Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation du basculement ou du basculement dans la base de données globale Amazon Aurora
La fonction de base de données globale Aurora fournit une meilleure protection de continuité des activités et de reprise après sinistre (BCDR) que la haute disponibilité standard fournie par un cluster de base de données Aurora en un seul Région AWS. En utilisant la base de données mondiale Aurora, vous pouvez planifier une reprise plus rapide en cas de catastrophes régionales rares et imprévues ou en cas d'interruption rapide du niveau de service.
Vous pouvez consulter les directives et procédures suivantes pour planifier, tester et mettre en œuvre votre stratégie BCDR à l'aide de la fonctionnalité de base de données globale Aurora.
Rubriques
Planification de la continuité des activités et de la reprise après sinistre
Réalisation de commutations pour les bases de données globales Amazon Aurora
Reprise d'une base de données Amazon Aurora globale à partir d'une panne non planifiée
Gestion des bases RPOs de données globales basées sur Aurora PostgreSQL
Résilience interrégionale pour les clusters secondaires de bases de données mondiales
Planification de la continuité des activités et de la reprise après sinistre
Pour planifier votre stratégie de continuité des activités et de reprise après sinistre, il est utile de comprendre la terminologie sectorielle suivante et la manière dont ces termes sont liés aux fonctionnalités de la base de données mondiale Aurora.
La reprise après sinistre est généralement axée sur les deux objectifs stratégiques suivants :
-
Objectif de délai de reprise (RTO) : temps nécessaire à un système pour revenir à un état de fonctionnement après un sinistre ou une interruption de services. En d’autres termes, le RTO mesure les temps d’arrêt. Pour Aurora Global Database, le RTO peut être de l'ordre de quelques minutes.
-
Objectif de point de reprise (RPO) : quantité de données pouvant être perdue (mesurée dans le temps) après un sinistre ou une interruption de services. Cette perte de données est généralement due à un retard de réplication asynchrone. Pour une base de données Aurora globale, le RPO est généralement mesuré en secondes. Avec une base de données globale basée sur Aurora PostgreSQL–, vous pouvez utiliser le paramètre
rds.global_db_rpopour définir et suivre la limite supérieure du RPO, mais cela peut affecter le traitement des transactions sur le nœud d'écriture du cluster principal. Pour de plus amples informations, veuillez consulter Gestion des bases RPOs de données globales basées sur Aurora PostgreSQL.
L'exécution d'un basculement ou d'un basculement avec Aurora Global Database implique de promouvoir un cluster de base de données secondaire en tant que cluster de base de données principal. Le terme « panne régionale » est couramment utilisé pour décrire divers scénarios de défaillance. Le pire des scénarios pourrait être une panne généralisée due à un événement catastrophique qui toucherait des centaines de kilomètres carrés. Toutefois, la plupart des pannes sont beaucoup plus localisées et ne concernent qu'un petit sous-ensemble de services cloud ou de systèmes clients. Tenez compte de toute l'étendue de la panne pour vous assurer que le basculement entre régions est la bonne solution et pour choisir la méthode de basculement adaptée à la situation. L'utilisation de l'approche de basculement ou de commutation dépend du scénario de panne spécifique :
-
Basculement : utilisez cette approche pour récupérer après une panne imprévue. Avec cette approche, vous effectuez un basculement entre régions vers l'un des clusters de bases de données secondaires de votre base de données globale Aurora. Le RPO pour cette approche est généralement une valeur non nulle mesurée en secondes. L'ampleur de la perte de données dépend du délai global de réplication de la base de données Aurora Régions AWS au moment de la panne. Pour en savoir plus, consultez Reprise d'une base de données Amazon Aurora globale à partir d'une panne non planifiée.
-
Basculement : cette opération était auparavant appelée « basculement planifié géré ». Utilisez cette approche pour des scénarios contrôlés, tels que la maintenance opérationnelle et d'autres procédures opérationnelles planifiées dans lesquels tous les clusters Aurora et les autres services avec lesquels ils interagissent sont en bon état. Étant donné que cette fonction synchronise les clusters de base de données secondaires avec le cluster principal avant toute modification, le RPO est égal à 0 (aucune donnée perdue). Pour en savoir plus, consultez Réalisation de commutations pour les bases de données globales Amazon Aurora.
Note
Avant de pouvoir effectuer un basculement ou un basculement vers un cluster de base de données Aurora secondaire sans tête, vous devez y ajouter une instance de base de données. Pour plus d'informations sur les clusters de bases de données sans tête, consultez Création d'un cluster de base de données Aurora sans tête dans une région secondaire.
Réalisation de commutations pour les bases de données globales Amazon Aurora
Note
Les basculements étaient auparavant appelés basculements planifiés gérés.
En utilisant les switchovers, vous pouvez modifier régulièrement la région de votre cluster principal. Cette approche est destinée aux scénarios contrôlés tels que la maintenance opérationnelle et d'autres procédures opérationnelles planifiées.
Il existe trois cas d'utilisation courants pour l'utilisation des commutations.
-
Pour les exigences de « rotation régionale » imposées à des secteurs spécifiques. Par exemple, la réglementation des services financiers peut exiger que les systèmes de niveau 0 passent à une autre région pendant plusieurs mois afin de garantir que les procédures de reprise après sinistre sont régulièrement mises à l'épreuve.
-
Pour les applications « follow-the-sun » multirégionales. Par exemple, une entreprise peut souhaiter fournir une latence d'écriture plus faible dans différentes régions en fonction des heures d'ouverture dans différents fuseaux horaires.
-
Comme zero-data-loss méthode pour revenir à la région principale d'origine après un basculement.
Note
Les switchovers sont conçus pour être utilisés sur une base de données globale Aurora où tous les clusters Aurora et les autres services avec lesquels ils interagissent sont en bon état. Pour récupérer après une panne imprévue, suivez la procédure appropriée dans Reprise d'une base de données Amazon Aurora globale à partir d'une panne non planifiée.
Vous pouvez effectuer des commutations interrégionales gérées avec Aurora Global Database uniquement si les clusters de base de données principal et secondaire possèdent les mêmes versions de moteur majeures et secondaires. Selon le moteur et les versions du moteur, les niveaux de correctifs peuvent devoir être identiques ou les niveaux de correctif peuvent être différents. Pour obtenir la liste des moteurs et des versions de moteurs qui autorisent ces opérations entre les clusters principaux et secondaires avec différents niveaux de correctif, consultezCompatibilité des niveaux de correctif pour les commutations ou basculements entre régions gérés. Avant de commencer la commutation, vérifiez les versions du moteur de votre cluster global pour vous assurer qu'elles prennent en charge la commutation interrégionale gérée, et mettez-les à niveau si nécessaire.
Lors d'un changement, Aurora fait du cluster de la région secondaire que vous avez choisie votre cluster principal. Le mécanisme de commutation conserve la topologie de réplication existante de votre base de données globale : elle possède toujours le même nombre de clusters Aurora dans les mêmes régions. Avant qu'Aurora ne lance le processus de commutation, elle attend que tous les clusters de régions secondaires soient entièrement synchronisés avec le cluster de régions principal. Ensuite, le cluster de base de données de la région principale devient en lecture seule. Le cluster secondaire choisi fait passer l'un de ses nœuds en lecture seule au statut d'écrivain complet, ce qui permet à ce cluster secondaire de jouer le rôle de cluster principal. Tous les clusters secondaires ayant été synchronisés avec le principal au début du processus, le nouveau cluster principal poursuit les opérations de la base de données Aurora globale sans perdre de données. Votre base de données est indisponible pendant une courte période durant laquelle les clusters principaux et secondaires sélectionnés endossent leurs nouveaux rôles.
Note
Pour gérer les emplacements de réplication pour Aurora PostgreSQL après avoir effectué un basculement, consultez. Gestion des emplacements logiques pour Aurora Postgre SQL
Pour optimiser la disponibilité des applications, nous vous recommandons d'effectuer les opérations suivantes avant d'utiliser cette fonctionnalité :
-
Effectuez cette opération pendant les heures creuses ou à tout autre moment où les écritures sur le cluster de base de données principal sont minimales.
-
Vérifiez les temps de retard pour tous les clusters de bases de données Aurora secondaires de la base de données Aurora globale. Pour toutes les bases de données globales basées sur Aurora PostgreSQL et pour les bases de données globales basées sur Aurora MySQL à partir des versions du moteur 3.04.0 et supérieures ou 2.12.0 et supérieures, utilisez Amazon CloudWatch pour consulter la métrique pour tous les clusters de bases de données secondaires.
AuroraGlobalDBRPOLagPour les versions mineures inférieures des bases de données globales basées sur Aurora MySQL, consultez la métriqueAuroraGlobalDBReplicationLagà la place. Ces métriques indiquent le retard (en millisecondes) de la réplication vers un cluster secondaire par rapport au cluster de bases de données principal. Cette valeur est directement proportionnelle au temps nécessaire à Aurora pour terminer la commutation. Par conséquent, plus la valeur de retard est élevée, plus la commutation prendra de temps. Lorsque vous examinez ces métriques, faites-le à partir du cluster principal actuel.Pour plus d'informations sur CloudWatch les métriques pour Aurora, consultezMétriques de niveau cluster pour Amazon Aurora.
-
Le cluster de base de données secondaire promu lors d'une commutation peut avoir des paramètres de configuration différents de ceux de l'ancien cluster de base de données principal. Nous vous recommandons de veiller à ce que les types de paramètres de configuration suivants soient cohérents dans tous les clusters de vos clusters de bases de données globales Aurora. Cela permet de minimiser les problèmes de performances, les incompatibilités de charge de travail et les autres comportements anormaux après un passage au numérique.
-
Configurer le groupe de paramètres du cluster de base de données Aurora pour le nouveau cluster principal, si nécessaire — Lorsque vous promouvez un cluster de base de données secondaire pour qu'il prenne le rôle principal, le groupe de paramètres du cluster secondaire peut être configuré différemment de celui du cluster principal. Si c'est le cas, modifiez le groupe de paramètres du cluster de base de données secondaire promu afin qu'il soit conforme aux paramètres de votre cluster principal. Pour savoir comment procéder, consultez Modification des paramètres d'une base de données Aurora globale.
-
Configurez les outils et options de surveillance, tels que les CloudWatch événements et les alarmes Amazon : configurez le cluster de base de données promu avec la même capacité de journalisation, les mêmes alarmes, etc. que celles requises pour la base de données globale. Comme pour les groupes de paramètres, la configuration de ces fonctionnalités n'est pas héritée du cluster principal durant le processus de commutation. Certaines CloudWatch mesures, telles que le délai de réplication, ne sont disponibles que pour les régions secondaires. Ainsi, une commutation modifie la façon d'afficher ces métriques et de définir des alarmes sur celles-ci, et peut nécessiter d'apporter des modifications à des tableaux de bord prédéfinis. Pour plus d'informations sur les clusters de base de données Aurora et leur surveillance, consultezSurveillance des métriques RDS d' Amazon Aurora avec Amazon CloudWatch.
-
Configurez les intégrations avec d'autres AWS services : si votre base de données globale Aurora s'intègre à des AWS services tels que AWS Secrets Manager Amazon S3 AWS Lambda, assurez-vous de configurer vos intégrations avec ces services selon vos besoins. AWS Identity and Access Management Pour plus d'informations sur l'intégration de bases de données Aurora globales avec IAM, Simple Storage Service (Amazon S3) et Lambda, veuillez consulter Utilisation des bases de données globales Amazon Aurora avec d'autres services AWS. Pour en savoir plus sur Secrets Manager, consultez Comment automatiser la réplication des secrets dans AWS Secrets Manager Across Régions AWS
.
-
Si vous utilisez le point de terminaison Aurora Global Database Writer, vous n'avez pas besoin de modifier les paramètres de connexion dans votre application. Vérifiez que les modifications DNS se sont propagées et que vous pouvez vous connecter et effectuer des opérations d'écriture sur le nouveau cluster principal. Vous pouvez ensuite reprendre le fonctionnement complet de votre application.
Supposons que les connexions de vos applications utilisent le point de terminaison du cluster de l'ancien cluster principal, au lieu du point de terminaison global du rédacteur. Dans ce cas, assurez-vous de modifier les paramètres de connexion de votre application pour utiliser le point de terminaison du nouveau cluster principal. Si vous avez accepté les noms fournis lors de la création de la base de données Aurora globale, vous pouvez modifier le point de terminaison en supprimant la chaîne -ro du point de terminaison du cluster promu dans votre application. Par exemple, le point de terminaison du cluster secondaire my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com devient my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com lorsque ce cluster est promu cluster principal.
Si vous utilisez le proxy RDS, veillez à rediriger les opérations d'écriture de votre application vers le point de read/write endpoint of the proxy that's associated with the new primary cluster. This proxy endpoint might be the default endpoint or a custom read/write terminaison approprié. Pour plus d'informations, voir Fonctionnement des points de terminaison du proxy RDS avec les bases de données globales.
Vous pouvez effectuer une commutation de base de données globale Aurora à l'aide de l'API, de AWS Management Console AWS CLI, ou de l'API RDS.
Pour effectuer la commutation sur votre base de données globale Aurora
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Choisissez Databases et recherchez la base de données globale Aurora dans laquelle vous souhaitez effectuer le basculement.
-
Choisissez Commuter ou basculer vers la base de données globale dans le menu Actions.
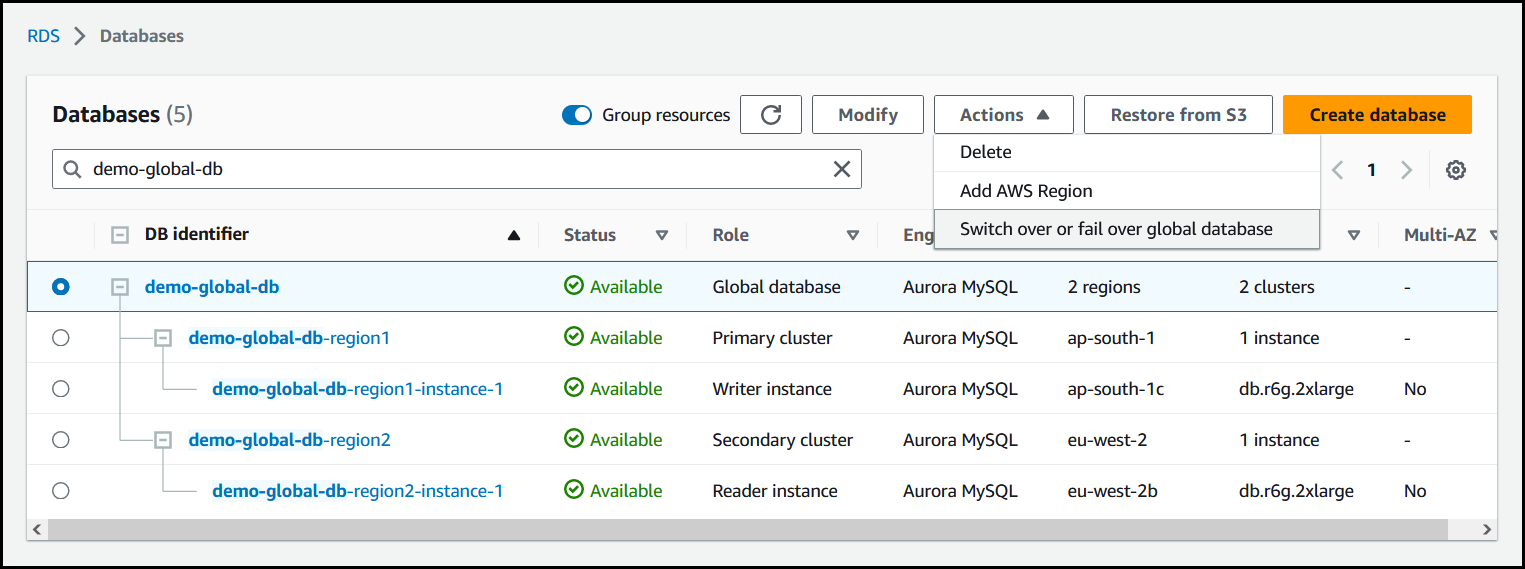
-
Choisissez Commutation.
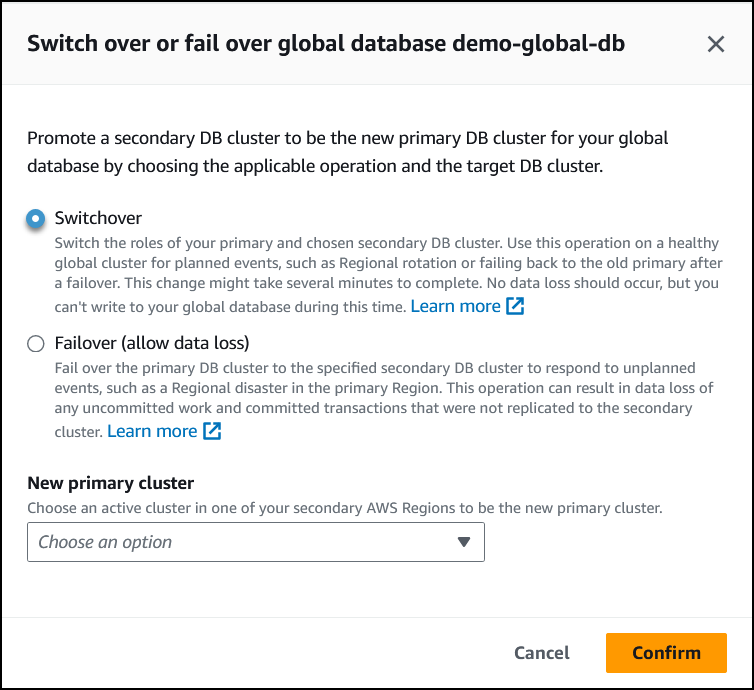
-
Pour Nouveau cluster principal, choisissez un cluster actif dans l'une de vos Régions AWS secondaires comme nouveau cluster principal.
-
Choisissez Confirmer.
Lorsque la commutation se termine, vous pouvez voir les clusters de bases de données Aurora et leurs rôles actuels dans la liste Bases de données, comme illustré dans l'image suivante.
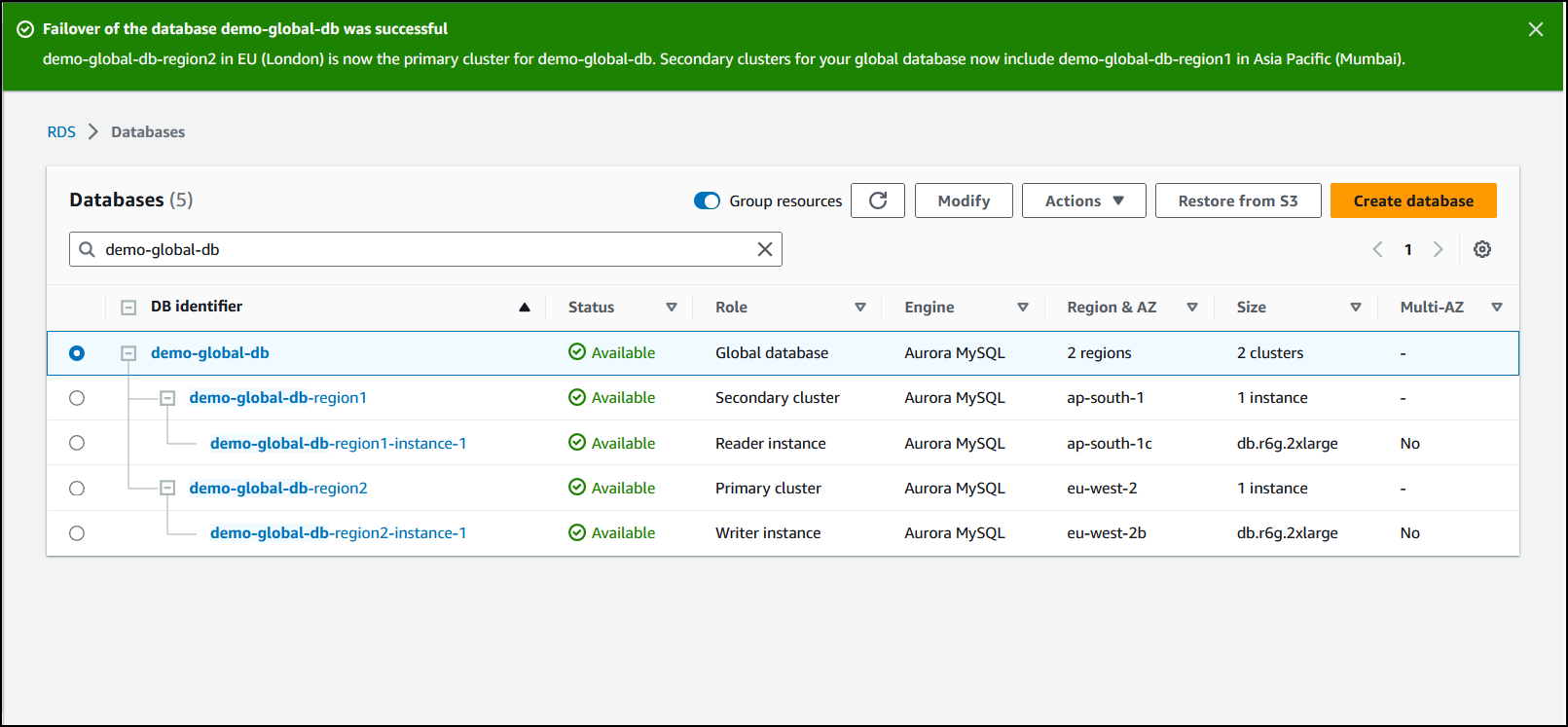
Pour effectuer la commutation sur votre base de données globale Aurora
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Choisissez Databases et recherchez la base de données globale Aurora dans laquelle vous souhaitez effectuer le basculement.
-
Choisissez Commuter ou basculer vers la base de données globale dans le menu Actions.
-
Choisissez Commutation.
-
Pour Nouveau cluster principal, choisissez un cluster actif dans l'une de vos Régions AWS secondaires comme nouveau cluster principal.
-
Choisissez Confirmer.
Lorsque la commutation se termine, vous pouvez voir les clusters de bases de données Aurora et leurs rôles actuels dans la liste Bases de données, comme illustré dans l'image suivante.
Pour effectuer la commutation sur une base de données globale Aurora
Utilisez la commande switchover-global-cluster CLI pour effectuer une commutation pour la base de données globale Aurora. Avec la commande, passez les valeurs pour les paramètres suivants.
-
--region— Spécifiez l' Région AWS endroit où s'exécute le cluster de base de données principal de la base de données globale Aurora. -
--global-cluster-identifier– Spécifiez le nom de votre base de données Aurora globale. -
--target-db-cluster-identifier– Spécifiez l'Amazon Resource Name (ARN) du cluster de base de données Aurora que vous souhaitez promouvoir comme cluster principal pour la base de données Aurora globale.
Dans Linux, macOS, ou Unix:
aws rds --regionregion_of_primary\ switchover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote
Dans Windows:
aws rds --regionregion_of_primary^ switchover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote
Pour effectuer une commutation pour la base de données globale Aurora, exécutez l'opération SwitchoverGlobalClusterAPI.
Reprise d'une base de données Amazon Aurora globale à partir d'une panne non planifiée
Dans de rares cas, votre base de données globale Aurora peut rencontrer une panne inattendue dans sa base de données principale Région AWS. Si cela se produit, votre cluster de bases de données Aurora principal et son nœud d'enregistreur ne sont pas disponibles, et la réplication entre les clusters de bases de données principal et secondaire s'interrompt. Pour minimiser les temps d'arrêt (RTO) et la perte de données (RPO), vous pouvez travailler rapidement pour effectuer un basculement entre régions.
Aurora Global Database propose deux méthodes de basculement que vous pouvez utiliser en cas de reprise après sinistre :
-
Basculement géré : cette méthode est recommandée pour la reprise après sinistre. Lorsque vous utilisez cette méthode, Aurora réintègre automatiquement l'ancienne région principale dans la base de données globale en tant que région secondaire lorsqu'elle redevient disponible. Ainsi, la topologie d'origine de votre cluster global est conservée. Pour apprendre à utiliser cette méthode, consultez Réalisation de basculements gérés pour les bases de données globales Aurora.
-
Basculement manuel : cette méthode alternative peut être utilisée quand le basculement géré n'est pas une option, par exemple quand vos régions principale et secondaire exécutent des versions de moteur incompatibles. Pour apprendre à utiliser cette méthode, consultez Réalisation de basculements manuels pour les bases de données globales Aurora.
Important
Les deux méthodes de basculement peuvent entraîner la perte de données de transaction d'écriture qui n'ont pas été répliquées dans la région secondaire choisie avant que le basculement se produise. Toutefois, le processus de récupération qui fait la promotion d'une instance de base de données sur le cluster de bases de données secondaire choisi comme instance de base de données principale d'enregistreur garantit que les données sont dans un état de cohérence transactionnelle. Les failovers sont également susceptibles de provoquer des problèmes de division cérébrale.
Réalisation de basculements gérés pour les bases de données globales Aurora
Cette approche vise à assurer la continuité des activités dans le cas d'une véritable catastrophe régionale ou interruption complète du niveau de service.
Lors d'un basculement géré, le cluster secondaire de la région secondaire que vous avez choisie devient le nouveau cluster principal. Le cluster secondaire choisi promeut l'un de ses nœuds en lecture seule au statut d'enregistreur complet. Cette étape permet au cluster d'endosser le rôle de cluster principal. Votre base de données est indisponible pendant une courte période pendant que ce cluster endosse son nouveau rôle. Dès que cette ancienne région principale est saine et à nouveau disponible, Aurora l'ajoute automatiquement au cluster mondial en tant que région secondaire. Ainsi, la topologie de réplication existante de votre base de données globale Aurora est conservée.
Note
Pour gérer les emplacements de réplication pour Aurora PostgreSQL après un basculement, consultez. Gestion des emplacements logiques pour Aurora Postgre SQL
Note
Vous pouvez effectuer des basculements interrégionaux gérés avec Aurora Global Database uniquement si les clusters de base de données principal et secondaire possèdent les mêmes versions de moteur majeures et secondaires. Selon le moteur et les versions du moteur, les niveaux de correctifs peuvent devoir être identiques ou les niveaux de correctif peuvent être différents. Pour obtenir la liste des moteurs et des versions de moteurs qui autorisent ces opérations entre les clusters principaux et secondaires avec différents niveaux de correctif, consultezCompatibilité des niveaux de correctif pour les commutations ou basculements entre régions gérés. Avant de commencer le basculement, vérifiez les versions du moteur de votre cluster global pour vous assurer qu'elles prennent en charge le basculement interrégional géré, et mettez-les à niveau si nécessaire. Si les versions de votre moteur nécessitent des niveaux de correctifs identiques mais exécutent des niveaux de correctif différents, vous pouvez effectuer le basculement manuellement en suivant les étapes décrites dansRéalisation de basculements manuels pour les bases de données globales Aurora.
Le basculement géré n'attend pas que les données soient synchronisées entre la région secondaire choisie et la région principale actuelle. Dans la mesure où la base de données globale Aurora réplique les données de manière asynchrone, il est possible que toutes les transactions ne soient pas répliquées dans la AWS région secondaire choisie avant que celle-ci ne soit promue pour accepter les fonctionnalités complètes de lecture/écriture.
Pour garantir la cohérence des données, Aurora crée un nouveau volume de stockage pour l'ancienne région principale après sa restauration. Avant de créer le nouveau volume de stockage dans la AWS région, Aurora tente de prendre un instantané de l'ancien volume de stockage au point de défaillance. Ainsi, vous pouvez restaurer l'instantané et récupérer toutes les données manquantes. Si cette opération aboutit, Aurora place cet instantané nommé rds:unplanned-global-failover- dans la section des instantanés du AWS Management Console. Vous pouvez également utiliser la name-of-old-primary-DB-cluster-timestampdescribe-db-cluster-snapshots AWS CLI commande ou l'opération DescribeDBClusterSnapshots API pour voir les détails de l'instantané.
Lorsque vous lancez un basculement géré, Aurora tente également d'arrêter le trafic d'écriture via la couche de stockage Aurora hautement disponible. Nous appelons ce mécanisme « clôture d'écriture ». Si le processus aboutit, Aurora émet un événement RDS vous indiquant que les écritures ont été arrêtées. Dans le cas peu probable de plusieurs défaillances de l'AZ dans une région, il est possible que le processus de délimitation des écritures ne réussisse pas à temps. Dans ce cas, Aurora émet un événement RDS vous informant que le délai imparti pour arrêter les écritures a expiré. Si l'ancien cluster principal est accessible sur le réseau, Aurora y enregistre ces événements. Dans le cas contraire, Aurora enregistre les événements sur le nouveau cluster principal. Pour en savoir plus sur ces événements, consultezÉvènements de cluster de base de données. Parce que l'écriture restreinte est une tentative de tous les moyens, il est possible que les écritures soient momentanément acceptées dans l'ancienne région principale, ce qui provoquerait des problèmes de division cérébrale.
Nous vous recommandons d'effectuer les tâches suivantes avant d'effectuer un basculement avec Aurora Global Database. Cela permet de minimiser le risque de problèmes de division cérébrale ou de récupération de données non répliquées à partir de l'instantané de l'ancien cluster principal.
-
Pour empêcher l'envoi d'écritures au cluster principal d'Aurora Global Database, mettez les applications hors ligne.
-
Assurez-vous que toutes les applications qui se connectent au cluster de base de données principal utilisent le point de terminaison global du rédacteur. La valeur de ce point de terminaison reste la même même lorsqu'une nouvelle région devient le cluster principal en raison d'un basculement ou d'un basculement. Aurora met en œuvre des mesures de protection supplémentaires afin de minimiser le risque de perte de données pour les opérations d'écriture soumises via le point de terminaison global. Pour plus d'informations sur les points de terminaison globaux du rédacteur, consultezConnexion à la base de données mondiale Amazon Aurora.
-
Si vous utilisez le point de terminaison global Writer et que votre application ou vos couches réseau mettent en cache les valeurs DNS, réduisez le time-to-live (TTL) de votre cache DNS à une valeur faible, telle que 5 secondes. Ainsi, votre application enregistre rapidement les modifications DNS auprès du point de terminaison global du rédacteur. Bien qu'Aurora tente de bloquer les écritures dans l'ancienne région principale, le succès de l'action n'est pas garanti. La réduction de la durée du cache DNS réduit encore le risque de problèmes de split-brain. Vous pouvez également rechercher l'événement RDS qui vous indique quand Aurora a observé les modifications DNS pour le point de terminaison global du rédacteur. Ainsi, vous pouvez vérifier que votre application a également enregistré la modification DNS avant de redémarrer le trafic d'écriture de votre application.
-
Vérifiez les temps de latence pour tous les clusters de base de données Aurora secondaires dans la base de données globale Aurora. Le choix de la région secondaire présentant le retard de réplication minimum peut minimiser les pertes de données avec la région principale actuellement défaillante.
Pour toutes les versions des bases de données globales basées sur Aurora PostgreSQL, et pour les bases de données globales basées sur Aurora MySQL à partir des versions du moteur 3.04.0 et supérieures ou 2.12.0 et supérieures, utilisez Amazon CloudWatch pour consulter la métrique pour tous les clusters de bases de données secondaires.
AuroraGlobalDBRPOLagPour les versions mineures inférieures des bases de données globales basées sur Aurora MySQL, consultez la métriqueAuroraGlobalDBReplicationLagà la place. Ces métriques indiquent le retard (en millisecondes) de la réplication vers un cluster secondaire par rapport au cluster de bases de données principal.Pour plus d'informations sur CloudWatch les métriques pour Aurora, consultezMétriques de niveau cluster pour Amazon Aurora.
Au cours d'un basculement géré, le cluster de bases de données secondaire choisi est promu dans son nouveau rôle de cluster principal. Toutefois, il n'hérite pas des différentes options de configuration du cluster de base de données principal. Une incompatibilité de configuration peut provoquer des problèmes de performances, des incompatibilités de charge de travail et d'autres comportements anormaux. Pour éviter de tels problèmes, nous vous recommandons de résoudre les différences entre vos clusters de bases de données Aurora globales pour les cas suivants :
-
Configurez le groupe de paramètres du cluster de base de données Aurora pour le nouveau principal, si nécessaire : vous pouvez configurer les groupes de paramètres de votre cluster de base de données Aurora indépendamment pour chaque cluster Aurora de votre base de données globale Aurora. Par conséquent, lorsque vous promouvez un cluster de bases de données secondaire pour endosser le rôle de cluster principal, le groupe de paramètres du cluster secondaire peut être configuré différemment de celui du cluster principal. Si c'est le cas, modifiez le groupe de paramètres du cluster de base de données secondaire promu afin qu'il soit conforme aux paramètres de votre cluster principal. Pour savoir comment procéder, consultez Modification des paramètres d'une base de données Aurora globale.
-
Configurez les outils et options de surveillance, tels que les CloudWatch événements et les alarmes Amazon : configurez le cluster de base de données promu avec la même capacité de journalisation, les mêmes alarmes, etc. que celles requises pour la base de données globale. Comme pour les groupes de paramètres, la configuration de ces fonctionnalités n'est pas héritée du cluster principal durant le processus de basculement. Certaines CloudWatch mesures, telles que le délai de réplication, ne sont disponibles que pour les régions secondaires. Ainsi, un basculement modifie la façon d'afficher ces métriques et de définir des alarmes sur celles-ci, et peut nécessiter d'apporter des modifications à des tableaux de bord prédéfinis. Pour plus d'informations sur la surveillance des clusters de base de données Aurora, consultezSurveillance des métriques RDS d' Amazon Aurora avec Amazon CloudWatch.
-
Configurer les intégrations avec d'autres AWS services — Si votre base de données globale Aurora s'intègre à d'autres AWS services AWS Secrets Manager AWS Identity and Access Management, tels qu'Amazon S3 AWS Lambda, vous devez vous assurer que ceux-ci sont configurés conformément aux exigences pour l'accès depuis n'importe quelle région secondaire. Pour plus d'informations sur l'intégration de bases de données Aurora globales avec IAM, Simple Storage Service (Amazon S3) et Lambda, veuillez consulter Utilisation des bases de données globales Amazon Aurora avec d'autres services AWS. Pour en savoir plus sur Secrets Manager, consultez Comment automatiser la réplication des secrets dans AWS Secrets Manager Across Régions AWS
.
Généralement, le cluster secondaire choisi endosse le rôle principal en quelques minutes. Dès que l'instance de base de données Writer de la nouvelle région principale est disponible, vous pouvez y connecter vos applications et reprendre vos charges de travail. Une fois qu'Aurora a promu le nouveau cluster principal, il reconstruit automatiquement tous les clusters de régions secondaires supplémentaires.
Comme les bases de données globales Aurora utilisent la réplication asynchrone, le retard de réplication dans chaque région secondaire peut varier. Aurora reconstruit ces régions secondaires pour qu'elles disposent exactement des mêmes point-in-time données que le nouveau cluster de régions principal. La durée de la tâche de reconstruction complète peut prendre de quelques minutes à plusieurs heures, selon la taille du volume de stockage et la distance entre les régions. Lorsque les clusters des régions secondaires ont fini de se reconstruire à partir de la nouvelle région principale, ils sont disponibles pour un accès en lecture.
Dès que le nouvel enregistreur principal est promu et disponible, le cluster de la nouvelle région principale peut gérer les opérations de lecture et d'écriture pour la base de données globale Aurora.
Si vous utilisez le point de terminaison global, il n'est pas nécessaire de modifier les paramètres de connexion dans votre application. Vérifiez que les modifications DNS se sont propagées et que vous pouvez vous connecter et effectuer des opérations d'écriture sur le nouveau cluster principal. Vous pouvez ensuite reprendre le fonctionnement complet de votre application.
Si vous n'utilisez pas le point de terminaison global, assurez-vous de modifier le point de terminaison de votre application afin d'utiliser le point de terminaison du cluster de base de données principal récemment promu. Si vous avez accepté les noms fournis lors de la création de la base de données Aurora globale, vous pouvez modifier le point de terminaison en supprimant la chaîne -ro du point de terminaison du cluster promu dans votre application.
Par exemple, le point de terminaison du cluster secondaire my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com devient my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com lorsque ce cluster est promu cluster principal.
Si vous utilisez le proxy RDS, veillez à rediriger les opérations d'écriture de votre application vers le point de read/write endpoint of the proxy that's associated with the new primary cluster. This proxy endpoint might be the default endpoint or a custom read/write terminaison approprié. Pour plus d'informations, voir Fonctionnement des points de terminaison du proxy RDS avec les bases de données globales.
Pour restaurer la topologie d'origine du cluster de bases de données global, Aurora surveille la disponibilité de l'ancienne région principale. Dès que cette région est saine et à nouveau disponible, Aurora l'ajoute automatiquement au cluster global en tant que région secondaire. Avant de créer le nouveau volume de stockage dans l'ancienne région principale, Aurora essaie de prendre un instantané de l'ancien volume de stockage au point de défaillance. Il le fait pour que vous puissiez l'utiliser pour récupérer les données manquantes. Si cette opération aboutit, Aurora crée un instantané nommérds:unplanned-global-failover-. Vous pouvez trouver cet instantané dans la section Instantanés du AWS Management Console. Vous pouvez également voir cet instantané répertorié dans les informations renvoyées par l'opération d'API DBClusterDescribe Snapshots. name-of-old-primary-DB-cluster-timestamp
Note
L'instantané de l'ancien volume de stockage est un instantané du système soumis à la période de conservation des sauvegardes configurée sur l'ancien cluster principal. Pour conserver cet instantané en dehors de la période de conservation, vous pouvez le copier pour l'enregistrer en tant qu'instantané manuel. Pour en savoir plus sur la copie des instantanés, y compris la tarification, consultez Copie d'instantanés de clusters de bases.
Une fois la topologie d'origine restaurée, vous pouvez rétablir votre base de données globale dans la région principale d'origine en effectuant une opération de commutation au moment qui convient le mieux à votre activité et à votre charge de travail. Pour ce faire, suivez les étapes de Réalisation de commutations pour les bases de données globales Amazon Aurora.
Vous pouvez effectuer un basculement avec la base de données globale Aurora à l'aide de l'API AWS Management Console, de AWS CLI, ou de l'API RDS.
Pour effectuer le basculement géré sur votre base de données globale Aurora
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Choisissez Databases et recherchez la base de données globale Aurora dans laquelle vous souhaitez effectuer le basculement.
-
Choisissez Commuter ou basculer vers la base de données globale dans le menu Actions.
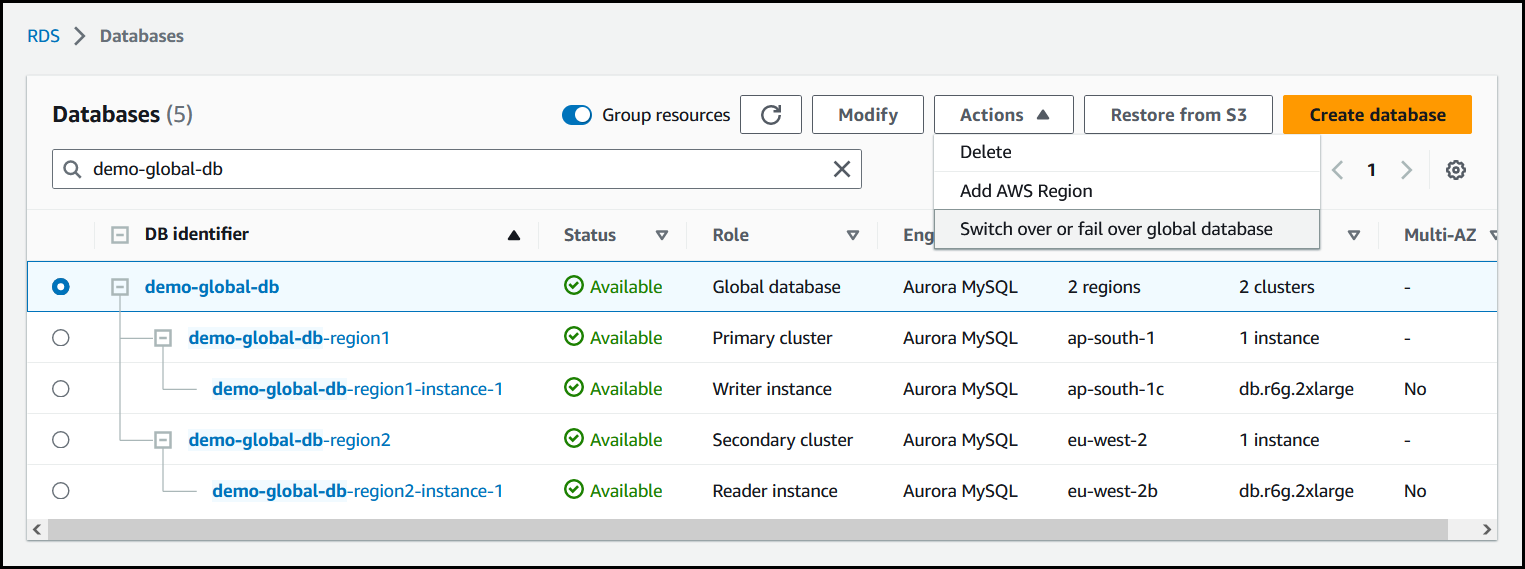
-
Choisissez Basculement (autoriser la perte de données).
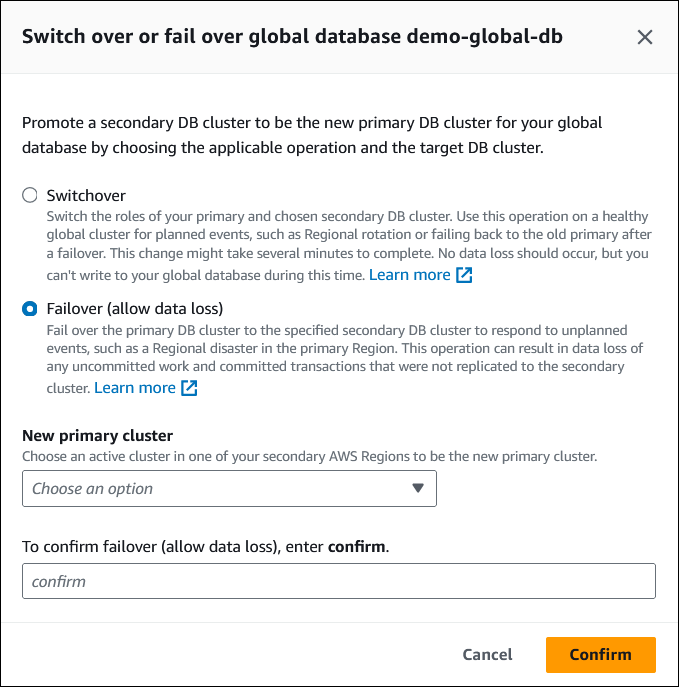
-
Pour Nouveau cluster principal, choisissez un cluster actif dans l'une de vos Régions AWS secondaires comme nouveau cluster principal.
-
Saisissez
confirm, puis choisissez Confirmer.
Une fois le basculement terminé, vous pouvez afficher les clusters de base de données Aurora et leur état actuel dans la liste des bases de données, comme illustré dans l'image suivante.
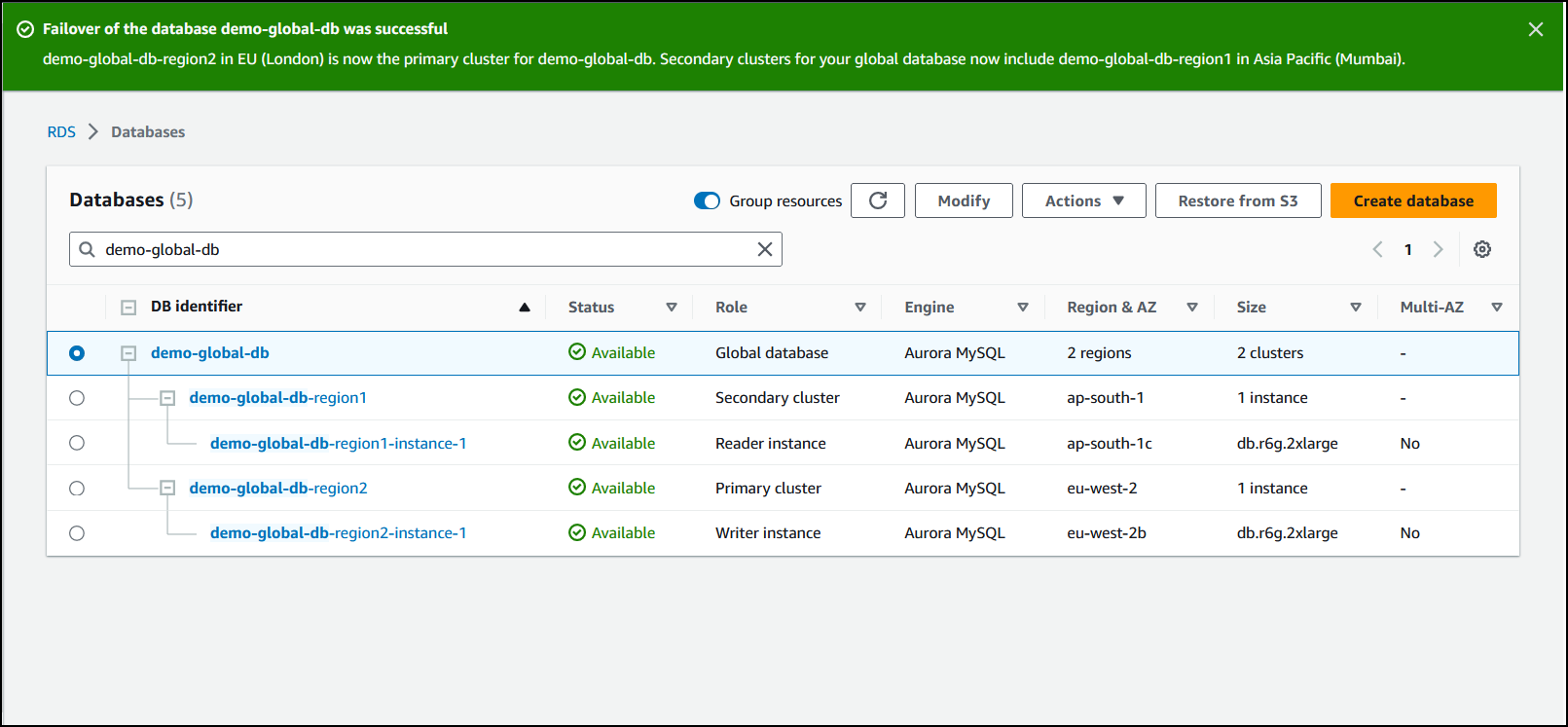
Pour effectuer le basculement géré sur votre base de données globale Aurora
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Choisissez Databases et recherchez la base de données globale Aurora dans laquelle vous souhaitez effectuer le basculement.
-
Choisissez Commuter ou basculer vers la base de données globale dans le menu Actions.
-
Choisissez Basculement (autoriser la perte de données).
-
Pour Nouveau cluster principal, choisissez un cluster actif dans l'une de vos Régions AWS secondaires comme nouveau cluster principal.
-
Saisissez
confirm, puis choisissez Confirmer.
Une fois le basculement terminé, vous pouvez afficher les clusters de base de données Aurora et leur état actuel dans la liste des bases de données, comme illustré dans l'image suivante.
Pour effectuer le basculement géré sur une base de données globale Aurora
Utilisez la commande failover-global-cluster CLI pour effectuer un basculement avec la base de données globale Aurora. Avec la commande, passez les valeurs pour les paramètres suivants.
-
--region— Spécifiez l' Région AWS endroit où s'exécute le cluster de base de données secondaire que vous souhaitez utiliser comme nouveau principal pour la base de données globale Aurora. -
--global-cluster-identifier– Spécifiez le nom de votre base de données Aurora globale. -
--target-db-cluster-identifier: spécifiez l'Amazon Resource Name (ARN) du cluster de bases de données Aurora que vous souhaitez promouvoir comme nouveau cluster principal pour la base de données globale Aurora. -
--allow-data-loss: faites-en explicitement une opération de basculement à la place d'une opération de commutation. Une opération de basculement peut entraîner une certaine perte de données si les composants de réplication asynchrone n'ont pas terminé d'envoyer toutes les données répliquées vers la région secondaire.
Dans Linux, macOS, ou Unix:
aws rds --regionregion_of_selected_secondary\ failover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote\ --allow-data-loss
Dans Windows:
aws rds --regionregion_of_selected_secondary^ failover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote^ --allow-data-loss
Pour effectuer un basculement avec Aurora Global Database, exécutez l'opération FailoverGlobalClusterAPI.
Réalisation de basculements manuels pour les bases de données globales Aurora
Dans certains scénarios, vous ne pourrez peut-être pas utiliser le processus de basculement géré. Par exemple, si vos clusters de bases de données principal et secondaire n'exécutent pas des versions de moteur compatibles. Dans ce cas, vous pouvez suivre ce processus manuel pour effectuer un basculement vers votre région secondaire cible.
Astuce
Nous vous recommandons de comprendre ce processus avant de l'utiliser. Ayez un plan prêt pour agir rapidement au premier signe de problème à l'échelle de la région. Vous pouvez être prêt à identifier la région secondaire présentant le moins de retard de réplication en utilisant Amazon CloudWatch régulièrement pour suivre les temps de latence des clusters secondaires. Veillez à tester votre plan pour vérifier que vos procédures sont complètes et précises, et que le personnel est formé pour effectuer un basculement de reprise après sinistre avant que le cas de figure se présente réellement.
Pour effectuer un basculement manuel vers un cluster secondaire après une panne imprévue dans la région principale
-
Arrêtez l'émission d'instructions DML et toute autre opération d'écriture vers le cluster de base de données Aurora principal dans la Région AWS concernée par l'interruption.
-
Identifiez un cluster de base de données Aurora à partir d'un cluster de base de données secondaire Région AWS à utiliser comme nouveau cluster de base de données principal. Si votre base de données globale Aurora comporte Régions AWS au moins deux clusters secondaires, choisissez le cluster secondaire présentant le moins de retard de réplication.
-
Détachez le cluster de base de données secondaire choisi de la base de données Aurora globale.
La suppression d'un cluster de base de données secondaire d'une base de données Aurora globale interrompt immédiatement la réplication du cluster principal vers le cluster secondaire et le promeut en cluster de base de données Aurora provisionné autonome avec des capacités complètes en lecture/écriture. Tous les autres clusters de bases de données Aurora secondaires associés au cluster principal dans la région concernée par la panne restent disponibles et peuvent accepter les appels de votre application. Ils consomment également des ressources. Puisque vous recréez la base de données Aurora globale, supprimez les autres clusters de bases de données secondaires avant de créer la nouvelle base de données Aurora globale dans les étapes suivantes. Cela évite les incohérences de données parmi les clusters de bases de données de la base de données Aurora globale (problèmes de split-brain).
Afin d'obtenir les étapes détaillées du détachement, consultez Dissociation d'un cluster d'une base de données Amazon Aurora globale.
-
Reconfigurez votre application pour envoyer toutes les opérations d'écriture à ce cluster de base de données Aurora désormais autonome à l'aide de son nouveau point de terminaison. Si vous avez accepté les noms fournis lors de la création de la base de données Aurora globale, vous pouvez modifier le point de terminaison en supprimant la chaîne
-rodu point de terminaison du cluster promu dans votre application.Par exemple, le point de terminaison du cluster secondaire
my-global.cluster-ro-aaaaaabbbbbb---us-west-1---rds.amazonaws.com.rproxy.goskope.comdevientmy-global---cluster-aaaaaabbbbbb---us-west-1---rds.amazonaws.com.rproxy.goskope.comlorsque ce cluster est détaché de la base de données Aurora globale.Ce cluster de base de données Aurora devient le cluster principal d'une nouvelle base de données Aurora globale lorsque vous commencez à y ajouter des Régions lors de l'étape suivante.
Si vous utilisez le proxy RDS, veillez à rediriger les opérations d'écriture de votre application vers le point de read/write endpoint of the proxy that's associated with the new primary cluster. This proxy endpoint might be the default endpoint or a custom read/write terminaison approprié. Pour plus d'informations, voir Fonctionnement des points de terminaison du proxy RDS avec les bases de données globales.
-
Ajoutez un Région AWS au cluster de base de données. Lorsque vous effectuez cette opération, le processus de réplication du cluster primaire vers le cluster secondaire commence. Afin d'obtenir les étapes détaillées pour ajouter une région, consultez Ajouter un Région AWS à une base de données globale Amazon Aurora.
-
Ajoutez-en Régions AWS d'autres si nécessaire pour recréer la topologie requise pour prendre en charge votre application.
Assurez-vous que les écritures d'application sont envoyées au cluster de base de données Aurora approprié avant, pendant et après l'application de ces modifications. Cela évite les incohérences de données parmi les clusters de bases de données de la base de données Aurora globale (problèmes de split-brain).
Si vous l'avez reconfiguré en réponse à une panne dans un Région AWS, vous pouvez en faire à nouveau Région AWS le serveur principal une fois la panne résolue. Pour ce faire, vous ajoutez l'ancienne base de données Région AWS à votre nouvelle base de données globale, puis vous utilisez le processus de commutation pour changer de rôle. Votre base de données globale Aurora doit utiliser une version d'Aurora PostgreSQL ou d'Aurora MySQL qui prend en charge les commutations. Pour de plus amples informations, veuillez consulter Réalisation de commutations pour les bases de données globales Amazon Aurora.
Gestion des bases RPOs de données globales basées sur Aurora PostgreSQL
Avec une base de données globale basée sur Aurora PostgreSQL, vous pouvez gérer l'objectif de point de reprise (RPO) de votre base de données globale Aurora à l'aide du paramètre rds.global_db_rpo. Le RPO représente la quantité maximale de données pouvant être perdue en cas de panne.
Lorsque vous définissez un RPO pour votre base de données globale basée sur Aurora PostgreSQL–, Aurora surveille le temps de retard RPO de tous les clusters secondaires pour vous assurer qu'au moins un cluster secondaire reste dans la fenêtre RPO cible. Le temps de retard RPO est une autre métrique basée sur le temps.
Le RPO est utilisé lorsque votre base de données reprend ses opérations dans une nouvelle base de données Région AWS après un basculement. Aurora évalue le RPO et les retards de RPO pour valider (ou bloquer) des transactions sur le cluster principal comme suit :
-
Effectue la transaction si au moins un cluster de base de données secondaire a un temps de retard RPO inférieur au RPO.
-
Bloque la transaction si tous les clusters de bases de données secondaires ont des temps de retard RPO supérieurs au RPO. Il enregistre également l'événement dans le fichier journal PostgreSQL et émet des événements « wait » qui montrent les sessions bloquées.
En d'autres termes, si tous les clusters secondaires prennent du retard sur le RPO cible, Aurora interrompt les transactions sur le cluster principal jusqu'à ce qu'au moins un des clusters secondaires le rattrape. Les transactions interrompues sont reprises et validées dès que le retard d'au moins un cluster de base de données secondaire devient inférieur au RPO. Par conséquent, aucune transaction ne peut être validée tant que le RPO n'est pas atteint.
Le paramètre rds.global_db_rpo est dynamique. Si vous décidez de ne pas bloquer toutes les transactions d'écriture jusqu'à ce que le retard diminue suffisamment, vous pouvez le réinitialiser rapidement. Dans ce cas, Aurora reconnaît et met en œuvre le changement après un court délai.
Important
Dans une base de données globale ne comportant que deux AWS régions, nous recommandons de conserver la valeur par défaut du rds.global_db_rpo paramètre dans le groupe de paramètres de la région secondaire. Dans le cas contraire, un basculement en cas de perte de la AWS région principale pourrait amener Aurora à suspendre les transactions. Attendez plutôt qu'Aurora ait terminé de reconstruire le cluster dans l'ancienne AWS région défaillante avant de modifier ce paramètre afin d'appliquer un RPO maximal.
Si vous définissez ce paramètre comme indiqué ci-dessous, vous pouvez également surveiller les métriques qu'il génère. Vous pouvez le faire en utilisant psql ou un autre outil d'interrogation du cluster de base de données principal de la base de données Aurora globale et obtenir des informations détaillées sur les opérations de votre base de données globale basée sur Aurora PostgreSQL–. Pour savoir comment procéder, consultez Surveillance des bases de données globales SQL basées sur Aurora Postgre.
Rubriques
Configuration de l'objectif de point de récupération
Le paramètre rds.global_db_rpo contrôle le paramètre RPO pour une base de données PostgreSQL. Ce paramètre est pris en charge par Aurora PostgreSQL. Les valeurs valides pour rds.global_db_rpo sont comprises entre 20 secondes et 2 147 483 647 secondes (68 ans). Choisissez une valeur réaliste pour répondre aux besoins de votre entreprise et à votre cas d'utilisation. Par exemple, si vous voulez prévoir jusqu'à 10 minutes pour votre RPO, définissez la valeur sur 600.
Vous pouvez définir cette valeur pour votre base de données globale basée sur Aurora PostgreSQL–à l'aide de l' AWS Management Console, de l' AWS CLI ou de l'API RDS.
Pour définir le RPO
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Choisissez le cluster principal de votre base de données Aurora globale et ouvrez l'onglet Configuration pour rechercher son groupe de paramètres de cluster de base de données. Par exemple, le groupe de paramètres par défaut pour un cluster de base de données principal exécutant Aurora PostgreSQL 11.7 est
default.aurora-postgresql11.Les groupes de paramètres ne peuvent pas être modifiés directement. Au lieu de cela, procédez comme suit :
-
Créez un groupe de paramètres de cluster de base de données personnalisé en utilisant le groupe de paramètres par défaut approprié comme point de départ. Par exemple, créez un groupe de paramètres de cluster de base de données personnalisé basé sur le
default.aurora-postgresql11. -
Sur votre groupe de paramètres de bases de données personnalisé, définissez la valeur du paramètre rds.global_db_rpo pour répondre à votre cas d'utilisation. Les valeurs valides sont comprises entre 20 secondes et la valeur entière maximale 2 147 483 647 secondes (68 ans).
-
Appliquez le groupe de paramètres de cluster de base de données modifié à votre cluster de base de données Aurora.
-
Pour de plus amples informations, veuillez consulter Modification des paramètres d'un groupe de paramètres de cluster de base de données dans Amazon Aurora.
Pour définir le rds.global_db_rpo paramètre, utilisez la commande CLI modify-db-cluster-parameter-group. Dans la commande, spécifiez le nom du groupe de paramètres de votre cluster principal et les valeurs du paramètre RPO.
Dans l'exemple suivant, le RPO est défini sur 600 secondes (10 minutes) pour le groupe de paramètres du cluster de base de données principal appelé my_custom_global_parameter_group.
Dans Linux, macOS, ou Unix:
aws rds modify-db-cluster-parameter-group \ --db-cluster-parameter-group-namemy_custom_global_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Dans Windows:
aws rds modify-db-cluster-parameter-group ^
--db-cluster-parameter-group-name my_custom_global_parameter_group ^
--parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Pour modifier le rds.global_db_rpo paramètre, utilisez l'opération d'DBClusterParameterGroupAPI Amazon RDS Modify.
Affichage de l'objectif de point de récupération
L'objectif de point de récupération (RPO) d'une base de données globale est stocké dans le paramètre rds.global_db_rpo pour chaque cluster de base de données. Vous pouvez vous connecter au point de terminaison du cluster secondaire que vous souhaitez afficher et utiliser psql afin d'interroger l'instance pour cette valeur.
db-name=>Si ce paramètre n'est pas défini, la requête renvoie le résultat suivant :
rds.global_db_rpo
-------------------
-1
(1 row)La réponse ci-dessous est renvoyée par un cluster de base de données secondaire pour lequel le paramètre RPO est défini sur 1 minute.
rds.global_db_rpo
-------------------
60
(1 row) Vous pouvez également utiliser l'interface de ligne de commande pour obtenir des valeurs afin de savoir si rds.global_db_rpo est actif sur l'un des clusters de bases de données Aurora en utilisant l'interface de ligne de commande pour obtenir les valeurs de tous les paramètres user du cluster.
Dans Linux, macOS, ou Unix:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-namelab-test-apg-global\ --source user
Dans Windows:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-namelab-test-apg-global* --source user
La commande renvoie une sortie similaire à celle ci-dessous pour tous les paramètres user différents des paramètres de cluster de base de données default-engine ou system.
{
"Parameters": [
{
"ParameterName": "rds.global_db_rpo",
"ParameterValue": "60",
"Description": "(s) Recovery point objective threshold, in seconds, that blocks user commits when it is violated.",
"Source": "user",
"ApplyType": "dynamic",
"DataType": "integer",
"AllowedValues": "20-2147483647",
"IsModifiable": true,
"ApplyMethod": "immediate",
"SupportedEngineModes": [
"provisioned"
]
}
]
}
Pour en savoir plus sur l'affichage des paramètres du groupe de paramètres de cluster, consultez Affichage des valeurs de paramètres pour un groupe de paramètres de cluster de base de données dans Amazon Aurora.
Désactivation de l'objectif de point de récupération
Pour désactiver le RPO, réinitialisez le paramètre rds.global_db_rpo. Vous pouvez réinitialiser les paramètres à l'aide de la AWS Management Console, de l' AWS CLI ou de l'API RDS.
Pour désactiver le RPO
Connectez-vous à la console Amazon RDS AWS Management Console et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Dans le volet de navigation, choisissez Groupes de paramètres.
-
Dans la liste, choisissez votre groupe de paramètres de cluster de base de données principal.
-
Choisissez Modifier les paramètres.
-
Sélectionnez la case en regard du paramètre rds.global_db_rpo.
-
Choisissez Réinitialiser.
-
Lorsque l'écran affiche Réinitialiser les paramètres dans le groupe de paramètres de base de données, choisissez Réinitialiser les paramètres.
Pour de plus amples informations sur la réinitialisation d'un paramètre avec la console, veuillez consulter Modification des paramètres d'un groupe de paramètres de cluster de base de données dans Amazon Aurora.
Pour réinitialiser le rds.global_db_rpo paramètre, utilisez la commande reset-db-cluster-parameter-group.
Dans Linux, macOS, ou Unix:
aws rds reset-db-cluster-parameter-group \ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
Dans Windows:
aws rds reset-db-cluster-parameter-group ^
--db-cluster-parameter-group-name global_db_cluster_parameter_group ^
--parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate" Pour réinitialiser le rds.global_db_rpo paramètre, utilisez l'DBClusterParameterGroupopération Amazon RDS API Reset.
