Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation de fichiers Amazon S3
Qu'est-ce que S3 Files ?
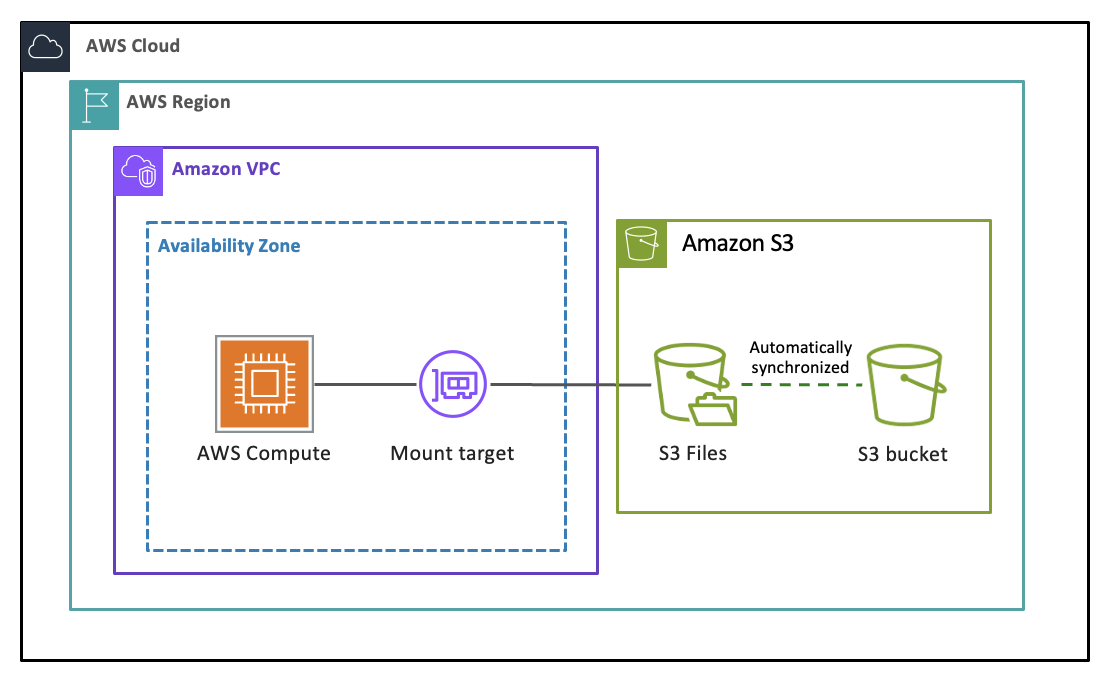
S3 Files est un système de fichiers partagé qui connecte n'importe quelle ressource de AWS calcul directement à vos données dans Amazon S3. Il fournit un accès rapide et direct à toutes vos données S3 sous forme de fichiers avec une sémantique complète du système de fichiers et des performances à faible latence, sans que vos données ne quittent S3. Chaque application, agent et équipe basés sur des fichiers peut accéder à vos données S3 et les utiliser en tant que système de fichiers à l'aide des outils dont ils dépendent déjà. Conçu à l'aide d'Amazon EFS, S3 Files vous offre les performances et la simplicité d'un système de fichiers avec l'évolutivité, la durabilité et la rentabilité de S3. Vous pouvez lire, écrire et organiser les données à l'aide d'opérations sur les fichiers et les répertoires, tandis que S3 Files gère la synchronisation des modifications entre votre compartiment et votre système de fichiers.
Comment fonctionne S3 Files ?
Lorsque vous créez un système de fichiers S3 lié à votre compartiment S3 ou à un préfixe qu'il contient et que vous le montez sur une ressource de calcul telle qu'une instance EC2 ou une fonction Lambda, S3 Files présente d'abord une vue traversable des objets de votre compartiment sous forme de fichiers. Lorsque vous parcourez les répertoires et que vous ouvrez des fichiers, les métadonnées et le contenu associés sont placés sur le stockage haute performance du système de fichiers. Lorsque vous lisez des fichiers, S3 Files charge le contenu des fichiers sur le stockage haute performance à la demande sans dupliquer l'intégralité de votre ensemble de données. Lorsque vous écrivez des données, vos écritures sont transférées vers le stockage haute performance et sont à nouveau synchronisées avec votre compartiment S3. S3 Files traduit intelligemment les opérations de votre système de fichiers en demandes S3 efficaces en votre nom. De nombreuses opérations de lecture contournent complètement le système de fichiers, les données étant diffusées directement depuis S3.
Vous pouvez configurer le seuil de taille de fichier pour ce qui est chargé sur le stockage haute performance (par défaut <128 KiB), car les latences sont les plus importantes pour les petits fichiers. S3 Files diffuse les lectures de fichiers directement depuis votre compartiment S3 dans deux cas : lorsque les données du fichier ne sont pas stockées dans le stockage haute performance du système de fichiers, et pour les lectures volumineuses supérieures ou égales à 1 MiB, même lorsque les données résident également sur le stockage haute performance du système de fichiers. Le compartiment S3 est optimisé pour un débit élevé, tandis que la couche de stockage haute performance du système de fichiers est optimisée pour un accès à faible latence. S3 Files importe de manière asynchrone les données de petits fichiers (< 128 KiB par défaut) vers le stockage haute performance du système de fichiers pour un accès à faible latence lors des lectures suivantes. Les données récemment modifiées qui n'ont pas encore été synchronisées avec S3 sont toujours diffusées depuis le système de fichiers. Pour de plus amples informations, veuillez consulter Personnalisation de la synchronisation pour les fichiers S3.
Les données qui n'ont pas été lues dans un délai configurable (1 à 365 jours, 30 par défaut) expirent automatiquement du stockage haute performance. Vos données officielles restent toujours dans S3, et la synchronisation en arrière-plan assure la cohérence du système de fichiers et du compartiment dans les deux sens. Pour de plus amples informations, veuillez consulter Comprendre le fonctionnement de la synchronisation.
Les services de calcul pris en charge pour monter vos systèmes de fichiers S3 sont Amazon EC2, AWS Lambda Amazon EKS et Amazon ECS. Pour de plus amples informations, veuillez consulter Montage de vos compartiments S3 sur des ressources de calcul.
Utilisez-vous S3 Files pour la première fois ?
Si vous utilisez S3 Files pour la première fois, créez votre premier système de fichiers S3 à l'aide de la console S3 ou de la AWS CLI en suivant leTutoriel : Débuter avec les fichiers S3.
Concepts clés
Les termes suivants sont utilisés dans la documentation de S3 Files :
- Système de fichiers
Un système de fichiers partagé lié à votre compartiment S3.
- High-performance rangement
La couche de stockage à faible latence au sein de votre système de fichiers où résident les données de fichiers et les métadonnées activement utilisées. S3 Files gère automatiquement ce stockage, en y copiant les données lorsque vous accédez à des fichiers et en supprimant les données qui n'ont pas été lues dans un délai d'expiration configurable. Vous payez un tarif de stockage pour les données résidant sur le stockage haute performance.
- Synchronisation
Processus par lequel S3 Files assure la cohérence de votre ensemble de données de travail actif et de vos modifications entre votre système de fichiers et le compartiment S3. L'importation copie les données de votre compartiment S3 vers le système de fichiers. L'exportation copie les modifications que vous apportez via le système de fichiers vers votre compartiment S3. S3 Files effectue la synchronisation automatiquement dans les deux sens.
- Cible de montage
Une cible de montage fournit un accès réseau à votre système de fichiers au sein d'une seule zone de disponibilité de votre VPC. Vous avez besoin d'au moins une cible de montage pour accéder à votre système de fichiers à partir de ressources informatiques, et vous pouvez créer un maximum d'une cible de montage par zone de disponibilité.
- Point d'accès
Les points d'accès sont des points d'entrée spécifiques à une application vers un système de fichiers qui simplifient la gestion de l'accès aux données à grande échelle pour les ensembles de données partagés. Vous pouvez utiliser les points d'accès pour renforcer les identités et les autorisations des utilisateurs pour toutes les demandes de système de fichiers effectuées via le point d'accès. Lorsque vous créez un système de fichiers à l'aide AWS de la console de gestion, S3 Files crée automatiquement un point d'accès pour le système de fichiers.
Caractéristiques
- Hautes performances sans réplication complète des données
S3 Files fournit un accès aux fichiers à faible latence en copiant uniquement votre ensemble de travail actif sur le stockage haute performance du système de fichiers, et non l'intégralité de votre ensemble de données. Les petits fichiers fréquemment consultés sont servis depuis le stockage haute performance avec des latences inférieures à une milliseconde ou à un chiffre. Les lectures volumineuses sont diffusées directement depuis S3 à un débit global pouvant atteindre plusieurs téraoctets par seconde. Cela signifie que vous bénéficiez des performances du système de fichiers pour les charges de travail interactives et du débit S3 pour les charges de travail en streaming, sans payer pour stocker ou importer des données que vous n'utilisez pas ou qui ne bénéficient pas d'une faible latence. Pour de plus amples informations, veuillez consulter Spécifications de performance.
- Routage de lecture intelligent
Les fichiers S3 acheminent automatiquement les demandes de lecture vers la couche de stockage (système de fichiers S3 ou compartiment S3) qui leur convient le mieux, tout en conservant la sémantique complète du système de fichiers, notamment la cohérence, le verrouillage et les autorisations POSIX. De petites lectures aléatoires de fichiers activement utilisés sont effectuées à partir du stockage haute performance pour une faible latence. Les lectures séquentielles importantes et les lectures de données ne figurant pas dans le système de fichiers sont effectuées directement depuis votre compartiment S3 pour un débit élevé, sans frais de données du système de fichiers.
- Synchronisation automatique
S3 Files assure automatiquement la cohérence de votre système de fichiers et de votre compartiment S3 dans les deux sens. Les modifications que vous apportez via le système de fichiers sont copiées dans votre compartiment S3, et les modifications apportées directement à votre compartiment S3 sont reflétées dans la vue de votre système de fichiers. Vous pouvez personnaliser le comportement de synchronisation, notamment les données importées et leur durée de conservation dans le système de fichiers. Pour de plus amples informations, veuillez consulter Comprendre le fonctionnement de la synchronisation.
- Performances évolutives
S3 Files adapte automatiquement le débit et les IOPS en fonction de l'activité de votre charge de travail. Vous n'avez pas besoin de fournir ou de gérer la capacité de performance et vous ne payez que pour ce que vous utilisez.
- Durabilité régionale
Les données écrites sur la couche de stockage haute performance ont la même durabilité qu'Amazon S3. Il stocke les données de manière redondante dans plusieurs zones de disponibilité géographiquement séparées au sein d'une même AWS région, offrant ainsi une durabilité et une disponibilité élevées à vos données.
- Chiffrement
S3 Files chiffre toutes les données en transit à l'aide du protocole TLS et toutes les données au repos à l'aide de clés AWS KMS. Vous pouvez utiliser des clés AWS détenues (par défaut) ou vos propres clés gérées par le client. Pour de plus amples informations, veuillez consulter Chiffrement.
- Sémantique du système de fichiers
S3 Files prend en charge les protocoles NFS version 4.2 et 4.1. Il fournit une sémantique d'accès au système de fichiers, telle que la cohérence des données en lecture après écriture, le verrouillage des fichiers et les autorisations POSIX.
Comment vous sont facturés les fichiers S3 ?
Vous payez un tarif de stockage correspondant à la fraction de données actives résidant sur le stockage haute performance, et vous payez des frais d'accès au système de fichiers pour la lecture et l'écriture sur le stockage haute performance de votre système de fichiers. S3 Files diffuse les lectures de fichiers directement depuis votre compartiment S3 dans deux cas : lorsque les données du fichier ne sont pas stockées dans le stockage haute performance du système de fichiers, et pour les lectures volumineuses supérieures ou égales à 1 MiB, même lorsque les données résident également sur le stockage haute performance du système de fichiers. Le compartiment S3 est optimisé pour un débit élevé, tandis que la couche de stockage haute performance du système de fichiers est optimisée pour un accès à faible latence. S3 Files importe de manière asynchrone les données de petits fichiers (< 128 KiB par défaut) vers le stockage haute performance du système de fichiers pour un accès à faible latence lors des lectures suivantes. Ces lectures n'entraînent que le coût des requêtes S3 GET standard, sans frais d'accès au système de fichiers. Les frais d'accès au système de fichiers s'appliquent aux opérations de synchronisation : l'importation de données dans le système de fichiers entraîne des frais d'écriture, et la réexportation des modifications vers S3 entraîne des frais de lecture. Pour de plus amples informations, veuillez consulter Comment les fichiers S3 sont mesurés. Pour connaître les tarifs actuels, consultez la page de tarification de S3 Files
