Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
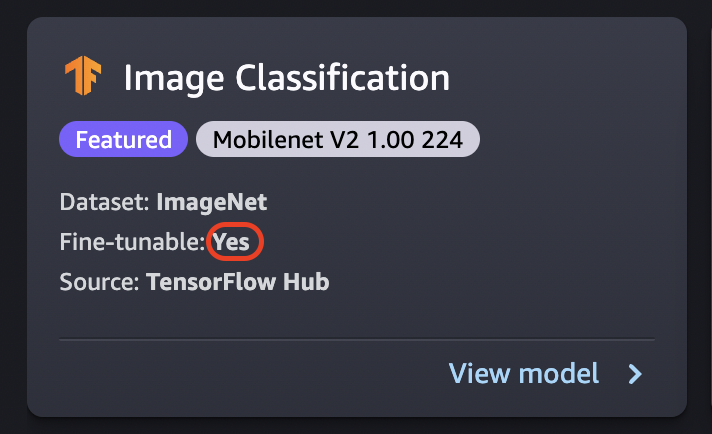
El ajuste entrena un modelo previamente entrenado en un nuevo conjunto de datos sin tener que entrenarlo desde cero. Este proceso, también conocido como aprendizaje por transferencia, puede producir modelos precisos con conjuntos de datos más pequeños y con menos tiempo de entrenamiento. Puede ajustar un modelo si su tarjeta muestra el atributo fine-tunable configurado como Sí.
importante
A partir del 30 de noviembre de 2023, la experiencia anterior de Amazon SageMaker Studio pasa a denominarse Amazon SageMaker Studio Classic. La siguiente sección es específica del uso de la aplicación de Studio Classic. Para obtener información sobre el uso de la experiencia de Studio actualizada, consulte Amazon SageMaker Studio.
nota
Para obtener más información sobre el ajuste fino de los JumpStart modelos en Studio, consulta Afinamiento de un modelo en Studio
Ajuste del origen de datos
Al ajustar un modelo, puede usar el conjunto de datos predeterminado o elegir sus propios datos que se encuentren en un bucket de Amazon S3.
Para ver los buckets disponibles, elija Buscar bucket de S3. Estos buckets están limitados por los permisos utilizados para configurar su cuenta de Studio Classic. También puede especificar un URI de Amazon S3 seleccionando Introducir la ubicación del bucket de Amazon S3.
sugerencia
Para obtener información sobre cómo dar formato a los datos de su bucket, seleccione Más información. La sección de descripción del modelo contiene información detallada sobre las entradas y salidas.
Para los modelos de texto:
-
El bucket debe tener un archivo data.csv.
-
La primera columna debe ser un entero único para la etiqueta de clase. Por ejemplo:
1,2,3,4,n -
La segunda columna debe ser una cadena.
-
La segunda columna debe tener el texto correspondiente que coincida con el tipo y el idioma del modelo.
Para los modelos de visión:
-
El bucket debe tener tantos subdirectorios como el número de clases.
-
Cada subdirectorio debe contener imágenes que pertenezcan a esa clase en formato .jpg.
nota
El bucket de Amazon S3 debe estar en el mismo Región de AWS lugar en el que se ejecuta SageMaker AI Studio Classic, ya que la SageMaker IA no permite solicitudes entre regiones.
Ajuste de la configuración de implementación
Se recomienda la familia p3 como la más rápida para el entrenamiento de aprendizaje profundo y se recomienda para ajustar un modelo. En el siguiente gráfico se muestra el número de instancias GPUs en cada tipo de instancia. Hay otras opciones disponibles entre las que puede elegir, incluidos los tipos de instancia p2 y g4.
| Tipo de instancia | GPUs |
|---|---|
| p3.2xlarge | 1 |
| p3.8xlarge | 4 |
| p3.16xlarge | 8 |
| p3dn.24xlarge | 8 |
Hiperparámetros
Puede personalizar los hiperparámetros del trabajo de entrenamiento que se utilizan para ajustar el modelo. Los hiperparámetros disponibles para cada modelo ajustable varían según el modelo. Para obtener información sobre cada hiperparámetro disponible, consulte la documentación de hiperparámetros del modelo que elija en Algoritmos integrados y modelos previamente entrenados en Amazon SageMaker. Por ejemplo, consulte Clasificación de imágenes: TensorFlow hiperparámetros para obtener más información sobre la clasificación de imágenes (hiperparámetros), que se puede ajustar con precisión. TensorFlow
Si usa el conjunto de datos predeterminado para los modelos de texto sin cambiar los hiperparámetros, obtendrá un modelo casi idéntico. En el caso de los modelos de visión, el conjunto de datos predeterminado es diferente del conjunto de datos utilizado para entrenar los modelos previamente entrenados, por lo que su modelo será diferente en consecuencia.
Los siguientes hiperparámetros son comunes entre los diversos modelos:
-
Época: una época es un ciclo que recorre todo el conjunto de datos. Varios intervalos completan un lote y, finalmente, varios lotes completan una época. Se ejecutan varias épocas hasta que la precisión del modelo alcanza un nivel aceptable o cuando la tasa de error cae por debajo de un nivel aceptable.
-
Tasa de aprendizaje: la cantidad que deben cambiar los valores entre épocas. A medida que se perfecciona el modelo, se modifican sus ponderaciones internas y se comprueban las tasas de error para ver si el modelo mejora. Una tasa de aprendizaje típica es de 0,1 o 0,01, donde 0,01 es un ajuste mucho menor y podría provocar que el entrenamiento tarde mucho en converger, mientras que 0,1 es mucho mayor y puede provocar que el entrenamiento se sobrepase. Es uno de los principales hiperparámetros que puede ajustar para entrenar su modelo. Tenga en cuenta que, en el caso de los modelos de texto, una tasa de aprendizaje mucho menor (5e-5 para BERT) puede dar como resultado un modelo más preciso.
-
Tamaño del lote: el número de registros del conjunto de datos que se van a seleccionar para cada intervalo y enviarlos al GPUs para su entrenamiento.
En un ejemplo de imagen, puede enviar 32 imágenes por GPU, por lo que 32 sería el tamaño del lote. Si eliges un tipo de instancia con más de una GPU, el lote se divide entre el número de GPUs. El tamaño de lote sugerido varía según los datos y el modelo que utilice. Por ejemplo, la forma en que optimiza los datos de imagen difiere de la forma en que gestiona los datos de idioma.
En el gráfico de tipos de instancia de la sección de configuración de despliegue, puedes ver el número de instancias GPUs por tipo de instancia. Comience con un tamaño de lote recomendado estándar (por ejemplo, 32 para un modelo de visión). Luego, multiplícalo por el número del GPUs tipo de instancia que seleccionaste. Por ejemplo, si usas un
p3.8xlarge, sería 32 (tamaño del lote) multiplicado por 4 (GPUs), lo que da un total de 128, ya que el tamaño del lote se ajusta al número de GPUs. Para un modelo de texto como BERT, intente empezar con un tamaño de lote de 64 y, a continuación, redúzcalo según sea necesario.
Salida del entrenamiento
Cuando se completa el proceso de ajuste, JumpStart proporciona información sobre el modelo: modelo principal, nombre del trabajo de entrenamiento, ARN del trabajo de entrenamiento, tiempo de entrenamiento y ruta de salida. En la ruta de salida puede encontrar su nuevo modelo en un bucket de Amazon S3. La estructura de carpetas usa el nombre del modelo que haya proporcionado y el archivo del modelo está en una subcarpeta /output y siempre tiene el nombre model.tar.gz.
Ejemplo: s3://bucket/model-name/output/model.tar.gz
Configuración de valores predeterminados para el entrenamiento de modelos
Puede configurar valores predeterminados para parámetros como las funciones de IAM y las claves de KMS para rellenarlos previamente para la implementación y el entrenamiento del modelo. VPCs JumpStart Para obtener más información, consulte Configure los valores predeterminados de los modelos JumpStart .
