Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
importante
Amazon Web Services (AWS) anuncia que no habrá nuevas versiones o versiones de SageMaker Training Compiler. Puede seguir utilizando SageMaker Training Compiler a través de los AWS Deep Learning Containers (DLCs) existentes para SageMaker formación. Es importante tener en cuenta que, si bien los existentes DLCs permanecen accesibles, ya no recibirán parches ni actualizaciones de ellos AWS, de acuerdo con la Política de soporte de AWS Deep Learning Containers Framework.
Si se produce un error, puede utilizar la siguiente lista para intentar solucionar los problemas del trabajo de entrenamiento. Si necesitas más ayuda, ponte en contacto con el equipo de SageMaker IA a través de los foros de AWS soporte
El trabajo de entrenamiento no converge como se esperaba en comparación con el trabajo de entrenamiento nativo
Los problemas de convergencia van desde «el modelo no aprende cuando SageMaker Training Compiler está activado» hasta «el modelo aprende pero es más lento que el marco nativo». En esta guía de solución de problemas, asumimos que la convergencia es correcta sin SageMaker Training Compiler (en el marco nativo) y consideramos que esta es la base de referencia.
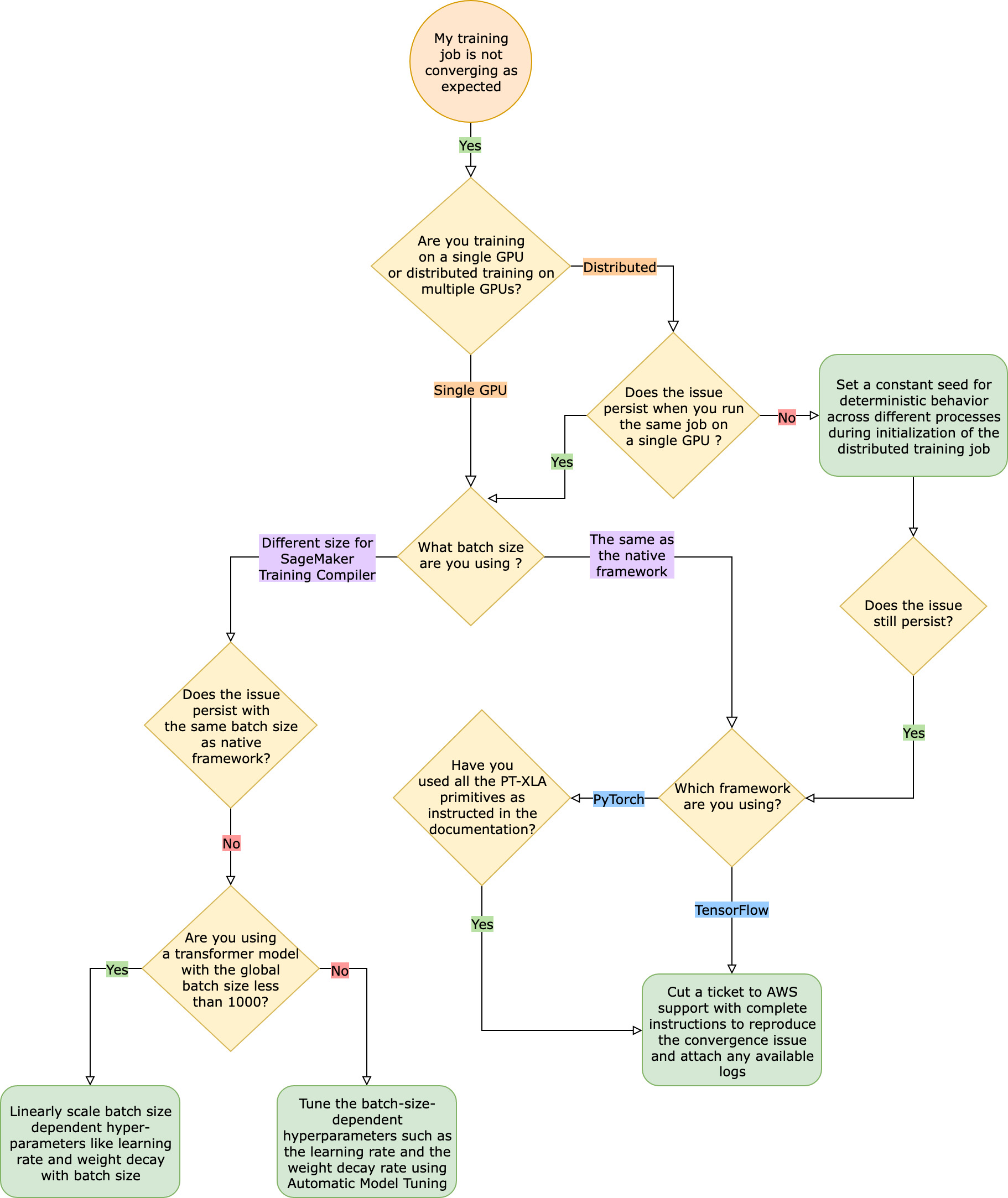
Ante estos problemas de convergencia, el primer paso es identificar si el problema se limita a la entrenamiento distribuida o si se debe a una entrenamiento con una sola GPU. El entrenamiento distribuido con SageMaker Training Compiler es una extensión del entrenamiento con una sola GPU con pasos adicionales.
-
Configure un clúster con varias instancias o. GPUs
-
Distribuya los datos de entrada a todos los trabajadores.
-
Sincronice las actualizaciones del modelo de todos los trabajadores.
Por lo tanto, cualquier problema de convergencia en la entrenamiento con una sola GPU se propaga a la entrenamiento distribuida con varios trabajadores.
Los problemas de convergencia se producen en el entrenamiento con una sola GPU
Si su problema de convergencia se debe a un entrenamiento con una sola GPU, es probable que se deba a una configuración incorrecta de los hiperparámetros o a la. torch_xla APIs
Comprobar los hiperparámetros
El entrenamiento con SageMaker Training Compiler provoca un cambio en el espacio de memoria de un modelo. El compilador decide de forma inteligente entre la reutilización y el recálculo, lo que provoca el correspondiente aumento o disminución del consumo de memoria. Para aprovechar esto, es esencial volver a ajustar el tamaño del lote y los hiperparámetros asociados al migrar un trabajo de formación a Training Compiler. SageMaker Sin embargo, los ajustes incorrectos de los hiperparámetros suelen provocar oscilaciones, pérdidas de entrenamiento y, posiblemente, una convergencia más lenta. En raras ocasiones, los hiperparámetros agresivos pueden provocar que el modelo no aprenda (la métrica de pérdida de entrenamiento no disminuye ni devuelve NaN). Para identificar si el problema de convergencia se debe a los hiperparámetros, realice una side-by-side prueba de dos trabajos de formación con y sin SageMaker Training Compiler manteniendo todos los hiperparámetros iguales.
Comprueba si torch_xla APIs están configurados correctamente para el entrenamiento con una sola GPU
Si el problema de convergencia persiste con los hiperparámetros de referencia, debes comprobar si se ha hecho un uso incorrecto de los hiperparámetros torch_xla APIs, específicamente los que se utilizan para actualizar el modelo. Básicamente, torch_xla sigue acumulando instrucciones (aplazando la ejecución) en forma de gráfico hasta que se le indique explícitamente que ejecute el gráfico acumulado. La función torch_xla.core.xla_model.mark_step() facilita la ejecución del gráfica acumulado. La ejecución del gráfico debe sincronizarse mediante esta función después de cada actualización del modelo y antes de imprimir y registrar cualquier variable. Si no incluye el paso de sincronización, el modelo podría utilizar valores obsoletos de la memoria durante las impresiones, los registros y las sucesivas pasadas, en lugar de utilizar los valores más recientes que deben sincronizarse después de cada iteración y actualización del modelo.
Puede resultar más complicado si se utiliza SageMaker Training Compiler con técnicas de escalado de gradiente (posiblemente mediante el uso de AMP) o de recorte de gradientes. El orden apropiado para calcular los gradientes con AMP es el siguiente.
-
Cálculo de gradientes con escalado
-
Desescalado del gradiente, recorte del gradiente y, a continuación, escalado
-
Actualización del modelo
-
Sincronizar la ejecución del gráfico con
mark_step()
Para encontrar la operación adecuada APIs para las mencionadas en la lista, consulta la guía para migrar tu guion de entrenamiento a SageMaker Training Compiler.
Considerar la posibilidad de utilizar el ajuste automático de modelos
Si el problema de convergencia surge al volver a ajustar el tamaño del lote y los hiperparámetros asociados, como la tasa de aprendizaje, al utilizar SageMaker Training Compiler, considere la posibilidad de utilizar el ajuste automático del modelo para ajustar los hiperparámetros. Puede consultar el cuaderno de ejemplo sobre cómo ajustar los hiperparámetros
Problemas de convergencia que se producen en el entrenamiento distribuida
Si su problema de convergencia persiste en el entrenamiento distribuido, es probable que se deba a una configuración incorrecta para la inicialización del peso o a la. torch_xla APIs
Comprobar la inicialización del peso entre los trabajadores
Si el problema de la convergencia surge al ejecutar un trabajo de entrenamiento distribuido con varios trabajadores, asegúrese de que haya un comportamiento determinista uniforme en todos los trabajadores estableciendo un valor inicial constante cuando proceda. Tenga cuidado con técnicas como la inicialización del peso, que implica laasignación al azar. Cada trabajador podría terminar entrenando a un modelo diferente en ausencia de una semilla constante.
Comprueba si torch_xla APIs están configurados correctamente para el entrenamiento distribuido
Si el problema persiste, es probable que se deba a un uso incorrecto de torch_xla APIs la formación distribuida. Asegúrese de añadir lo siguiente en su estimador para configurar un clúster para la formación distribuida con Training Compiler SageMaker .
distribution={'torchxla': {'enabled': True}}Esto debería ir acompañado de una función _mp_fn(index) en el script de entrenamiento, que se invoque una vez por trabajador. Sin la función mp_fn(index), podría terminar dejando que cada uno de los trabajadores entrenar el modelo de forma independiente sin compartir las actualizaciones del modelo.
A continuación, asegúrese de utilizar la torch_xla.distributed.parallel_loader.MpDeviceLoader API junto con el muestreador de datos distribuido, tal y como se indica en la documentación sobre la migración del guion de entrenamiento a SageMaker Training Compiler, como en el siguiente ejemplo.
torch.utils.data.distributed.DistributedSampler()Esto garantiza que los datos de entrada se distribuyan correctamente entre todos los trabajadores.
Por último, para sincronizar las actualizaciones del modelo de todos los trabajadores, utilice torch_xla.core.xla_model._fetch_gradients para recopilar los gradientes de todos los trabajadores y torch_xla.core.xla_model.all_reduce combinar todos los gradientes recopilados en una sola actualización.
Puede resultar más complicado usar SageMaker Training Compiler con técnicas de escalado de gradiente (posiblemente mediante el uso de AMP) o recorte de gradiente. El orden apropiado para calcular los gradientes con AMP es el siguiente.
-
Cálculo de gradientes con escalado
-
Sincronización de gradientes entre todos los trabajadores
-
Desescalado del gradiente, recorte del gradiente y, a continuación, escalado de gradiente
-
Actualización del modelo
-
Sincronizar la ejecución del gráfico con
mark_step()
Tenga en cuenta que esta lista de verificación incluye un elemento adicional para sincronizar a todos los trabajadores, en comparación con la lista de verificación para el entrenamiento con una sola GPU.
El trabajo de entrenamiento falla debido a que falta la configuración de PyTorch /XLA
Si un trabajo de entrenamiento falla y Missing XLA configuration aparece el mensaje de error, es posible que se deba a un error de configuración en el número de instancias que se GPUs utilizan por instancia.
XLA requiere variables de entorno adicionales para compilar el trabajo de entrenamiento. La variable de entorno que falta más comúnmente es GPU_NUM_DEVICES. Para que el compilador funcione correctamente, debes establecer esta variable de entorno igual al número de GPUs por instancia.
Existen tres enfoques para configurar la variable de entorno GPU_NUM_DEVICES:
-
Método 1: utilice el
environmentargumento de la clase de SageMaker estimadores AI. Por ejemplo, si utilizas unaml.p3.8xlargeinstancia que tiene cuatro GPUs, haz lo siguiente:# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... instance_type="ml.p3.8xlarge", hyperparameters={...}, environment={ ... "GPU_NUM_DEVICES": "4" # corresponds to number of GPUs on the specified instance }, ) -
Método 2: usa el
hyperparametersargumento de la clase de estimadores de SageMaker IA y analízalo en tu guion de entrenamiento.-
Para especificar el número de GPUs, añade un par clave-valor al argumento.
hyperparametersPor ejemplo, si usas una
ml.p3.8xlargeinstancia que tiene cuatro GPUs, haz lo siguiente:# Using the SageMaker Python SDK's HuggingFace estimator hf_estimator=HuggingFace( ... entry_point = "train.py" instance_type= "ml.p3.8xlarge", hyperparameters = { ... "n_gpus":4# corresponds to number of GPUs on specified instance } ) hf_estimator.fit() -
En su script de entrenamiento, analice el hiperparámetro
n_gpusy especifíquelo como entrada para la variable de entornoGPU_NUM_DEVICES.# train.py import os, argparse if __name__ == "__main__": parser = argparse.ArgumentParser() ... # Data, model, and output directories parser.add_argument("--output_data_dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"]) parser.add_argument("--model_dir", type=str, default=os.environ["SM_MODEL_DIR"]) parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"]) parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"]) parser.add_argument("--n_gpus", type=str, default=os.environ["SM_NUM_GPUS"]) args, _ = parser.parse_known_args() os.environ["GPU_NUM_DEVICES"] = args.n_gpus
-
-
Método 3: codifique de forma rígida la variable de entorno
GPU_NUM_DEVICESen su script de entrenamiento. Por ejemplo, agrega lo siguiente a tu script si usas una instancia que tiene cuatro GPUs.# train.py import os os.environ["GPU_NUM_DEVICES"] =4
sugerencia
Para saber el número de dispositivos de GPU en las instancias de aprendizaje automático que desea utilizar, consulte Computación acelerada
SageMaker Training Compiler no reduce el tiempo total de entrenamiento
Si el tiempo total de entrenamiento no disminuye con SageMaker Training Compiler, te recomendamos encarecidamente que revises la SageMaker Recomendaciones y consideraciones sobre Training Compiler página para comprobar la configuración del entrenamiento, la estrategia de relleno para la forma del tensor de entrada y los hiperparámetros.
