Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création d’un cluster de bases de données Aurora sans tête dans une région secondaire
Bien qu'une base de données globale Aurora nécessite au moins un cluster de base de données Aurora secondaire dans un cluster Région AWS différent du cluster principal, vous pouvez utiliser une configuration headless pour le cluster secondaire. Un cluster de bases de données Aurora secondaire sans tête est un cluster sans instance de base de données. Ce type de configuration peut réduire les dépenses d’une base de données Aurora globale. Dans un cluster de bases de données Aurora, le calcul et le stockage sont découplés. Sans l’instance de base de données, vous êtes facturé pour le stockage, mais pas pour le calcul. Si la configuration est correcte, le volume de stockage d’un cluster secondaire sans tête reste synchronisé avec le cluster de bases de données Aurora principal.
Ajoutez le cluster secondaire comme vous le faites normalement lors de la création d’une base de données Aurora globale. Si vous créez tous les clusters de la base de données globale, suivez la procédure décrite dans Création d’une base de données Amazon Aurora globale. Si vous avez déjà un cluster de bases de données à utiliser comme cluster principal, suivez la procédure décrite dans Ajouter un Région AWS vers une base de données mondiale Amazon Aurora.
Après que le cluster de bases de données Aurora principal commence la réplication vers le cluster secondaire, supprimez l’instance de base de données en lecture seule Aurora du cluster de bases de données Aurora secondaire. Ce cluster secondaire est désormais considéré comme « sans tête », car il n’a plus d’instance de base de données. Même sans instance de base de données dans le cluster secondaire, Aurora reste synchronisé avec le cluster de bases de données Aurora principal.
Avertissement
Avec Aurora PostgreSQL, pour créer un cluster headless dans un environnement Région AWS secondaire, utilisez l'API ou RDS pour AWS CLI ajouter le cluster secondaire. Région AWS Ignorez l’étape de création de l’instance de base de données de lecteur pour le cluster secondaire. Actuellement, la création d’un cluster sans tête n’est pas prise en charge dans la console RDS. Pour connaître les procédures CLI et API à utiliser, consultez Ajouter un Région AWS vers une base de données mondiale Amazon Aurora.
Si votre base de données globale utilise une version de moteur Aurora PostgreSQL antérieure à 13.4, 12.8 ou 11.13, la création d’une instance de base de données de lecteur dans une région secondaire, puis sa suppression peuvent entraîner un problème de vacuum Aurora PostgreSQL sur l’instance de base de données d’enregistreur de la région principale. Si vous rencontrez ce problème, redémarrez l’instance de base de données d’enregistreur de la région principale après avoir supprimé l’instance de base de données de lecteur de la région secondaire.
Ajouter un cluster de bases de données Aurora secondaire sans tête à votre base de données Aurora globale
Connectez-vous à la console Amazon RDS Console de gestion AWS et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Dans le volet de navigation du Console de gestion AWS, choisissez Databases.
-
Sélectionnez la base de données Aurora globale qui a besoin d’un cluster de bases de données Aurora secondaire. Assurez-vous que le cluster de bases de données Aurora principal est
Available. -
Pour Actions, choisissez Ajouter une AWS région.
-
Sur la page Ajouter une région, choisissez la région secondaire Région AWS.
Vous ne pouvez pas en choisir un Région AWS qui possède déjà un cluster de base de données Aurora secondaire pour la même base de données globale Aurora. De plus, il ne peut pas s’agir de la même région que le cluster de bases de données Aurora principal.
-
Complétez les champs restants pour le cluster Aurora secondaire dans le nouveau Région AWS. Il s’agit des mêmes options de configuration que pour n’importe quelle instance de cluster de bases de données Aurora.
Pour une base de données Aurora globale basée sur Aurora MySQL, ignorez l’option Activer le transfert d’écriture du réplica en lecture. Cette option n’a aucune fonction après la suppression de l’instance du lecteur.
Choisissez Ajouter une AWS région. Une fois que vous avez terminé d'ajouter la région à votre base de données globale Aurora, vous pouvez la voir dans la liste des bases de données, Console de gestion AWS comme indiqué sur la capture d'écran.

Vérifiez l'état du cluster de base de données Aurora secondaire et de son instance de lecteur avant de continuer, en utilisant le Console de gestion AWS ou le AWS CLI. Par exemple :
$aws rds describe-db-clusters --db-cluster-identifiersecondary-cluster-id--query '*[].[Status]' --output textPlusieurs minutes peuvent être nécessaires pour que l’état d’un cluster de bases de données Aurora secondaire nouvellement ajouté passe de
creatingàavailable. Lorsque le cluster de bases de données Aurora est disponible, vous pouvez supprimer l’instance de lecteur.Choisissez l’instance de lecteur dans le cluster de bases de données Aurora secondaire, puis choisissez Delete (Supprimer).

Après la suppression de l’instance de lecteur, le cluster secondaire continue à faire partie de la base de données globale Aurora. Aucune instance ne lui est associée, comme indiqué ci-dessous.
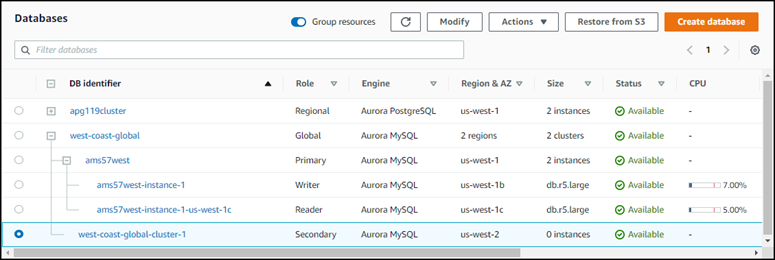
Vous pouvez utiliser ce cluster de bases de données Aurora secondaire sans tête pour restaurer manuellement votre base de données Amazon Aurora globale en cas d’interruption non planifiée dans la Région AWS principale.
