Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Terminología y conceptos de Amazon Kinesis Data Streams
Antes de utilizar Amazon Kinesis Data Streams debe comprender su arquitectura y terminología.
Temas
Analizar la arquitectura de alto nivel de Kinesis Data Streams
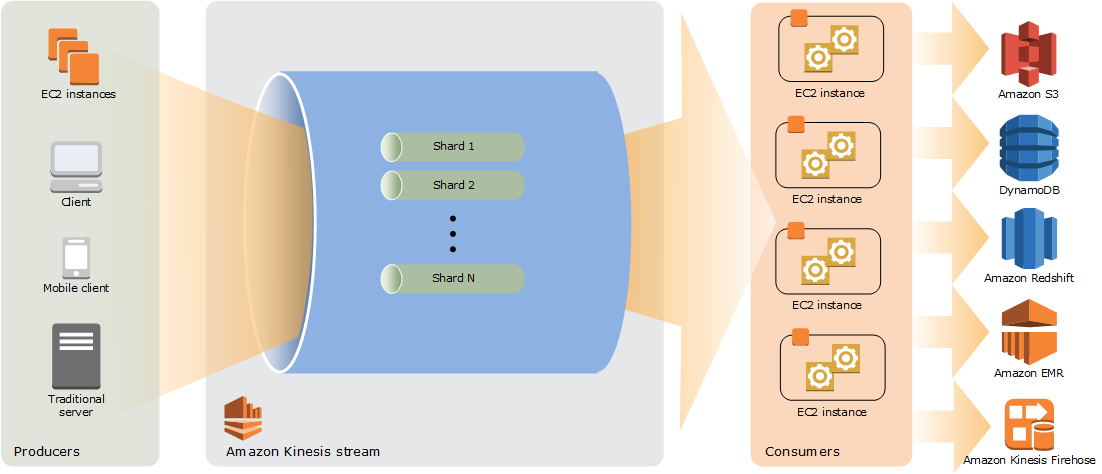
El siguiente diagrama ilustra la arquitectura de alto nivel de Kinesis Data Streams. Los productores envían datos continuamente a Kinesis Data Streams, mientras que los consumidores los procesan en tiempo real. Los consumidores (por ejemplo, una aplicación personalizada que se ejecute en Amazon EC2 o una transmisión de entrega de Amazon Data Firehose) pueden almacenar sus resultados mediante un AWS servicio como Amazon DynamoDB, Amazon Redshift o Amazon S3.
Conocer la terminología de Kinesis Data Streams
Kinesis Data Streams
Un flujo de datos de Kinesis es un conjunto de particiones. Cada fragmento tiene una secuencia de registros de datos. A su vez, cada registro de datos tiene un número de secuencia que asigna Kinesis Data Streams.
Registro de datos
Un registro de datos es la unidad de datos que se almacena en un flujo de datos de Kinesis. Los registros de datos se componen de un número de secuencia, una clave de partición y un blob de datos, que es una secuencia inmutable de bytes. Kinesis Data Streams no inspecciona, interpreta ni cambia los datos del blob de ninguna manera. Un blob de datos puede ser de hasta 1 MB.
Modo de capacidad
El modo de capacidad de un flujo de datos determina cómo se administra la capacidad y cómo se le cobra por el uso del flujo de datos. Actualmente, en Kinesis Data Streams, puede elegir entre un modo bajo demanda y un modo aprovisionado para los flujos de datos. Para obtener más información, consulte Elegir el modo correcto para el flujo.
Con el modo bajo demanda, Kinesis Data Streams administra automáticamente las particiones para proporcionar el rendimiento necesario. Solo se le cobrará por el rendimiento real que utilice y Kinesis Data Streams se adapta automáticamente a las necesidades de rendimiento de las cargas de trabajo a medida que aumentan o disminuyen. Para obtener más información, consulte Características y casos de uso del modo estándar bajo demanda.
Con el modo aprovisionado, debe especificar el número de particiones del flujo de datos. La capacidad total de un flujo de datos es la suma de las capacidades de las particiones. Puede aumentar o disminuir el número de particiones de un flujo de datos según sea necesario y se le cobrará una tarifa por hora según el número de particiones. Para obtener más información, consulte Características del modo aprovisionado y casos de uso.
Periodo de retención
El periodo de retención es el tiempo durante el cual se puede obtener acceso a los registros de datos después de que se agreguen a la secuencia. El periodo de retención de una secuencia se establece en un valor predeterminado de 24 horas tras su creación. Puede aumentar el período de retención hasta 8760 horas (365 días) mediante la IncreaseStreamRetentionPeriodoperación y reducir el período de retención hasta un mínimo de 24 horas mediante la operación. DecreaseStreamRetentionPeriod Para las secuencias con periodos de retención superiores a 24 horas se aplican cargos adicionales. Para obtener más información, consulte los precios de Amazon Kinesis Data Streams
Productor
Los productores colocan los registros en Amazon Kinesis Data Streams. Por ejemplo, un servidor web que envía datos de registro a una secuencia es un productor.
Consumidor
Los consumidores obtienen los registros de Amazon Kinesis Data Streams y los procesan. Estos consumidores se denominan Aplicación Amazon Kinesis Data Streams.
Aplicación Amazon Kinesis Data Streams
Una aplicación de Amazon Kinesis Data Streams es consumidor de un flujo que normalmente se ejecuta en una flota de instancias de EC2.
Es posible desarrollar dos tipos de consumidores: consumidores de distribución ramificada compartida y consumidores de distribución ramificada mejorada. Para conocer las diferencias entre ellos y saber cómo crear cada tipo de consumidor, consulte Leer datos de Amazon Kinesis Data Streams.
La salida de una aplicación de Kinesis Data Streams se puede utilizar como entrada para otro flujo, lo que permitirá crear topologías complejas que procesan datos en tiempo real. Una aplicación también puede enviar datos a una variedad de otros AWS servicios. Puede haber varias aplicaciones para una secuencia, y cada aplicación puede consumir datos procedentes de la secuencia de forma independiente y de forma simultánea.
Partición
Un fragmento es una sucesión de registros de datos identificados inequívocamente en una secuencia. Una secuencia consta de uno o varios fragmentos, cada uno de los cuales proporciona una unidad de capacidad fija. Cada partición puede admitir hasta 5 transacciones por segundo para las lecturas, hasta una velocidad máxima total de lectura de datos de 2 MB por segundo y hasta 1000 registros por segundo para las escrituras, hasta una velocidad máxima de escritura de datos total de 1 MB por segundo (incluidas las claves de partición). La capacidad de los datos de la secuencia es una función del número de fragmentos que especifique para la secuencia. La capacidad total de la secuencia es la suma de las capacidades de sus fragmentos.
Si su velocidad de transferencia de datos aumenta, puede incrementar o reducir el número de fragmentos asignados a su secuencia. Para obtener más información, consulte Cambiar las particiones de un flujo.
Clave de partición
Una clave de partición se utiliza para agrupar datos por partición en un flujo. Kinesis Data Streams divide los registros de datos que pertenecen a un flujo en varias particiones. Utiliza la clave de partición asociada a cada registro de datos para determinar a qué fragmento pertenece un registro de datos determinado. Las claves de partición son cadenas Unicode, con un límite de longitud máxima de 256 caracteres para cada clave. Se utiliza una función hash MD5 para asignar claves de partición a valores enteros de 128 bits y para asignar registros de datos asociados a fragmentos utilizando los rangos de claves hash de los fragmentos. Cuando una aplicación pone los datos en una secuencia, debe especificarse una clave de partición.
Sequence Number
Cada registro de datos tiene un número de secuencia único por clave de partición en su partición. Kinesis Data Streams asigna el número de secuencia después escribir en el flujo con client.putRecords o client.putRecord. Por lo general, los números secuenciales de una misma clave de partición aumentan con el paso del tiempo. Cuanto más largo sea el período de tiempo entre las solicitudes de escritura, mayores serán los números secuenciales.
nota
Los números secuenciales no se pueden utilizar como índices de conjuntos de datos dentro de la misma secuencia. Para separar lógicamente conjuntos de datos, utilice claves de partición o cree una secuencia independiente para cada conjunto de datos.
Kinesis Client Library
Kinesis Client Library se compila en la aplicación para permitir un consumo de datos tolerante a errores desde el flujo. Kinesis Client Library garantiza que para cada partición haya un procesador de registros que la ejecute y la procese. La biblioteca también simplifica la lectura de los datos desde la secuencia. Kinesis Client Library utiliza las tablas de Amazon DynamoDB para almacenar los metadatos relacionados con el consumo de datos. Crea tres tablas por cada aplicación que procesa datos. Para obtener más información, consulte Uso de Kinesis Client Library.
Nombre de la aplicación
El nombre de una aplicación de Amazon Kinesis Data Streams la identifica. Cada una de sus aplicaciones debe tener un nombre único que se ajuste a la AWS cuenta y la región utilizadas por la aplicación. Este nombre se utiliza como nombre para la tabla de control en Amazon DynamoDB y el espacio de nombres para las métricas de Amazon. CloudWatch
Server-Side Cifrado
Amazon Kinesis Data Streams puede cifrar la información confidencial automáticamente cuando un productor la introduce en un flujo. Kinesis Data Streams utiliza claves maestras de AWS KMS para el cifrado. Para obtener más información, consulte Protección de datos en Amazon Kinesis Data Streams.
nota
Para leer o escribir en una secuencia cifrada, las aplicaciones productoras y consumidoras deben tener permiso para obtener acceso a la clave maestra. Para obtener más información sobre la concesión de permisos para aplicaciones productoras y consumidoras, consulte Permisos para utilizar claves de KMS generadas por el usuario.
nota
El uso del cifrado del lado del servidor conlleva AWS Key Management Service ()AWS KMS costes. Para obtener más información, consulte Precios de AWS Key Management Service
