Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Qu’est-ce qu’Amazon S3 ?
Amazon Simple Storage Service (Amazon S3) est un service de stockage d’objets qui offre une capacité de mise à l’échelle, une disponibilité des données, une sécurité et des performances de pointe. Les clients de toutes tailles et secteurs peuvent utiliser Amazon S3 pour stocker et protéger toute quantité de données dans un large éventail de cas d’utilisation, par exemple des lacs de données, des sites Web, des applications mobiles, des sauvegardes et restaurations, des archives, des applications métier, des appareils IoT et l’analytique du big data. Amazon S3 offre des fonctions de gestion qui vous permettent d’optimiser, d’organiser et de configurer l’accès à vos données aux fins de répondre aux exigences spécifiques de votre entreprise, de votre organisation et de votre conformité.
Note
Pour plus d’informations sur l’utilisation de la classe de stockage Amazon S3 Express One Zone avec des compartiments de répertoires, consultez S3 Express One Zone et Utilisation des compartiments de répertoires.
Rubriques
Fonctions d’Amazon S3
Classes de stockage
Amazon S3 offre un large éventail de classes de stockage conçues pour différents cas d’utilisation. Par exemple, vous pouvez stocker les données de production critiques dans S3 Standard ou S3 Express One Zone pour un accès fréquent, réduire les coûts en stockant les données rarement consultées dans S3 Standard-IA ou S3 One, et archiver les données au moindre coût dans S3 Glacier Instant Retrieval Zone-IA, S3 Glacier Flexible Retrieval et S3 Glacier Deep Archive.
Amazon S3 Express One Zone est une classe de stockage Amazon S3 à zone unique et hautes performances, spécialement conçue pour fournir un accès aux données constant en moins de dix millisecondes pour vos applications les plus sensibles à la latence. S3 Express One Zone est la classe de stockage d’objets cloud qui présente la latence la plus faible à l’heure actuelle, avec une vitesse d’accès aux données jusqu’à 10 fois plus grande et des coûts de demande 50 % inférieurs à ceux de S3 Standard. S3 Express One Zone est la première classe de stockage S3 dans laquelle vous pouvez sélectionner une zone de disponibilité unique avec la possibilité de regrouper le stockage d’objets et les ressources de calcul, ce qui assure la vitesse d’accès la plus élevée possible. En outre, pour augmenter encore la vitesse d’accès et prendre en charge des centaines de milliers de demandes par seconde, les données sont stockées dans un nouveau type de compartiment : un compartiment de répertoires Amazon S3. Pour plus d’informations, consultez S3 Express One Zone et Utilisation des compartiments de répertoires.
Vous pouvez stocker des données dont les modèles d'accès changent ou sont inconnus dans S3 Intelligent-Tiering, ce qui optimise les coûts de stockage en déplaçant automatiquement vos données entre quatre niveaux d'accès lorsque vos modèles d'accès changent. Ces quatre niveaux d’accès comprennent deux niveaux d’accès à faible latence optimisés pour les accès fréquents et peu fréquents, et deux niveaux d’accès d’archive optionnels conçus pour un accès asynchrone pour les données rarement consultées.
Pour de plus amples informations, veuillez consulter Bien comprendre et gérer les classes de stockage Amazon S3.
Gestion du stockage
Amazon S3 dispose de fonctions de gestion du stockage que vous pouvez utiliser pour gérer les coûts, répondre aux exigences réglementaires, réduire la latence et enregistrer plusieurs copies distinctes de vos données aux fins de respecter les exigences de conformité.
-
Cycle de vie S3 : configurez une configuration de cycle de vie pour gérer vos objets et les stocker de manière rentable pendant tout leur cycle de vie. Vous pouvez transférer des objets vers d’autres classes de stockage S3 ou faire expirer des objets qui atteignent la fin de leur durée de vie.
-
Verrouillage d’objet S3 : empêchez que les objets Amazon S3 soient supprimés ou écrasés sur une période déterminée ou indéfinie. Le verrouillage des objets vous permet de satisfaire aux exigences réglementaires qui nécessitent le stockage (WORM) write-once-read-many, ou d’ajouter simplement une couche de protection contre la suppression et les modifications d’objets.
-
Réplication S3 : répliquez les objets ainsi que leurs métadonnées et balises d'objet respectives vers un ou plusieurs compartiments de destination identiques ou différents Régions AWS pour réduire la latence, la conformité, la sécurité et d'autres cas d'utilisation.
-
Opérations par lots S3 – Gérez des milliards d’objets à grande échelle avec une seule demande API S3 ou quelques clics dans la console Amazon S3. Vous pouvez utiliser Batch Operations pour effectuer des opérations telles que Copy, Invoke AWS Lambda function et Restore sur des millions ou des milliards d'objets.
Gestion des accès et sécurité
Amazon S3 fournit des fonctions d’audit et de gestion de l’accès à vos compartiments et objets. Par défaut, les compartiments S3 et les objets sont privés. Vous avez uniquement accès aux ressources S3 que vous créez. Pour accorder des autorisations de ressources granulaires prenant en charge votre cas d’utilisation spécifique ou pour vérifier les autorisations de vos ressources Amazon S3, vous pouvez utiliser les fonctions suivantes.
-
Bloquer l’accès public S3 – Bloque l’accès public aux compartiments S3 et aux objets. Par défaut, les paramètres de blocage de l’accès public sont activés au niveau du compartiment. Nous vous recommandons de laisser tous les paramètres de blocage de l’accès public activés, sauf si vous savez que vous devez en désactiver un ou plusieurs pour votre cas d’utilisation spécifique. Pour de plus amples informations, veuillez consulter Configuration des paramètres de blocage d’accès public pour vos compartiments S3.
-
Gestion des identités et des accès AWS (IAM) — IAM est un service Web qui vous permet de contrôler en toute sécurité l'accès aux AWS ressources, y compris à vos ressources Amazon S3. Avec IAM, vous pouvez gérer de manière centralisée les autorisations qui contrôlent les AWS ressources auxquelles les utilisateurs peuvent accéder. Vous pouvez utiliser IAM pour contrôler les personnes qui s’authentifient (sont connectées) et sont autorisées (disposent d’autorisations) à utiliser des ressources.
-
Politiques de compartiment : utilisez un langage de IAM-based politique pour configurer les autorisations basées sur les ressources pour vos compartiments S3 et les objets qu'ils contiennent.
-
Amazon S3 access points (Points d’accès Amazon S3) — configurez des points de terminaison réseau nommés avec des stratégies d’accès dédiées pour gérer l’accès aux données à grande échelle pour les jeux de données partagés dans Amazon S3.
-
Listes de contrôle d’accès (ACL) – Accordez des autorisations de lecture et d’écriture pour des compartiments et des objets individuels aux utilisateurs autorisés. En règle générale, nous recommandons d’utiliser des politiques basées sur les ressources S3 (politiques de compartiment et politiques de point d’accès) ou des politiques d’utilisateur IAM pour le contrôle d’accès à la place des listes ACL. Les politiques constituent une option de contrôle d’accès simplifiée et plus flexible. Les politiques de compartiment et de point d’accès vous permettent de définir des règles s’appliquant de manière générale à toutes les demandes adressées à vos ressources Amazon S3. Pour plus d’informations sur les cas spécifiques où vous devriez utiliser des listes ACL plutôt que des politiques basées sur les ressources ou des politiques d’utilisateur IAM, consultez Gestion des accès à l’aide des listes ACL.
-
Propriété d’objets S3 : prenez possession de chaque objet présent dans votre compartiment, afin de simplifier la gestion des accès aux données stockées dans Amazon S3. La propriété d’objets S3 est un paramètre Amazon S3 au niveau des compartiments que vous pouvez utiliser pour désactiver ou activer les listes ACL. Par défaut, les listes ACL sont désactivées. Lorsque les listes ACL sont désactivées, le propriétaire du compartiment détient tous les objets présents dans le compartiment et gère l’accès aux données exclusivement à l’aide de politiques de gestion des accès.
-
Analyseur d’accès IAM pour S3 : évaluez et contrôlez vos politiques d’accès aux compartiments S3, en veillant à ce que ces politiques fournissent uniquement l’accès prévu à vos ressources S3.
Traitement des données
Pour transformer les données et déclencher des flux de travail afin d’automatiser diverses autres activités de traitement à grande échelle, vous pouvez utiliser les fonctions suivantes.
-
S3 Object Lambda – ajoutez votre propre code aux requêtes S3 GET, HEAD et LIST afin de modifier et de traiter les données lorsqu’elles sont renvoyées vers une application. Filtrez les lignes, redimensionnez dynamiquement les images, supprimez les données confidentielles et bien plus encore.
-
Notifications d'événements : déclenchez des flux de travail qui utilisent Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue Service (Amazon SQS) et lorsqu'une modification AWS Lambda est apportée à vos ressources S3.
Journalisation et surveillance du stockage
Amazon S3 fournit des outils de journalisation et de surveillance que vous pouvez utiliser pour surveiller et contrôler la façon dont vos ressources Amazon S3 sont utilisées. Pour plus d’informations, consultez Outils de surveillance.
Outils de surveillance automatique
-
Amazon CloudWatch Metrics for Amazon S3 — Suivez l'état de fonctionnement de vos ressources S3 et configurez des alertes de facturation lorsque les frais estimés atteignent un seuil défini par l'utilisateur.
-
AWS CloudTrail— Enregistrez les actions effectuées par un utilisateur, un rôle ou un Service AWS dans Amazon S3. CloudTrail les journaux vous fournissent un suivi détaillé des API pour les opérations au niveau du bucket S3 et au niveau de l'objet.
Outils de surveillance manuelle
-
La journalisation des accès au serveur fournit des enregistrements détaillés pour les demandes soumises à un compartiment. Vous pouvez utiliser les journaux d’accès au serveur pour des audits de sécurité et d’accès, afin d’en savoir plus sur votre base de clients et pour comprendre votre facture Amazon S3.
-
AWS Trusted Advisor : évaluez votre compte à l'aide de vérifications des AWS meilleures pratiques pour identifier les moyens d'optimiser votre AWS infrastructure, d'améliorer la sécurité et les performances, de réduire les coûts et de surveiller les quotas de service. Vous pouvez ensuite suivre les recommandations pour optimiser vos services et vos ressources.
Analytique et informations
Amazon S3 offre des fonctions qui vous aident à gagner en visibilité sur l’utilisation de votre stockage, ce qui vous permet de mieux comprendre, analyser et optimiser votre stockage à grande échelle.
-
Amazon S3 Storage Lens : comprenez, analysez et optimisez votre stockage. S3 Storage Lens fournit plus de 60 indicateurs d'utilisation et d'activité ainsi que des tableaux de bord interactifs pour agréger les données relatives à l'ensemble de votre organisation, à des comptes Régions AWS, à des compartiments ou à des préfixes spécifiques.
-
Analyse de classe de stockage : analysez les modèles d’accès au stockage afin de décider lorsqu’il est temps de déplacer vos données vers une classe de stockage plus économique.
-
Inventaire S3 avec rapports d’inventaire : auditez et produisez des rapports sur les objets et leurs métadonnées correspondantes, et configurez d’autres fonctions Amazon S3 pour qu’elles agissent dans les rapports d’inventaire. Par exemple, vous pouvez signaler le statut de réplication et de chiffrement de vos objets. Pour obtenir la liste de toutes les métadonnées disponibles pour chaque objet dans les rapports d’inventaire, consultez Liste d’inventaire Amazon S3.
Forte cohérence
Amazon S3 assure une forte cohérence entre lecture après écriture pour les requêtes PUT et DELETE relatives à l'ensemble des objets de votre compartiment Amazon S3. Régions AWS Cela s’applique à la fois aux écritures sur de nouveaux objets ainsi qu’aux opérations PUT qui écrasent les objets existants et aux opérations DELETE. En outre, les opérations de lecture sur Amazon S3 Select, les listes de contrôle d’accès Amazon S3, les balises d’objet Amazon S3 et les métadonnées d’objet (par exemple l’objet HEAD) sont fortement cohérentes. Pour plus d’informations, consultez Modèle de cohérence des données Amazon S3.
Fonctionnement d’Amazon S3
Amazon S3 est un service de stockage d’objets qui stocke les données en tant qu’objets, données hiérarchiques, ou données tabulaires dans des compartiments. Un objet est un fichier et toutes les métadonnées qui le décrivent. Un compartiment est un conteneur d’objets.
Pour stocker vos données dans Amazon S3, vous devez d’abord créer un compartiment et spécifier un nom de compartiment et une Région AWS. Ensuite, vous chargez vos données dans ce compartiment en tant qu’objets dans Amazon S3. Chaque objet possède une key (clé) (ou key name [nom de clé]), qui est l’identifiant unique d’un objet au sein d’un compartiment.
S3 propose des fonctionnalités que vous pouvez configurer pour prendre en charge votre cas d’utilisation spécifique. Par exemple, vous pouvez utiliser la gestion des versions S3 pour conserver plusieurs versions d’un objet dans un même compartiment et vous permettre de restaurer des objets qui sont accidentellement supprimés ou écrasés.
Les compartiments et les objets qu’ils contiennent sont privés et ne sont accessibles que si vous accordez explicitement des autorisations d’accès. Vous pouvez utiliser des politiques de compartiment, des politiques Gestion des identités et des accès AWS (IAM), des listes de contrôle d'accès (ACL) et des points d'accès S3 pour gérer l'accès.
Rubriques
Compartiments
Amazon S3 prend en charge quatre types de compartiments : les compartiments à usage général, les compartiments de répertoires, les compartiments de table et les compartiments de vecteur. Chaque type de compartiment fournit un ensemble unique de fonctionnalités répondant à différents cas d’utilisation.
Compartiments à usage général : les compartiments à usage général sont recommandés pour la plupart des cas d’utilisation et les modèles d’accès, et sont le type de compartiment S3 d’origine. Un compartiment à usage général est un conteneur pour les objets stockés dans Amazon S3. Vous pouvez stocker autant d’objets que vous le souhaitez dans un compartiment et dans toutes les classes de stockage (à l’exception de S3 Express One Zone). Vous pouvez ainsi stocker des objets de manière redondante dans plusieurs zones de disponibilité. Pour plus d’informations, consultez Création, configuration et utilisation des compartiments à usage général Amazon S3.
Par défaut, les compartiments à usage général existent dans un espace de noms global, ce qui signifie que chaque nom de compartiment doit être unique Comptes AWS Régions AWS dans l'ensemble d'une partition. Une partition est un regroupement de régions. AWS possède actuellement quatre partitions : aws (Régions standard), aws-cn (Régions de Chine), aws-us-gov (AWS GovCloud (US)) et aws-eusc (European Sovereign Cloud). Lorsque vous créez un bucket à usage général, vous pouvez choisir de créer un bucket dans l'espace de noms global partagé ou de créer un bucket dans l'espace de noms régional de votre compte. L'espace de noms régional de votre compte est une subdivision de l'espace de noms global dans lequel seul votre compte peut créer des buckets. Les nouveaux compartiments à usage général créés dans l'espace de noms régional de votre compte sont propres à votre compte et ne peuvent jamais être recréés par un autre compte. Pour plus d'informations sur les espaces de noms de compartiments, consultez la section Espaces de noms pour les compartiments à usage général.
Note
Par défaut, tous les compartiments à usage général sont privés. Vous pouvez toutefois autoriser l’accès public à des compartiments à usage général. Vous pouvez contrôler l’accès aux compartiments à usage général peut être définie au niveau du compartiment, du préfixe (dossier) ou de la balise d’objet. Pour plus d’informations, consultez Contrôle d’accès dans Amazon S3.
Compartiments de répertoires : recommandés pour les cas d’utilisation à faible latence et les cas d’utilisation liés à la résidence des données. Par défaut, vous pouvez créer jusqu’à 100 compartiments de répertoires dans votre Compte AWS, sans limite quant au nombre d’objets que vous pouvez stocker dans un compartiment de répertoires. Les compartiments de répertoires organisent les objets dans des répertoires hiérarchiques (préfixes) dans des répertoires, contrairement à la structure de stockage horizontale des compartiments à usage général. Ce type de compartiment ne comporte pas de limite de préfixe et les répertoires individuels peuvent faire l’objet d’une mise à l’échelle horizontale. Pour plus d’informations, consultez Utilisation des compartiments de répertoires.
-
Pour les cas d'utilisation à faible latence, vous pouvez créer un bucket d'annuaire dans une seule zone de AWS disponibilité pour stocker les données. Les compartiments de répertoires figurant dans des zones de disponibilité prennent en charge la classe de stockage S3 Express One Zone. Avec S3 Express One Zone, vos données sont stockées de façon redondante sur plusieurs appareils au sein d’une même zone de disponibilité. La classe de stockage S3 Express One Zone est recommandée si votre application est sensible aux performances et peut bénéficier d’une latence inférieure à dix millisecondes pour les demandes
PUTetGET. Pour en savoir plus sur la création de compartiments de répertoires dans les zones de disponibilité, consultez Charges de travail hautes performances. -
Pour les cas d'utilisation liés à la résidence des données, vous pouvez créer un bucket de répertoire dans une seule zone locale AWS dédiée (DLZ) pour stocker les données. Dans les zones locales dédiées, vous pouvez créer des compartiments de répertoires S3 pour stocker les données dans un périmètre de sécurisation des données spécifique, afin de répondre à vos cas d’utilisation liés à la résidence des données et à leur isolement. Les compartiments de répertoire situés dans les Zones Locales prennent en charge la classe de stockage S3 One Zone-Infrequent Access (S3 One Zone-IA ; Z-IA). Pour en savoir plus sur la création de compartiments de répertoires dans Local Zones, consultez Charges de travail liées à la résidence des données.
Note
L’accès public aux compartiments de répertoires est désactivé par défaut. Ce comportement ne peut pas être modifié. Vous ne pouvez pas autoriser l’accès aux objets stockés dans des compartiments de répertoires. Vous pouvez accorder l’accès uniquement à vos compartiments de répertoires. Pour plus d’informations, consultez Authentification et autorisation des demandes.
Compartiments de table : recommandé pour stocker des données tabulaires, telles que des transactions d’achat quotidiennes, des données de capteur diffusées en continu ou des impressions publicitaires. Les données tabulaires représentent des données en colonnes et en lignes, comme dans une table de base de données. Les compartiments de table fournissent un stockage S3 optimisé pour les charges de travail d’analytique et de machine learning, avec des fonctionnalités conçues pour améliorer en permanence les performances des requêtes et réduire les coûts de stockage des tables. S3 Tables est spécialement conçu pour stocker des données tabulaires au format Apache Iceberg. Vous pouvez interroger des données tabulaires dans les tables S3 à l'aide des moteurs de requête populaires, notamment Amazon Athena Amazon Redshift, et Apache Spark. Par défaut, vous pouvez créer jusqu'à 10 compartiments de tables Compte AWS par personne Région AWS et jusqu'à 10 000 tables par compartiment de table. Pour plus d’informations, consultez Utilisation de S3 Tables et des compartiments de table.
Note
Tous les compartiments de table et toutes les tables sont privés et ne peuvent pas être rendus publics. Ces ressources sont accessibles uniquement par les utilisateurs auxquels l’accès a été accordé explicitement. Pour accorder l’accès, vous pouvez utiliser des politiques basées sur les ressources IAM pour les compartiments de tables et les tables, et des politiques basées sur l’identité IAM pour les utilisateurs et les rôles. Pour plus d’informations, consultez Sécurité de S3 Tables.
Compartiments de vecteur : les compartiments de vecteur S3 sont un type de compartiment Amazon S3 conçu spécialement pour stocker et interroger les vecteurs. Les compartiments de vecteur utilisent des opérations d’API dédiées pour écrire et interroger des données vectorielles de manière efficace. Avec les compartiments vectoriels S3, vous pouvez stocker des intégrations vectorielles pour les modèles d'apprentissage automatique, effectuer des recherches de similarité et intégrer des services tels qu'Amazon Bedrock et Amazon. OpenSearch
Les compartiments de vecteur S3 organisent les données à l’aide d’index vectoriels, qui sont des ressources dans un compartiment qui stockent et organisent les données vectorielles pour une recherche de similarité efficace. Chaque index vectoriel peut être configuré avec des dimensions, des métriques de distance (comme la similarité des cosinus) et des configurations de métadonnées spécifiques afin de l’optimiser pour votre cas d’utilisation spécifique. Pour de plus amples informations, veuillez consulter Utilisation de S3 Vectors et de compartiments de vecteur.
Informations supplémentaires sur tous les types de compartiments
Lorsque vous créez un compartiment, vous saisissez un nom de compartiment et choisissez la Région AWS où se trouve le compartiment. Une fois un compartiment créé, vous ne pouvez pas modifier son nom ni sa Région. Les noms de compartiments doivent suivre les règles de dénomination de compartiment :
Les compartiments aussi :
-
Organisez l’espace de noms Amazon S3 au niveau le plus élevé. Pour les compartiments à usage général, cet espace de noms est
S3. Pour les compartiments de répertoire, cet espace de noms ests3express. Pour les compartiments de table, cet espace de noms ests3tables. -
Identifiez le responsable de compte pour les frais de stockage et de transfert de données.
-
Sert d’unité de regroupement pour les rapports d’utilisation.
Objets
Les objets sont les entités fondamentales stockées dans Amazon S3. Les objets sont composés de données et de métadonnées. Les métadonnées sont un ensemble de paires nom-valeur décrivant des objets. Ces pairs comprennent certaines métadonnées par défaut telles que la date de la dernière modification et des métadonnées HTTP standard comme Content-Type. Vous pouvez aussi spécifier des métadonnées personnalisées au moment du stockage de l’objet.
Chaque objet est contenu dans un compartiment. Par exemple, si l’objet nommé photos/puppy.jpg est stocké dans le compartiment à usage général amzn-s3-demo-bucket, dans la région USA Ouest (Oregon), il est adressable à l’aide de l’URL https://amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpg. Pour plus d’informations, consultez Accès à un compartiment.
Un objet est identifié de manière unique dans un compartiment par clé (nom) et un ID de version (si la gestion des versions S3 est activée sur le compartiment). Pour en savoir plus sur les objets, consultez Présentation des objets Amazon S3.
Clés
Une clé d’objet (ou nom de clé) est l’identifiant unique d’un objet au sein d’un compartiment. Chaque objet d’un compartiment possède une clé et une seule. La combinaison d’un compartiment, d’une clé d’objet et éventuellement d’un ID de version (si la gestion des versions S3 est activée pour le compartiment) identifie de manière unique chaque objet. Vous pouvez donc considérer Amazon S3 comme un mappage de données entre « compartiment + clé + version » et l’objet lui-même.
Chaque objet Amazon S3 peut être adressé de manière unique via la combinaison du point de terminaison du service web, du nom du compartiment, de la clé et, le cas échéant, d’une version. Par exemple, dans l’URL https://, « amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpgamzn-s3-demo-bucketphotos/puppy.jpg » est la clé.
Pour en savoir plus sur les clés d’objet, consultez Attribution d’un nom aux objets Amazon S3.
Gestion des versions S3
Vous pouvez utiliser la gestion des versions S3 pour conserver plusieurs variantes d’un objet dans le même compartiment. Vous pouvez utiliser la gestion des versions S3 pour préserver, récupérer et restaurer chaque version de chaque objet stocké dans vos compartiments. Vous pouvez facilement récupérer les données en cas d’actions involontaires des utilisateurs ou de défaillances des applications.
Pour plus d’informations, consultez Conservation de plusieurs versions d’objets grâce à la gestion des versions S3.
ID de version
Lorsque vous activez la gestion des versions S3 pour un compartiment, Amazon S3 génère un ID de version unique pour chaque objet ajouté au compartiment. Les objets qui existaient déjà dans le compartiment au moment où vous activez la gestion des versions ont un ID de version égal à null. Si vous modifiez ces objets (ou tout autre) par d'autres opérations, telles que CopyObjectet PutObject, les nouveaux objets obtiennent un ID de version unique.
Pour de plus amples informations, veuillez consulter Conservation de plusieurs versions d’objets grâce à la gestion des versions S3.
Politique de compartiment
Une politique de compartiment est une politique basée sur les ressources Gestion des identités et des accès AWS (IAM) que vous pouvez utiliser pour accorder des autorisations d'accès à votre compartiment et aux objets qu'il contient. Seul le propriétaire du compartiment peut associer une politique à un compartiment. Les autorisations attachées au compartiment s’appliquent à tous les objets du compartiment appartenant au compte propriétaire du compartiment. Les politiques de compartiment sont limitées à une taille de 20 Ko.
Les politiques de compartiment utilisent JSON-based un langage de politique d'accès standard dans tous les domaines AWS. Vous pouvez utiliser des politiques de compartiment pour ajouter ou refuser des autorisations pour les objets d’un compartiment. Les politiques de compartiment autorisent ou rejettent les demandes basées sur les éléments de la stratégie, y compris le demandeur, les actions S3, les ressources et les aspects ou conditions de la demande (par exemple, l’adresse IP utilisée pour effectuer la demande). Par exemple, vous pouvez créer une politique de compartiment qui accorde des autorisations entre comptes pour charger des objets vers un compartiment S3 tout en veillant à ce que le propriétaire du compartiment ait le contrôle total des objets téléchargés. Pour plus d’informations, consultez Exemples de politiques de compartiment Amazon S3.
Dans votre politique de compartiment, vous pouvez utiliser des caractères génériques sur des Amazon Resource Names (ARN) et d’autres valeurs pour accorder des autorisations à un sous-ensemble d’objets. Par exemple, vous pouvez contrôler l’accès aux groupes d’objets qui commencent par un préfixecourant ou se terminent par une extension donnée, comme .html.
Points d’accès S3
Les points d’accès Amazon S3 sont nommés points de terminaison réseau avec des stratégies d’accès dédiées qui décrivent comment accéder aux données à l’aide de ce point de terminaison. Les points d’accès sont rattachés à une source de données sous-jacente, comme par exemple un compartiment à usage général, un compartiment de répertoires ou un volume FSx pour OpenZFS, que vous pouvez utiliser pour effectuer des opérations sur des objets S3, comme GetObject et PutObject. Les points d'accès simplifient la gestion de l'accès aux données à grande échelle pour les ensembles de données partagés dans Amazon S3.
Chaque point d’accès dispose de sa propre stratégie d’accès. Vous pouvez configurer des paramètres de Blocage de l’accès public pour chaque point d’accès attaché au compartiment. Vous pouvez configurer n’importe quel point d’accès pour accepter uniquement les demandes provenant d’un cloud privé virtuel (VPC) afin de restreindre l’accès aux données Amazon S3 à un réseau privé.
Pour plus d’informations sur les points d’accès pour les compartiments à usage général, consultez Gestion de l’accès aux jeux de données avec des points d’accès. Pour plus d’informations sur les points d’accès pour les compartiments de répertoires, consultez Gestion des accès aux jeux de données partagés dans des compartiments de répertoires avec des points d’accès.
Listes de contrôle d’accès (ACL)
Vous pouvez utiliser des ACL pour accorder des autorisations de lecture et d’écriture aux utilisateurs autorisés pour des compartiments à usage général et des objets individuels. Chaque compartiment à usage général et objet possède une ACL qui lui est attachée comme sous-ressource. L'ACL définit le Comptes AWS ou les groupes auxquels l'accès est accordé et le type d'accès. Les ACL représentent un mécanisme de contrôle d’accès qui précède les politiques IAM. Pour en savoir plus sur les listes ACL, consultez Présentation de la liste de contrôle d’accès (ACL).
La propriété d'objets S3 est un paramètre Amazon S3 au niveau des compartiments que vous pouvez utiliser pour contrôler la propriété des objets qui sont chargés dans votre compartiment, ainsi que pour désactiver ou activer les listes ACL. Par défaut, la propriété des objets est définie sur le paramètre Propriétaire du compartiment appliqué et toutes les listes ACL sont désactivées. Lorsque les ACL sont désactivées, le propriétaire du compartiment détient tous les objets du compartiment et gère leur accès exclusivement au moyen de politiques de gestion des accès.
La majorité des cas d’utilisation modernes dans Amazon S3 ne nécessitent plus l’utilisation des listes ACL. Nous vous recommandons de maintenir les listes ACL désactivées, sauf si vous devez contrôler individuellement l’accès à chaque objet. Lorsque les listes ACL sont désactivées, vous pouvez utiliser des politiques pour contrôler l’accès à tous les objets de votre compartiment, quelle que soit la personne qui les a chargés dans votre compartiment. Pour plus d’informations, consultez Consultez Contrôle de la propriété des objets et désactivation des listes ACL pour votre compartiment.
Régions
Vous pouvez choisir la zone géographique Région AWS dans laquelle Amazon S3 stocke les buckets que vous créez. Vous pouvez choisir une Région pour optimiser la latence, minimiser les coûts ou répondre aux exigences réglementaires. Les objets stockés dans une région Région AWS ne quittent jamais la région, sauf si vous les transférez ou les répliquez explicitement dans une autre région. Par exemple, les objets stockés dans la Région Europe (Irlande) ne la quittent jamais.
Note
Vous pouvez accéder à Amazon S3 et à ses fonctionnalités uniquement dans Régions AWS les zones activées pour votre compte. Pour plus d'informations sur la façon de permettre à une région de créer et de gérer AWS des ressources, consultez Gérer Régions AWS dans le Références générales AWS.
Pour obtenir la liste des points de terminaison et des régions Amazon S3 disponibles, consultez Régions et points de terminaison dans la Références générales AWS.
Modèle de cohérence des données Amazon S3
Amazon S3 assure une forte cohérence entre lecture après écriture pour les requêtes PUT et DELETE relatives à l'ensemble des objets de votre compartiment Amazon S3. Régions AWS Cela s’applique à la fois aux écritures sur de nouveaux objets ainsi qu’aux demandes PUT qui écrasent les objets existants et aux demandes DELETE. En outre, les opérations de lecture sur Amazon S3 Select, les listes de contrôle d’accès (ACL) Amazon S3, les balises d’objet Amazon S3 et les métadonnées d’objet (par exemple l’objet HEAD) sont fortement cohérentes.
Les mises à jour d’une seule clé sont atomiques. Par exemple, si vous faites une demande PUT sur une clé existante d’un thread et exécutez simultanément une demande GET sur la même clé à partir d’un second thread, vous obtiendrez les anciennes données ou les nouvelles données, mais jamais des données partielles ni corrompues.
Amazon S3 garantit une haute disponibilité en répliquant les données sur plusieurs serveurs dans les centres de données AWS . Si une demande PUT aboutit, vos données sont stockées en toute sécurité. Toute lecture (demandes GET ou LIST) initiée après la réception d’une réponse PUT réussie retournera les données écrites par la demande PUT. Voici des exemples de ce comportement :
-
Un processus écrit un nouvel objet sur Amazon S3 et dresse immédiatement une liste des clés dans ce compartiment. Le nouvel objet s’affiche dans la liste.
-
Un processus remplace un objet existant et tente immédiatement de le lire. Amazon S3 retourne les nouvelles données.
-
Un processus efface un objet existant et tente immédiatement de le lire. Amazon S3 ne retourne aucune donnée, car l’objet a été supprimé.
-
Un processus efface un objet existant et dresse immédiatement une liste des clés dans ce compartiment. L’objet ne s’affiche pas dans la liste.
Note
-
Amazon S3 ne prend pas en charge le verrouillage d’objet pour les auteurs simultanés. Si deux demandes PUT sont effectuées simultanément sur la même clé, la demande indiquant l’horodatage le plus récent est retenue. Si cela pose un problème, vous devrez créer un mécanisme de verrouillage d’objet à votre application.
-
Les mises à jour sont basées sur les clés. Il n’est pas possible d’effectuer des mises à jour atomiques sur plusieurs clés. Par exemple, vous ne pouvez pas mettre à jour une clé qui dépend de la mise à jour d’une autre clé, sauf si vous intégrez cette fonctionnalité dans votre application.
Les configurations de compartiment ont un modèle de cohérence éventuelle. Plus précisément, cela signifie que :
-
Si vous supprimez un compartiment et répertoriez immédiatement tous les compartiments, il est possible que le compartiment supprimé figure toujours dans la liste.
-
Si vous activez la gestion des versions sur un compartiment pour la première fois, la propagation complète de la modification peut prendre un court laps de temps. Nous vous recommandons d’attendre 15 minutes après l’activation de la gestion des versions avant d’exécuter des opérations d’écriture (demandes PUT ou DELETE) sur les objets du compartiment.
Applications simultanées
Cette section fournit des exemples de comportement à attendre de la part d’Amazon S3 lorsque plusieurs clients écrivent sur les mêmes éléments.
Dans cet exemple, W1 (écriture 1) et W2 (écriture 2) s’achèvent avant le début de R1 (lecture 1) et R2 (lecture 2). Comme S3 est fortement cohérent, R1 et R2 retournent tous les deux color = ruby.
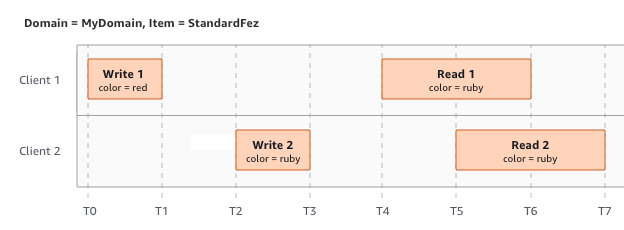
Dans l’exemple suivant, W2 ne s’achève pas avant le début de R1. Par conséquent, R1 peut renvoyer color = ruby ou color = garnet. Cependant, puisque W1 et W2 se terminent avant le début de R2, R2 renvoie color =
garnet.
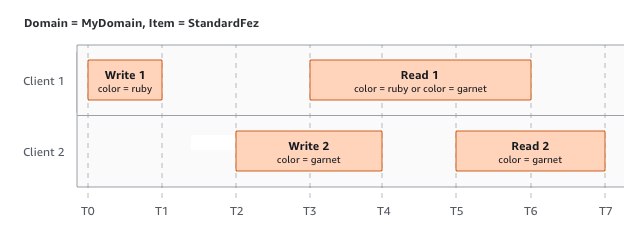
Dans le dernier exemple, W2 commence avant que W1 ait reçu un accusé de réception. Par conséquent, ces écritures sont considérées comme simultanées. Amazon S3 utilise en interne la sémantique « priorité à la dernière écriture » pour déterminer quelle écriture a priorité. Toutefois, l’ordre dans lequel Amazon S3 reçoit les demandes et l’ordre dans lequel les applications reçoivent des accusés de réception ne peuvent pas être prédits en raison de différents facteurs, comme la latence réseau. Par exemple, W2 peut être initié par une instance Amazon EC2 dans la même Région alors que W1 peut être initié par un hôte plus éloigné. La meilleure façon de déterminer la valeur finale consiste à effectuer la lecture une fois les deux écritures reconnues.

Services connexes
Après avoir chargé vos données dans Amazon S3, vous pouvez les utiliser avec d'autres AWS services. Les services suivants sont ceux que vous êtes susceptibles d’utiliser le plus fréquemment :
-
Amazon Elastic Compute Cloud (Amazon EC2)
— offre une capacité de calcul évolutive dans le AWS Cloud. L’utilisation d’Amazon EC2 vous dispense d’investir à l’avance dans du matériel et, par conséquent, vous pouvez développer et déployer les applications plus rapidement. Vous pouvez utiliser Amazon EC2 pour lancer autant de serveurs virtuels que nécessaire, configurer la sécurité et les réseaux, et gérer le stockage. -
Amazon EMR
: permet aux entreprises, aux chercheurs, aux analystes de données et aux développeurs de traiter de grandes quantités de données de manière simple et économique. Amazon EMR utilise un framework Hadoop hébergé qui s’exécute sur l’infrastructure à l’échelle du web d’Amazon EC2 et d’Amazon S3. -
AWS Transfer Family
: fournit une prise en charge entièrement gérée des transferts de fichiers directement vers et depuis Amazon S3 ou Amazon Elastic File System (Amazon EFS) à l’aide du protocole File Transfer Protocol (SFTP) Secure Shell (SSH), du protocole File Transfer Protocol over SSL (FTPS) et du protocole File Transfer Protocol (FTP).
Accès à Amazon S3
Vous pouvez utiliser Amazon S3 de l’une des façons suivantes :
Console de gestion AWS
La console est une interface utilisateur Web permettant de gérer Amazon S3 et ses AWS ressources. Si vous vous êtes inscrit à un Compte AWS, vous pouvez accéder à la console Amazon S3 en vous connectant au Console de gestion AWS et en choisissant S3 sur la page d' Console de gestion AWS accueil.
AWS Command Line Interface
Vous pouvez utiliser les outils de ligne de AWS commande pour émettre des commandes ou créer des scripts sur la ligne de commande de votre système afin d'effectuer des tâches AWS (y compris S3).
Le AWS Command Line Interface (AWS CLI)
AWS Kits SDK
AWS fournit des SDK (kits de développement logiciel) composés de bibliothèques et d'exemples de code pour différents langages de programmation et plateformes (Java, Python, Ruby, .NET, iOS, Android, etc.). Les AWS SDK constituent un moyen pratique de créer un accès programmatique à S3 et. AWS Amazon S3 est un service REST. Vous pouvez envoyer des demandes à Amazon S3 à l'aide des bibliothèques du AWS SDK, qui encapsulent l'API REST Amazon S3 sous-jacente et simplifient vos tâches de programmation. Par exemple, ils automatisent les tâches comme le calcul de signatures, la signature cryptographique des demandes, la gestion des erreurs et les nouvelles tentatives automatiques de demande. Pour plus d'informations sur les AWS SDK, notamment sur la façon de les télécharger et de les installer, consultez la section Outils pour AWS
Chaque interaction avec Amazon S3 est authentifiée ou anonyme. Si vous utilisez les AWS SDK, les bibliothèques calculent la signature pour l'authentification à partir des clés que vous fournissez. Pour plus d’informations sur la façon d’adresser des demandes à Amazon S3, consultez Envoi de demandes.
API REST Amazon S3
L’architecture d’Amazon S3 a été conçue de manière à être neutre en termes de langage de programmation et utilise nos interfaces supportées par AWS pour stocker et récupérer des objets. Vous pouvez accéder à S3 et à AWS par programmation à l’aide de l’API REST Amazon S3. L’API REST est une interface HTTP pour Amazon S3. Lorsque vous utilisez l’API REST, vous utilisez des demandes HTTP standard pour créer, récupérer et supprimer des compartiments et des objets.
Pour utiliser l’API REST, vous pouvez choisir n’importe quelle boîte à outils prenant en charge HTTP. Vous pouvez même utiliser un explorateur pour récupérer des objets, si ceux-ci peuvent être lus de manière anonyme.
L’API REST utilise les codes de statut et en-têtes HTTP standard afin de permettre aux explorateurs et boîtes à outils classiques de fonctionner. Dans certains zones, nous avons ajouté des fonctionnalités à HTTP (par exemple, nous avons ajouté des en-têtes afin de permettre le contrôle d’accès). Dans ces cas précis, nous avons fait notre possible pour intégrer cette nouvelle fonctionnalité de sorte qu’elle corresponde à la manière dont HTTP est généralement utilisé.
Si vous faites des appels directs d’API REST dans votre application, vous devez écrire le code pour calculer la signature et l’ajouter à la demande. Pour plus d’informations sur la façon d’adresser des demandes à Amazon S3, consultez Envoi de demandes dans la Référence d’API Amazon S3.
Note
Le support de l’API SOAP via HTTP est obsolète, mais continue d’être disponible sur HTTPS. Les nouvelles fonctions Amazon S3 ne sont pas prises en charge pour SOAP. Nous vous recommandons d'utiliser l'API REST ou les AWS SDK.
Paiement pour Amazon S3
La tarification d’Amazon S3 est conçue de sorte que vous n’avez pas à planifier les besoins en stockage de votre application. La plupart des fournisseurs de stockage exigent que vous achetiez une quantité prédéterminée de capacité de stockage et de transfert réseau. Dans ce scénario, si vous dépassez cette capacité, votre service est fermé ou vous devez payer des coûts supplémentaires élevés. Si vous ne dépassez pas cette limite, vous payerez malgré tout comme si vous l’aviez pleinement utilisée.
Amazon S3 ne facture que ce que vous avez utilisé et il n’y a aucuns frais cachés ou supplémentaires. Ce modèle vous fournit un service à coût variable qui peut évoluer avec votre activité tout en vous offrant les avantages financiers de l'infrastructure. AWS Pour plus d’informations, consultez Tarification Amazon S3
Lorsque vous vous inscrivez AWS, vous êtes automatiquement Compte AWS inscrit à tous les services AWS, y compris Amazon S3. Toutefois, seuls les services que vous utilisez vous sont facturés. Si vous êtes un nouveau client Amazon S3, vous pouvez commencer à utiliser Amazon S3 gratuitement. Pour plus d’informations, consultez la page sur l’offre gratuite AWS
Pour consulter votre facture, dirigez-vous vers le Tableau de bord de gestion des coûts et de la facturation dans la AWS Billing and Cost Management console
Conformité PCI DSS
Amazon S3 prend en charge le traitement, le stockage et la transmission des données de cartes bancaires par un commerçant ou un fournisseur de services et a été validé comme étant conforme à la norme PCI (Payment Card Industry) DSS (Data Security Standard). Pour plus d'informations sur la norme PCI DSS, notamment sur la manière de demander une copie du Package de AWS conformité PCI, consultez la section PCI
