Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
¿Qué es Step Functions?
Administrar el estado y transformar los datos
Obtenga información sobre cómo pasar datos entre estados con variables y cómo transformar datos con JSONata.
Con AWS Step Functionsél, puede crear flujos de trabajo, también denominadosMáquinas de estado, para crear aplicaciones distribuidas, automatizar procesos, organizar microservicios y crear canalizaciones de datos y aprendizaje automático.
Step Functions se basa en máquinas de estado y tareas. En Step Functions, las máquinas de estado se denominan flujos de trabajo y consisten en una serie de pasos controlados en eventos. Cada paso de un flujo de trabajo se denomina estado. Por ejemplo, el estado de una tarea representa una unidad de trabajo que realiza otro AWS servicio, como llamar a otro Servicio de AWS o a una API. Las instancias de flujos de trabajo en ejecución que realizan tareas se denominan ejecuciones en Step Functions.
El trabajo en las tareas de su máquina de estado también se puede realizar utilizando Actividades que son trabajadores que existen fuera de Step Functions.
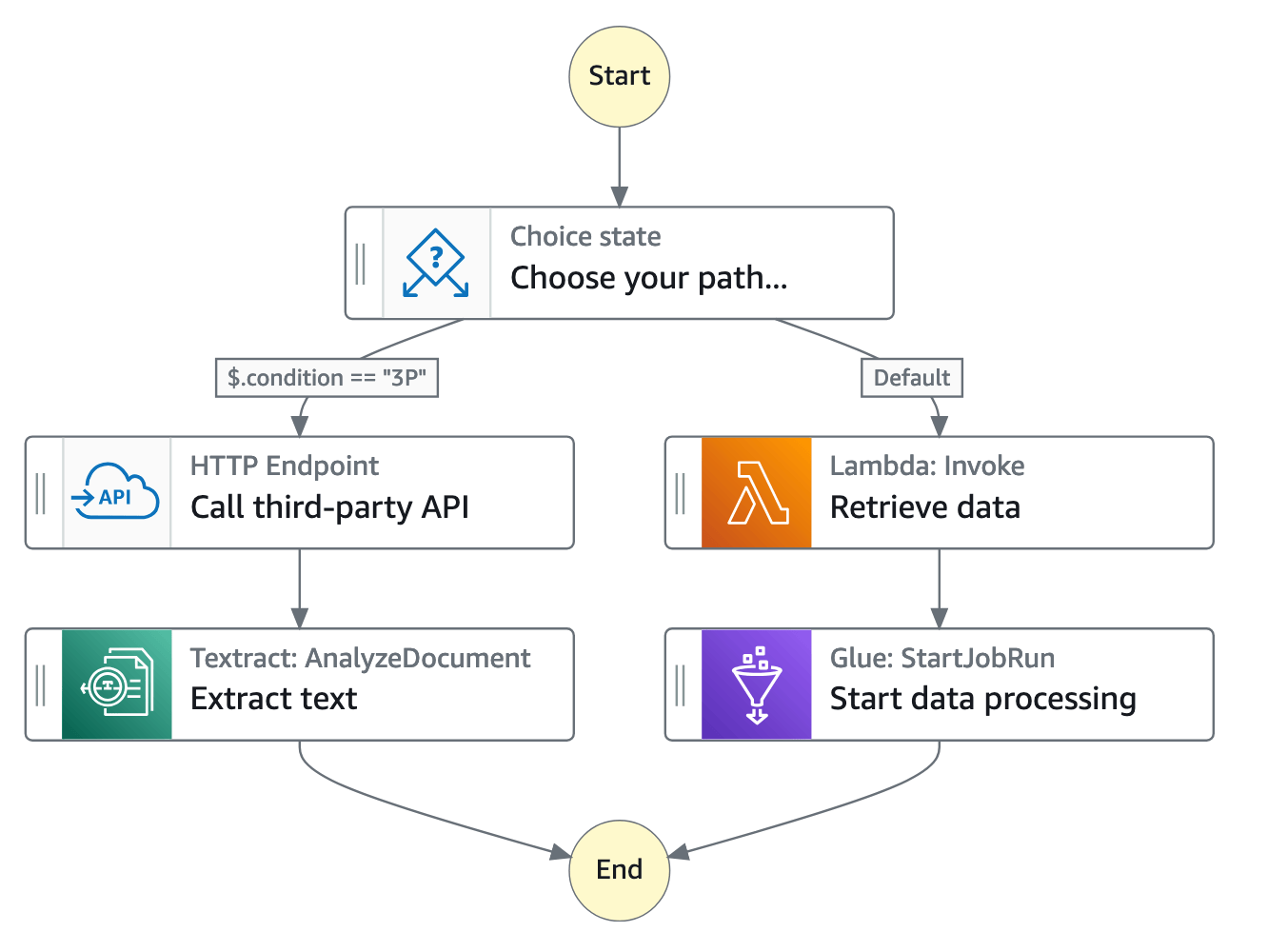
En la consola de Step Functions, puede visualizar, editar y depurar el flujo de trabajo de su aplicación. Puede examinar el estado de cada paso de su flujo de trabajo para asegurarse de que su aplicación se ejecuta en orden y según lo esperado.
Según su caso de uso, puede hacer que Step Functions llame a AWS servicios, como Lambda, para realizar tareas. Puede disponer de AWS servicios de control de Step Functions, por ejemplo AWS Glue, para crear flujos de trabajo de extracción, transformación y carga. También puede crear flujos de trabajo automatizados y de larga duración para aplicaciones que requieren la interacción humana.
Para obtener una lista completa de AWS las regiones en las que Step Functions está disponible, consulta la tabla de AWS
regiones
Aprenda a usar Step Functions
Comience con lo que se Tutorial introductorio indica en esta guía. Para obtener información sobre temas avanzados y casos de uso, consulte los módulos del taller The Step Functions
Tipos de flujos de trabajo estándar y rápidos
Step Functions tiene dos tipos de flujo de trabajo:
-
Los flujos de trabajo estándar son ideales para flujos de trabajo auditables y de larga duración, ya que muestran el historial de ejecución y la depuración visual.
Los flujos de trabajo estándar se ejecutan exactamente una vez y pueden durar hasta un año. Esto significa que cada paso de un flujo de trabajo estándar se ejecutará exactamente una vez.
-
Los flujos de trabajo exprés son ideales para high-event-rate cargas de trabajo, como el procesamiento de datos en streaming y la ingesta de datos de IoT.
Los flujos de trabajo exprés tienen una ejecución de at-least-onceflujo de trabajo y pueden ejecutarse durante un máximo de cinco minutos. Esto significa que uno o más pasos de un flujo de trabajo rápidos pueden ejecutarse más de una vez, mientras que cada paso del flujo de trabajo se ejecuta al menos una vez.
| Flujos de trabajo estándar | Flujos de trabajo rápidos |
|---|---|
| Índice de ejecución de 2000 por segundo | Índice de ejecución de 100 000 por segundo |
| Índice de transición de estado de 4000 por segundo | Índice de transición de estado casi ilimitada |
| Con precio por transición de estado | Precio por número y duración de las ejecuciones |
| Mostrar el historial de ejecución y la depuración visual | Mostrar el historial de ejecución y la depuración visual en función del nivel de registro |
| Consultar el historial de ejecución en Step Functions |
Envíe el historial de ejecución a CloudWatch |
| Compatibilidad con integraciones con todos los servicios. Compatibilidad con las integraciones optimizadas con algunos servicios. |
Compatibilidad con integraciones con todos los servicios. |
| Compatibilidad con un patrón de respuesta a solicitudes para todos los servicios Compatibilidad con los patrones Ejecutar un trabajo y/o Espere la devolución de la llamada en servicios específicos (consulte la siguiente sección para obtener más información) |
Compatibilidad con un patrón de respuesta a solicitudes para todos los servicios |
Para obtener más información acerca de los precios de Step Functions y de la elección del tipo de flujo de trabajo, consulte lo siguiente:
Integración con otros servicios de
Step Functions se integra con varios AWS servicios. Para llamar a otros AWS servicios, puede utilizar dos tipos de integración:
-
AWS Las integraciones del SDK proporcionan una forma de llamar a cualquier AWS servicio directamente desde tu máquina de estado, lo que te da acceso a miles de acciones de la API.
-
Las integraciones optimizadas ofrecen opciones personalizadas para usar esos servicios en sus máquinas de estado.
Para combinar Step Functions con otros servicios, hay tres patrones de integración de servicios:
-
Solicitar una respuesta (predeterminado)
Llame a un servicio y deje que Step Funciones avance al siguiente estado después de que obtenga una respuesta HTTP.
-
Llame a un servicio y haga que Step Functions espere a que finalice un trabajo.
-
Espera a que te devuelvan la llamada con un token de tarea (. waitForTaskSímbolo)
Llame a un servicio con un token de tarea y haga que Step Functions espere hasta que el token de tarea regrese con una devolución de llamada.
Los flujos de trabajo estándar y los flujos de trabajo rápidos son compatibles con las mismas integraciones, pero no con los mismos patrones de integración.
-
Los flujos de trabajo estándar admiten integraciones de Respuesta de la solicitud. Algunos servicios son compatibles con Run a Job (.sync) o Wait for Callback (. waitForTaskToken) y, en algunos casos, ambas cosas. Para obtener detalles, consulte la siguiente tabla de integraciones optimizadas.
-
Los flujos de trabajo rápidos solo admiten integraciones de Respuesta de la solicitud.
Para ayudarle a decidir entre los dos tipos, consulte Elegir el tipo de flujo de trabajo en Step Functions.
AWS Integraciones de SDK en Step Functions
| Servicio integrado | Respuesta de la solicitud | Ejecutar un trabajo: .sync | Espere a que Callback -. waitForTaskSímbolo |
|---|---|---|---|
| Más de doscientos servicios | Estándar y exprés | No compatible | Estándar |
Integraciones optimizadas en Step Functions
| Servicio integrado | Respuesta de la solicitud | Ejecutar un trabajo: .sync | Espere a que Callback -. waitForTaskSímbolo |
|---|---|---|---|
| Amazon API Gateway | Estándar y exprés | No compatible | Estándar |
| Amazon Athena | Estándar y exprés | Estándar | No compatible |
| AWS Batch | Estándar y exprés | Estándar | No compatible |
| Amazon Bedrock | Estándar y exprés | Estándar | Estándar |
| AWS CodeBuild | Estándar y exprés | Estándar | No compatible |
| Amazon DynamoDB | Estándar y exprés | No admitido | No admitido |
| Amazon ECS/Fargate | Estándar y exprés | Estándar | Estándar |
| Amazon EKS | Estándar y exprés | Estándar | Estándar |
| Amazon EMR | Estándar y exprés | Estándar | No compatible |
| Amazon EMR on EKS | Estándar y exprés | Estándar | No compatible |
| Amazon EMR Serverless | Estándar y exprés | Estándar | No compatible |
| Amazon EventBridge | Estándar y exprés | No compatible | Estándar |
| AWS Glue | Estándar y exprés | Estándar | No compatible |
| AWS Glue DataBrew | Estándar y exprés | Estándar | No compatible |
| AWS Lambda | Estándar y exprés | No compatible | Estándar |
| AWS Elemental MediaConvert | Estándar y exprés | Estándar | No compatible |
| Amazon SageMaker AI | Estándar y exprés | Estándar | No compatible |
| Amazon SNS | Estándar y exprés | No compatible | Estándar |
| Amazon SQS | Estándar y exprés | No compatible | Estándar |
| AWS Step Functions | Estándar y exprés | Estándar | Estándar |
Ejemplos de casos de uso de flujos de trabajo
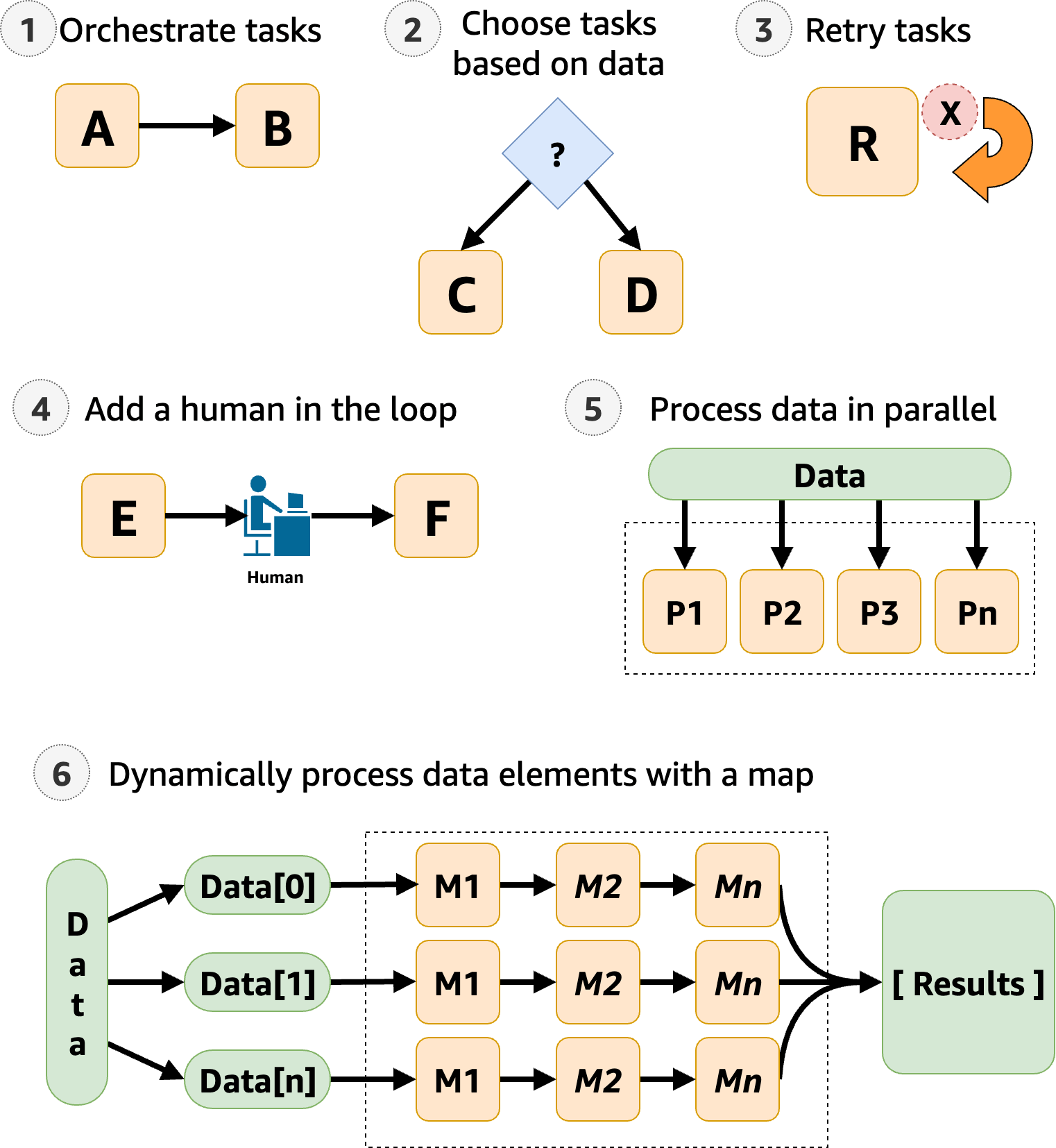
Step Functions gestiona los componentes y la lógica de la aplicación para que pueda escribir menos código y centrarse en crear y actualizar la aplicación rápidamente. La imagen siguiente muestra seis casos de uso de Step Functions.
-
Orquestar tareas: puede crear flujos de trabajo que organicen una serie de tareas o pasos en un orden específico. Por ejemplo, la tarea A podría ser una función de Lambda que proporciona entradas para otra función de Lambda de la tarea B. El último paso del flujo de trabajo arroja el resultado final.
-
Elegir tareas en función de los datos. Al usar un estado
Choice, puede hacer que Step Functions tome decisiones en función de las aportaciones del estado. Por ejemplo, imagine que un cliente solicita un aumento del límite de crédito. Si la solicitud supera el límite de crédito previamente aprobado por su cliente, puede hacer que Step Functions envíe la solicitud de su cliente a un administrador para que la apruebe. Si la solicitud es inferior al límite de crédito preaprobado por su cliente, puede hacer que Step Functions apruebe la solicitud automáticamente. -
Gestión de errores (
Retry/Catch): puede volver a intentar las tareas fallidas o detectar las tareas fallidas y ejecutar automáticamente pasos alternativos.Por ejemplo, después de que un cliente solicite un nombre de usuario, es posible que la primera llamada al servicio de validación falle, por lo que el flujo de trabajo podría volver a intentar la solicitud. Si la segunda solicitud se realiza correctamente, el flujo de trabajo puede continuar.
O bien, si el cliente solicitó un nombre de usuario no válido o no disponible, una instrucción
Catchpodría llevar a un paso del flujo de trabajo de Step Functions que sugiera un nombre de usuario alternativo.Para ver ejemplos de
RetryyCatch, consulte Control de errores en los flujos de trabajo de Step Functions. -
Humano en el bucle: Step Functions puede incluir pasos de aprobación humana en el flujo de trabajo. Por ejemplo, imagine que un cliente bancario intenta enviar fondos a un amigo. Con una llamada y un token de tarea, puede hacer que Step Functions espere hasta que el amigo del cliente confirme la transferencia y, a continuación, Step Functions continuará con el flujo de trabajo para notificar al cliente bancario que la transferencia se ha completado.
Para ver un ejemplo, consulta Creación de un ejemplo de patrón de devolución de llamada con Amazon SQS, Amazon SNS y Lambda.
-
Procesar datos en pasos paralelos: al usar un estado
Parallel, Step Functions puede procesar datos de entrada en pasos paralelos. Por ejemplo, un cliente podría necesitar convertir un archivo de video a varias resoluciones de pantalla, para que las personas espectadoras puedan verlo en varios dispositivos. Su flujo de trabajo podría enviar el archivo de vídeo original a varias funciones de Lambda o utilizar la AWS Elemental MediaConvert integración optimizada para procesar un vídeo en varias resoluciones de pantalla al mismo tiempo. -
Procesar de forma dinámica los elementos de datos: al usar un estado
Map, Step Functions puede ejecutar un conjunto de pasos de trabajo en cada elemento de un conjunto de datos. Las iteraciones se ejecutan en paralelo, lo que permite procesar un conjunto de datos rápidamente. Por ejemplo, cuando un cliente pide treinta artículos, el sistema debe aplicar el mismo flujo de trabajo para preparar cada artículo para su entrega. Una vez que todos los artículos se hayan reunido y empaquetado para su entrega, el siguiente paso podría ser enviar rápidamente al cliente un correo electrónico de confirmación con información de seguimiento.Para un ejemplo de plantilla de inicio, consulte Procesamiento de datos con un Map.
