What is Amazon Data Firehose?
Amazon Data Firehose is a fully managed service for delivering real-time streaming data
For more information about AWS big data solutions, see Big Data on AWS
Learn key concepts
As you get started with Amazon Data Firehose, you can benefit from understanding the following concepts.
- Firehose stream
-
The underlying entity of Amazon Data Firehose. You use Amazon Data Firehose by creating a Firehose stream and then sending data to it. For more information, see Tutorial: Create a Firehose stream from console and Send data to a Firehose stream.
- Record
-
The data of interest that your data producer sends to a Firehose stream. A record can be as large as 1,000 KB.
- Data producer
-
Producers send records to Firehose streams. For example, a web server that sends log data to a Firehose stream is a data producer. You can also configure your Firehose stream to automatically read data from an existing Kinesis data stream, and load it into destinations. For more information, see Send data to a Firehose stream.
- Buffer size and buffer interval
-
Amazon Data Firehose buffers incoming streaming data to a certain size or for a certain period of time before delivering it to destinations. Buffer Size is in MBs and Buffer Interval is in seconds.
Understand data flow in Amazon Data Firehose
For Amazon S3 destinations, streaming data is delivered to your S3 bucket. If data transformation is enabled, you can optionally back up source data to another Amazon S3 bucket.
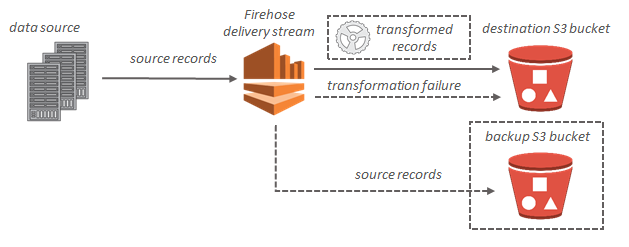
For Amazon Redshift destinations, streaming data is delivered to your S3 bucket first. Amazon Data Firehose then issues an Amazon Redshift COPY command to load data from your S3 bucket to your Amazon Redshift cluster. If data transformation is enabled, you can optionally back up source data to another Amazon S3 bucket.

For OpenSearch Service destinations, streaming data is delivered to your OpenSearch Service cluster, and it can optionally be backed up to your S3 bucket concurrently.

For Splunk destinations, streaming data is delivered to Splunk, and it can optionally be backed up to your S3 bucket concurrently.

