Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation du machine learning Amazon Aurora avec Aurora PostgreSQL
En utilisant l'apprentissage automatique Amazon Aurora avec votre cluster de bases de données Aurora PostgreSQL, vous pouvez utiliser Amazon Comprehend, Amazon SageMaker AI ou Amazon Bedrock, selon vos besoins. Ces services prennent chacun en charge des cas d’utilisation propres au machine learning.
L'apprentissage automatique Aurora est pris en charge dans certaines versions Régions AWS et pour des versions spécifiques d'Aurora PostgreSQL uniquement. Avant d’essayer de configurer le machine learning Aurora, vérifiez la disponibilité pour votre version d’Aurora PostgreSQL et votre région. Pour en savoir plus, consultez Machine Learning Aurora avec Aurora PostgreSQL.
Rubriques
Exigences pour l’utilisation du machine learning Aurora avec Aurora PostgreSQL
Fonctions prises en charge et limitations du machine learning Aurora avec Aurora PostgreSQL
Utilisations d’Amazon Bedrock avec votre cluster de bases de données Aurora PostgreSQL
Utiliser Amazon Comprehend avec votre cluster de bases de données Aurora PostgreSQL
Utilisation de l' SageMaker IA avec votre cluster de base de données Aurora PostgreSQL
Exportation de données vers Amazon S3 pour la formation de modèles d' SageMaker IA (niveau avancé)
Considérations sur les performances du machine learning Aurora avec Aurora PostgreSQL
Exigences pour l’utilisation du machine learning Aurora avec Aurora PostgreSQL
AWS les services d'apprentissage automatique sont des services gérés qui sont configurés et exécutés dans leurs propres environnements de production. L'apprentissage automatique Aurora prend en charge l'intégration avec Amazon Comprehend, SageMaker AI et Amazon Bedrock. Avant d’essayer de configurer votre cluster de bases de données Aurora PostgreSQL pour utiliser le machine learning Aurora, assurez-vous de comprendre les exigences et prérequis suivants.
Les services Amazon Comprehend, SageMaker AI et Amazon Bedrock doivent être exécutés de la même manière que Région AWS votre cluster de base de données Aurora PostgreSQL. Vous ne pouvez pas utiliser les services Amazon Comprehend, SageMaker AI ou Amazon Bedrock à partir d'un cluster de base de données Aurora PostgreSQL situé dans une autre région.
Si votre cluster de base de données Aurora PostgreSQL se trouve dans un cloud public virtuel (VPC) basé sur le service Amazon VPC différent de celui de vos services Amazon Comprehend SageMaker et AI, le groupe de sécurité du VPC doit autoriser les connexions sortantes vers le service d'apprentissage automatique Aurora cible. Pour de plus amples informations, veuillez consulter Permettre la communication réseau entre Amazon Aurora et d'autres AWS services.
Pour l' SageMaker IA, les composants d'apprentissage automatique que vous souhaitez utiliser pour les inférences doivent être configurés et prêts à être utilisés. Pendant le processus de configuration de votre cluster de base de données Aurora PostgreSQL, vous devez disposer de l'Amazon Resource Name (ARN) SageMaker du point de terminaison AI. Les data scientists de votre équipe sont probablement les mieux placés pour travailler avec l' SageMaker IA pour préparer les modèles et effectuer les autres tâches de ce type. Pour commencer à utiliser Amazon SageMaker AI, consultez Get Started with Amazon SageMaker AI. Pour plus d'informations sur les inférences et les points de terminaison, voir Real-time inférence.
-
Pour Amazon Bedrock, vous devez disposer de l’ID des modèles Bedrock que vous souhaitez utiliser pour les inférences, disponible au cours du processus de configuration de votre cluster de bases de données Aurora PostgreSQL. Les scientifiques des données de votre équipe sont probablement les mieux placés pour travailler avec Bedrock afin de décider des modèles à utiliser, les optimiser si nécessaire et effectuer d’autres tâches de ce type. Pour commencer à utiliser Amazon Bedrock, consultez Comment configurer Bedrock.
-
Les utilisateurs d’Amazon Bedrock doivent demander l’accès aux modèles avant de pouvoir s’en servir. Si vous souhaitez ajouter des modèles supplémentaires pour la génération de texte, de discussion instantanée et d’images, vous devez demander l’accès aux modèles dans Amazon Bedrock. Pour plus d’informations, consultez Accès aux modèles.
Fonctions prises en charge et limitations du machine learning Aurora avec Aurora PostgreSQL
L'apprentissage automatique Aurora prend en charge tout point de terminaison d' SageMaker IA capable de lire et d'écrire le format CSV (valeurs séparées par des virgules) via une ContentType valeur de. text/csv Les algorithmes d' SageMaker IA intégrés qui acceptent actuellement ce format sont les suivants.
Linear Learner
Random Cut Forest
XGBoost
Pour en savoir plus sur ces algorithmes, consultez la section Choisir un algorithme dans le manuel Amazon SageMaker AI Developer Guide.
Lorsque vous utilisez Amazon Bedrock avec le machine learning Aurora, les limitations suivantes s’appliquent :
-
Les fonctions définies par l’utilisateur (UDF) permettent d’interagir nativement avec Amazon Bedrock. Les UDF n’ont pas d’exigences spécifiques en matière de demande ou de réponse ; ils peuvent donc utiliser n’importe quel modèle.
-
Vous pouvez utiliser des UDF pour créer le flux de travail souhaité. Par exemple, vous pouvez combiner des primitives de base, telles que
pg_cronpour exécuter une requête, récupérer des données, générer des inférences et écrire dans des tables pour répondre directement aux requêtes. -
Les UDF ne prennent pas en charge les appels par lots ou parallèles.
-
L’extension de machine learning Aurora ne prend pas en charge les interfaces vectorielles. Dans le cadre de l’extension, une fonction est disponible pour générer les vectorisations de la réponse du modèle au format
float8[]permettant de stocker ces vectorisations dans Aurora. Pour plus d’informations sur l’utilisation defloat8[], consultez Utilisations d’Amazon Bedrock avec votre cluster de bases de données Aurora PostgreSQL.
Configuration de votre cluster de bases de données Aurora PostgreSQL de façon à utiliser le machine learning Aurora
Pour que l'apprentissage automatique Aurora fonctionne avec votre cluster de bases de données Aurora PostgreSQL, vous devez créer Gestion des identités et des accès AWS un rôle (IAM) pour chacun des services que vous souhaitez utiliser. Le rôle IAM permet à votre cluster de bases de données Aurora PostgreSQL d’utiliser le service de machine learning Aurora pour le compte du cluster. Vous devez également installer l’extension du machine learning Aurora. Dans les rubriques suivantes, vous pouvez trouver des procédures de configuration pour chacun de ces services de machine learning Aurora.
Rubriques
Configuration d’Aurora PostgreSQL pour utiliser Amazon Bedrock
Dans la procédure suivante, vous devez d’abord créer le rôle et la stratégie IAM qui donnent à votre Aurora PostgreSQL l’autorisation d’utiliser Amazon Bedrock pour le compte du cluster. Vous associez ensuite la stratégie à un rôle IAM que votre cluster de bases de données Aurora PostgreSQL utilise pour fonctionner avec Amazon Bedrock. Pour des raisons de simplicité, cette procédure utilise la Console de gestion AWS pour effectuer toutes les tâches.
Pour configurer votre cluster de bases de données Aurora PostgreSQL pour utiliser Amazon Bedrock
Connectez-vous à la console IAM Console de gestion AWS et ouvrez-la à https://console.aws.amazon.com/iam/
l'adresse. Ouvrez la console IAM à l’adresse https://console.aws.amazon.com/iam/
. Choisissez Politiques (sous Gestion des accès) dans le menu de la console Gestion des identités et des accès AWS (IAM).
Choisissez Create Policy (Créer une politique). Sur la page de l’éditeur visuel, choisissez Service, puis saisissez Bedrock dans le champ Sélectionner un service. Développez le niveau d’accès en lecture. Choisissez InvokeModelparmi les paramètres de lecture d'Amazon Bedrock.
Choisissez le Foundation/Provisioned modèle auquel vous souhaitez accorder l'accès en lecture via la politique.
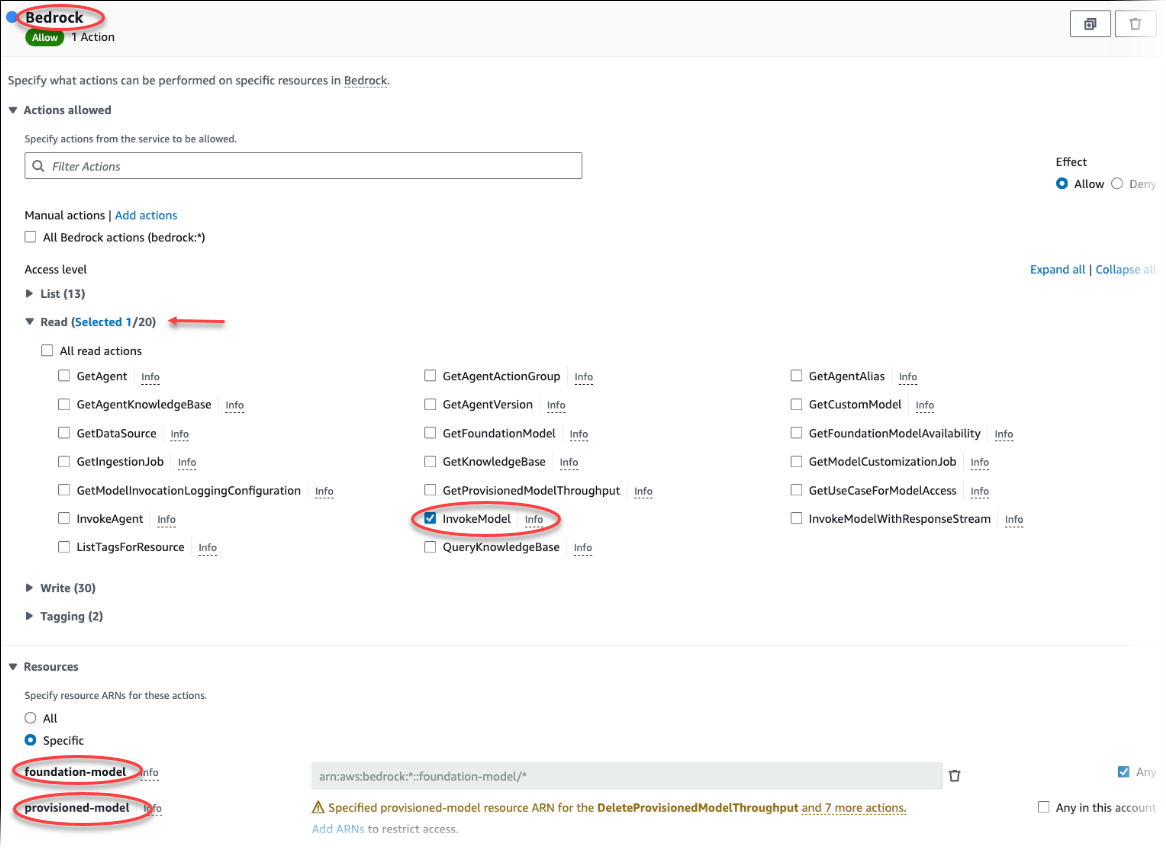
Choisissez Next: Tags (Suivant : Balises) et définissez toutes les balises (facultatif). Choisissez Suivant : Vérification. Saisissez un nom et une description pour la stratégie, comme indiqué dans l’image.
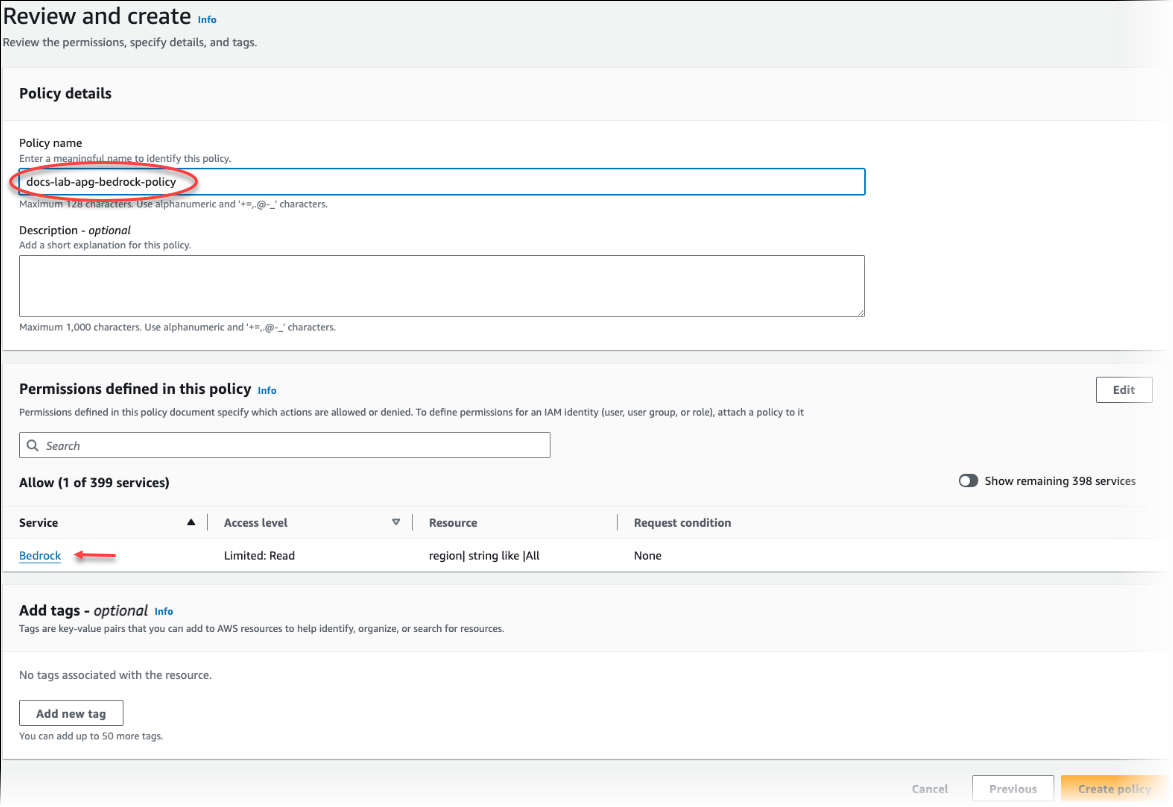
Choisissez Create Policy (Créer une politique). La console affiche une alerte lorsque la stratégie a été enregistrée. Vous pouvez la trouver dans la liste des stratégies.
Choisissez Roles (under Access management) (Rôles (sous Gestion des accès)) sur la console IAM.
Choisissez Créer un rôle.
Sur la page Sélectionner une entité de confiance, choisissez la vignette Service AWS , puis choisissez RDS pour ouvrir le sélecteur.
Choisissez RDS – Add Role to Database (RDS – Ajoutez un rôle à la base de données).
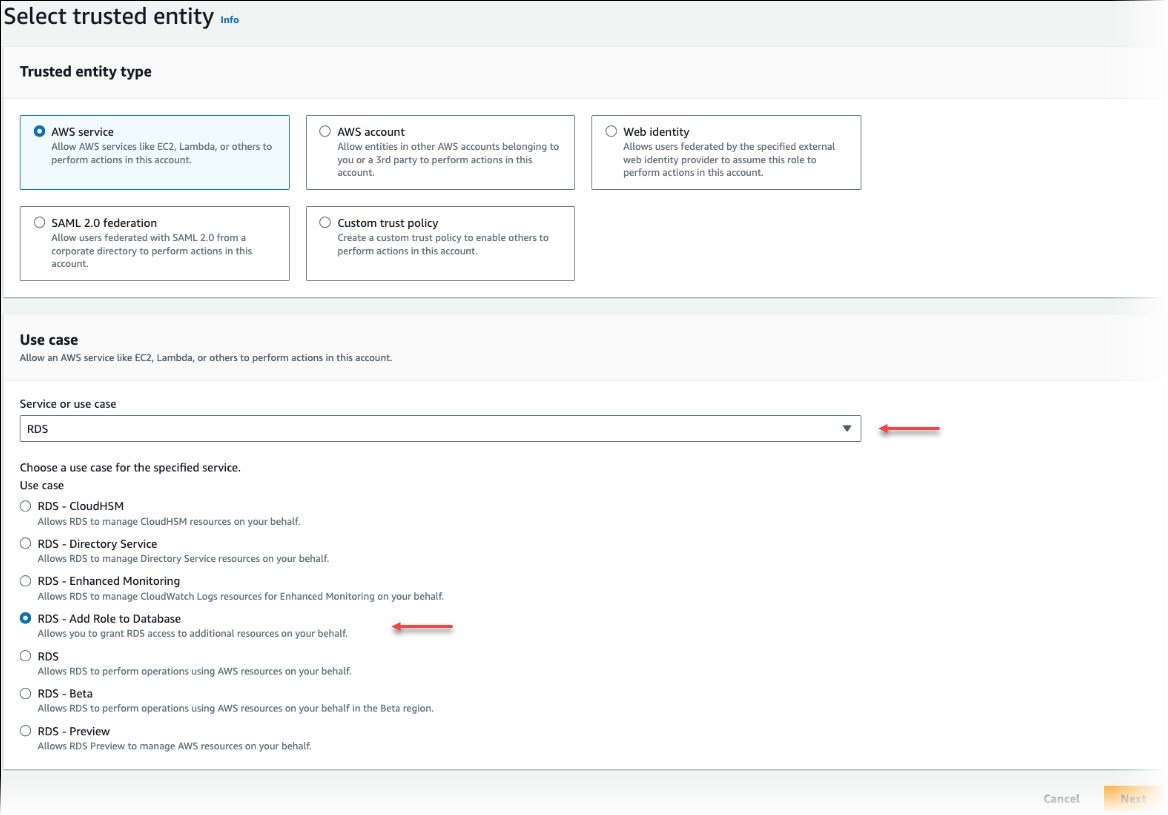
Choisissez Suivant. Sur la page Ajouter des autorisations, recherchez la stratégie que vous avez créée à l’étape précédente et choisissez-la parmi celles répertoriées. Choisissez Suivant.
Next: Review (Suivant : Vérification). Saisissez un nom pour le rôle IAM et une description.
Ouvrez la console Amazon RDS à l'adresse https://console.aws.amazon.com/rds/
. Accédez à l'emplacement Région AWS où se trouve votre cluster de base de données Aurora PostgreSQL.
-
Dans le panneau de navigation, choisissez Bases de données, puis le cluster de bases de données Aurora PostgreSQL que vous souhaitez utiliser avec Bedrock.
-
Choisissez l’onglet Connectivity & security (Connectivité et sécurité) et faites défiler la page pour accéder à la section Manage IAM roles (Gérer les rôles IAM). Dans le sélecteur Add IAM roles to this cluster (Ajouter des rôles IAM à ce cluster), choisissez le rôle que vous avez créé dans les étapes précédentes. Dans le sélecteur Fonction, choisissez Bedrock, puis choisissez Ajouter un rôle.
Le rôle (avec sa stratégie) est associé au cluster de bases de données Aurora PostgreSQL. Une fois le processus terminé, vous pouvez trouver le rôle dans la liste Rôles IAM actuels pour ce cluster, comme indiqué dans l’image suivante.
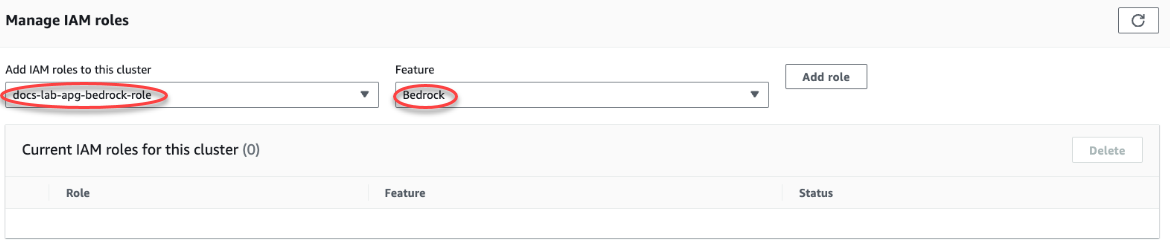
La configuration IAM pour Amazon Bedrock est terminée. Continuez à configurer votre Aurora PostgreSQL pour qu’il fonctionne avec le machine learning Aurora en installant l’extension comme indiqué dans Installation de l’extension du machine learning Aurora.
Configuration d’Aurora PostgreSQL pour utiliser Amazon Comprehend
Dans la procédure suivante, vous devez d’abord créer le rôle et la stratégie IAM qui donnent à votre Aurora PostgreSQL l’autorisation d’utiliser Amazon Comprehend pour le compte du cluster. Vous associez ensuite la stratégie à un rôle IAM que votre cluster de bases de données Aurora PostgreSQL utilise pour fonctionner avec Amazon Comprehend. Par souci de simplicité, cette procédure utilise la Console de gestion AWS pour effectuer toutes les tâches.
Configurer votre cluster de bases de données Aurora PostgreSQL pour utiliser Amazon Comprehend
Connectez-vous à la console IAM Console de gestion AWS et ouvrez-la à https://console.aws.amazon.com/iam/
l'adresse. Ouvrez la console IAM à l’adresse https://console.aws.amazon.com/iam/
. Choisissez Politiques (sous Gestion des accès) dans le menu de la console Gestion des identités et des accès AWS (IAM).
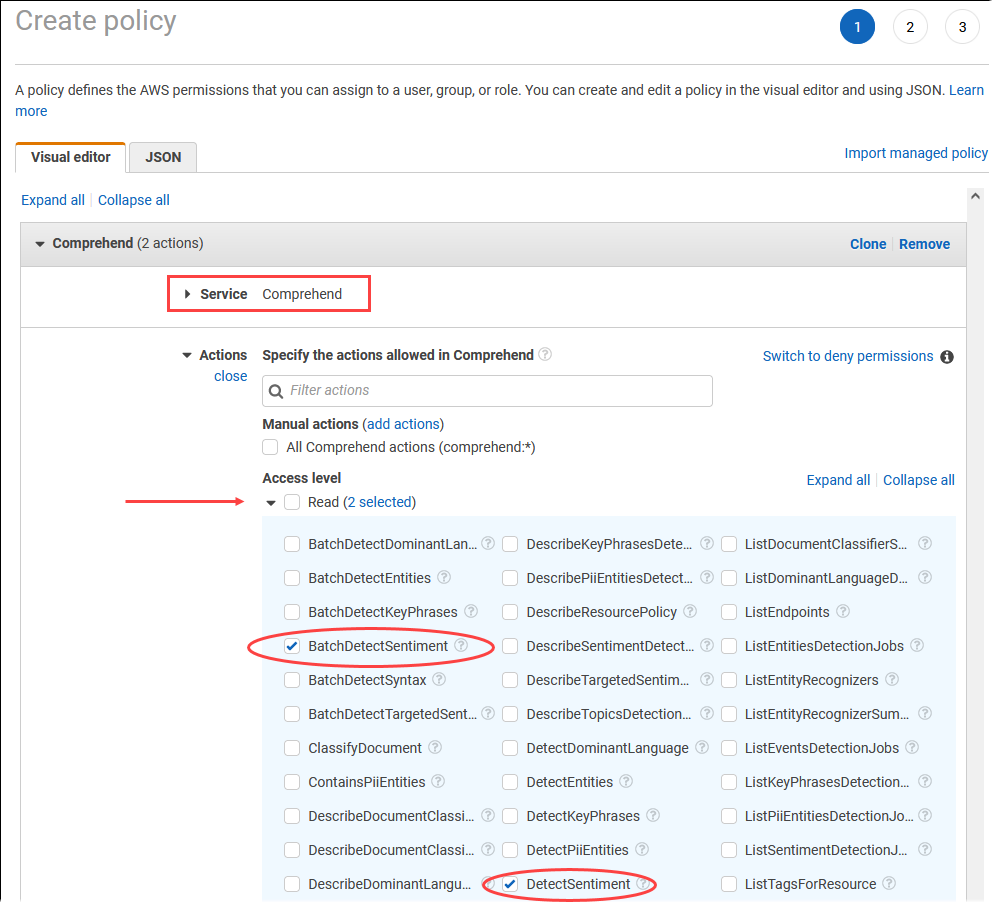
Choisissez Create Policy (Créer une politique). Sur la page de l’éditeur visuel, choisissez Service, puis saisissez Comprehend dans le champ Sélectionner un service. Développez le niveau d’accès en lecture. Choisissez BatchDetectSentimentet DetectSentimentparmi les paramètres de lecture d'Amazon Comprehend.
Choisissez Next: Tags (Suivant : Balises) et définissez toutes les balises (facultatif). Choisissez Suivant : Vérification. Saisissez un nom et une description pour la stratégie, comme indiqué dans l’image.
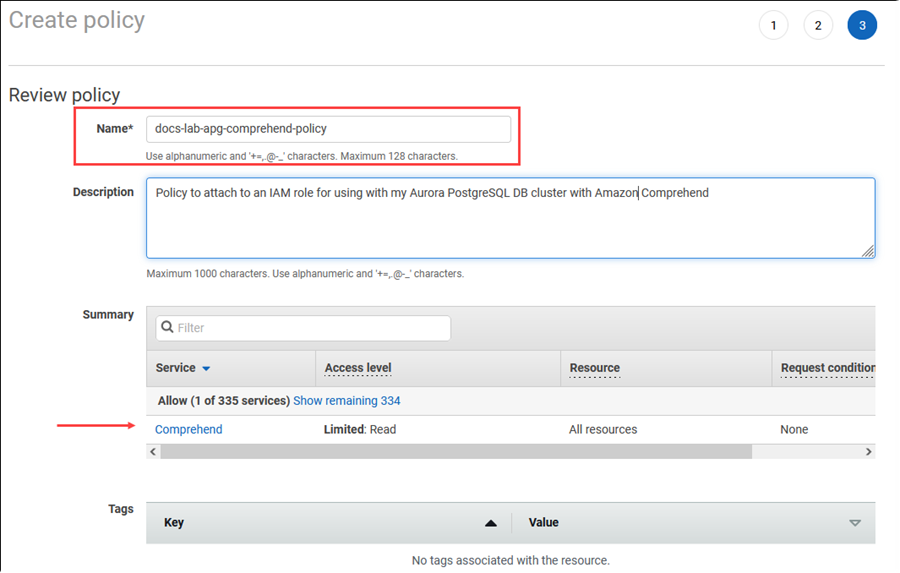
Choisissez Create Policy (Créer une politique). La console affiche une alerte lorsque la stratégie a été enregistrée. Vous pouvez la trouver dans la liste des stratégies.
Choisissez Roles (under Access management) (Rôles (sous Gestion des accès)) sur la console IAM.
Choisissez Créer un rôle.
Sur la page Sélectionner une entité de confiance, choisissez la vignette Service AWS , puis choisissez RDS pour ouvrir le sélecteur.
Choisissez RDS – Add Role to Database (RDS – Ajoutez un rôle à la base de données).
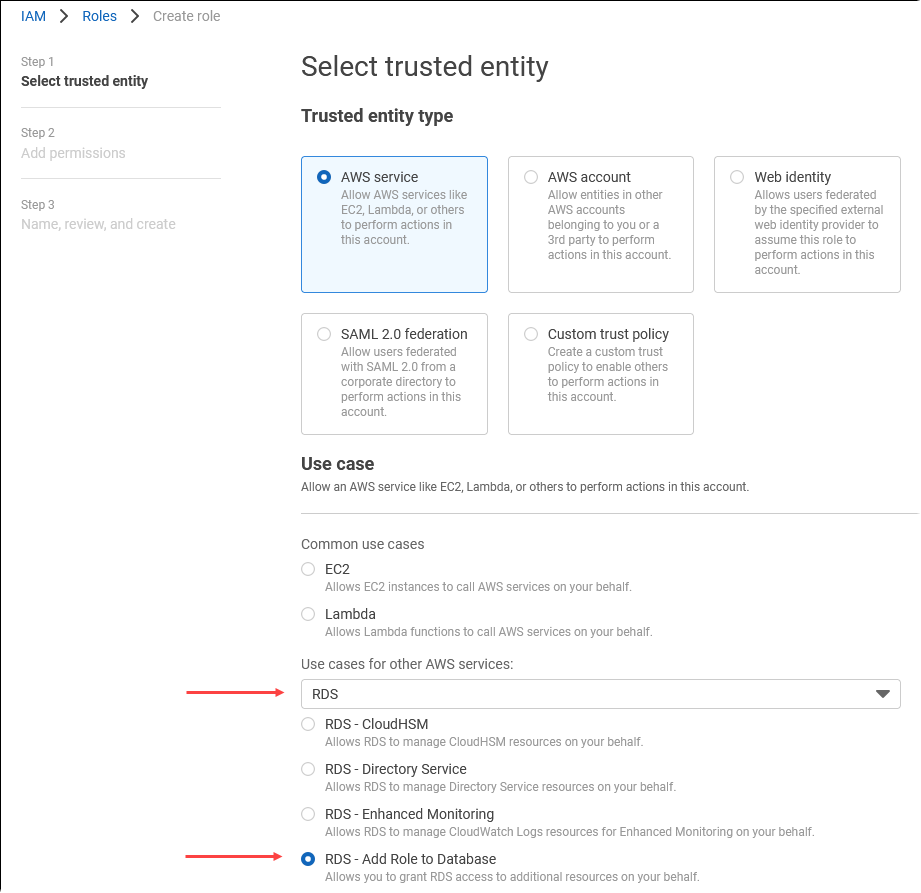
Choisissez Suivant. Sur la page Ajouter des autorisations, recherchez la stratégie que vous avez créée à l’étape précédente et choisissez-la parmi celles répertoriées. Choisissez Next (Suivant).
Next: Review (Suivant : Vérification). Saisissez un nom pour le rôle IAM et une description.
Ouvrez la console Amazon RDS à l'adresse https://console.aws.amazon.com/rds/
. Accédez à l'emplacement Région AWS où se trouve votre cluster de base de données Aurora PostgreSQL.
-
Dans le panneau de navigation, choisissez Bases de données, puis le cluster de bases de données Aurora PostgreSQL que vous souhaitez utiliser avec Amazon Comprehend.
-
Choisissez l’onglet Connectivity & security (Connectivité et sécurité) et faites défiler la page pour accéder à la section Manage IAM roles (Gérer les rôles IAM). Dans le sélecteur Add IAM roles to this cluster (Ajouter des rôles IAM à ce cluster), choisissez le rôle que vous avez créé dans les étapes précédentes. Dans le sélecteur Fonction, choisissez Comprehend, puis Ajouter un rôle.
Le rôle (avec sa stratégie) est associé au cluster de bases de données Aurora PostgreSQL. Une fois le processus terminé, vous pouvez trouver le rôle dans la liste Rôles IAM actuels pour ce cluster, comme indiqué dans l’image suivante.
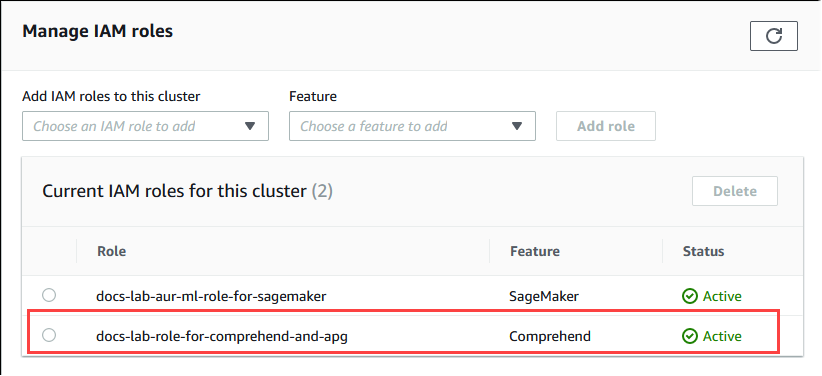
La configuration IAM pour Amazon Comprehend est terminée. Continuez à configurer votre Aurora PostgreSQL pour qu’il fonctionne avec le machine learning Aurora en installant l’extension comme indiqué dans Installation de l’extension du machine learning Aurora.
Configuration d'Aurora PostgreSQL pour utiliser Amazon AI SageMaker
Avant de pouvoir créer la politique et le rôle IAM pour votre cluster de base de données Aurora PostgreSQL, vous devez disposer de la configuration de votre modèle d'IA et de SageMaker votre point de terminaison.
Pour configurer votre cluster de base de données Aurora PostgreSQL afin d'utiliser l'IA SageMaker
Connectez-vous à la console IAM Console de gestion AWS et ouvrez-la à https://console.aws.amazon.com/iam/
l'adresse. Choisissez Politiques (sous Gestion des accès) dans le menu de la console Gestion des identités et des accès AWS (IAM), puis choisissez Créer une politique. Dans l'éditeur visuel, choisissez SageMakerle service. Pour Actions, ouvrez le sélecteur de lecture (sous Niveau d'accès) et choisissez InvokeEndpoint. Dans ce cas, une icône d’avertissement s’affiche.
Ouvrez le sélecteur de ressources et choisissez le lien Ajouter un ARN pour restreindre l'accès sous Spécifier l'ARN de la ressource du point de terminaison pour l' InvokeEndpoint action.
Entrez vos ressources Région AWS d' SageMaker IA et le nom de votre point de terminaison. Votre AWS compte est prérempli.
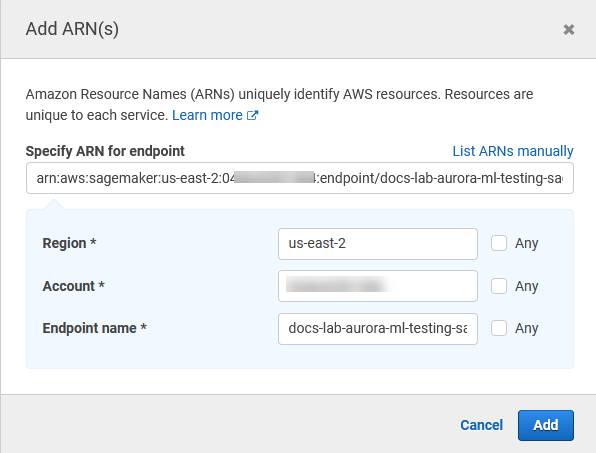
Choisissez Add (Ajouter) pour enregistrer. Choisissez Next: Tags (Suivant : Balises) et Next: Review (Suivant : Vérification) pour accéder à la dernière page du processus de création de la stratégie.
Saisissez un nom et une description pour la stratégie, puis choisissez Create policy (Créer une stratégie). La stratégie est créée et ajoutée à la liste des stratégies. Une alerte s’affiche dans la console lorsque cela se produit.
Dans la console IAM, choisissez Roles (Rôles).
Choisissez Créer un rôle.
Sur la page Sélectionner une entité de confiance, choisissez la vignette Service AWS , puis choisissez RDS pour ouvrir le sélecteur.
Choisissez RDS – Add Role to Database (RDS – Ajoutez un rôle à la base de données).
Choisissez Suivant. Sur la page Ajouter des autorisations, recherchez la stratégie que vous avez créée à l’étape précédente et choisissez-la parmi celles répertoriées. Choisissez Next (Suivant).
Next: Review (Suivant : Vérification). Saisissez un nom pour le rôle IAM et une description.
Ouvrez la console Amazon RDS à l'adresse https://console.aws.amazon.com/rds/
. Accédez à l'emplacement Région AWS où se trouve votre cluster de base de données Aurora PostgreSQL.
-
Dans le volet de navigation, choisissez Databases, puis choisissez le cluster de bases de données Aurora PostgreSQL que vous souhaitez utiliser avec l'IA. SageMaker
-
Choisissez l’onglet Connectivity & security (Connectivité et sécurité) et faites défiler la page pour accéder à la section Manage IAM roles (Gérer les rôles IAM). Dans le sélecteur Add IAM roles to this cluster (Ajouter des rôles IAM à ce cluster), choisissez le rôle que vous avez créé dans les étapes précédentes. Dans le sélecteur de fonctionnalités, choisissez SageMaker AI, puis choisissez Ajouter un rôle.
Le rôle (avec sa stratégie) est associé au cluster de bases de données Aurora PostgreSQL. Une fois le processus terminé, vous pouvez trouver le rôle dans la liste Rôles IAM actuels pour ce cluster.
La configuration de l'IAM pour l' SageMaker IA est terminée. Continuez à configurer votre Aurora PostgreSQL pour qu’il fonctionne avec le machine learning Aurora en installant l’extension comme indiqué dans Installation de l’extension du machine learning Aurora.
Configuration d'Aurora PostgreSQL pour utiliser Amazon S3 SageMaker pour l'IA (version avancée)
Pour utiliser l' SageMaker IA avec vos propres modèles plutôt que d'utiliser les composants prédéfinis fournis par l' SageMaker IA, vous devez configurer un bucket Amazon Simple Storage Service (Amazon S3) que le cluster de bases de données Aurora PostgreSQL pourra utiliser. Il s’agit d’une rubrique avancée qui n’est pas entièrement documentée dans ce Guide de l’utilisateur Amazon Aurora. Le processus général est le même que pour intégrer le support à l' SageMaker IA, comme suit.
Créez la politique et le rôle IAM pour Amazon S3.
Ajoutez le rôle IAM et l’importation ou l’exportation Amazon S3 en tant que fonction dans l’onglet Connectivité et sécurité de votre cluster de bases de données Aurora PostgreSQL.
Ajoutez l’ARN du rôle à votre groupe de paramètres de cluster de bases de données personnalisé pour chaque cluster de bases de données Aurora.
Pour plus d’informations de base, consultez Exportation de données vers Amazon S3 pour la formation de modèles d' SageMaker IA (niveau avancé).
Installation de l’extension du machine learning Aurora
Les extensions d'apprentissage automatique Aurora aws_ml 1.0 fournissent deux fonctions que vous pouvez utiliser pour appeler Amazon Comprehend, des services d' SageMaker intelligence artificielle, ainsi aws_ml 2.0 que deux fonctions supplémentaires que vous pouvez utiliser pour appeler les services Amazon Bedrock. L’installation de ces extensions sur votre cluster de bases de données Aurora PostgreSQL crée également un rôle administratif pour la fonction.
Note
L'utilisation de ces fonctions dépend de l'achèvement de la configuration IAM pour le service d'apprentissage automatique Aurora (Amazon Comprehend SageMaker , AI, Amazon Bedrock), comme indiqué dans. Configuration de votre cluster de bases de données Aurora PostgreSQL de façon à utiliser le machine learning Aurora
aws_comprehend.detect_sentiment – Vous utilisez cette fonction pour appliquer une analyse des sentiments au texte stocké dans la base de données de votre cluster de bases de données Aurora PostgreSQL.
aws_sagemaker.invoke_endpoint — Vous utilisez cette fonction dans votre code SQL pour communiquer avec le point de terminaison AI depuis votre cluster. SageMaker
aws_bedrock.invoke_model : vous utilisez cette fonction dans votre code SQL pour communiquer avec les modèles Bedrock de votre cluster. La réponse de cette fonction sera exprimée au format TEXT. Ainsi, si un modèle renvoie une réponse au format corps JSON, la sortie de cette fonction sera transmise à l’utilisateur final sous forme de chaîne de caractères.
aws_bedrock.invoke_model_get_embeddings : vous utilisez cette fonction dans votre code SQL pour invoquer des modèles Bedrock qui renvoient des vectorisations de sortie dans une réponse JSON. Cette fonctionnalité peut être utilisée pour extraire les vectorisations liés directement à la clé JSON, ce qui permet d’optimiser la réponse et de l’adapter à vos processus internes.
Installer l’extension du machine learning Aurora dans votre cluster de bases de données Aurora PostgreSQL
Utilisez
psqlpour vous connecter à l’instance d’enregistreur de votre cluster de bases de données Aurora PostgreSQL. Connectez-vous à la base de données spécifique dans laquelle vous souhaitez installer l’extensionaws_ml.psql --host=cluster-instance-1.111122223333.aws-region.rds.amazonaws.com --port=5432 --username=postgres --password --dbname=labdb
labdb=>CREATE EXTENSION IF NOT EXISTS aws_ml CASCADE;NOTICE: installing required extension "aws_commons" CREATE EXTENSIONlabdb=>
L’installation des extensions aws_ml crée également le rôle administratif aws_ml et trois nouveaux schémas, comme suit.
aws_comprehend– Schéma du service Amazon Comprehend et source de la fonctiondetect_sentiment(aws_comprehend.detect_sentiment).aws_sagemaker— Schéma du service d' SageMaker IA et source de lainvoke_endpointfonction (aws_sagemaker.invoke_endpoint).aws_bedrock: schéma du service Amazon Bedrock et source des fonctionsinvoke_model(aws_bedrock.invoke_model)etinvoke_model_get_embeddings(aws_bedrock.invoke_model_get_embeddings).
Le rôle rds_superuser se voit attribuer le rôle administratif aws_ml et devient OWNER de ces trois schémas de machine learning Aurora. Pour permettre aux autres utilisateurs de la base de données d’accéder aux fonctions de machine learning Aurora, rds_superuser doit accorder des privilèges EXECUTE sur les fonctions de machine learning Aurora. Par défaut, les privilèges EXECUTE sont révoqués de PUBLIC sur les fonctions des deux schémas de machine learning Aurora.
Dans une configuration de base de données à locataires multiples, vous pouvez empêcher les locataires d’accéder aux fonctions de machine learning d’Aurora en utilisant REVOKE USAGE sur le schéma de machine learning Aurora spécifique que vous souhaitez protéger.
Utilisations d’Amazon Bedrock avec votre cluster de bases de données Aurora PostgreSQL
Pour Aurora PostgreSQL, le machine learning Aurora fournit la fonction Amazon Bedrock suivante pour travailler avec vos données texte. Cette fonction n’est disponible qu’après avoir installé l’extension aws_ml 2.0 et effectué toutes les procédures de configuration. Pour plus d’informations, consultez Configuration de votre cluster de bases de données Aurora PostgreSQL de façon à utiliser le machine learning Aurora.
- aws_bedrock.invoke_model
-
Cette fonction prend en entrée un texte au format JSON, le traite pour différents modèles hébergés sur Amazon Bedrock, puis renvoie la réponse du modèle sous forme de texte JSON. Cette réponse peut contenir du texte, une image ou des vectorisations. Voici un résumé de la documentation de la fonction.
aws_bedrock.invoke_model( IN model_id varchar, IN content_type text, IN accept_type text, IN model_input text, OUT model_output varchar)
Les entrées et sorties de cette fonction sont les suivantes.
-
model_id: identifiant du modèle. content_type: le type de demande adressée au modèle Bedrock.accept_type: le type de réponse à attendre du modèle Bedrock. Généralement application/JSON pour la plupart des modèles.model_input: invites ; ensemble spécifique d’entrées pour le modèle au format spécifié par content_type. Pour plus d'informations sur la demande acceptée format/structure par le modèle, voir Paramètres d'inférence pour les modèles de base.model_output: la sortie du modèle Bedrock sous forme de texte.
L’exemple suivant montre comment invoquer un modèle Anthropic Claude 2 pour Bedrock en utilisant invoke_model.
Exemple Exemple : une requête simple utilisant les fonctions Amazon Bedrock
SELECT aws_bedrock.invoke_model ( model_id := 'anthropic.claude-v2', content_type:= 'application/json', accept_type := 'application/json', model_input := '{"prompt": "\n\nHuman: You are a helpful assistant that answers questions directly and only using the information provided in the context below.\nDescribe the answer in detail.\n\nContext: %s \n\nQuestion: %s \n\nAssistant:","max_tokens_to_sample":4096,"temperature":0.5,"top_k":250,"top_p":0.5,"stop_sequences":[]}' );
- aws_bedrock.invoke_model_get_embeddings
-
La sortie du modèle peut indiquer des vectorisations vectorielles dans certains cas. Étant donné que la réponse varie selon le modèle, il est possible d’utiliser une autre fonction, invoke_model_get_embeddings, qui fonctionne exactement comme invoke_model, mais renvoie les vectorisations en spécifiant la clé JSON appropriée.
aws_bedrock.invoke_model_get_embeddings( IN model_id varchar, IN content_type text, IN json_key text, IN model_input text, OUT model_output float8[])
Les entrées et sorties de cette fonction sont les suivantes.
-
model_id: identifiant du modèle. content_type: le type de demande adressée au modèle Bedrock. Ici, accept_type est défini sur la valeur par défautapplication/json.model_input: invites ; ensemble spécifique d’entrées pour le modèle au format spécifié par content_type. Pour plus d'informations sur la demande acceptée format/structure par le modèle, voir Paramètres d'inférence pour les modèles de base.json_key: référence au champ à partir duquel la vectorisation doit être extraite. Cela peut varier si le modèle de vectorisation change.-
model_output: la sortie du modèle Bedrock est un ensemble de vectorisations comportant des décimales de 16 bits.
L'exemple suivant montre comment générer une intégration à l'aide du modèle Titan Embeddings G1 — Text embedding pour l'expression PostgreSQL monitoring views. I/O
Exemple Exemple : une requête simple utilisant les fonctions Amazon Bedrock
SELECT aws_bedrock.invoke_model_get_embeddings( model_id := 'amazon.titan-embed-text-v1', content_type := 'application/json', json_key := 'embedding', model_input := '{ "inputText": "PostgreSQL I/O monitoring views"}') AS embedding;
Utiliser Amazon Comprehend avec votre cluster de bases de données Aurora PostgreSQL
Pour Aurora PostgreSQL, le machine learning Aurora fournit la fonction Amazon Comprehend suivante pour travailler avec vos données texte. Cette fonction n’est disponible qu’après avoir installé l’extension aws_ml et effectué toutes les procédures de configuration. Pour plus d’informations, consultez Configuration de votre cluster de bases de données Aurora PostgreSQL de façon à utiliser le machine learning Aurora.
- aws_comprehend.detect_sentiment
-
Cette fonction prend du texte en entrée et évalue si le texte a une posture émotionnelle positive, négative, neutre ou mixte. Il produit ce sentiment ainsi qu’un niveau de confiance pour son évaluation. Voici un résumé de la documentation de la fonction.
aws_comprehend.detect_sentiment( IN input_text varchar, IN language_code varchar, IN max_rows_per_batch int, OUT sentiment varchar, OUT confidence real)
Les entrées et sorties de cette fonction sont les suivantes.
-
input_text– Le texte pour évaluer et attribuer un sentiment (négatif, positif, neutre, mixte). language_code: la langue duinput_textidentifié à l’aide de l’identifiant à deux lettres ISO 639-1 avec une sous-étiquette régionale (selon les besoins) ou du code à trois lettres ISO 639-2, selon le cas. Par exemple,enest le code pour l’anglais,zhest le code pour le chinois simplifié. Pour plus d’informations, consultez Langues prises en charge dans le Guide du développeur Amazon Comprehend.max_rows_per_batch– Le nombre maximal de lignes par lot pour le traitement par lots. Pour plus d’informations, consultez Présentation du mode par lots et des fonctions de machine learning d’Aurora.sentiment: l’impression du texte de saisie, identifié comme étant POSITIVE, NEGATIVE, NEUTRAL ou MIXED.confidence– Le degré de fiabilité de la précision dusentimentspécifié. Les valeurs vont de 0,0 à 1,0.
Voici des exemples qui montrent comment utiliser cette fonction.
Exemple Exemple : une requête simple utilisant les fonctions Amazon Comprehend
Voici un exemple de requête simple qui fait appel à cette fonction pour évaluer la satisfaction des clients auprès de votre équipe d’assistance. Supposons que vous disposiez d’une table de base de données (support) qui enregistre les commentaires des clients après chaque demande d’aide. Cet exemple de requête applique la fonction aws_comprehend.detect_sentiment au texte de la colonne feedback du tableau et génère le sentiment et le niveau de confiance de ce sentiment. Cette requête génère également des résultats par ordre décroissant.
SELECT feedback, s.sentiment,s.confidence FROM support,aws_comprehend.detect_sentiment(feedback, 'en') s ORDER BY s.confidence DESC;feedback | sentiment | confidence ----------------------------------------------------------+-----------+------------ Thank you for the excellent customer support! | POSITIVE | 0.999771 The latest version of this product stinks! | NEGATIVE | 0.999184 Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 Your product is too complex, but your support is great. | MIXED | 0.957958 Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 My problem was never resolved! | NEGATIVE | 0.920644 When will the new version of this product be released? | NEUTRAL | 0.902706 I cannot stand that chatbot. | NEGATIVE | 0.895219 Your support tech talked down to me. | NEGATIVE | 0.868598 It took me way too long to get a real person. | NEGATIVE | 0.481805 (10 rows)
Pour éviter qu’une détection de sentiment vous soit facturée plusieurs fois par ligne de table, vous pouvez matérialiser les résultats. Faites-le sur les lignes qui vous intéressent. Par exemple, les notes du clinicien sont mises à jour afin que seules celles en français (fr) utilisent la fonction de détection des sentiments.
UPDATE clinician_notes SET sentiment = (aws_comprehend.detect_sentiment (french_notes, 'fr')).sentiment, confidence = (aws_comprehend.detect_sentiment (french_notes, 'fr')).confidence WHERE clinician_notes.french_notes IS NOT NULL AND LENGTH(TRIM(clinician_notes.french_notes)) > 0 AND clinician_notes.sentiment IS NULL;
Pour plus d’informations sur l’optimisation de vos appels de fonction, consultez Considérations sur les performances du machine learning Aurora avec Aurora PostgreSQL.
Utilisation de l' SageMaker IA avec votre cluster de base de données Aurora PostgreSQL
Après avoir configuré votre environnement d' SageMaker IA et intégré Aurora PostgreSQL comme indiqué Configuration d'Aurora PostgreSQL pour utiliser Amazon AI SageMaker dans la section, vous pouvez appeler des opérations à l'aide de la fonction. aws_sagemaker.invoke_endpoint La fonction aws_sagemaker.invoke_endpoint permet uniquement une connexion à un point de terminaison de modèle se trouvant dans la même Région AWS. Si votre instance de base de données comporte plusieurs répliques, Régions AWS
assurez-vous de configurer et de déployer chaque modèle d' SageMaker IA sur chaque Région AWS.
Les appels à aws_sagemaker.invoke_endpoint destination sont authentifiés à l'aide du rôle IAM que vous avez configuré pour associer votre cluster de base de données Aurora PostgreSQL au service SageMaker AI et au point de terminaison que vous avez fournis lors du processus de configuration. SageMaker Les points de terminaison du modèle d'IA sont limités à un compte individuel et ne sont pas publics. L'endpoint_nameURL ne contient pas l'identifiant du compte. SageMaker L'IA détermine l'ID du compte à partir du jeton d'authentification fourni par le rôle SageMaker AI IAM de l'instance de base de données.
- aws_sagemaker.invoke_endpoint
Cette fonction prend le point de terminaison SageMaker AI en entrée et le nombre de lignes à traiter par lots. Il prend également en entrée les différents paramètres attendus par le point de terminaison du modèle d' SageMaker IA. La documentation de référence de cette fonction est la suivante.
aws_sagemaker.invoke_endpoint( IN endpoint_name varchar, IN max_rows_per_batch int, VARIADIC model_input "any", OUT model_output varchar )
Les entrées et sorties de cette fonction sont les suivantes.
endpoint_name— Une URL de point de terminaison Région AWS indépendante.max_rows_per_batch– Le nombre maximal de lignes par lot pour le traitement par lots. Pour plus d’informations, consultez Présentation du mode par lots et des fonctions de machine learning d’Aurora.model_input: un ou plusieurs paramètres d’entrée pour le modèle. Il peut s'agir de n'importe quel type de données requis par le modèle d' SageMaker IA. PostgreSQL vous permet de spécifier jusqu’à 100 paramètres d’entrée pour une fonction. Les types de données des tableaux doivent être unidimensionnels, mais peuvent contenir autant d'éléments que prévu par le modèle d' SageMaker IA. Le nombre d'entrées d'un modèle d' SageMaker IA est limité uniquement par la limite de taille des messages SageMaker AI de 6 Mo.model_output— La sortie du modèle d' SageMaker IA sous forme de texte.
Création d'une fonction définie par l'utilisateur pour invoquer un modèle d' SageMaker IA
Créez une fonction distincte définie par l'utilisateur à appeler aws_sagemaker.invoke_endpoint pour chacun de vos modèles d' SageMaker IA. Votre fonction définie par l'utilisateur représente le point de terminaison SageMaker AI hébergeant le modèle. La aws_sagemaker.invoke_endpoint fonction s'exécute dans le cadre de la fonction définie par l'utilisateur. User-defined les fonctions offrent de nombreux avantages :
-
Vous pouvez donner son propre nom à votre modèle d' SageMaker IA au lieu de vous contenter de faire appel
aws_sagemaker.invoke_endpointà tous vos modèles d' SageMaker IA. -
Vous pouvez spécifier l’URL du point de terminaison du modèle en un seul endroit dans votre code d’application SQL.
-
Vous pouvez contrôler les privilèges
EXECUTEde chaque fonction de machine learning Aurora indépendamment. -
Vous pouvez déclarer les types d’entrée et de sortie du modèle à l’aide des types SQL. SQL impose le nombre et le type d'arguments transmis à votre modèle d' SageMaker IA et effectue une conversion de type si nécessaire. L'utilisation de types SQL se
SQL NULLtraduira également par la valeur par défaut appropriée attendue par votre modèle d' SageMaker IA. -
Vous pouvez réduire la taille maximale de lot si vous souhaitez retourner les premières lignes un peu plus rapidement.
Pour spécifier une fonction définie par l’utilisateur, utilisez l’instruction DDL (Data Definition Language) SQL CREATE FUNCTION. Lorsque vous créez cette fonction, vous spécifiez les éléments suivants :
-
Paramètres d’entrée du modèle.
-
Le point de terminaison d' SageMaker IA spécifique à invoquer.
-
Type de retour.
La fonction définie par l'utilisateur renvoie l'inférence calculée par le point de terminaison SageMaker AI après avoir exécuté le modèle sur les paramètres d'entrée. L'exemple suivant crée une fonction définie par l'utilisateur pour un modèle d' SageMaker IA avec deux paramètres d'entrée.
CREATE FUNCTION classify_event (IN arg1 INT, IN arg2 DATE, OUT category INT)
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', NULL,
arg1, arg2 -- model inputs are separate arguments
)::INT -- cast the output to INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;Notez ce qui suit :
-
L’entrée de la fonction
aws_sagemaker.invoke_endpointpeut être constituée par un ou plusieurs paramètres de n’importe quel type de données. -
Cet exemple utilise un type de sortie INT. Si vous faites passer la sortie d’un type
varcharà un autre type, elle doit être convertie en un type scalaire intégré PostgreSQL tel queINTEGER,REAL,FLOATouNUMERIC. Pour plus d’informations sur ces types, consultez Date Typesdans la documentation PostgreSQL. -
Spécifiez
PARALLEL SAFEpour activer le traitement de requêtes parallèles. Pour plus d’informations, consultez Améliorer les temps de réponse grâce au traitement parallèle des requêtes. -
Spécifiez
COST 5000pour estimer le coût d’exécution de la fonction. Utilisez un nombre positif donnant le coût d’exécution estimé de la fonction, en unités decpu_operator_cost.
Transmission d'un tableau en entrée à un modèle d' SageMaker IA
La fonction aws_sagemaker.invoke_endpoint peut avoir jusqu’à 100 paramètres d’entrée, ce qui est la limite pour les fonctions PostgreSQL. Si le modèle d' SageMaker IA nécessite plus de 100 paramètres du même type, transmettez-les sous forme de tableau.
L'exemple suivant définit une fonction qui transmet un tableau en entrée au modèle de régression SageMaker AI. La sortie est convertie à une valeur REAL.
CREATE FUNCTION regression_model (params REAL[], OUT estimate REAL) AS $$ SELECT aws_sagemaker.invoke_endpoint ( 'sagemaker_model_endpoint_name', NULL, params )::REAL $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
Spécification de la taille du lot lors de l'appel d'un modèle d' SageMaker IA
L'exemple suivant crée une fonction définie par l'utilisateur pour un modèle d' SageMaker IA qui définit la taille du lot par défaut sur NULL. La fonction vous permet également de fournir une taille de lot différente lorsque vous l’invoquez.
CREATE FUNCTION classify_event (
IN event_type INT, IN event_day DATE, IN amount REAL, -- model inputs
max_rows_per_batch INT DEFAULT NULL, -- optional batch size limit
OUT category INT) -- model output
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', max_rows_per_batch,
event_type, event_day, COALESCE(amount, 0.0)
)::INT -- casts output to type INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;Remarques :
-
Utilisez le paramètre
max_rows_per_batchfacultatif pour contrôler le nombre de lignes pour une invocation de fonction en mode traitement par lots. Si vous utilisez une valeur NULL, l’optimiseur de requête choisit automatiquement la taille de lot maximale. Pour de plus amples informations, veuillez consulter Présentation du mode par lots et des fonctions de machine learning d’Aurora. -
Par défaut, la transmission de NULL en tant que valeur de paramètre est traduite en chaîne vide avant d'être transmise à SageMaker AI. Pour cet exemple, les entrées ont différents types.
-
Si vous avez une entrée non textuelle ou une entrée de texte qui doit par défaut avoir une valeur autre qu’une chaîne vide, utilisez l’instruction
COALESCE. UtilisezCOALESCEpour traduire NULL en la valeur de remplacement nulle souhaitée dans l’appel àaws_sagemaker.invoke_endpoint. Pour le paramètreamountde cet exemple, une valeur NULL est convertie en 0.0.
Invoquer un modèle d' SageMaker IA doté de plusieurs sorties
L'exemple suivant crée une fonction définie par l'utilisateur pour un modèle d' SageMaker IA qui renvoie plusieurs sorties. Votre fonction doit convertir la sortie de la fonction aws_sagemaker.invoke_endpoint en un type de données correspondant. Par exemple, vous pouvez utiliser le type de point PostgreSQL intégré pour les paires (x, y) ou un type composite défini par l’utilisateur.
Cette fonction définie par l’utilisateur renvoie des valeurs à partir d’un modèle renvoyant plusieurs sorties à l’aide d’un type composite pour les sorties.
CREATE TYPE company_forecasts AS ( six_month_estimated_return real, one_year_bankruptcy_probability float); CREATE FUNCTION analyze_company ( IN free_cash_flow NUMERIC(18, 6), IN debt NUMERIC(18,6), IN max_rows_per_batch INT DEFAULT NULL, OUT prediction company_forecasts) AS $$ SELECT (aws_sagemaker.invoke_endpoint('endpt_name', max_rows_per_batch,free_cash_flow, debt))::company_forecasts; $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
Pour le type composite, utilisez les champs dans le même ordre que celui dans lequel ils apparaissent dans la sortie du modèle et convertissez la sortie aws_sagemaker.invoke_endpoint en votre type composite. L’appelant peut extraire les champs individuels soit par leur nom, soit avec la notation PostgreSQL « .* ».
Exportation de données vers Amazon S3 pour la formation de modèles d' SageMaker IA (niveau avancé)
Nous vous recommandons de vous familiariser avec l'apprentissage automatique et l' SageMaker IA d'Aurora en utilisant les algorithmes et les exemples fournis plutôt que d'essayer de former vos propres modèles. Pour plus d'informations, consultez Get Started with Amazon SageMaker AI
Pour entraîner des modèles d' SageMaker IA, vous exportez des données vers un compartiment Amazon S3. Le compartiment Amazon S3 est utilisé par l' SageMaker IA pour entraîner votre modèle avant son déploiement. Vous pouvez interroger les données d’un cluster de bases de données Aurora PostgreSQL et les enregistrer directement dans des fichiers texte stockés dans un compartiment Amazon S3. L' SageMaker IA consomme ensuite les données du compartiment Amazon S3 à des fins d'entraînement. Pour en savoir plus sur la formation de modèles d' SageMaker IA, consultez Entraînez un modèle avec Amazon SageMaker AI.
Note
Lorsque vous créez un compartiment Amazon S3 pour l'entraînement des modèles d' SageMaker IA ou la notation par lots, sagemaker utilisez-le dans le nom du compartiment Amazon S3. Pour plus d'informations, consultez Spécifier un compartiment Amazon S3 pour télécharger des ensembles de données d'entraînement et stocker les données de sortie dans le manuel Amazon SageMaker AI Developer Guide.
Pour plus d’informations sur l’exportation de vos données, consultez Exportation de données à partir d’un cluster de bases de données Aurora PostgreSQL vers Amazon S3.
Considérations sur les performances du machine learning Aurora avec Aurora PostgreSQL
Les services Amazon Comprehend et SageMaker AI effectuent la majeure partie du travail lorsqu'ils sont invoqués par une fonction d'apprentissage automatique Aurora. Cela signifie que vous pouvez adapter ces ressources selon vos besoins, de manière indépendante. Pour votre cluster de bases de données Aurora PostgreSQL, vous pouvez rendre vos appels de fonctions aussi efficaces que possible. Vous trouverez ci-dessous quelques considérations relatives aux performances à prendre en compte lors de l’utilisation du machine learning Aurora depuis Aurora PostgreSQL.
Rubriques
Présentation du mode par lots et des fonctions de machine learning d’Aurora
Généralement, PostgreSQL exécute les fonctions une ligne à la fois. Le machine learning Aurora peut réduire cette surcharge en combinant en lots les appels au service de machine learning Aurora externe pour de nombreuses lignes avec une approche appelée exécution en mode traitement par lots. En mode traitement par lots, le machine learning Aurora reçoit les réponses d’un lot de lignes d’entrée, puis retransmet les réponses à la requête en cours d’exécution une ligne à la fois. Cette optimisation améliore le débit de vos requêtes Aurora sans limiter l’optimiseur de requêtes PostgreSQL.
Aurora utilise automatiquement le mode traitement par lots si la fonction est référencée à partir de la liste SELECT, d’une clause WHERE ou d’une clause HAVING. Notez que les CASE expressions simples de haut niveau sont éligibles pour une exécution en mode batch. Top-level les CASE expressions recherchées sont également éligibles pour une exécution en mode batch à condition que la première WHEN clause soit un prédicat simple avec un appel de fonction en mode batch.
Votre fonction définie par l’utilisateur doit être une fonction LANGUAGE SQL et doit spécifier PARALLEL SAFE et COST 5000.
Migration de fonction de l’instruction SELECT vers la clause FROM
Habituellement, une fonction aws_ml éligible à l’exécution en mode traitement par lots est automatiquement migrée par Aurora vers la clause FROM.
La migration des fonctions en mode traitement par lots éligibles vers la clause FROM peut être examinée manuellement au niveau de chaque requête. Pour ce faire, vous utilisez les instructions EXPLAIN (et ANALYSE et VERBOSE) et vous recherchez les informations « Batch Processing (Traitement par lots) » sous chaque en mode traitement par lot Function Scan. Vous pouvez également utiliser EXPLAIN (avec VERBOSE) sans exécuter la requête. Vous observez ensuite si les appels à la fonction apparaissent sous la forme Function
Scan sous une jointure de boucle imbriquée qui n’a pas été spécifiée dans l’instruction d’origine.
Dans l’exemple suivant, l’opérateur de jointure de boucle imbriquée dans le plan montre que Aurora a migré la fonction anomaly_score. Il a migré cette fonction de la liste SELECT vers la clause FROM, où elle est éligible à l’exécution en mode traitement par lots.
EXPLAIN (VERBOSE, COSTS false)
SELECT anomaly_score(ts.R.description) from ts.R;
QUERY PLAN
-------------------------------------------------------------
Nested Loop
Output: anomaly_score((r.description)::text)
-> Seq Scan on ts.r
Output: r.id, r.description, r.score
-> Function Scan on public.anomaly_score
Output: anomaly_score.anomaly_score
Function Call: anomaly_score((r.description)::text)Pour désactiver l’exécution en mode traitement par lots, définissez le paramètre apg_enable_function_migration sur false. Cela empêche la migration des fonctions aws_ml de la liste SELECT vers la clause FROM. L’exemple suivant indique comment procéder.
SET apg_enable_function_migration = false;Le paramètre apg_enable_function_migration est un paramètre GUC (Grand Unified Configuration) reconnu par l’extension Aurora PostgreSQL apg_plan_mgmt pour la gestion des plans de requêtes. Pour désactiver la migration des fonctions dans une session, utilisez la gestion des plans de requêtes pour enregistrer le plan résultant en tant que plan approved. Lors de l’exécution, la gestion des plans de requêtes applique le plan approved avec son paramètre apg_enable_function_migration. Cette application se produit indépendamment de la valeur du paramètre GUC apg_enable_function_migration. Pour plus d’informations, consultez Gestion des plans d’exécution de requêtes pour Aurora PostgreSQL.
Utilisation du paramètre max_rows_per_batch
Les fonctions aws_comprehend.detect_sentiment et aws_sagemaker.invoke_endpoint ont toutes deux un paramètre max_rows_per_batch. Ce paramètre indique le nombre de lignes qui peuvent être envoyées au service de machine learning Aurora. Plus le jeu de données traité par votre fonction est grand, plus vous pouvez augmenter la taille du lot.
Batch-mode les fonctions améliorent l'efficacité en créant des lots de lignes qui répartissent le coût des appels des fonctions d'apprentissage automatique Aurora sur un grand nombre de lignes. Toutefois, si une instruction SELECT se termine prématurément en raison d’une clause LIMIT, le lot peut être construit sur plus de lignes que la requête n’en utilise. Cette approche peut entraîner des frais supplémentaires sur votre AWS compte. Pour profiter des avantages de l’exécution en mode traitement par lots tout en évitant de créer des lots trop volumineux, utilisez une valeur plus petite pour le paramètre max_rows_per_batch dans vos appels de fonction.
Si vous effectuez une action EXPLAIN (VERBOSE, ANALYZE) sur une requête qui utilise l’exécution en mode traitement par lots, vous voyez un opérateur FunctionScan qui se trouve sous une jointure de boucle imbriquée. Le nombre de boucles rapporté par EXPLAIN équivaut au nombre de fois où une ligne a été extraite à partir de l’opérateur FunctionScan. Si une instruction utilise une clause LIMIT, le nombre d’extractions est cohérent. Pour optimiser la taille du lot, définissez le paramètre max_rows_per_batch sur cette valeur. Cependant, si la fonction de mode traitement par lots est référencée dans un prédicat dans la clause WHERE ou HAVING, vous ne pouvez probablement pas connaître le nombre d’extractions à l’avance. Dans ce cas, utilisez les boucles comme guide et testez l’élément max_rows_per_batch pour trouver un paramètre optimisant les performances.
Vérification de l’exécution en mode traitement par lots
Pour voir si une fonction a été exécutée en mode batch, utilisez EXPLAIN ANALYZE. Si l’exécution en mode traitement par lots a été utilisée, le plan de requêtes inclura les informations dans une section « Batch Processing (Traitement par lots) ».
EXPLAIN ANALYZE SELECT user-defined-function();
Batch Processing: num batches=1 avg/min/max batch size=3333.000/3333.000/3333.000
avg/min/max batch call time=146.273/146.273/146.273Dans cet exemple, 1 lot contenait 3 333 lignes, dont le traitement a duré 146,273 ms. La section « Batch Processing (Traitement par lots) » contient les éléments suivants :
-
Le nombre de lots pour cette opération d’analyse de fonction
-
La taille moyenne, minimale et maximale du lot
-
La durée moyenne, minimale et maximale d’exécution du lot
En général, le lot final est plus petit que le reste, ce qui entraîne souvent une taille de lot minimale bien inférieure à la taille moyenne.
Pour renvoyer les premières lignes plus rapidement, définissez le paramètre max_rows_per_batch sur une valeur plus petite.
Pour réduire le nombre d’appels en mode traitement par lots au service ML lorsque vous utilisez une clause LIMIT dans votre fonction définie par l’utilisateur, définissez le paramètre max_rows_per_batch sur une valeur plus petite.
Améliorer les temps de réponse grâce au traitement parallèle des requêtes
Pour obtenir des résultats le plus rapidement possible à partir d’un grand nombre de lignes, vous pouvez combiner le traitement des requêtes parallèles avec le traitement par lots. Vous pouvez utiliser le traitement des requêtes parallèles pour les instructions SELECT, CREATE TABLE AS SELECT et CREATE
MATERIALIZED VIEW.
Note
PostgreSQL ne prend pas encore en charge les requêtes parallèles pour les instructions DML (Data Manipulation Language).
Le traitement des requêtes parallèles se produit à la fois dans la base de données et dans le service ML. Le nombre de cœurs dans la classe d’instance de la base de données limite le degré de parallélisme pouvant être utilisé lors de l’exécution d’une requête. Le serveur de base de données peut construire un plan d’exécution de requêtes parallèles qui partitionne la tâche entre un ensemble d’unités de travail parallèles. Ensuite, chacune de ces unités de travail peut créer des requêtes par lots contenant des dizaines de milliers de lignes (ou autant que ce qui est autorisé par chaque service).
Les demandes groupées provenant de tous les travailleurs parallèles sont envoyées au point de terminaison SageMaker AI. Le degré de parallélisme que le point de terminaison peut prendre en charge est limité par le nombre et le type d’instances qui le prennent en charge. Pour obtenir K degrés de parallélisme, vous avez besoin d’une classe d’instance de base de données ayant au moins K cœurs. Vous devez également configurer le point de terminaison SageMaker AI de votre modèle pour qu'il comporte K instances initiales d'une classe d'instance suffisamment performante.
Pour utiliser le traitement des requêtes parallèles, vous pouvez définir le paramètre de stockage parallel_workers de la table qui contient les données que vous prévoyez de transmettre. Vous définissez parallel_workers sur une fonction en mode traitement par lots telle que aws_comprehend.detect_sentiment. Si l'optimiseur choisit un plan de requête parallèle, les services AWS ML peuvent être appelés à la fois par lots et en parallèle.
Vous pouvez utiliser les paramètres suivants avec la fonction aws_comprehend.detect_sentiment pour obtenir un plan avec un parallélisme à quatre voies. Si vous modifiez l’un des deux paramètres suivants, vous devez redémarrer l’instance de base de données pour que les modifications soient effectives
-- SET max_worker_processes to 8; -- default value is 8
-- SET max_parallel_workers to 8; -- not greater than max_worker_processes
SET max_parallel_workers_per_gather to 4; -- not greater than max_parallel_workers
-- You can set the parallel_workers storage parameter on the table that the data
-- for the Aurora machine learning function is coming from in order to manually override the degree of
-- parallelism that would otherwise be chosen by the query optimizer
--
ALTER TABLE yourTable SET (parallel_workers = 4);
-- Example query to exploit both batch-mode execution and parallel query
EXPLAIN (verbose, analyze, buffers, hashes)
SELECT aws_comprehend.detect_sentiment(description, 'en')).*
FROM yourTable
WHERE id < 100;Pour plus d’informations sur le contrôle des requêtes parallèles, consultez Plans parallélisés
Utilisation des vues matérialisées et des colonnes matérialisées
Lorsque vous invoquez un AWS service tel que SageMaker AI ou Amazon Comprehend depuis votre base de données, votre compte est débité conformément à la politique tarifaire de ce service. Pour minimiser les frais sur votre compte, vous pouvez matérialiser le résultat de l'appel du AWS service dans une colonne matérialisée afin que le AWS service ne soit pas appelé plus d'une fois par ligne de saisie. Si vous le souhaitez, vous pouvez ajouter une colonne d’horodatage materializedAt pour enregistrer l’heure à laquelle les colonnes ont été matérialisées.
La latence d’une instruction INSERT ordinaire à une seule ligne est généralement beaucoup moins élevée que celle de l’appel d’une fonction en mode traitement par lots. Ainsi, vous risquez de ne pas être en mesure de répondre aux exigences de latence de votre application si vous appelez la fonction en mode traitement par lots pour chaque INSERT d’une seule ligne exécuté par votre application. Pour matérialiser le résultat de l'appel d'un AWS service dans une colonne matérialisée, les applications hautes performances doivent généralement remplir les colonnes matérialisées. Pour ce faire, elles émettent périodiquement une instruction UPDATE qui s’exécute sur un grand lot de lignes en même temps.
UPDATE applique un verrou au niveau de la ligne qui peut avoir un impact sur une application en cours d’exécution. Donc, vous pouvez avoir besoin d’utiliser SELECT ... FOR UPDATE SKIP LOCKED ou MATERIALIZED
VIEW.
Les requêtes analytiques qui s’exécutent sur un grand nombre de lignes en temps réel peuvent combiner la matérialisation en mode traitement par lots et le traitement en temps réel. Pour ce faire, ces requêtes rassemblent sous la forme d’une opération UNION ALL les résultats prématérialisés avec une requête sur les lignes qui n’ont pas encore de résultats matérialisés. Dans certains cas, une telle opération UNION ALL est nécessaire à plusieurs endroits ou la requête peut être générée par une application tierce. Si c’est le cas, vous pouvez créer un élément VIEW pour encapsuler l’opération UNION ALL afin que ce détail ne soit pas exposé au reste de l’application SQL.
Vous pouvez utiliser une vue matérialisée pour matérialiser les résultats d’une instruction SELECT arbitraire à un moment dans le temps. Vous pouvez également l’utiliser pour actualiser la vue matérialisée à tout moment dans le futur. Actuellement, PostgreSQL ne prend pas en charge l’actualisation incrémentielle. Chaque fois que la vue matérialisée est actualisée, elle est entièrement recalculée.
Vous pouvez actualiser les vues matérialisées avec l’option CONCURRENTLY, qui met à jour le contenu de la vue matérialisée sans appliquer de verrou exclusif. Cela permet à une application SQL de lire la vue matérialisée pendant qu’elle est actualisée.
Surveillance du machine learning Aurora
Vous pouvez surveiller les fonctions aws_ml en définissant le paramètre track_functions de votre groupe de paramètres de cluster de bases de données personnalisé sur all. Par défaut, ce paramètre est défini sur pl, ce qui signifie que seules les fonctions du langage de procédure sont suivies. En le remplaçant par all, les fonctions aws_ml sont également suivies. Pour plus d'informations, consultez la section Run-time Statistiques
Pour plus d'informations sur la surveillance des performances des opérations d' SageMaker IA appelées par les fonctions d'apprentissage automatique Aurora, consultez la section Monitor Amazon SageMaker AI dans le manuel Amazon SageMaker AI Developer Guide.
Avec track_functions défini sur all, vous pouvez interroger la vue pg_stat_user_functions pour obtenir des statistiques sur les fonctions que vous définissez et utilisez pour appeler les services de machine learning Aurora. Pour chaque fonction, la vue inclut le nombre de calls, total_time et self_time.
Pour consulter les statistiques des fonctions aws_sagemaker.invoke_endpoint et aws_comprehend.detect_sentiment, vous pouvez filtrer les résultats par nom de schéma à l’aide de la requête suivante.
SELECT * FROM pg_stat_user_functions WHERE schemaname LIKE 'aws_%';
Pour effacer les statistiques, procédez comme suit.
SELECT pg_stat_reset();
Vous pouvez obtenir les noms de vos fonctions SQL qui appellent la fonction aws_sagemaker.invoke_endpoint en interrogeant le catalogue du système pg_proc de PostgreSQL. Ce catalogue contient des informations sur les fonctions, les procédures et plus encore. Pour plus d’informations, consultez pg_procproname) dont la source (prosrc) inclut le texte invoke_endpoint.
SELECT proname FROM pg_proc WHERE prosrc LIKE '%invoke_endpoint%';
