Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Optimización del rendimiento de los modelos con SageMaker Neo
Neo es una capacidad de Amazon SageMaker AI que permite que los modelos de aprendizaje automático se entrenen una sola vez y se ejecuten en cualquier lugar de la nube y en la periferia.
Si es la primera vez que utiliza SageMaker Neo, le recomendamos que consulte la sección Introducción a los dispositivos perimetrales para obtener instrucciones paso a paso sobre cómo compilar e implementar en un dispositivo perimetral.
¿Qué es SageMaker Neo?
Normalmente, la optimización de modelos de machine learning para inferencias en varias plataformas resulta extremadamente difícil ya que se tienen que ajustar a mano los modelos para la configuración específica de hardware y software de cada plataforma. Si desea obtener un rendimiento de nivel óptimo para una carga de trabajo determinada, tiene que conocer el conjunto de instrucciones de la arquitectura de hardware, los patrones de acceso de memoria y las formas de datos de entrada entre otros factores. Para el desarrollo de software tradicional, las herramientas tales como compiladores y perfiladores simplifican el proceso. Para el machine learning, la mayoría de las herramientas pertenecen específicamente al marco o al hardware. Esto le obliga a realizar un proceso manual de prueba y error que es poco fiable y productivo.
Neo optimiza automáticamente los modelos Gluon, Keras, MXNet, PyTorch TensorFlow TensorFlow-Lite, y ONNX para su inferencia en máquinas Android, Linux y Windows basadas en procesadores de Ambarella, ARM, Intel, Nvidia, NXP, Qualcomm, Texas Instruments y Xilinx. Neo se prueba con los modelos de visión artificial disponibles en los zoológicos modelo de todos los sistemas. SageMaker Neo admite la compilación y el despliegue en dos plataformas principales: instancias en la nube (incluida Inferentia) y dispositivos periféricos.
Para obtener más información sobre los marcos compatibles y los tipos de instancias de nube en los que puede realizar la implementación, consulte Tipos de instancias y marcos compatibles para instancias en la nube.
Para obtener más información sobre los marcos compatibles, los dispositivos periféricos, los sistemas operativos, las arquitecturas de chips y los modelos de aprendizaje automático habituales probados por SageMaker AI Neo para dispositivos periféricos, consulte Marcos, dispositivos, sistemas y arquitecturas compatibles para dispositivos periféricos.
Funcionamiento
Neo se compone de un compilador y un tiempo de ejecución. Primero, la API de compilación de Neo lee los modelos exportados desde distintos marcos de trabajo. A continuación, convierte las operaciones y funciones específicas del marco de trabajo en una representación intermedia con independencia de este. Después, realiza una serie de optimizaciones. A continuación, genera código binario para las operaciones optimizadas, las escribe en una biblioteca de objetos compartidos y guarda la definición del modelo y los parámetros en archivos independientes. Neo también proporciona un tiempo de ejecución para cada plataforma de destino que carga y ejecuta el modelo compilado.
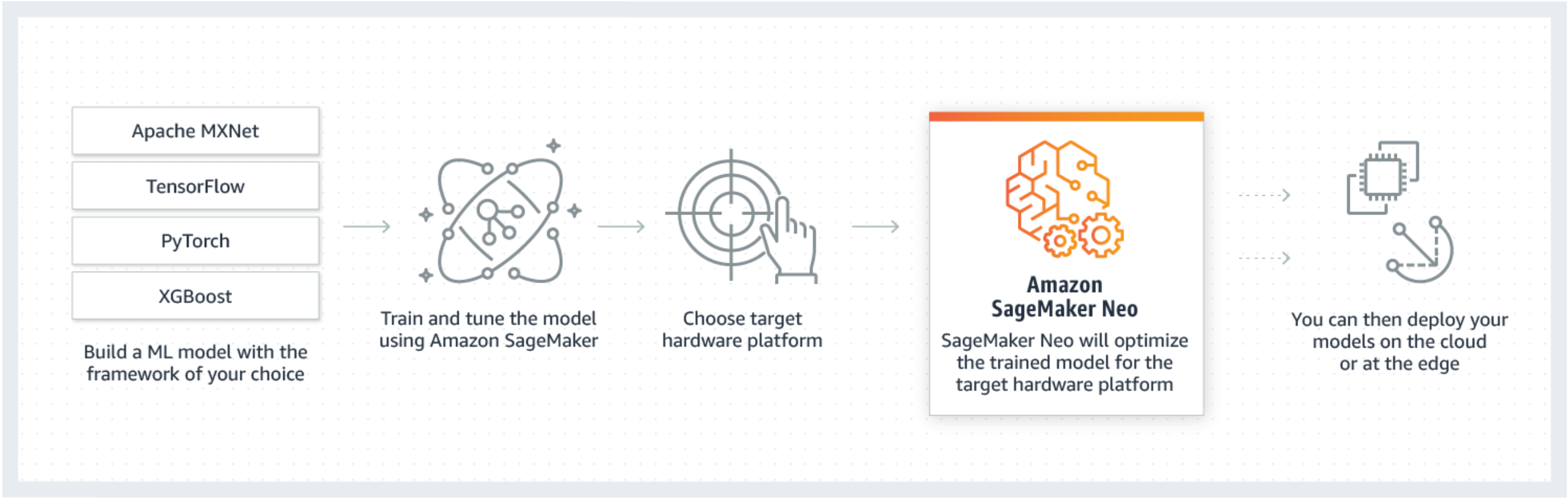
Puede crear un trabajo de compilación de Neo desde la consola de SageMaker IA, el AWS Command Line Interface (AWS CLI), un cuaderno de Python o la SDK.For información de SageMaker IA sobre cómo compilar un modelo, consulteCompilación de modelos con Neo. Con unos cuantos comandos de CLI, una invocación de la API o unos pocos clics, puede convertir un modelo para plataforma que prefiera. Puede implementar el modelo rápidamente en un punto final de SageMaker IA o en un AWS IoT Greengrass dispositivo.
Neo puede optimizar modelos con parámetros ya sea en FP32 o cuantificados con un ancho de bits de INT8 o de FP16.
Temas
