenamiento.
El siguiente es un ejemplo de una configuración de análisis que calculará las métricas de sesgo previas y posteriores al entrenamiento.
{
"version": "1.0",
"pre_training_bias_metrics": {
"label": "Target",
"label_value_or_threshold": "1",
"facets": {
"Gender": [{
"value_or_threshold": "0",
"metrics": [
{
"name": "CDDL",
"description": "Conditional Demographic Disparity in Labels (CDDL)",
"value": -0.06
},
{
"name": "CI",
"description": "Class Imbalance (CI)",
"value": 0.6
},
...
]
}]
}
},
"post_training_bias_metrics": {
"label": "Target",
"label_value_or_threshold": "1",
"facets": {
"Gender": [{
"value_or_threshold": "0",
"metrics": [
{
"name": "AD",
"description": "Accuracy Difference (AD)",
"value": -0.13
},
{
"name": "CDDPL",
"description": "Conditional Demographic Disparity in Predicted Labels (CDDPL)",
"value": 0.04
},
...
]
}]
}
}
}Informe de análisis del sesgo
El informe de análisis del sesgo incluye varias tablas y diagramas que contienen explicaciones y descripciones detalladas. Incluyen, entre otras cosas, la distribución de los valores de las etiquetas, la distribución de los valores de las facetas, un diagrama de rendimiento del modelo de alto nivel, una tabla de métricas de sesgo y sus descripciones. Para obtener más información sobre las métricas de sesgo y cómo interpretarlas, consulte Aprenda cómo Amazon SageMaker Clarify ayuda a detectar el sesgo
Análisis SHAP
SageMaker Los trabajos de procesamiento de Clarify utilizan el algoritmo SHAP del núcleo para calcular las atribuciones de las características. El trabajo SageMaker de procesamiento de Clarify produce valores SHAP locales y globales. Estos ayudan a determinar la contribución de cada característica a las predicciones del modelo. Los valores SHAP locales representan la importancia de la característica para cada instancia individual, mientras que los valores SHAP globales agregan los valores SHAP locales de todas las instancias del conjunto de datos. Para obtener más información acerca de los valores SHAP y cómo interpretarlos, consulte Atribuciones de características que utilizan valores Shapley.
Esquema del archivo de análisis SHAP
Los resultados del análisis SHAP global se almacenan en la sección de explicaciones del archivo de análisis, en la sección correspondiente al método kernel_shap. Los diferentes parámetros del archivo de análisis SHAP son los siguientes:
-
explanations: la sección del archivo de análisis que contiene los resultados del análisis de importancia de las características.
-
kernal_shap: sección del archivo de análisis que contiene el resultado del análisis SHAP global.
-
global_shap_values: sección del archivo de análisis que contiene varios pares clave-valor. Cada clave del par clave-valor representa un nombre de característica del conjunto de datos de entrada. Cada valor del par clave-valor corresponde al valor SHAP global de la característica. El valor SHAP global se obtiene al agregar los valores SHAP por instancia de la característica mediante la configuración
agg_method. Si la configuraciónuse_logitestá activada, el valor se calcula mediante los coeficientes de regresión logística, que se pueden interpretar como coeficientes logarítmicos de probabilidades. -
expected_value: la predicción media del conjunto de datos de referencia. Si la configuración
use_logitestá activada, el valor se calcula mediante coeficientes de regresión logística. -
global_top_shap_text: se utiliza para el análisis de explicabilidad del NLP. Sección del archivo de análisis que incluye un conjunto de pares clave-valor. SageMaker Los trabajos de procesamiento de Clarify agregan los valores de SHAP de cada token y, a continuación, seleccionan los principales tokens en función de sus valores de SHAP globales. La configuración
max_top_tokensdefine el número de tokens que se van a seleccionar.Cada uno de los principales tokens seleccionados tiene un par clave-valor. La clave del par clave-valor corresponde al nombre de la característica de texto de un token principal. Cada valor del par clave-valor son los valores SHAP globales del token principal. Para ver un ejemplo de un par clave-valor
global_top_shap_text, consulte la siguiente salida.
-
-
A continuación, se muestra un ejemplo de salida del análisis de SHAP de un conjunto de datos tabular.
{
"version": "1.0",
"explanations": {
"kernel_shap": {
"Target": {
"global_shap_values": {
"Age": 0.022486410860333206,
"Gender": 0.007381025261958729,
"Income": 0.006843906804137847,
"Occupation": 0.006843906804137847,
...
},
"expected_value": 0.508233428001
}
}
}
}A continuación, se muestra un ejemplo de salida del análisis de SHAP de un conjunto de datos de texto. La salida correspondiente a la columna Comments es un ejemplo de salida que se genera después del análisis de una característica de texto.
{
"version": "1.0",
"explanations": {
"kernel_shap": {
"Target": {
"global_shap_values": {
"Rating": 0.022486410860333206,
"Comments": 0.058612104851485144,
...
},
"expected_value": 0.46700941970297033,
"global_top_shap_text": {
"charming": 0.04127962903247833,
"brilliant": 0.02450240786522321,
"enjoyable": 0.024093569652715457,
...
}
}
}
}
}Esquema del archivo de referencia generado
Cuando no se proporciona una configuración de referencia de SHAP, el trabajo de procesamiento de SageMaker Clarify genera un conjunto de datos de referencia. SageMaker Clarify utiliza un algoritmo de agrupamiento basado en la distancia para generar un conjunto de datos de referencia a partir de los clústeres creados a partir del conjunto de datos de entrada. El conjunto de datos de referencia resultante se guarda en un archivo CSV, ubicado en explanations_shap/baseline.csv. Este archivo de salida contiene una fila de encabezado y varias instancias en función del parámetro num_clusters especificado en la configuración del análisis. El conjunto de datos de referencia solo consta de columnas de características. El siguiente ejemplo muestra una referencia creada mediante al agrupar en clúster el conjunto de datos de entrada.
Age,Gender,Income,Occupation
35,0,2883,1
40,1,6178,2
42,0,4621,0Esquema de valores SHAP locales a partir del análisis de explicabilidad de un conjunto de datos tabulares
En el caso de los conjuntos de datos tabulares, si se utiliza una sola instancia de procesamiento, el trabajo de procesamiento de SageMaker Clarify guarda los valores SHAP locales en un archivo CSV denominado. explanations_shap/out.csv Si utiliza varias instancias de computación, los valores SHAP locales se guardan en varios archivos CSV del directorio explanations_shap.
Un archivo de salida que contiene valores SHAP locales tiene una fila que contiene los valores SHAP locales de cada columna definida en los encabezados. Los encabezados siguen la convención de nomenclatura de Feature_Label, donde el nombre de la característica se anexa con un guion bajo seguido del nombre de la variable objetivo.
En el caso de problemas multiclase, primero varían los nombres de las características en el encabezado y luego las etiquetas. Por ejemplo, dos características F1, F2, y dos clases L1 y L2, en los encabezados son F1_L1, F2_L1, F1_L2 y F2_L2. Si la configuración de análisis contiene un valor para el parámetro joinsource_name_or_index, la columna de clave utilizada en la unión se anexa al final del nombre del encabezado. Esto permite asignar los valores SHAP locales a instancias del conjunto de datos de entrada. A continuación, se muestra un ejemplo de un archivo de salida que contiene valores SHAP.
Age_Target,Gender_Target,Income_Target,Occupation_Target 0.003937908,0.001388849,0.00242389,0.00274234 -0.0052784,0.017144491,0.004480645,-0.017144491 ...
Esquema de valores SHAP locales a partir del análisis de explicabilidad del NLP
Para el análisis de explicabilidad de la PNL, si se utiliza una sola instancia de procesamiento, el trabajo de procesamiento de Clarify guarda SageMaker los valores SHAP locales en un archivo JSON Lines denominado explanations_shap/out.jsonl Si utiliza varias instancias de computación, los valores SHAP locales se guardan en varios archivos JSON Lines del directorio explanations_shap.
Cada archivo que contiene valores SHAP locales tiene varias líneas de datos y cada línea es un objeto JSON válido. El objeto JSON tiene los siguientes atributos:
-
explanations: la sección del archivo de análisis que contiene una serie de explicaciones Kernel SHAP para una sola instancia. Cada elemento de la matriz tiene los siguientes miembros:
-
feature_name: el nombre del encabezado de las características proporcionado por la configuración del encabezado.
-
data_type: el tipo de función que deduce el trabajo de procesamiento de Clarify. SageMaker Los valores válidos para las características de texto incluyen
numerical,categoricalyfree_text(para las características de texto). -
attributions: conjunto de objetos de atribución específicos de una característica. Una característica de texto puede tener varios objetos de atribución, cada uno para una unidad definida por la configuración
granularity. El objeto de atribución tiene los siguientes miembros:-
attribution: conjunto de valores de probabilidad específico de una clase.
-
description: (para las características del texto). La descripción de las unidades de texto.
-
partial_text: la parte del texto explicada por el trabajo de procesamiento de Clarify. SageMaker
-
start_idx: un índice de base cero para identificar la ubicación de la matriz que indica el principio del fragmento de texto parcial.
-
-
-
El siguiente es un ejemplo de una sola línea de un archivo de valores SHAP local, embellecido para mejorar su legibilidad.
{
"explanations": [
{
"feature_name": "Rating",
"data_type": "categorical",
"attributions": [
{
"attribution": [0.00342270632248735]
}
]
},
{
"feature_name": "Comments",
"data_type": "free_text",
"attributions": [
{
"attribution": [0.005260534499999983],
"description": {
"partial_text": "It's",
"start_idx": 0
}
},
{
"attribution": [0.00424190349999996],
"description": {
"partial_text": "a",
"start_idx": 5
}
},
{
"attribution": [0.010247314500000014],
"description": {
"partial_text": "good",
"start_idx": 6
}
},
{
"attribution": [0.006148907500000005],
"description": {
"partial_text": "product",
"start_idx": 10
}
}
]
}
]
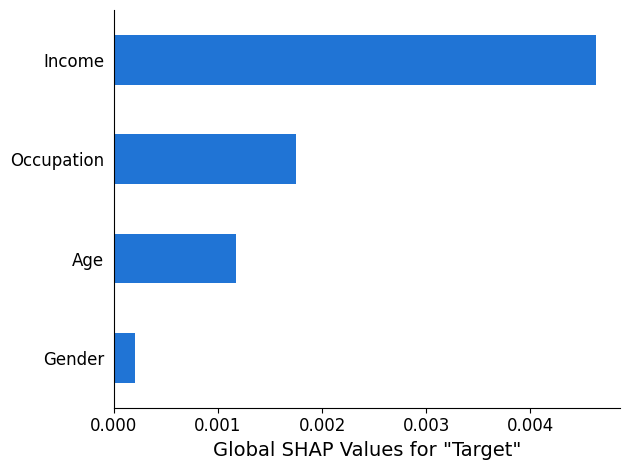
}Informe de análisis SHAP
El informe de análisis SHAP proporciona un gráfico de barras con un máximo de 10 valores SHAP principales globales. El siguiente ejemplo de gráfico muestra los valores SHAP de las 4 características principales.
Análisis de explicabilidad de la visión artificial (CV)
SageMaker La explicabilidad de la visión artificial de Clarify toma un conjunto de datos compuesto por imágenes y trata cada imagen como una colección de superpíxeles. Tras el análisis, el trabajo SageMaker de procesamiento Clarify genera un conjunto de datos de imágenes en el que cada imagen muestra el mapa térmico de los superpíxeles.
El siguiente ejemplo muestra una señal de límite de velocidad de entrada a la izquierda y un mapa térmico muestra la magnitud de los valores SHAP a la derecha. Estos valores SHAP se calcularon mediante un modelo Resnet-18 de reconocimiento de imágenes que está entrenado para reconocer las señales de tráfico alemanas

Para obtener más información, consulte los cuadernos de muestra en los que se explica la clasificación de imágenes con SageMaker Clarify
Análisis de gráficas de dependencia parcial (PDPs)
Los gráficos de dependencia parcial muestran la dependencia de la respuesta objetivo prevista con respecto a un conjunto de características de entrada de interés. Están marginadas sobre los valores de todas las demás características de entrada y se denominan características de complemento. De forma intuitiva, puede interpretar la dependencia parcial como la respuesta objetivo, que se espera como una función de cada característica de entrada de interés.
Esquema del archivo de análisis
Los valores PDP se almacenan en la sección explanations del archivo de análisis correspondiente al método pdp. Los parámetros de explanations son los siguientes:
-
explanations: la sección de los archivos de análisis que contiene los resultados del análisis de importancia de las características.
-
pdp: la sección del archivo de análisis que contiene una matriz de explicaciones PDP para una sola instancia. Cada elemento de la matriz tiene los siguientes miembros:
-
feature_name: el nombre del encabezado de las características proporcionado por la configuración de
headers. -
data_type: el tipo de función inferido por el trabajo de procesamiento de SageMaker Clarify. Los valores válidos de
data_typeincluyen los numéricos y los categóricos. -
feature_values: contiene los valores presentes en la característica. Si lo
data_typeinferido por SageMaker Clarify es categórico,feature_valuescontiene todos los valores únicos que podría tener la entidad. Si lodata_typeinferido por SageMaker Clarify es numérico,feature_valuescontiene una lista del valor central de los cubos generados. El parámetrogrid_resolutiondetermina el número de buckets que se utilizan para agrupar los valores de la columna de características. -
data_distribution: matriz de porcentajes en la que cada valor es el porcentaje de instancias que contiene un bucket. El parámetro
grid_resolutiondetermina el número de buckets. Los valores de la columna de características se agrupan en estos buckets. -
model_predictions: matriz de predicciones del modelo, en la que cada elemento de la matriz es una matriz de predicciones que corresponde a una clase de la salida del modelo.
label_headers: los encabezados de etiquetas proporcionados por la configuración
label_headers. -
error: se genera un mensaje de error si los valores PDP no se calculan por un motivo determinado. Este mensaje de error reemplaza el contenido de los campos
feature_values,data_distributionsymodel_predictions.
-
-
A continuación se muestra un ejemplo de la salida de un archivo de análisis que contiene el resultado de un análisis PDP.
{
"version": "1.0",
"explanations": {
"pdp": [
{
"feature_name": "Income",
"data_type": "numerical",
"feature_values": [1046.9, 2454.7, 3862.5, 5270.2, 6678.0, 8085.9, 9493.6, 10901.5, 12309.3, 13717.1],
"data_distribution": [0.32, 0.27, 0.17, 0.1, 0.045, 0.05, 0.01, 0.015, 0.01, 0.01],
"model_predictions": [[0.69, 0.82, 0.82, 0.77, 0.77, 0.46, 0.46, 0.45, 0.41, 0.41]],
"label_headers": ["Target"]
},
...
]
}
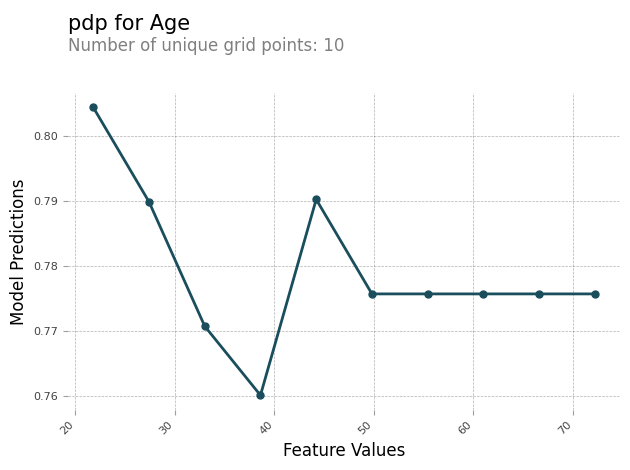
}Informe de análisis PDP
Puede generar un informe de análisis que contenga un gráfico PDP para cada característica. El gráfico PDP traza los feature_values a lo largo del eje x y traza las model_predictions a lo largo del eje y. Para los modelos multiclase, model_predictions es una matriz y cada elemento de esta matriz corresponde a una de las clases de predicción del modelo.
El siguiente es un ejemplo de gráfico PDP para la característica Age. En la salida de ejemplo, el PDP muestra el número de valores de la característica que están agrupados en buckets. El número de buckets viene determinado por grid_resolution. Los buckets de valores de las características se representan gráficamente en función de las predicciones del modelo. En este ejemplo, los valores de la característica más altos tienen los mismos valores de predicción del modelo.
Valores asimétricos de Shapley
SageMaker Los trabajos de procesamiento de Clarify utilizan el algoritmo de valores asimétricos de Shapley para calcular las atribuciones explicativas del modelo de previsión de series temporales. Este algoritmo determina la contribución de las características de entrada en cada paso temporal en las predicciones pronosticadas.
Esquema del archivo de análisis de valores asimétricos de Shapley
Los resultados de los valores asimétricos de Shapley se almacenan en un bucket de Amazon S3. Puede encontrar la ubicación de este bucket en la sección de explicaciones del archivo de análisis. Esta sección contiene los resultados del análisis de importancia de las características. Los siguientes parámetros se incluyen en el archivo de análisis de valores asimétricos de Shapley.
asymmetric_shapley_value: sección del archivo de análisis que contiene metadatos sobre los resultados del trabajo de explicación, incluidos los siguientes:
explanation_results_path: ubicación de Amazon S3 con los resultados de la explicación
direction: configuración proporcionada por el usuario para el valor de configuración de
directiongranularity: configuración proporcionada por el usuario para el valor de configuración de
granularity
El siguiente fragmento muestra los parámetros mencionados anteriormente en un archivo de análisis de ejemplo:
{
"version": "1.0",
"explanations": {
"asymmetric_shapley_value": {
"explanation_results_path": EXPLANATION_RESULTS_S3_URI,
"direction": "chronological",
"granularity": "timewise",
}
}
}En las siguientes secciones, se describe cómo la estructura de los resultados de la explicación depende del valor de granularity en la configuración.
Nivel de detalle basado en tiempo
Cuando el nivel de detalle es timewise, la salida se representa en la siguiente estructura. El valor scores representa la atribución de cada marca de tiempo. El valor offset representa la predicción del modelo sobre los datos de referencia y describe el comportamiento del modelo cuando no recibe datos.
En el siguiente fragmento, se muestra un ejemplo de la salida de un modelo que hace predicciones para dos pasos temporales. Por lo tanto, todas las atribuciones son una lista de dos elementos, donde la primera entrada se refiere al primer intervalo de tiempo pronosticado.
{
"item_id": "item1",
"offset": [1.0, 1.2],
"explanations": [
{"timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.1]},
{"timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.2]},
{"timestamp": "2019-09-13 00:00:00", "scores": [0.45, 0.3]},
]
}
{
"item_id": "item2",
"offset": [1.0, 1.2],
"explanations": [
{"timestamp": "2019-09-11 00:00:00", "scores": [0.51, 0.35]},
{"timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.22]},
{"timestamp": "2019-09-13 00:00:00", "scores": [0.46, 0.31]},
]
}Nivel de detalle afinado
El siguiente ejemplo muestra los resultados de la atribución cuando la el nivel de detalle es fine_grained. El valor offset tiene el mismo significado que el descrito en la sección anterior. Las atribuciones se calculan para cada característica de entrada en cada marca de tiempo para una serie temporal objetivo y series temporales relacionadas, si hay disponibles, además de para cada covariable estática, si hay alguna disponible.
{
"item_id": "item1",
"offset": [1.0, 1.2],
"explanations": [
{"feature_name": "tts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.11]},
{"feature_name": "tts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.43]},
{"feature_name": "tts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.15, 0.51]},
{"feature_name": "tts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.81, 0.18]},
{"feature_name": "rts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.01, 0.10]},
{"feature_name": "rts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.41]},
{"feature_name": "rts_feature_name_1", "timestamp": "2019-09-13 00:00:00", "scores": [0.95, 0.59]},
{"feature_name": "rts_feature_name_1", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]},
{"feature_name": "rts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.65, 0.56]},
{"feature_name": "rts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.43, 0.34]},
{"feature_name": "rts_feature_name_2", "timestamp": "2019-09-13 00:00:00", "scores": [0.16, 0.61]},
{"feature_name": "rts_feature_name_2", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]},
{"feature_name": "static_covariate_1", "scores": [0.6, 0.1]},
{"feature_name": "static_covariate_2", "scores": [0.1, 0.3]},
]
}Para ambos casos de uso, timewise y fine-grained, los resultados se almacenan en el formato JSON Lines (.jsonl).
