REL10-BP01 Implementación de la carga de trabajo en varias ubicaciones
Distribuya los datos y los recursos de la carga de trabajo entre varias zonas de disponibilidad o, si es necesario, entre varias Regiones de AWS.
Un principio fundamental para el diseño de servicios en AWS es evitar puntos únicos de error, incluida la infraestructura física subyacente. AWS proporciona recursos y servicios de computación en la nube a nivel internacional en múltiples ubicaciones geográficas denominadas regiones. Cada región es independiente física y lógicamente y consta de tres o más zonas de disponibilidad (AZ). Las zonas de disponibilidad están geográficamente cerca unas de otras, pero están físicamente separadas y aisladas. Cuando distribuye sus cargas de trabajo entre las zonas y regiones de disponibilidad, mitiga el riesgo de amenazas como incendios, inundaciones, desastres relacionados con el clima, terremotos y errores humanos.
Cree una estrategia de ubicación para ofrecer una alta disponibilidad que sea adecuada para las cargas de trabajo.
Resultado deseado: las cargas de trabajo de producción se distribuyen entre varias zonas de disponibilidad (AZ) o regiones para lograr la tolerancia a los errores y una alta disponibilidad.
Patrones comunes de uso no recomendados:
-
La carga de trabajo de producción solo existe en una sola zona de disponibilidad.
-
Se implementa una arquitectura multirregional cuando una arquitectura Multi-AZ podría cumplir los requisitos empresariales.
-
Las implementaciones o los datos se desincronizan, lo que provoca cambios en la configuración o una replicación insuficiente de los datos.
-
No se tienen en cuenta las dependencias entre los componentes de la aplicación si los requisitos de resiliencia y de múltiples ubicaciones difieren entre esos componentes.
Beneficios de establecer esta práctica recomendada:
-
Su carga de trabajo es más resistente a los incidentes, como los cortes de energía o de control ambiental, los desastres naturales, los fallos del servicio previo o los problemas de red que afectan a una zona de disponibilidad o a toda una región.
-
Puede acceder a un inventario más amplio de instancias de Amazon EC2 y reducir la probabilidad de que se produzcan InsufentCapacityExceptions (ICE) al lanzar tipos de instancias EC2 específicos.
Nivel de riesgo expuesto si no se establece esta práctica recomendada: alto
Guía para la implementación
Implemente y opere todas las cargas de trabajo de producción en al menos dos zonas de disponibilidad (AZ) en una región.
Uso de varias zonas de disponibilidad
Las zonas de disponibilidad son ubicaciones de alojamiento de recursos que están separadas físicamente entre sí para evitar fallos correlacionados debidos a riesgos como incendios, inundaciones y tornados. Cada zona de disponibilidad tiene una infraestructura física independiente, que incluye conexiones eléctricas de servicios públicos, fuentes de energía de emergencia, servicios mecánicos y conectividad de red. Esta disposición limita los errores en cualquiera de estos componentes únicamente a la zona de disponibilidad afectada. Por ejemplo, si un incidente en toda la zona de disponibilidad hace que las instancias de EC2 no estén disponibles en la zona de disponibilidad afectada, las instancias de la otra zona de disponibilidad seguirán disponibles.
A pesar de estar separadas físicamente, las zonas de disponibilidad de la misma Región de AWS están lo suficientemente cerca como para proporcionar redes de alto rendimiento y baja latencia (milisegundos de un solo dígito). Puede replicar los datos de forma sincrónica entre las zonas de disponibilidad para la mayoría de las cargas de trabajo sin que ello afecte significativamente a la experiencia del usuario. Esto significa que puede utilizar las zonas de disponibilidad en una configuración activa/activa o activa/en espera.
Toda la computación asociada a su carga de trabajo debe distribuirse entre varias zonas de disponibilidad. Esto incluye instancias de Amazon EC2
También debe replicar los datos de su carga de trabajo y ponerlos a disposición en varias zonas de disponibilidad. Algunos servicios de datos gestionados de AWS, como Amazon S3
Si utiliza un almacenamiento autogestionado, como los volúmenes de Amazon Elastic Block Store (EBS)
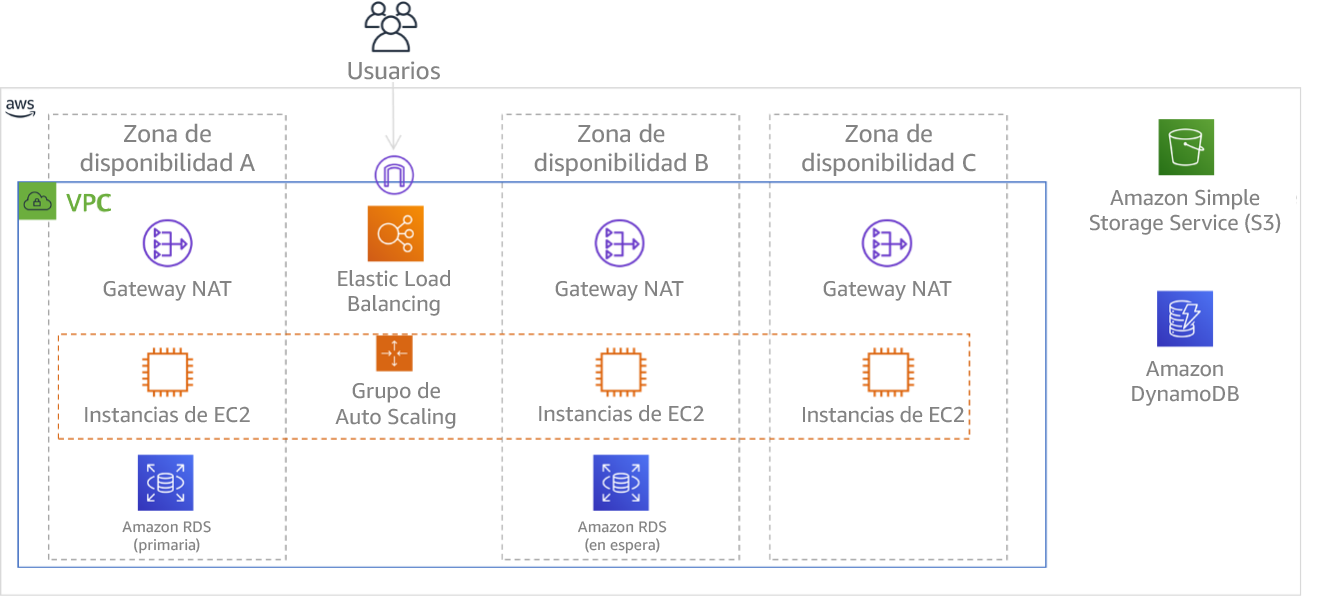
Figura 9: Arquitectura de varios niveles implementada en tres zonas de disponibilidad. Tenga en cuenta que Amazon S3 y Amazon DynamoDB siempre se implementan automáticamente en varias zonas de disponibilidad (Multi-AZ). El ELB también se implementa en las tres zonas.
Uso de múltiples Regiones de AWS
Si tiene cargas de trabajo que requieren una capacidad de recuperación extrema (como infraestructuras críticas, aplicaciones relacionadas con la salud o servicios con requisitos de disponibilidad estrictos u obligatorios por parte del cliente), es posible que necesite una disponibilidad adicional más allá de lo que puede ofrecer una sola Región de AWS. En este caso, debe implementar y operar su carga de trabajo en al menos dos Regiones de AWS (siempre que sus requisitos de residencia de datos lo permitan).
Las Regiones de AWS se encuentran en diferentes regiones geográficas de todo el mundo y en varios continentes. Las Regiones de AWS tienen una separación física y un aislamiento aún mayores que las zonas de disponibilidad por sí solas. Los servicios de AWS, con pocas excepciones, aprovechan este diseño para funcionar de forma totalmente independiente entre diferentes regiones (también conocidos como servicios regionales). El fallo de un servicio en una Región de AWS está diseñado para no afectar al servicio en una región diferente.
Cuando utilice su carga de trabajo en varias regiones, debe tener en cuenta requisitos adicionales. Como los recursos de las distintas regiones están separados y son independientes los unos de los otros, debe duplicar los componentes de la carga de trabajo en cada región. Esto incluye la infraestructura básica, como las VPC, además de los servicios de computación y de datos.
NOTA: Cuando se plantee un diseño multirregional, compruebe que su carga de trabajo sea capaz de ejecutarse en una sola región. Si crea dependencias entre regiones en las que un componente de una región depende de servicios o componentes de una región diferente, puede aumentar el riesgo de fallos y reducir considerablemente su nivel de fiabilidad.
Para facilitar las implementaciones multirregionales y mantener la coherencia, los AWS CloudFormation StackSets pueden replicar toda su infraestructura de AWS en varias regiones. AWS CloudFormation
También debe replicar los datos en cada una de las regiones que elija. Muchos servicios de datos gestionados de AWS ofrecen capacidad de replicación entre regiones, incluidos Amazon S3, Amazon DynamoDB, Amazon RDS, Amazon Aurora, Amazon Redshift, Amazon ElastiCache, y Amazon EFS. Las tablas globales de Amazon DynamoDB
AWS también ofrece la posibilidad de dirigir el tráfico de solicitudes a sus implementaciones regionales con gran flexibilidad. Por ejemplo, puede configurar sus registros DNS con Amazon Route 53
Incluso si decide no operar en varias regiones por motivos de alta disponibilidad, considere la posibilidad de hacerlo en varias regiones como parte de su estrategia de recuperación ante desastres (DR). Si es posible, replique los datos y los componentes de la infraestructura de su carga de trabajo en una configuración de espera activa o piloto ligero en una región secundaria. En este diseño, se replica la infraestructura de referencia de la región principal, como las VPC, los grupos de escalado automático, los orquestadores de contenedores y otros componentes, pero se configuran los componentes de tamaño variable de la región en espera (como el número de instancias de EC2 y réplicas de bases de datos) para que tengan un tamaño operativo mínimo. También puede organizar la replicación continua de los datos desde la región principal a la región en espera. Si se produce un incidente, puede escalar horizontalmente o aumentar los recursos de la región en espera y, después, convertirla en la región principal.
Pasos para la implementación
-
Coordínese con las partes interesadas de la empresa y los expertos en residencia de datos para determinar qué Regiones de AWS se pueden utilizar para alojar sus recursos y datos.
-
Contacte con las partes interesadas tanto a nivel técnico como empresarial para evaluar su carga de trabajo y determinar si sus necesidades de resiliencia pueden satisfacerse mediante un método Multi-AZ (una sola Región de AWS) o si requieren un enfoque multirregional (si se permiten varias regiones). El uso de varias regiones puede proporcionar una mayor disponibilidad, pero también puede suponer una complejidad y un coste adicionales. Tenga en cuenta los siguientes factores en la evaluación:
-
Objetivos empresariales y requisitos del cliente: ¿cuánto tiempo de inactividad se permite en caso de que se produzca un incidente que afecte a la carga de trabajo en una zona o región de disponibilidad? Evalúe los objetivos de puntos de recuperación, tal como se describe en REL13-BP01. Definición de objetivos de recuperación para el tiempo de inactividad y la pérdida de datos.
-
Requisitos de recuperación ante desastres (DR): ¿Contra qué tipo de posible desastre quiere asegurarse? Plantéese la posibilidad de que se produzcan pérdidas de datos o una falta de disponibilidad prolongada en diferentes ámbitos de impacto, desde una sola zona de disponibilidad hasta una región completa. Si replica los datos y los recursos en todas las zonas de disponibilidad y una sola zona de disponibilidad sufre un error prolongado, puede recuperar el servicio en otra zona de disponibilidad. Si replica los datos y los recursos en todas las regiones, puede recuperar el servicio en otra región.
-
-
Implemente los recursos informáticos en varias zonas de disponibilidad.
-
En la VPC, cree varias subredes en diferentes zonas de disponibilidad. Configure cada una de ellas para que sea lo suficientemente grande como para albergar los recursos necesarios para atender la carga de trabajo, incluso durante un incidente. Para obtener más información, consulte REL02-BP03 Garantía de que la asignación de subredes IP tenga en cuenta la expansión y la disponibilidad.
-
Si utiliza instancias de Amazon EC2, utilice EC2 Auto Scaling
para gestionar las instancias. Especifique las subredes que haya elegido en el paso anterior al crear los grupos de escalado automático. -
Si utiliza la computación de AWS Fargate para Amazon ECS o Amazon EKS, seleccione las subredes que haya elegido en el primer paso al crear un servicio de ECS, lanzar una tarea de ECS o crear un perfil de Fargate para EKS.
-
Si utiliza funciones de AWS Lambda que deben ejecutarse en su VPC, seleccione las subredes que haya elegido en el primer paso al crear la función de Lambda. Para cualquier función que no tenga una configuración de VPC, AWS Lambda administra la disponibilidad automáticamente por usted.
-
Coloque los directores de tráfico, como los equilibradores de carga, al frente de sus recursos informáticos. Si el equilibrio de carga entre zonas está activado, los equilibradores de carga de aplicaciones de AWS y los equilibradores de carga de red detectan si no es posible contactar con los destinos, como las instancias de EC2 y los contenedores, debido al deterioro de la zona de disponibilidad y redirigen el tráfico hacia los destinos que se encuentran en las zonas de disponibilidad en buen estado. Si inhabilita el equilibrio de carga entre zonas, utilice Amazon Application Recovery Controller (ARC) para proporcionar la capacidad de cambio de zona. Si utiliza un equilibrador de carga de terceros o ha implementado sus propios equilibradores de carga, configúrelos con múltiples interfaces en diferentes zonas de disponibilidad.
-
-
Replique los datos de la carga de trabajo en varias zonas de disponibilidad.
-
Si utiliza un servicio de datos gestionado de AWS, como Amazon RDS, Amazon ElastiCache o Amazon FSx, consulte detenidamente su guía del usuario para conocer sus capacidades de replicación y resiliencia de datos. Habilite la replicación entre zonas de disponibilidad y la conmutación por error si es necesario.
-
Si utiliza servicios de almacenamiento gestionados de AWS, como Amazon S3, Amazon EFS y Amazon FSx, evite utilizar configuraciones Single-AZ o One Zone para datos que requieran una gran durabilidad. Utilice una configuración Multi-AZ para estos servicios. Consulte la guía del usuario del servicio correspondiente para determinar si la replicación Multi-AZ está habilitada de forma predeterminada o si debe habilitarla.
-
Si ejecuta una base de datos, una cola u otro servicio de almacenamiento autogestionado, organice la replicación en zonas de disponibilidad múltiples según las instrucciones o las prácticas recomendadas de la aplicación. Familiarícese con los procedimientos de conmutación por error de su aplicación.
-
-
Configure su servicio de DNS para detectar el deterioro de la zona de disponibilidad y redirigir el tráfico a una zona de disponibilidad en buen estado. Amazon Route 53, en combinación con Elastic Load Balancers, puede hacerlo automáticamente. Route 53 también se puede configurar con registros de conmutación por error que utilizan comprobaciones de estado para responder a las consultas únicamente con direcciones IP en buen estado. En el caso de cualquier registro de DNS que se utilice para la conmutación por error, especifique un valor de tiempo de vida (TTL) corto (por ejemplo, 60 segundos o menos) para evitar que el almacenamiento en caché de los registros impida la recuperación (los registros de alias de Route 53 le proporcionan los TTL adecuados).
Pasos adicionales cuando se utilizan varias Regiones de AWS
-
Replique todo el código del sistema operativo (SO) y de la aplicación que utilice su carga de trabajo en las regiones seleccionadas. Replique las imágenes de máquina de Amazon (AMI) que utilizan sus instancias de EC2 si es necesario mediante soluciones como Generador de imágenes de Amazon EC2. Replique las imágenes de contenedores almacenadas en los registros mediante soluciones como la replicación entre regiones de Amazon ECR. Habilite la replicación regional para cualquier bucket de Amazon S3 que se utilice para almacenar los recursos de la aplicación.
-
Implemente sus recursos informáticos y metadatos de configuración (como los parámetros almacenados en el almacén de parámetros de AWS Systems Manager) en varias regiones. Utilice los mismos procedimientos descritos en los pasos anteriores, pero replique la configuración para cada región que utilice para su carga de trabajo. Utilice la infraestructura como soluciones de código, tales como AWS CloudFormation, para reproducir uniformemente las configuraciones entre las regiones. Si utiliza una región secundaria en una configuración piloto sencilla para la recuperación ante desastres, puede reducir la cantidad de recursos informáticos a un valor mínimo para ahorrar costes, con el consiguiente aumento del tiempo de recuperación.
-
Replique los datos de la región principal en las regiones secundarias.
-
Las tablas globales de Amazon DynamoDB proporcionan réplicas globales de sus datos que se pueden escribir desde cualquier región compatible. Con otros servicios de datos gestionados por AWS, como Amazon RDS, Amazon Aurora y Amazon Elasticache, se designa una región principal (lectura/escritura) y regiones de réplica (solo lectura). Consulte las guías de usuario y del desarrollador de los servicios respectivos para obtener más información sobre la replicación regional.
-
Si ejecuta una base de datos autogestionada, organice la replicación en varias regiones siguiendo las instrucciones o las prácticas recomendadas de la aplicación. Familiarícese con los procedimientos de conmutación por error de su aplicación.
-
Si la carga de trabajo utiliza AWS EventBridge, tal vez tenga que reenviar los eventos seleccionados de su región principal a las regiones secundarias. Para ello, especifique los buses de eventos de sus regiones secundarias como destinos de los eventos coincidentes en su región principal.
-
-
Piense si quiere utilizar claves de cifrado idénticas en todas las regiones y en qué medida. Un enfoque típico que equilibra la seguridad y la facilidad de uso consiste en utilizar claves de ámbito regional para los datos y la autenticación regionales y locales y utilizar claves de ámbito internacional para cifrar los datos que se replican entre distintas regiones. AWS Key Management Service (KMS)
admite claves de varias regiones para distribuir y proteger de forma segura las claves compartidas entre las regiones. -
Puede usar AWS Global Accelerator para mejorar la disponibilidad de la aplicación, que dirige el tráfico a regiones que contengan puntos de conexión en buen estado.
Recursos
Prácticas recomendadas relacionadas:
Documentos relacionados:
-
Amazon EC2 Auto Scaling: Ejemplo: Distribuir instancias entre zonas de disponibilidad
-
Cómo coloca Amazon ECS las tareas en las instancias de contenedor (incluido Fargate)
-
Tablas globales: replicación en varias regiones para DynamoDB
-
Amazon Elasticache para Redis OSS: Replicación en Regiones de AWS con almacenes de datos globales
-
Amazon Route 53: Configuración de la recuperación ante errores a nivel de DNS
-
Guía para desarrolladores del Controlador de recuperación de aplicaciones de Amazon (ARC)
-
Sending and receiving Amazon EventBridge events between Regiones de AWS
-
Serie de blogs Creating a Multi-Region Application with AWS Services
-
Disaster Recovery (DR) Architecture on AWS, Part III: Pilot Light and Warm Standby
Videos relacionados:
