Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Migration d’une base de données SQL Server vers Babelfish pour Aurora PostgreSQL
Vous pouvez utiliser Babelfish pour Aurora PostgreSQL pour migrer une base de données SQL Server vers un cluster de bases de données Amazon Aurora PostgreSQL. Avant toute migration, consultez Utilisation de Babelfish avec une ou plusieurs bases de données.
Rubriques
Présentation du processus de migration
Le résumé suivant énumère les étapes nécessaires pour réussir la migration de votre application SQL Server et la faire fonctionner avec Babelfish. Pour plus d’informations sur les outils que vous pouvez utiliser pour les processus d’exportation et d’importation, et pour plus de détails, consultez Import/export outils pour migrer de SQL Server vers Babelfish. Pour charger les données, nous vous recommandons d'utiliser un cluster AWS DMS de base de données Aurora PostgreSQL comme point de terminaison cible.
-
Créez un cluster de bases de données Aurora PostgreSQL dans lequel Babelfish est activé. Pour savoir comment procéder, consultez Création d’un cluster de bases de données Babelfish pour Aurora PostgreSQL.
Pour importer les différents artefacts SQL exportés de votre base de données SQL Server, connectez-vous au cluster Babelfish en utilisant un outil SQL Server tel que sqlcmd
. Pour plus d’informations, consultez Utilisation d’un client SQL Server pour se connecter au cluster de bases de données. -
Sur la base de données SQL Server que vous souhaitez migrer, exportez le langage de définition de données (DDL). Le DDL est un code SQL qui décrit les objets de base de données contenant des données utilisateur (comme des tables, des index et des vues) et du code de base de données écrit par l’utilisateur (comme des procédures stockées, des fonctions définies par l’utilisateur et des déclencheurs).
Pour plus d’informations, consultez Utilisation de SQL Server Management Studio (SSMS) pour migrer vers Babelfish.
-
Exécutez un outil d’évaluation pour évaluer la portée des modifications dont vous pourriez avoir besoin pour que Babelfish puisse prendre en charge l’application exécutée sur SQL Server. Pour de plus amples informations, veuillez consulter Évaluation et gestion des différences entre SQL Server et Babelfish.
-
Passez en revue les limites du point de terminaison AWS DMS cible et mettez à jour le script DDL si nécessaire. Pour plus d’informations, consultez les limitations relatives à l’utilisation d’un point de terminaison cible PostgreSQL avec des tables Babelfish dans Utilisation de Babelfish pour Aurora PostgreSQL en tant que cible.
-
Sur votre nouveau cluster de base de données Babelfish, exécutez le DDL dans la T-SQL base de données spécifiée pour créer uniquement les schémas, les types de données définis par l'utilisateur et les tables avec leurs contraintes de clé primaire.
-
Utilisez-le AWS DMS pour migrer vos données de SQL Server vers les tables Babelfish. Pour la réplication continue à l’aide de SQL Server Change Data Capture ou SQL Replication, utilisez Aurora PostgreSQL au lieu de Babelfish comme point de terminaison. Pour ce faire, consultez Utilisation de Babelfish pour Aurora PostgreSQL en tant que cible pour AWS Database Migration Service.
-
Lorsque le chargement des données est terminé, créez tous les T-SQL objets restants qui supportent l'application sur votre cluster Babelfish.
-
Reconfigurez l’application cliente pour qu’elle se connecte au point de terminaison Babelfish au lieu de votre base de données SQL Server. Pour plus d’informations, consultez Connexion à un cluster de bases de données Babelfish.
-
Modifiez l’application si nécessaire et procédez à un nouveau test. Pour plus d’informations, consultez Différences entre Babelfish pour Aurora PostgreSQL et SQL Server.
Vous devez toujours évaluer vos requêtes SQL côté client. Les schémas générés à partir de votre instance SQL Server convertissent uniquement le code SQL côté serveur. Nous vous recommandons d’effectuer les étapes suivantes :
-
Capturez les requêtes côté client à l’aide de SQL Server Profiler avec le modèle prédéfini TSQL_Replay. Ce modèle capture des informations de T-SQL déclaration que vous pouvez ensuite réexécuter à des fins de réglage et de test itératifs. Vous pouvez démarrer Profiler dans SQL Studio Management Studio, à partir du menu Tools (Outils). Choisissez SQL Server Profiler pour ouvrir Profiler et choisissez le modèle TSQL_Replay.
Pour l’utiliser pour votre migration Babelfish, démarrez une trace, puis exécutez votre application à l’aide de vos tests fonctionnels. Le profileur capture les T-SQL déclarations. Une fois que vous avez terminé le test, arrêtez la trace. Enregistrez le résultat dans un fichier XML avec vos requêtes côté client (File > Save as > Trace XML File for Replay) (Fichier > Enregistrer sous > Tracer le fichier XML pour le relire).
Pour plus d’informations, consultez SQL Server Profiler
dans la documentation Microsoft. Pour plus d’informations sur le modèle TSQL_Replay, consultez Modèles du Générateur de profils SQL Server . -
Pour les applications comportant des requêtes SQL complexes côté client, nous vous recommandons d’utiliser Babelfish Compass pour les analyser afin de vérifier la compatibilité de ces requêtes avec Babelfish. Si l’analyse indique que les instructions SQL côté client contiennent des fonctions SQL non prises en charge, examinez les aspects SQL de l’application cliente et modifiez-les si nécessaire.
-
Vous pouvez également capturer les requêtes SQL en tant qu’événements étendus (format .xel). Pour ce faire, utilisez SSMS XEvent Profiler. Après avoir généré le fichier .xel, extrayez les instructions SQL dans des fichiers .xml que Compass peut ensuite traiter. Pour plus d’informations, consultez Use the SSMS XEvent Profiler
(Utiliser SSMS XEvent Profiler) dans la documentation Microsoft.
Lorsque vous êtes satisfait de tous les tests, de toutes les analyses et de toutes les modifications nécessaires pour votre application migrée, vous pouvez commencer à utiliser votre base de données Babelfish en production. Pour ce faire, arrêtez la base de données d’origine et redirigez les applications clientes en direct pour utiliser le port Babelfish TDS.
Note
AWS DMS prend désormais en charge la réplication des données de Babelfish. Pour plus d’informations, consultez AWS DMS prend désormais en charge Babelfish pour Aurora PostgreSQL en tant que cible
Évaluation et gestion des différences entre SQL Server et Babelfish
Pour de meilleurs résultats, nous vous recommandons d'évaluer le code de requête généré DDL/DML et le code de requête client avant de migrer votre application de base de données SQL Server vers Babelfish. Selon la version de Babelfish et les fonctionnalités spécifiques de SQL Server implémentées par votre application, vous devrez peut-être refactoriser votre application ou utiliser des alternatives aux fonctionnalités qui ne sont pas encore entièrement prises en charge dans Babelfish.
-
Pour évaluer le code de votre application SQL Server, utilisez Babelfish Compass sur le DDL généré pour déterminer la quantité de T-SQL code supportée par Babelfish. Identifiez T-SQL le code qui pourrait nécessiter des modifications avant de l'exécuter sur Babelfish. Pour plus d'informations sur cet outil, consultez l'outil Babelfish Compass
sur. GitHub Note
Babelfish Compass est un outil open source. Signalez tout problème avec Babelfish Compass par le biais du Support GitHub plutôt que par le biais du Support AWS .
Vous pouvez utiliser l'assistant de génération de script avec SQL Server Management Studio (SSMS) pour générer le fichier SQL évalué par Babelfish Compass. Nous recommandons les étapes suivantes pour rationaliser l’évaluation.
-
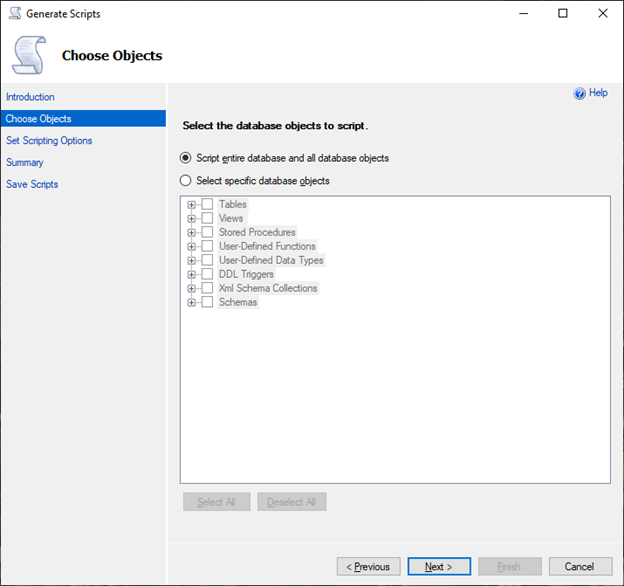
Sur la page Choose Objects (Choisir des objets), sélectionnez Script entire database and all database objects (Script de la base de données entière et tous les objets de la base de données).
-
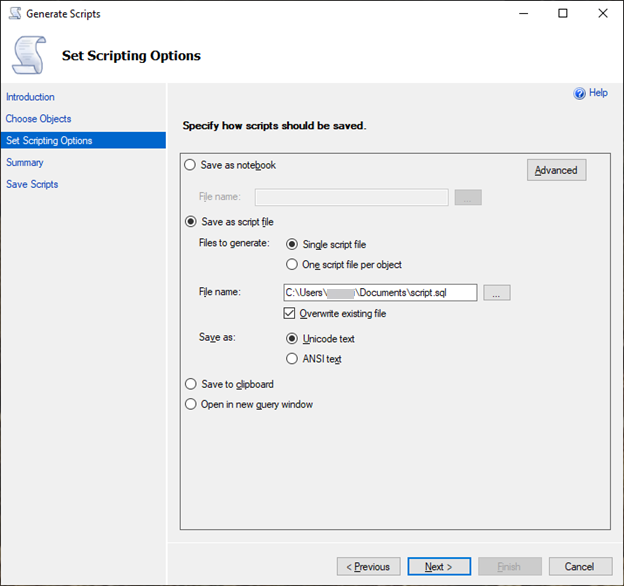
Pour l’option Set Scripting Options (Définir les options de script), choisissez Save as script file (Enregistrer comme fichier de script) en tant que Single script file (Fichier de script unique).
-
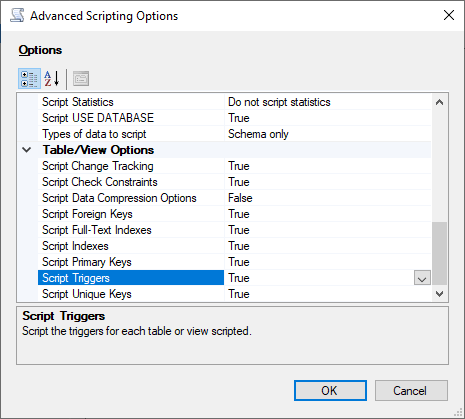
Choisissez Advanced (Avancé) pour modifier les options de script par défaut afin d’identifier les fonctionnalités qui sont normalement définies sur faux pour une évaluation complète :
-
Option Script Change Tracking définie sur True
-
Le script est Full-Text indexé sur True
-
Option Script Triggers définie sur True
-
Option Script Logins définie sur True
-
Option Script Owner définie sur True
-
Object-Level Autorisations de script sur True
-
Option Script Collations définie sur True
-
-
Effectuez les étapes restantes de l’assistant pour générer le fichier.
Import/export outils pour migrer de SQL Server vers Babelfish
Nous vous recommandons de l'utiliser AWS DMS comme outil principal pour migrer de SQL Server vers Babelfish. Cependant, Babelfish prend en charge plusieurs autres façons de migrer les données à l’aide d’outils SQL Server, dont les suivants.
-
SQL Server Integration Services (SSIS) pour toutes les versions de Babelfish. Pour obtenir plus d’informations, consultez Migrate from SQL Server to Aurora PostgreSQL using SSIS and Babelfish
(Migration de SQL Server vers Aurora PostgreSQL en utilisant SSIS et Babelfish). -
Utilisez l' Import/Export assistant SSMS pour les versions 2.1.0 et ultérieures de Babelfish. Cet outil est disponible via SSMS, mais également en tant qu’outil autonome. Pour plus d’informations, consultez Assistant Importation et Exportation SQL Server
dans la documentation Microsoft. -
L’utilitaire Microsoft bulk data copy (bcp) vous permet de copier les données d’une instance Microsoft SQL Server vers un fichier de données au format que vous spécifiez. Pour plus d’informations, consultez Utilitaire bcp
dans la documentation Microsoft. Babelfish prend désormais en charge la migration des données à l’aide du client BCP et l’utilitaire bcp prend désormais en charge l’indicateur -E(pour les colonnes d’identité) et l’indicateur -b (pour les insertions en lot). Certaines options de bcp ne sont pas prises en charge, notamment-C,-T,-G,-K,-R,-Vet-h.
Utilisation de SQL Server Management Studio (SSMS) pour migrer vers Babelfish
Nous recommandons de générer des fichiers séparés pour chacun des types d’objets spécifiques. Vous pouvez utiliser l’assistant Generate Scripts (Génération de scripts) dans SSMS pour chaque ensemble d’instructions DDL d’abord, puis modifier les objets en tant que groupe pour résoudre tous les problèmes trouvés pendant l’évaluation.
Procédez comme suit pour migrer les données à l'aide de AWS DMS ou d'autres méthodes de migration de données. Exécutez d’abord ces types de script de création pour une approche plus efficace et plus rapide du chargement des données sur les tables Babelfish dans Aurora PostgreSQL.
-
Exécutez les instructions
CREATE SCHEMA. -
Exécutez les instructions
CREATE TYPEpour créer des types de données définis par l’utilisateur. -
Exécutez les instructions
CREATE TABLEde base avec les clés primaires ou les contraintes uniques.
Effectuez le chargement des données à l'aide de l' import/export outil recommandé. Exécutez les scripts modifiés pour les étapes suivantes afin d’ajouter les objets de base de données restants. Vous avez besoin des instructions de création de table pour exécuter ces scripts pour les contraintes, les déclencheurs et les index. Une fois les scripts générés, supprimez les instructions de création de table.
-
Exécutez les instructions
ALTER TABLEpour les contraintes de contrôle, les contraintes de clé étrangère, les contraintes par défaut. -
Exécutez les instructions
CREATE TRIGGER. -
Exécutez les instructions
CREATE INDEX. -
Exécutez les instructions
CREATE VIEW. -
Exécutez les instructions
CREATE STORED PROCEDURE.
Pour générer des scripts pour chaque type d’objet
Suivez les étapes suivantes pour créer les instructions de base de création de table à l’aide de l’assistant Generate Scripts (Génération de scripts) dans SSMS. Suivez les mêmes étapes pour générer des scripts pour les différents types d’objets.
-
Connectez-vous à votre instance SQL Server existante.
-
Ouvrez le menu contextuel (clic droit) à partir d’un nom de base de données.
-
Choisissez Tasks (Tâches), puis Generate Scripts... (Générer des scripts...).
-
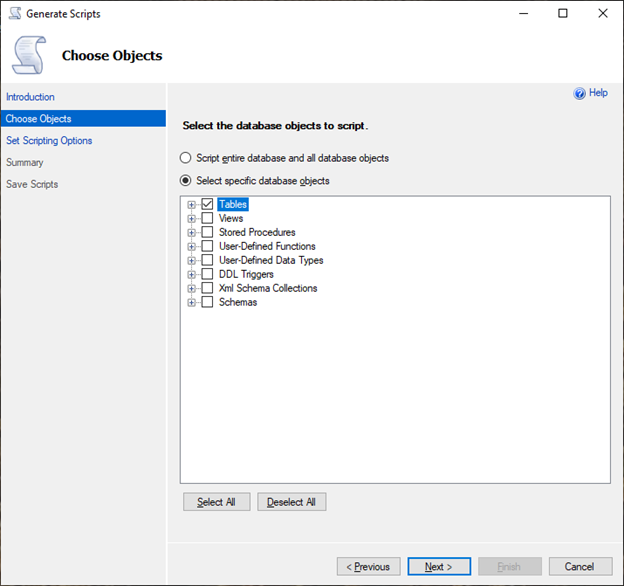
Dans le panneau Choose Objects (Choisir des objets), choisissez Select specific database objects (Sélectionner des objets de base de données spécifiques). Choisissez Tables, puis sélectionnez toutes les tables. Choisissez Next (Suivant) pour continuer.
-
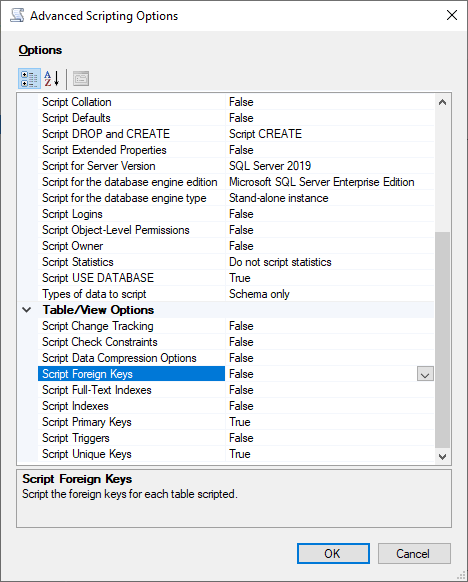
Sur la page Set Scripting Options (Définir les options de script), choisissez Advanced (Avancé) pour ouvrir les paramètres Options. Pour générer les instructions de base de création de table, modifiez les valeurs par défaut suivantes :
-
Option Script Defaults définie sur False.
-
Option Script Extended Properties définie sur False. Babelfish ne prend pas en charge les propriétés étendues.
-
Option Script Check Constraints définie sur False. Option Script Foreign Keys définie sur False.
-
-
Choisissez OK.
-
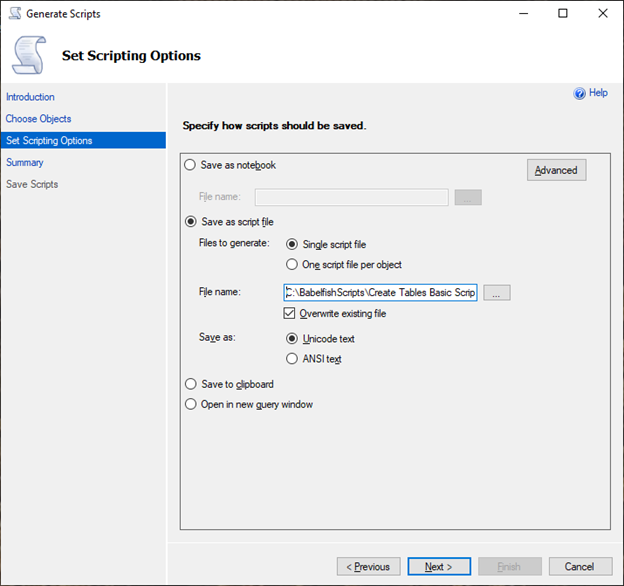
Sur la page Set Scripting Options (Définir les options de script), choisissez Save as script file (Enregistrer comme fichier de script), puis choisissez l’option Single script file (Fichier de script unique). Saisissez votre File name (Nom de fichier).
-
Choisissez Next (Suivant) pour afficher la page Summary wizard (Assistant Résumé).
-
Choisissez Next (Suivant) pour lancer la génération du script.
Vous pouvez continuer à générer des scripts pour les autres types d’objets dans l’assistant. Au lieu de choisir Finish (Terminer) après l’enregistrement du fichier, cliquez trois fois sur le bouton Previous (Précédent) pour revenir à la page Choose Objects (Choisir des objets). Répétez ensuite les étapes de l’assistant pour générer des scripts pour les autres types d’objets.
