Para obtener capacidades similares a las de Amazon Timestream, considere Amazon Timestream LiveAnalytics para InfluxDB. Ofrece una ingesta de datos simplificada y tiempos de respuesta a las consultas en milisegundos de un solo dígito para realizar análisis en tiempo real. Obtenga más información aquí.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Optimización del acceso a datos en Amazon Timestream
Puede optimizar los patrones de acceso a los datos en Amazon Timestream mediante el esquema de particionamiento o técnicas de organización de datos de Timestream.
Esquema de particionamiento de Timestream
Amazon Timestream usa un esquema de particionamiento altamente escalable en el que cada tabla de Timestream puede tener cientos, miles o incluso millones de particiones independientes. Un servicio de indexación y seguimiento de particiones de alta disponibilidad gestiona la partición, lo que minimiza el impacto de los errores y hace que el sistema sea más resistente.
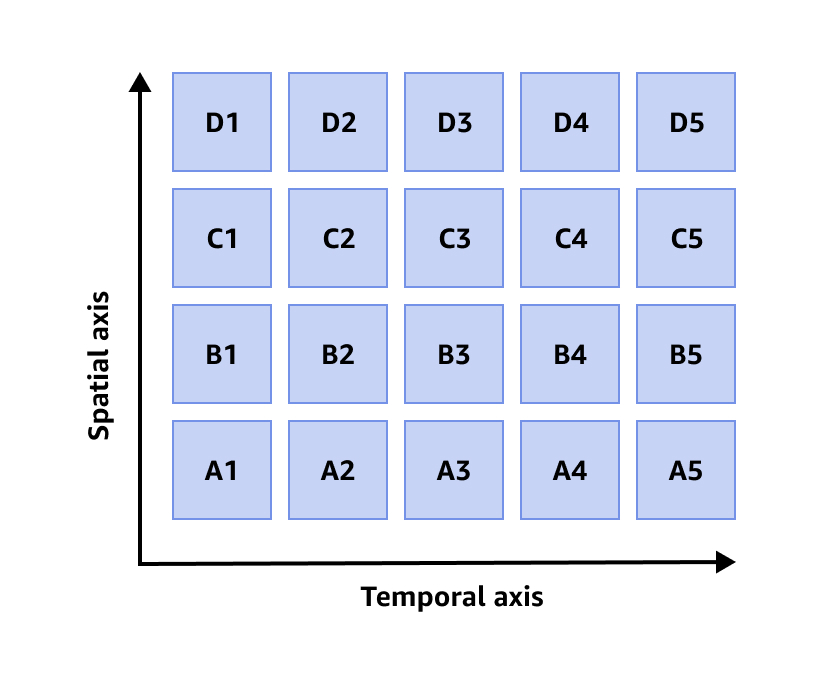
Organización de datos
Timestream almacena cada punto de datos que ingiere en una sola partición. Al introducir datos en una tabla Timestream, Timestream crea particiones de forma automática en función de las marcas de tiempo, la clave de partición y otros atributos de contexto de los datos. Además de particionar los datos a tiempo (partición temporal), Timestream también divide los datos en función de la clave de partición seleccionada y de otras dimensiones (partición espacial). Este enfoque permite distribuir el tráfico de escritura y podar de manera eficaz los datos para las consultas.
La característica de información sobre las consultas proporciona información valiosa sobre la eficiencia de la poda por parte de la consulta, que incluye las coberturas espacial y temporal de las consultas.
QuerySpatialCoverage
La QuerySpatialCoveragemétrica proporciona información sobre la cobertura espacial de la consulta ejecutada y de la tabla con la depuración espacial más ineficiente. Esta información puede ayudarlo a identificar las áreas que deben mejorarse en su estrategia de partición para mejorar la poda espacial. El valor de la métrica QuerySpatialCoverage oscila entre 0 y 1. Cuanto más bajo sea el valor de la métrica, más óptima será la poda de la consulta en el eje espacial. Por ejemplo, un valor de 0,1 indica que la consulta explora el 10 % del eje espacial. Un valor de 1 indica que la consulta escanea el 100 % del eje espacial.
ejemplo Uso de la información sobre las consultas para analizar la cobertura espacial de una consulta
Supongamos que tiene una base de datos de Timestream que almacena datos meteorológicos. Suponga que la temperatura se registra cada hora desde estaciones meteorológicas ubicadas en diferentes estados de los Estados Unidos. Imagine que elige State como una clave de partición definida por el cliente (CDPK) para particionar los datos por estado.
Supongamos que ejecuta una consulta para recuperar la temperatura media de todas las estaciones meteorológicas de California entre las 2 p. m. y las 4 p. m., de un día específico. El siguiente es un ejemplo de consulta para este escenario:
SELECT AVG(temperature) FROM "weather_data"."hourly_weather" WHERE time >= '2024-10-01 14:00:00' AND time < '2024-10-01 16:00:00' AND state = 'CA';
Con la característica de información sobre las consultas, puede analizar la cobertura espacial de la consulta. Imagine que la métrica QuerySpatialCoverage devuelve un valor de 0,02. Esto significa que la consulta solo escaneó el 2 % del eje espacial, lo que es eficiente. En este caso, la consulta pudo reducir el rango espacial de manera efectiva, ya que recuperó únicamente datos de California e ignoró los datos de otros estados.
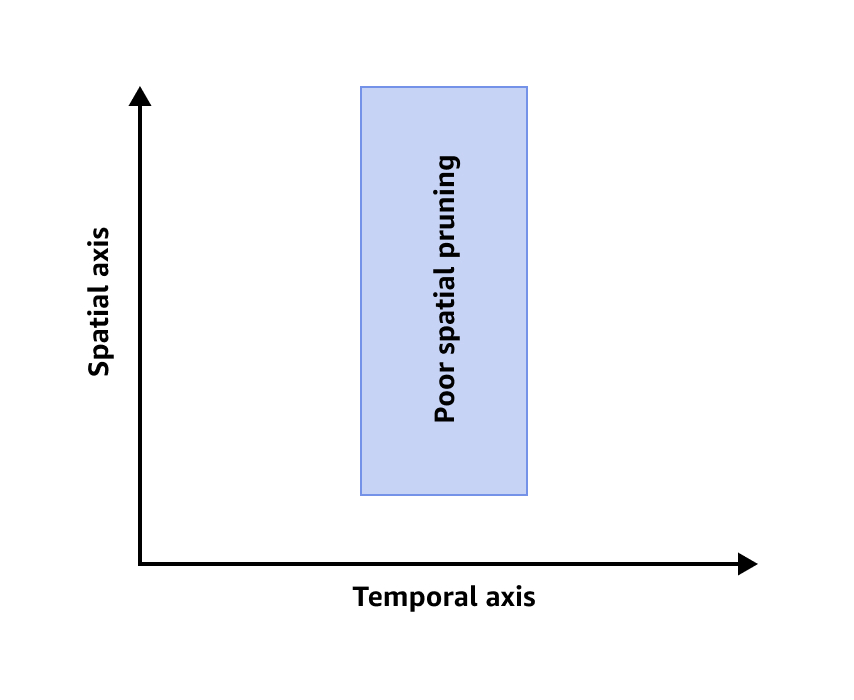
Por el contrario, si la métrica QuerySpatialCoverage devolviera un valor de 0,8, indicaría que la consulta escaneó el 80 % del eje espacial, lo que es menos eficiente. Esto podría sugerir que es necesario afinar la estrategia de partición para mejorar la poda espacial. Por ejemplo, puede seleccionar la clave de partición como ciudad o región en lugar de como estado. Con el análisis de la métrica QuerySpatialCoverage, puede identificar oportunidades para optimizar su estrategia de particionamiento y mejorar el rendimiento de sus consultas.
En la siguiente imagen, se muestra una poda espacial deficiente.
Para mejorar la eficiencia de la poda espacial, puede llevar a cabo una de las siguientes acciones o ambas:
-
Agregue
measure_name, la clave de partición predeterminada o use los predicados de la CDPK en la consulta. -
Si ya ha agregado los atributos que se mencionan en el punto anterior, elimine las funciones relacionadas con estos atributos o cláusulas, por ejemplo,
LIKE.
QueryTemporalCoverage
La métrica QueryTemporalCoverage proporciona información sobre el rango temporal que se explora con la consulta ejecutada, lo que incluye la tabla con el mayor rango de tiempo escaneado. El valor de la métrica QueryTemporalCoverage es el intervalo de tiempo representado en nanosegundos. Cuanto más bajo sea el valor de esta métrica, más óptima será la poda de la consulta en el rango temporal. Por ejemplo, una consulta que escanea los últimos minutos de datos es más eficaz que una consulta que escanea todo el intervalo de tiempo de la tabla.
ejemplo
Supongamos que tiene una base de datos de Timestream que almacena datos de sensores de IoT, con mediciones tomadas cada minuto desde dispositivos que se encuentran en una planta de fabricación. Suponga que ha dividido sus datos por device_ID.
Supongamos que ejecuta una consulta para recuperar la lectura media del sensor de un dispositivo específico durante los últimos 30 minutos. El siguiente es un ejemplo de consulta para este escenario:
SELECT AVG(sensor_reading) FROM "sensor_data"."factory_1" WHERE device_id = 'DEV_123' AND time >= NOW() - INTERVAL 30 MINUTE and time < NOW();
Con la característica de información sobre las consultas, puede analizar el rango temporal que escanea la consulta. Imagine que la métrica QueryTemporalCoverage devuelve un valor de 1800000000000 nanosegundos (30 minutos). Esto significa que la consulta solo escaneó los datos de los últimos 30 minutos, lo que constituye un intervalo temporal relativamente estrecho. Esto es una buena señal porque indica que la consulta pudo podar eficazmente la partición temporal y solo recuperó los datos que se solicitaron.
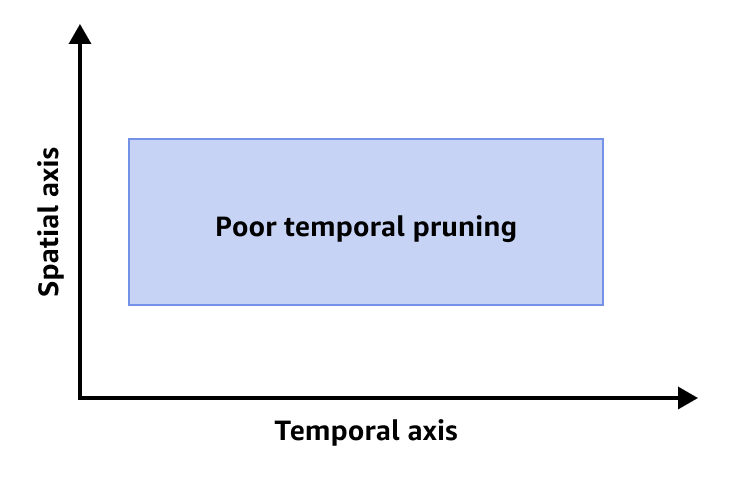
Por el contrario, si la métrica QueryTemporalCoverage arrojó un valor de 1 año en nanosegundos, indica que la consulta analizó un intervalo de tiempo de un año en la tabla, lo que resulta menos eficiente. Esto podría sugerir que la consulta no está optimizada para la poda temporal, por lo que podría mejorarla si añade filtros de tiempo.
En la siguiente imagen, se muestra una poda temporal deficiente.
Para mejorar la poda temporal, le recomendamos que realice una o todas las siguientes acciones:
-
Agregue los predicados de tiempo que faltan en la consulta y asegúrese de que estos poden el intervalo de tiempo deseado.
-
Elimine funciones relacionadas con los predicados de tiempo, como
MAX(). -
Agregue predicados de tiempo a todas las subconsultas. Esto es importante si las subconsultas unen tablas grandes o realizan operaciones complejas.
