Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Journaux d'accès (journaux standard)
Vous pouvez configurer CloudFront pour créer des fichiers journaux contenant des informations détaillées sur chaque demande d'utilisateur (spectateur) CloudFront reçue. Ils sont appelés journaux d'accès, également appelés journaux standard.
Chaque journal contient des informations comme l’heure à laquelle la demande a été reçue, l’heure du traitement, les chemins de demande et les réponses du serveur. Vous pouvez utiliser ces journaux d’accès pour analyser les modèles de trafic et résoudre des problèmes.
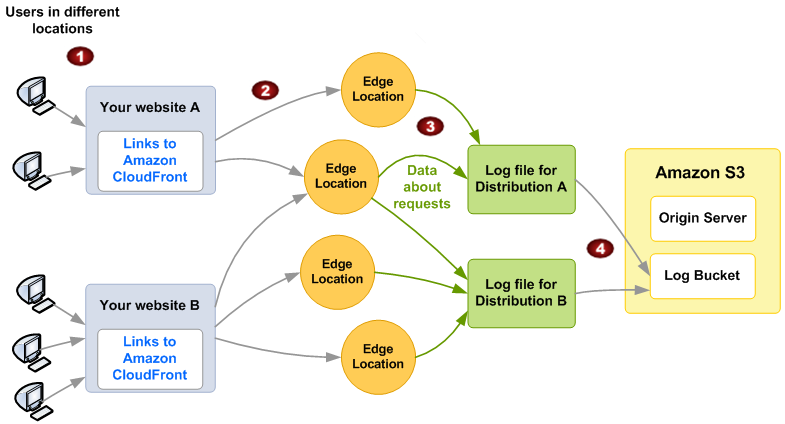
Le schéma suivant montre comment CloudFront enregistre les informations relatives aux demandes relatives à vos objets. Dans cet exemple, les distributions sont configurées pour envoyer les journaux d’accès vers un compartiment Amazon S3.
-
Dans cet exemple, vous avez deux sites Web, A et B, et deux CloudFront distributions correspondantes. Les utilisateurs demandent vos objets en utilisant URLs ceux qui sont associés à vos distributions.
-
CloudFront achemine chaque demande vers l'emplacement périphérique approprié.
-
CloudFront écrit les données relatives à chaque demande dans un fichier journal spécifique à cette distribution. Dans cet exemple, les informations sur les demandes associées à Distribution A vont dans un fichier journal réservé à Distribution A et celles sur les demandes associées à Distribution B dans un fichier journal réservé à Distribution B.
-
CloudFront enregistre régulièrement le fichier journal d'une distribution dans le compartiment Amazon S3 que vous avez spécifié lorsque vous avez activé la journalisation. CloudFront commence ensuite à enregistrer les informations relatives aux demandes suivantes dans un nouveau fichier journal pour la distribution.
Si aucun utilisateur n’accède à votre contenu pendant une heure donnée, vous ne recevez aucun fichier journal pour cette heure.
Note
Nous vous recommandons d'utiliser les journaux pour comprendre la nature des demandes concernant votre contenu, et non comme un compte rendu complet de toutes les demandes. CloudFront fournit des journaux d'accès dans la mesure du possible. L’entrée du journal pour une demande particulière peut être fournie bien après le traitement réel de la demande et, dans de rares cas, une entrée du journal peut ne pas être fournie du tout. Quand une entrée du journal est omise des journaux d'accès, le nombre d'entrées des journaux d'accès ne correspond pas à l'utilisation qui apparaît dans les rapports d'utilisation et de facturation AWS .
CloudFront prend en charge deux versions de journalisation standard. La journalisation standard (héritée) prend uniquement en charge l’envoi des journaux d’accès vers Amazon S3. La journalisation standard (v2) prend en charge des destinations de livraison supplémentaires. Vous pouvez configurer les deux options de journalisation, ou seulement l’une d’entre elles, pour votre distribution. Pour plus d’informations, consultez les rubriques suivantes :
Rubriques
Astuce
CloudFront propose également des journaux d'accès en temps réel, qui vous fournissent des informations sur les demandes adressées à une distribution en temps réel (les journaux sont livrés quelques secondes après réception des demandes). Vous pouvez utiliser les journaux d'accès en temps réel pour surveiller, analyser et prendre des mesures en fonction des performances de diffusion du contenu. Pour de plus amples informations, veuillez consulter Utiliser des journaux d'accès en temps réel.
