Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cargas de trabajo de transformación de datos con procesamiento SageMaker
SageMaker El procesamiento se refiere a las capacidades de la SageMaker IA para ejecutar los datos antes y después del procesamiento, diseñar funciones y modelar tareas de evaluación en la infraestructura totalmente gestionada de la SageMaker IA. Estas tareas se ejecutan como trabajos de procesamiento. A continuación, se proporciona información y recursos para obtener información sobre el SageMaker procesamiento.
Con la API de SageMaker procesamiento, los científicos de datos pueden ejecutar scripts y cuadernos para procesar, transformar y analizar conjuntos de datos a fin de prepararlos para el aprendizaje automático. Cuando se combina con otras tareas fundamentales de aprendizaje automático que proporciona la SageMaker IA, como la formación y el alojamiento, el procesamiento le proporciona las ventajas de un entorno de aprendizaje automático totalmente gestionado, que incluye todo el soporte de seguridad y cumplimiento integrado en SageMaker la IA. Tiene la flexibilidad de utilizar los contenedores de procesamiento de datos integrados o crear sus propios contenedores para una lógica de procesamiento personalizada y, a continuación, enviar los trabajos para que se ejecuten en una infraestructura gestionada por la SageMaker IA.
nota
Puede crear un trabajo de procesamiento mediante programación llamando a la acción de la CreateProcessingJobAPI en cualquier lenguaje compatible con la SageMaker IA o utilizando el. AWS CLI Para obtener información sobre cómo esta acción de API se traduce en una función en el idioma que prefieras, consulta la sección Vea también de CreateProcessingJob y elige un SDK. Como ejemplo, para los usuarios de Python, consulte la sección Amazon SageMaker Processing
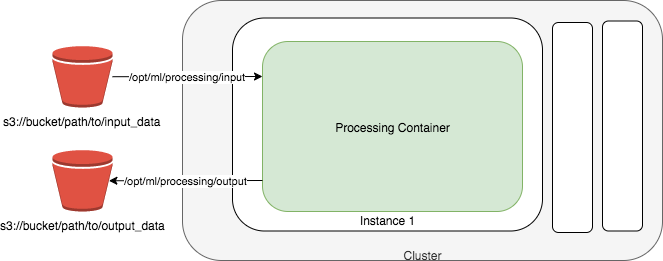
En el siguiente diagrama se muestra cómo Amazon SageMaker AI ejecuta un trabajo de procesamiento. Amazon SageMaker AI toma el script, copia los datos del Amazon Simple Storage Service (Amazon S3) y, a continuación, extrae un contenedor de procesamiento. Amazon SageMaker AI gestiona completamente la infraestructura subyacente de un trabajo de procesamiento. Después de enviar un trabajo de procesamiento, la SageMaker IA lanza las instancias de cómputo, procesa y analiza los datos de entrada y, una vez finalizada, libera los recursos. El resultado del trabajo de procesamiento se almacena en el bucket de Amazon S3 que especifique.
nota
Los datos de entrada tienen que estar almacenados en un bucket de Amazon S3. Como alternativa, también puede utilizar Amazon Athena o Amazon Redshift como orígenes de entrada.
sugerencia
Para obtener información sobre las prácticas recomendadas para la computación distribuida de los trabajos de entrenamiento y procesamiento de machine learning (ML) en general, consulte Informática distribuida con mejores prácticas de SageMaker IA.
Usa cuadernos SageMaker de muestra de Amazon Processing
Proporcionamos dos cuadernos de Jupyter de ejemplos que muestran cómo realizar el preprocesamiento de datos, la evaluación de modelos o ambas tareas.
Para ver un ejemplo de cuaderno que muestra cómo ejecutar scripts de scikit-learn para realizar el preprocesamiento de datos y el entrenamiento y la evaluación de modelos con el SDK de SageMaker Python para procesamiento, consulte scikit-learn Processing.
Para ver un ejemplo de bloc de notas que muestra cómo utilizar Amazon SageMaker Processing para realizar el preprocesamiento de datos distribuidos con Spark, consulte Procesamiento distribuido (Spark)
Para obtener instrucciones sobre cómo crear instancias de Jupyter Notebook y acceder a ellas, que puede utilizar para ejecutar estos ejemplos en SageMaker IA, consulte. Instancias de Amazon SageMaker Notebook Una vez que haya creado una instancia de bloc de notas y la haya abierto, seleccione la pestaña Ejemplos de SageMaker IA para ver una lista de todas las muestras de SageMaker IA. Para abrir un cuaderno, elija su pestaña Usar y elija Crear copia.
Supervisa los trabajos SageMaker de procesamiento de Amazon con CloudWatch registros y métricas
Amazon SageMaker Processing proporciona CloudWatch registros y métricas de Amazon para supervisar los trabajos de procesamiento. CloudWatch proporciona métricas de CPU, GPU, memoria, memoria de GPU y disco, y registro de eventos. Para obtener más información, consulte Métricas de Amazon SageMaker AI en Amazon CloudWatch y CloudWatch Registros para Amazon SageMaker AI.
