Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Migration des données de l'entrepôt de données sur site vers Amazon Redshift avec AWS Schema Conversion Tool
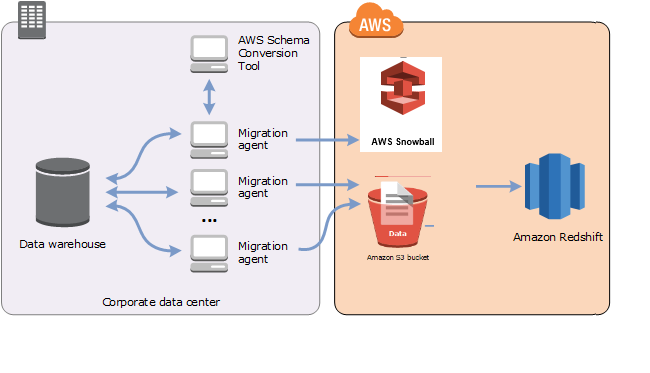
Vous pouvez utiliser un AWS SCT agent pour extraire les données de votre entrepôt de données sur site et les migrer vers Amazon Redshift. L'agent extrait vos données et les télécharge sur Amazon S3 ou, pour les migrations à grande échelle, sur un appareil AWS Snowball Edge Edge. Vous pouvez ensuite utiliser un AWS SCT agent pour copier les données sur Amazon Redshift.
Vous pouvez également utiliser AWS Database Migration Service (AWS DMS) pour migrer des données vers Amazon Redshift. L'avantage de AWS DMS est la prise en charge de la réplication continue (capture des données de modification). Toutefois, pour accélérer la migration des données, utilisez plusieurs AWS SCT agents en parallèle. Selon nos tests, les AWS SCT agents migrent les données plus rapidement que AWS DMS de 15 à 35 %. La différence de vitesse est due à la compression des données, à la prise en charge de la migration des partitions de table en parallèle et aux différents paramètres de configuration. Pour plus d’informations, consultez Utilisation d’une base de données Amazon Redshift comme cible pour AWS Database Migration Service.
Amazon S3 est un service de stockage et d'extraction. Pour stocker un objet dans Amazon S3, vous chargez le fichier correspondant dans un compartiment Amazon S3. Lorsque vous chargez un fichier, vous pouvez définir les autorisations sur l'objet, ainsi que celles liées aux métadonnées.
Migrations à grande échelle
Les migrations de données à grande échelle peuvent inclure de nombreux téraoctets d'informations et peuvent être ralenties par les performances du réseau et par la quantité de données à déplacer. AWS Snowball Edge Edge est un AWS service que vous pouvez utiliser pour transférer des données vers le cloud à faster-than-network grande vitesse à l'aide d'une appliance AWS appartenant à votre propriétaire. Un appareil AWS Snowball Edge Edge peut contenir jusqu'à 100 To de données. Il utilise un cryptage 256 bits et un module TPM (Trusted Platform Module) conforme aux normes du secteur pour garantir à la fois la sécurité et l'intégralité chain-of-custody de vos données. AWS SCT fonctionne avec les appareils AWS Snowball Edge Edge.
Lorsque vous utilisez AWS SCT un appareil AWS Snowball Edge Edge, vous migrez vos données en deux étapes. Tout d'abord, AWS SCT vous traitez les données localement, puis vous les déplacez vers le périphérique AWS Snowball Edge Edge. Vous envoyez ensuite l'appareil à AWS l'aide du processus AWS Snowball Edge Edge, puis vous chargez AWS automatiquement les données dans un compartiment Amazon S3. Ensuite, lorsque les données sont disponibles sur Amazon S3, vous pouvez les migrer AWS SCT vers Amazon Redshift. Les agents d'extraction de données peuvent travailler en arrière-plan lorsqu' AWS SCT il est fermé.
Le schéma suivant illustre le scénario pris en charge.
Les agents d'extraction de données sont actuellement pris en charge pour les entrepôts de données source suivants :
Analyses Azure Synapse
BigQuery
Base de données Greenplum (version 4.3)
Microsoft SQL Server (version 2008 et supérieure)
Netezza (version 7.0.3 et supérieure)
Oracle (version 10 et supérieure)
Flocon de neige (version 3)
Teradata (version 13 et supérieure)
Vertica (version 7.2.2 et supérieure)
Vous pouvez vous connecter aux points de terminaison FIPS pour Amazon Redshift si vous devez vous conformer aux exigences de sécurité de la Federal Information Processing Standard (FIPS). Les points de terminaison FIPS sont disponibles dans les régions suivantes : AWS
Région de l'Est des États-Unis (Virginie du Nord) (redshift-fips.us-east-1.amazonaws.com)
Région de l'est des États-Unis (Ohio) (redshift-fips.us-east-2.amazonaws.com)
Région ouest des États-Unis (Californie du Nord) (redshift-fips.us-west-1.amazonaws.com)
Région ouest des États-Unis (Oregon) (redshift-fips.us-west-2.amazonaws.com)
Reportez-vous aux informations contenues dans les rubriques suivantes pour savoir comment utiliser les agents d'extraction de données.
Rubriques
Conditions préalables à l'utilisation d'agents d'extraction de données
Enregistrement des agents d'extraction auprès du AWS Schema Conversion Tool
Modification des paramètres de l'extracteur et de la copie à partir des paramètres du projet
Création, exécution et surveillance d'une tâche d'extraction de AWS SCT données
Exportation et importation d'une tâche d'extraction de AWS SCT données
Extraction de données à l'aide d'un appareil AWS Snowball Edge Edge
Utilisation du partitionnement virtuel avec AWS Schema Conversion Tool
Bonnes pratiques et résolution des problèmes pour les agents d'extraction de données
Conditions préalables à l'utilisation d'agents d'extraction de données
Avant de travailler avec des agents d'extraction de données, ajoutez les autorisations requises pour Amazon Redshift en tant que cible pour votre utilisateur Amazon Redshift. Pour de plus amples informations, veuillez consulter Autorisations pour Amazon Redshift en tant que cible.
Stockez ensuite les informations de votre compartiment Amazon S3 et configurez votre système de confiance SSL (Secure Sockets Layer) et votre stockage de clés.
Paramètres Amazon S3
Une fois que vos agents ont extrait vos données, ils les téléchargent dans votre compartiment Amazon S3. Avant de continuer, vous devez fournir les informations d'identification pour vous connecter à votre AWS compte et à votre compartiment Amazon S3. Vous stockez vos informations d'identification et de compartiment dans un profil dans les paramètres globaux de l'application, puis vous associez le profil à votre AWS SCT projet. Si nécessaire, choisissez Paramètres généraux pour créer un nouveau profil. Pour de plus amples informations, veuillez consulter Gestion des profils dans AWS Schema Conversion Tool.
Pour migrer des données vers votre base de données Amazon Redshift cible, l'agent d'extraction de AWS SCT données doit être autorisé à accéder au compartiment Amazon S3 en votre nom. Pour fournir cette autorisation, créez un utilisateur Gestion des identités et des accès AWS (IAM) avec la politique suivante.
Dans l'exemple précédent, remplacez bucket_name111122223333:user/DataExtractionAgentName
Assumer des rôles IAM
Pour plus de sécurité, vous pouvez utiliser des rôles Gestion des identités et des accès AWS (IAM) pour accéder à votre compartiment Amazon S3. Pour ce faire, créez un utilisateur IAM pour vos agents d'extraction de données sans aucune autorisation. Créez ensuite un rôle IAM qui autorise l'accès à Amazon S3 et spécifiez la liste des services et des utilisateurs qui peuvent assumer ce rôle. Pour plus d’informations, consultez Rôles IAM dans le Guide de l’utilisateur IAM.
Pour configurer les rôles IAM afin d'accéder à votre compartiment Amazon S3
-
Créez un nouvel utilisateur IAM. Pour les informations d'identification de l'utilisateur, choisissez le type d'accès programmatique.
-
Configurez l'environnement hôte afin que votre agent d'extraction de données puisse assumer le rôle qui lui est AWS SCT attribué. Assurez-vous que l'utilisateur que vous avez configuré à l'étape précédente autorise les agents d'extraction de données à utiliser la chaîne de fournisseurs d'informations d'identification. Pour plus d'informations, consultez la section Utilisation des informations d'identification dans le Guide du AWS SDK pour Java développeur.
-
Créez un nouveau rôle IAM qui a accès à votre compartiment Amazon S3.
-
Modifiez la section de confiance de ce rôle pour autoriser l'utilisateur que vous avez créé auparavant à assumer le rôle. Dans l'exemple suivant, remplacez
111122223333:user/DataExtractionAgentName{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111122223333:user/DataExtractionAgentName" }, "Action": "sts:AssumeRole" } -
Modifiez la section de confiance de ce rôle en faisant confiance
redshift.amazonaws.com.rproxy.goskope.compour assumer le rôle.{ "Effect": "Allow", "Principal": { "Service": [ "redshift.amazonaws.com" ] }, "Action": "sts:AssumeRole" } -
Associez ce rôle à votre cluster Amazon Redshift.
Vous pouvez désormais exécuter votre agent d'extraction de données dans AWS SCT.
Lorsque vous utilisez l'acceptation du rôle IAM, la migration des données fonctionne de la manière suivante. L'agent d'extraction de données démarre et obtient les informations d'identification de l'utilisateur à l'aide de la chaîne de fournisseurs d'informations d'identification. Ensuite, vous créez une tâche de migration de données dans AWS SCT, puis vous spécifiez le rôle IAM que les agents d'extraction de données doivent assumer, puis vous lancez la tâche. AWS Security Token Service (AWS STS) génère des informations d'identification temporaires pour accéder à Amazon S3. L'agent d'extraction de données utilise ces informations d'identification pour charger des données sur Amazon S3.
AWS SCT Fournit ensuite à Amazon Redshift le rôle IAM. À son tour, Amazon Redshift obtient de nouvelles informations d'identification temporaires AWS STS pour accéder à Amazon S3. Amazon Redshift utilise ces informations d'identification pour copier les données d'Amazon S3 vers votre table Amazon Redshift.
Réglages de sécurité
Les agents AWS Schema Conversion Tool et les agents d'extraction peuvent communiquer via le protocole SSL (Secure Sockets Layer). Pour activer SSL, configurez un référentiel d'approbations et un magasin de clés.
Pour configurer la communication avec votre agent d'extraction
-
Démarrez le AWS Schema Conversion Tool.
-
Ouvrez le menu Paramètres, puis choisissez Paramètres globaux. La boîte de dialogue Global settings s'affiche.
-
Choisissez Security (Sécurité).
-
Choisissez Generate trust and key store, ou sélectionnez Select existing trust store.
Si vous choisissez Generate trust and key store, vous spécifiez ensuite le nom et le mot de passe pour les trust et key stores, ainsi que le chemin d'accès à l'emplacement des fichiers générés. Vous utiliserez ces fichiers au cours d'étapes ultérieures.
Si vous choisissez Sélectionner un magasin de confiance existant, vous devez ensuite spécifier le mot de passe et le nom de fichier pour le magasin de confiance et de clés. Vous utiliserez ces fichiers au cours d'étapes ultérieures.
-
Après avoir spécifié le trust store et le key store, cliquez sur OK pour fermer la boîte de dialogue des paramètres globaux.
Configuration de l'environnement pour les agents d'extraction de données
Vous pouvez installer plusieurs agents d'extraction de données sur un même hôte. Toutefois, nous vous recommandons d'exécuter un agent d'extraction de données sur un hôte.
Pour exécuter votre agent d'extraction de données, assurez-vous d'utiliser un hôte doté d'au moins quatre V CPUs et de 32 Go de mémoire. Définissez également la mémoire minimale disponible AWS SCT à au moins quatre Go. Pour de plus amples informations, veuillez consulter Configuration de mémoire supplémentaire.
La configuration optimale et le nombre d'hôtes d'agents dépendent de la situation spécifique de chaque client. Assurez-vous de prendre en compte des facteurs tels que la quantité de données à migrer, la bande passante du réseau, le temps nécessaire pour extraire les données, etc. Vous pouvez d'abord effectuer une preuve de concept (PoC), puis configurer vos agents d'extraction de données et vos hôtes en fonction des résultats de cette validation.
Installation d'agents d'extraction
Nous vous recommandons d'installer plusieurs agents d'extraction et d'effectuer ces installations sur des ordinateurs autres que l'ordinateur qui exécute AWS Schema Conversion Tool.
Les agents d'extraction sont actuellement pris en charge sur les systèmes d'exploitation suivants :
Microsoft Windows
Red Hat Enterprise Linux (RHEL) 6.0
Ubuntu Linux (version 14.04 et supérieure)
Utilisez la procédure suivante pour installer des agents d'extraction. Répétez cette procédure pour chaque ordinateur sur lequel vous souhaitez installer un agent d'extraction.
Pour installer un agent d'extraction
-
Si vous n'avez pas encore téléchargé le fichier AWS SCT d'installation, suivez les instructions Installation et configuration AWS Schema Conversion Tool pour le télécharger. Le fichier .zip qui contient le fichier AWS SCT d'installation contient également le fichier d'installation de l'agent d'extraction.
-
Téléchargez et installez la dernière version d'Amazon Corretto 11. Pour plus d'informations, consultez la section Téléchargements pour Amazon Corretto 11 dans le guide de l'utilisateur d'Amazon Corretto 11.
-
Recherchez le fichier du programme d'installation de l'agent d'extraction dans un sous-dossier nommé agents. Le fichier correct pour chaque système d'exploitation sur lequel vous souhaitez installer l'agent d'extraction est illustré ci-après.
Système d’exploitation Nom de fichier Microsoft Windows
aws-schema-conversion-tool-extractor-2.0.1.build-number.msiRHEL
aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpmUbuntu Linux
aws-schema-conversion-tool-extractor-2.0.1.build-number.deb -
Installez l'agent d'extraction sur un autre ordinateur en copiant le fichier d'installation sur le nouvel ordinateur.
-
Exécutez le fichier du programme d'installation. Suivez les instructions ci-dessous correspondant à votre système d'exploitation.
Système d’exploitation Instructions d'installation Microsoft Windows
Double-cliquez sur le fichier pour exécuter le programme d'installation.
RHEL
Exécutez les commandes suivantes dans le dossier dans lequel vous avez téléchargé ou déplacé le fichier.
sudo rpm -ivh aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpm sudo ./sct-extractor-setup.sh --configUbuntu Linux
Exécutez les commandes suivantes dans le dossier dans lequel vous avez téléchargé ou déplacé le fichier.
sudo dpkg -i aws-schema-conversion-tool-extractor-2.0.1.build-number.deb sudo ./sct-extractor-setup.sh --config -
Choisissez Suivant, acceptez le contrat de licence, puis cliquez sur Suivant.
-
Entrez le chemin d'installation de l'agent d'extraction de AWS SCT données, puis choisissez Next.
-
Choisissez Installer pour installer votre agent d'extraction de données.
AWS SCT installe votre agent d'extraction de données. Pour terminer l'installation, configurez votre agent d'extraction de données. AWS SCT lance automatiquement le programme de configuration. Pour de plus amples informations, veuillez consulter Configuration des agents d'extraction.
-
Choisissez Terminer pour fermer l'assistant d'installation après avoir configuré votre agent d'extraction de données.
Configuration des agents d'extraction
Utilisez la procédure suivante pour configurer des agents d'extraction. Répétez cette procédure sur chaque ordinateur sur lequel un agent d'extraction est installé.
Pour configurer votre agent d'extraction
-
Lancez le programme de configuration :
-
Sous Windows, AWS SCT lance automatiquement le programme de configuration lors de l'installation d'un agent d'extraction de données.
Au besoin, vous pouvez lancer le programme d'installation manuellement. Pour ce faire, exécutez le
ConfigAgent.batfichier sous Windows. Ce fichier se trouve dans le dossier où vous avez installé l'agent. -
Dans RHEL et Ubuntu, exécutez le
sct-extractor-setup.shfichier à partir de l'emplacement où vous avez installé l'agent.
Le programme de configuration vous invite à fournir des informations. Pour chaque invite, une valeur par défaut apparaît.
-
-
Acceptez la valeur par défaut à chaque invite ou entrez une nouvelle valeur.
Spécifiez les informations suivantes :
Pour Port d'écoute, entrez le numéro de port sur lequel l'agent écoute.
Pour Ajouter un fournisseur source, entrez oui, puis entrez votre plateforme d'entrepôt de données source.
Pour le pilote JDBC, entrez l'emplacement où vous avez installé les pilotes JDBC.
Dans le champ Dossier de travail, entrez le chemin dans lequel l'agent d'extraction de AWS SCT données stockera les données extraites. Le dossier de travail peut figurer sur un autre ordinateur que celui où est installé l'agent et un même dossier de travail peut être partagé par plusieurs agents installés sur différents ordinateurs.
Pour Activer la communication SSL, entrez oui.
Pour Key store, entrez l'emplacement du fichier key store.
Dans le champ Mot de passe du magasin de clés, entrez le mot de passe du magasin de clés.
Pour Activer l'authentification SSL du client, entrez oui.
Pour Trust store, entrez l'emplacement du fichier Trust Store.
Dans le champ Mot de passe du Trust Store, entrez le mot de passe du Trust Store.
Le programme de configuration met à jour le fichier de paramètres de l'agent d'extraction. Le fichier de paramètres se nomme settings.properties et se trouve à l'emplacement où vous avez installé l'agent d'extraction.
Vous trouverez ci-dessous un exemple de fichier de paramètres.
$ cat settings.properties
#extractor.start.fetch.size=20000
#extractor.out.file.size=10485760
#extractor.source.connection.pool.size=20
#extractor.source.connection.pool.min.evictable.idle.time.millis=30000
#extractor.extracting.thread.pool.size=10
vendor=TERADATA
driver.jars=/usr/share/lib/jdbc/terajdbc4.jar
port=8192
redshift.driver.jars=/usr/share/lib/jdbc/RedshiftJDBC42-1.2.43.1067.jar
working.folder=/data/sct
extractor.private.folder=/home/ubuntu
ssl.option=OFFPour modifier les paramètres de configuration, vous pouvez modifier le settings.properties fichier à l'aide d'un éditeur de texte ou réexécuter la configuration de l'agent.
Installation et configuration d'agents d'extraction avec des agents de copie dédiés
Vous pouvez installer des agents d'extraction dans une configuration dotée d'un stockage partagé et d'un agent de copie dédié. Le schéma suivant illustre ce scénario.
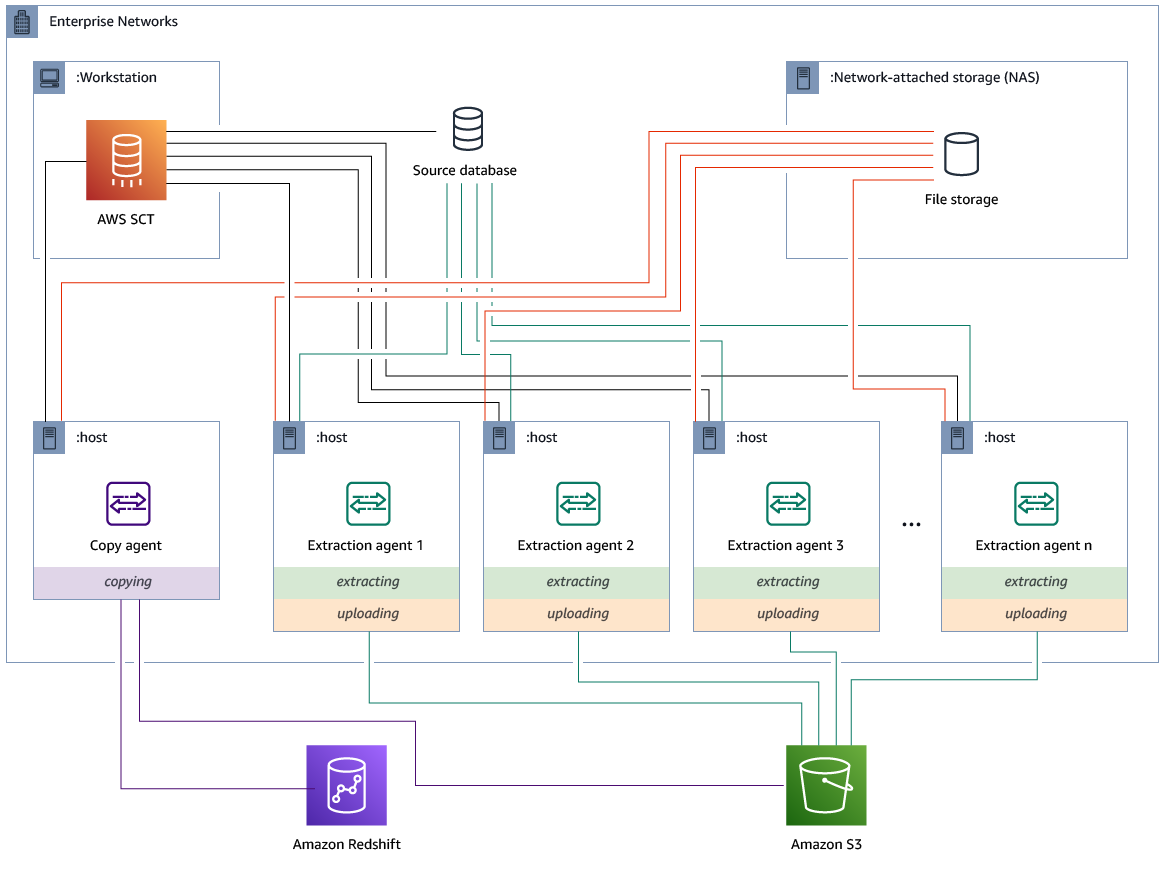
Cette configuration peut être utile lorsqu'un serveur de base de données source prend en charge jusqu'à 120 connexions et que votre réseau dispose d'une capacité de stockage suffisante. Suivez la procédure ci-dessous pour configurer les agents d'extraction dotés d'un agent de copie dédié.
Pour installer et configurer des agents d'extraction et un agent de copie dédié
-
Assurez-vous que le répertoire de travail de tous les agents d'extraction utilise le même dossier sur le stockage partagé.
-
Installez les agents d'extraction en suivant les étapes décrites dansInstallation d'agents d'extraction.
-
Configurez les agents d'extraction en suivant les étapes décritesConfiguration des agents d'extraction, mais spécifiez uniquement le pilote JDBC source.
-
Configurez un agent de copie dédié en suivant les étapes décritesConfiguration des agents d'extraction, mais spécifiez uniquement un pilote Amazon Redshift JDBC.
Agents d'extraction de départ
Utilisez la procédure suivante pour démarrer des agents d'extraction. Répétez cette procédure sur chaque ordinateur sur lequel un agent d'extraction est installé.
Les agents d'extraction agissent en tant qu'écouteurs. Lorsque vous démarrez un agent avec cette procédure, celui-ci commence à écouter les instructions. Vous enverrez aux agents des instructions pour extraire des données de votre entrepôt de données dans une section ultérieure.
Pour démarrer votre agent d'extraction
-
Sur l'ordinateur où l'agent d'extraction a été installé, exécutez la commande indiquée ci-après pour votre système d'exploitation.
Système d’exploitation Commande de démarrage Microsoft Windows
Double-cliquez sur le fichier de commandes
StartAgent.bat.RHEL
Exécutez la commande suivante dans le chemin d'accès au dossier où vous avez installé l'agent :
sudo initctlstartsct-extractorUbuntu Linux
Exécutez la commande suivante dans le chemin d'accès au dossier où vous avez installé l'agent. Utilisez la commande appropriée pour votre version d'Ubuntu.
Ubuntu 14.04:
sudo initctlstartsct-extractorUbuntu 15.04 et versions ultérieures :
sudo systemctlstartsct-extractor
Pour vérifier le statut de l'agent, exécutez la même commande en remplaçant start par status.
Pour arrêter un agent, exécutez la même commande en remplaçant start par stop.
Enregistrement des agents d'extraction auprès du AWS Schema Conversion Tool
Vous gérez vos agents d'extraction en utilisant AWS SCT. Les agents d'extraction agissent en tant qu'écouteurs. Lorsqu'ils reçoivent des instructions de leur part AWS SCT, ils extraient les données de votre entrepôt de données.
Utilisez la procédure suivante pour enregistrer les agents d'extraction dans votre AWS SCT projet.
Pour enregistrer un agent d'extraction
-
Démarrez AWS Schema Conversion Tool et ouvrez un projet.
-
Ouvrez le menu Affichage, puis choisissez Affichage de migration des données (autre). L'onglet Agents s'affiche. Si vous avez déjà enregistré des agents, AWS SCT affichez-les dans une grille en haut de l'onglet.
-
Choisissez S’inscrire.
Une fois que vous avez enregistré un agent dans un AWS SCT projet, vous ne pouvez pas enregistrer le même agent dans un autre projet. Si vous n'utilisez plus d'agent dans un AWS SCT projet, vous pouvez le désenregistrer. Vous pouvez ensuite l'enregistrer dans un autre projet.
-
Choisissez l'agent de données Redshift, puis cliquez sur OK.
-
Entrez vos informations dans l'onglet Connexion de la boîte de dialogue :
-
Dans Description, entrez une description de l'agent.
-
Dans Nom d'hôte, entrez le nom d'hôte ou l'adresse IP de l'ordinateur de l'agent.
-
Pour Port, entrez le numéro de port sur lequel l'agent écoute.
-
Choisissez Enregistrer pour enregistrer l'agent auprès de votre AWS SCT projet.
-
-
Répétez les étapes précédentes pour enregistrer plusieurs agents auprès de votre projet AWS SCT .
Masquer et récupérer des informations pour un AWS SCT agent
Un AWS SCT agent chiffre une quantité importante d'informations, par exemple les mots de passe des banques de données de confiance des utilisateurs, les comptes de base de données, les informations relatives aux comptes et autres éléments similaires. AWS Pour ce faire, il utilise un fichier spécial nommé seed.dat. Par défaut, l'agent crée ce fichier dans le dossier de travail de l'utilisateur qui configure l'agent pour la première fois.
Dans la mesure où différents utilisateurs peuvent configurer et exécuter l'agent, le chemin d'accès à seed.dat est stocké dans le paramètre {extractor.private.folder} du fichier settings.properties. Lorsque l'agent démarre, il peut utiliser ce chemin pour trouver le fichier seed.dat afin d'accéder aux informations du référentiel d'approbations et du magasin de clés de la base de données qu'il utilise.
Il se peut que vous ayez besoin de récupérer les mots de passe stockés par un agent dans les cas suivants :
Si l'utilisateur perd le
seed.datfichier et que l'emplacement et le port de l' AWS SCT agent n'ont pas changé.Si l'utilisateur perd le
seed.datfichier et que l'emplacement et le port de l' AWS SCT agent ont changé. Dans ce cas, la modification se produit généralement parce que l'agent a été migré vers un autre hôte ou port et que les informations contenues dans le fichierseed.datne sont plus valides.
Dans de tels cas, si un agent est démarré sans SSL, il démarre, puis accède au stockage de l'agent créé précédemment. Il passe ensuite à l'état Waiting for recovery (En attente de récupération).
Cependant, dans ces cas, si un agent est démarré avec SSL, vous ne pouvez pas le redémarrer. En effet, l'agent ne peut pas déchiffrer les mots de passe pour accéder aux certificats stockés dans le fichier settings.properties. Dans ce type de démarrage, l'agent ne parvient pas à démarrer. Une erreur similaire à la suivante est écrite dans le journal : « The agent could not start with SSL mode enabled. Please reconfigure the agent. Reason: The password for keystore is incorrect. » (L'agent n'a pas pu démarrer avec le mode SSL activé. Veuillez reconfigurer l'agent. Raison : le mot de passe du keystore est incorrect.)
Pour corriger ce problème, créez un nouvel agent et configurez-le afin qu'il utilise les mots de passe existants pour accéder aux certificats SSL. Pour cela, procédez comme suit.
Après avoir effectué cette procédure, l'agent doit s'exécuter et passer à l'état En attente de restauration. AWS SCT envoie automatiquement les mots de passe nécessaires à un agent en état En attente de restauration. Lorsque l'agent dispose des mots de passe, il redémarre toutes les tâches. Aucune autre action de l'utilisateur n'est requise sur le AWS SCT côté.
Pour reconfigurer l'agent et restaurer les mots de passe afin d'accéder aux certificats SSL
Installez un nouvel AWS SCT agent et exécutez la configuration.
Modifiez la propriété
agent.namedans le fichierinstance.propertiespour indiquer le nom de l'agent pour lequel le stockage a été créé, afin que le nouvel agent fonctionne avec le stockage de l'agent existant.Le fichier
instance.propertiesest stocké dans le dossier privé de l'agent, qui est nommé en utilisant la convention suivante :{.output.folder}\dmt\{hostName}_{portNumber}\Remplacez le nom de
{par celui du dossier de sortie de l'agent précédent.output.folder}À ce stade, AWS SCT essaie toujours d'accéder à l'ancien extracteur sur l'ancien hôte et le port. Par conséquent, l'extracteur inaccessible est à l'état FAILED (ÉCHEC). Vous pouvez ensuite modifier l'hôte et le port.
Modifiez l'hôte et/ou le port de l'ancien agent à l'aide de la commande Modify pour rediriger le flux de demandes vers le nouvel agent.
Quand AWS SCT peut envoyer un ping au nouvel agent, AWS SCT reçoit le statut En attente de restauration de la part de l'agent. AWS SCT récupère ensuite automatiquement les mots de passe de l'agent.
Chaque agent qui fonctionne avec le stockage de l'agent met à jour un fichier spécial appelé storage.lck et situé dans {. Ce fichier contient l'ID réseau de l'agent et le délai avant le verrouillage du stockage. Lorsque l'agent fonctionne avec le stockage de l'agent, il met à jour le fichier output.folder}\{agentName}\storage\storage.lck et étend le bail du stockage de 10 minutes toutes les 5 minutes. Aucune autre instance ne peut fonctionner avec le stockage de cet agent avant l'expiration du bail.
Création de règles de migration de données dans AWS SCT
Avant d'extraire vos données avec le AWS Schema Conversion Tool, vous pouvez configurer des filtres qui réduisent la quantité de données que vous extrayez. Vous pouvez créer des règles de migration des données en utilisant WHERE des clauses pour réduire le nombre de données que vous extrayez. Par exemple, vous pouvez écrire une clause WHERE qui sélectionne les données à partir d'une seule table.
Vous pouvez créer des règles de migration des données et enregistrer les filtres dans le cadre de votre projet. Votre projet étant ouvert, utilisez la procédure suivante pour créer des règles de migration de données.
Pour créer des règles de migration des données
-
Ouvrez le menu Affichage, puis choisissez Affichage de migration des données (autre).
-
Choisissez Règles de migration des données, puis sélectionnez Ajouter une nouvelle règle.
-
Configurez votre règle de migration des données :
-
Dans Nom, entrez le nom de votre règle de migration de données.
-
Pour Where schema name is like, entrez un filtre à appliquer aux schémas. Dans ce filtre, une clause
WHEREest évaluée à l'aide d'une clauseLIKE. Pour choisir un schéma, entrez un nom de schéma exact. Pour choisir plusieurs schémas, utilisez le caractère « % » comme caractère générique pour correspondre au nombre quelconque de caractères du nom du schéma. -
Pour un nom de table, par exemple, entrez un filtre à appliquer aux tables. Dans ce filtre, une clause
WHEREest évaluée à l'aide d'une clauseLIKE. Pour choisir une table, entrez un nom exact. Pour sélectionner plusieurs tables, utilisez le caractère « % » comme caractère générique pour faire correspondre le nombre de caractères que vous souhaitez au nom de la table. -
Pour la clause Where, entrez une
WHEREclause pour filtrer les données.
-
-
Une fois que vous avez configuré votre filtre, choisissez Save pour enregistrer votre filtre ou Cancel pour annuler vos modifications.
-
Une fois que vous avez terminé d'ajouter, de modifier et de supprimer des filtres, choisissez Enregistrer tout pour enregistrer toutes vos modifications.
Pour désactiver un filtre sans le supprimer, vous pouvez utiliser l'icône bascule. Pour dupliquer un filtre existant, utilisez l'icône de copie. Pour supprimer un filtre existant, utilisez l'icône de suppression. Pour enregistrer les modifications que vous apportez à vos filtres, choisissez Enregistrer tout.
Modification des paramètres de l'extracteur et de la copie à partir des paramètres du projet
Dans la fenêtre des paramètres du projet AWS SCT, vous pouvez choisir les paramètres des agents d'extraction de données et de la commande Amazon RedshiftCOPY.
Pour choisir ces paramètres, choisissez Paramètres, Paramètres du projet, puis Migration des données. Ici, vous pouvez modifier les paramètres d'extraction, les paramètres Amazon S3 et les paramètres de copie.
Suivez les instructions du tableau suivant pour fournir les informations relatives aux paramètres d'extraction.
| Pour ce paramètre | Faites ceci |
|---|---|
Format de compression |
Spécifiez le format de compression des fichiers d'entrée. Choisissez l'une des options suivantes : GZIP BZIP2, ZSTD ou Aucune compression. |
Caractère délimiteur |
Spécifiez le caractère ASCII qui sépare les champs dans les fichiers d'entrée. Les caractères non imprimables ne sont pas pris en charge. |
Valeur NULL sous forme de chaîne |
Activez cette option si vos données incluent un terminateur nul. Si cette option est désactivée, la |
Stratégie de tri |
Utilisez le tri pour relancer l'extraction à partir du point d'échec. Choisissez l'une des stratégies de tri suivantes : Utiliser le tri après le premier échec (recommandé), Utiliser le tri si possible ou Ne jamais utiliser le tri. Pour de plus amples informations, veuillez consulter Tri des données avant la migration à l'aide de AWS SCT. |
Schéma de température de la source |
Entrez le nom du schéma dans la base de données source, où l'agent d'extraction peut créer les objets temporaires. |
Taille du fichier de sortie (en Mo) |
Entrez la taille, en Mo, des fichiers chargés sur Amazon S3. |
Taille du fichier Snowball Out (en Mo) |
Entrez la taille, en Mo, des fichiers téléchargés vers AWS Snowball Edge. La taille des fichiers peut être comprise entre 1 et 1 000 Mo. |
Utilisez le partitionnement automatique. Pour Greenplum et Netezza, entrez la taille minimale des tables prises en charge (en mégaoctets) |
Activez cette option pour utiliser le partitionnement des tables, puis entrez la taille des tables à partitionner pour les bases de données sources Greenplum et Netezza. Pour les migrations d'Oracle vers Amazon Redshift, vous pouvez laisser ce champ vide car cela AWS SCT crée des sous-tâches pour toutes les tables partitionnées. |
Extrait LOBs |
Activez cette option pour extraire des objets volumineux (LOBs) de votre base de données source. LOBs inclure BLOBs CLOBs, NCLOBs,, des fichiers XML, etc. Pour chaque LOB, les agents AWS SCT d'extraction créent un fichier de données. |
LOBs Dossier de compartiment Amazon S3 |
Entrez l'emplacement où les agents AWS SCT d'extraction doivent être stockés LOBs. |
Appliquer RTRIM aux colonnes de chaînes |
Activez cette option pour supprimer un jeu de caractères spécifié à la fin des chaînes extraites. |
Conservez les fichiers localement après leur téléchargement sur Amazon S3 |
Activez cette option pour conserver les fichiers sur votre machine locale une fois que les agents d'extraction de données les ont chargés sur Amazon S3. |
Suivez les instructions du tableau suivant pour fournir les informations relatives aux paramètres Amazon S3.
| Pour ce paramètre | Faites ceci |
|---|---|
Utiliser un proxy |
Activez cette option pour utiliser un serveur proxy afin de télécharger des données sur Amazon S3. Choisissez ensuite le protocole de transfert de données, entrez le nom d'hôte, le port, le nom d'utilisateur et le mot de passe. |
Type de point de terminaison |
Choisissez FIPS pour utiliser le point de terminaison FIPS (Federal Information Processing Standard). Choisissez VPCE pour utiliser le point de terminaison du cloud privé virtuel (VPC). Ensuite, pour le point de terminaison VPC, entrez le système de nom de domaine (DNS) de votre point de terminaison VPC. |
Conservez les fichiers sur Amazon S3 après les avoir copiés sur Amazon Redshift |
Activez cette option pour conserver les fichiers extraits sur Amazon S3 après les avoir copiés sur Amazon Redshift. |
Suivez les instructions du tableau suivant pour fournir les informations relatives aux paramètres de copie.
| Pour ce paramètre | Faites ceci |
|---|---|
Nombre d'erreurs maximal |
Entrez le nombre d'erreurs de chargement. Lorsque l'opération atteint cette limite, les agents d'extraction de AWS SCT données mettent fin au processus de chargement des données. La valeur par défaut est 0, ce qui signifie que les AWS SCT agents d'extraction de données continuent le chargement des données indépendamment des défaillances. |
Remplace les caractères UTF-8 non valides |
Activez cette option pour remplacer les caractères UTF-8 non valides par le caractère spécifié et poursuivre l'opération de chargement des données. |
Utiliser le blanc comme valeur nulle |
Activez cette option pour charger les champs vides composés d'espaces blancs sous la forme de valeurs nulles. |
Utiliser le vide comme valeur nulle |
Activez cette option pour charger des champs vides |
Tronquer les colonnes |
Activez cette option pour tronquer les données en colonnes afin de les adapter à la spécification du type de données. |
Compression automatique |
Activez cette option pour appliquer le codage de compression lors d'une opération de copie. |
Actualisation automatique des statistiques |
Activez cette option pour actualiser les statistiques à la fin d'une opération de copie. |
Vérifier le fichier avant le chargement |
Activez cette option pour valider les fichiers de données avant de les charger sur Amazon Redshift. |
Tri des données avant la migration à l'aide de AWS SCT
Le tri de vos données avant la migration AWS SCT présente certains avantages. Si vous triez d'abord les données, vous AWS SCT pouvez redémarrer l'agent d'extraction au dernier point enregistré après un échec. De plus, si vous migrez des données vers Amazon Redshift et que vous les triez d'abord AWS SCT , vous pouvez les insérer plus rapidement dans Amazon Redshift.
Ces avantages sont liés à la manière dont les requêtes d'extraction de données sont AWS SCT créées. Dans certains cas, AWS SCT utilise la fonction analytique DENSE_RANK dans ces requêtes. DENSE_RANK peut toutefois utiliser beaucoup de temps et de ressources serveur pour trier le jeu de données résultant de l'extraction. Ainsi, s'il AWS SCT peut fonctionner sans lui, c'est le cas.
Pour trier les données avant de les migrer à l'aide de AWS SCT
Ouvrez un AWS SCT projet.
Ouvrez le menu contextuel (clic droit) de l'objet, puis choisissez Créer une tâche locale.
Choisissez l'onglet Avancé, puis dans Stratégie de tri, choisissez une option :
N'utilisez jamais le tri : l'agent d'extraction n'utilise pas la fonction analytique DENSE_RANK et redémarre depuis le début en cas d'échec.
Utilisez le tri si possible : l'agent d'extraction utilise DENSE_RANK si la table possède une clé primaire ou une contrainte unique.
Utiliser le tri après le premier échec (recommandé) — L'agent d'extraction essaie d'abord d'obtenir les données sans utiliser DENSE_RANK. Si la première tentative échoue, l'agent d'extraction reconstitue la requête en utilisant DENSE_RANK et conserve sa position en cas de défaillance.
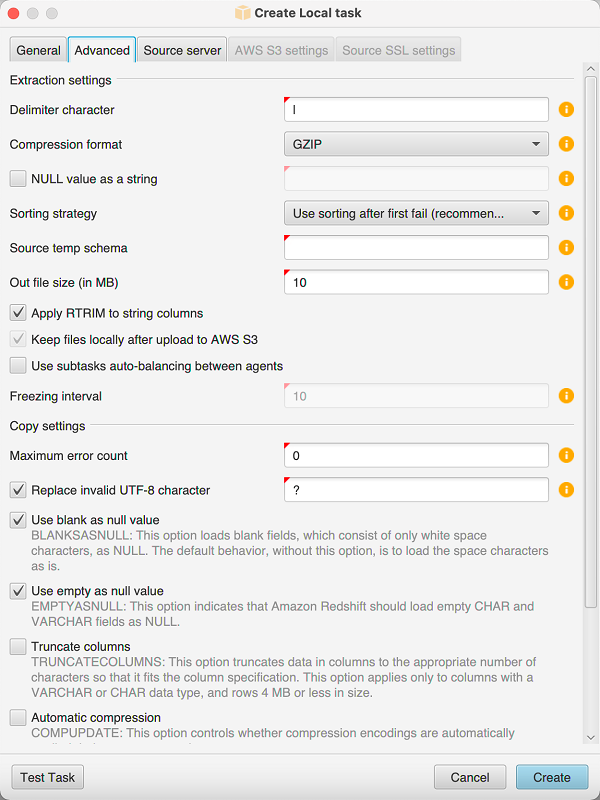
Définissez des paramètres supplémentaires comme décrit ci-dessous, puis choisissez Create pour créer votre tâche d'extraction de données.
Création, exécution et surveillance d'une tâche d'extraction de AWS SCT données
Utilisez les procédures suivantes pour créer, exécuter et surveiller des tâches d'extraction de données.
Pour affecter des tâches à des agents et migrer des données
-
Dans le AWS Schema Conversion Tool, après avoir converti votre schéma, choisissez une ou plusieurs tables dans le panneau de gauche de votre projet.
Vous pouvez choisir toutes les tables, cependant, nous ne recommandons pas cette pratique car elle risque d'altérer les performances. Nous vous recommandons de créer plusieurs tâches pour plusieurs tables en fonction de la taille de ces dernières dans votre entrepôt de données.
-
Ouvrez le menu contextuel (clic droit) de chaque table, puis choisissez Créer une tâche. La boîte de dialogue Créer une tâche locale s'ouvre.
-
Dans Nom de la tâche, entrez le nom de la tâche.
-
Pour le mode migration, choisissez l'une des options suivantes :
-
Extraire uniquement : extrayez vos données et enregistrez-les dans vos dossiers de travail locaux.
-
Extraire et chargement : extrayez vos données et chargez-les sur Amazon S3.
-
Extraire, charger et copier : extrayez vos données, chargez-les sur Amazon S3 et copiez-les dans votre entrepôt de données Amazon Redshift.
-
-
Pour le type de chiffrement, choisissez l'une des options suivantes :
-
AUCUN — Désactivez le chiffrement des données pendant tout le processus de migration des données.
-
CSE_SK — Utilisez le chiffrement côté client avec une clé symétrique pour migrer les données. AWS SCT génère automatiquement des clés de chiffrement et les transmet aux agents d'extraction de données à l'aide du protocole SSL (Secure Sockets Layer). AWS SCT ne chiffre pas les objets volumineux (LOBs) lors de la migration des données.
-
-
Choisissez Extraire LOBs pour extraire des objets de grande taille. Si vous n'avez pas besoin d'extraire des objets de grande taille, vous pouvez décocher la case. Cela permet de réduire la quantité de données qui sont extraites.
-
Pour obtenir des informations détaillées sur une tâche, choisissez Activer la journalisation des tâches. Vous pouvez utiliser le journal des tâches pour déboguer les problèmes.
Si vous activez la journalisation des tâches, choisissez le niveau de détails à afficher. Les niveaux sont les suivants, avec chaque niveau comprenant tous les messages du niveau précédent :
ERROR— La plus petite quantité de détails.WARNINGINFODEBUGTRACE— La plus grande quantité de détails.
-
Pour exporter des données depuis BigQuery, AWS SCT utilise le dossier bucket de Google Cloud Storage. Dans ce dossier, les agents d'extraction de données stockent vos données sources.
Pour saisir le chemin d'accès à votre dossier de bucket Google Cloud Storage, sélectionnez Avancé. Pour le dossier de bucket Google CS, entrez le nom du bucket et le nom du dossier.
-
Pour jouer le rôle d'utilisateur de votre agent d'extraction de données, choisissez les paramètres Amazon S3. Pour le rôle IAM, entrez le nom du rôle à utiliser. Pour Région, choisissez le Région AWS pour ce rôle.
-
Choisissez Tâche de test pour vérifier que vous pouvez vous connecter à votre dossier de travail, à votre compartiment Amazon S3 et à votre entrepôt de données Amazon Redshift. La vérification dépend du mode de migration que vous avez choisi.
-
Choisissez Create pour créer la tâche.
-
Répétez les étapes précédentes afin de créer des tâches pour toutes les données que vous souhaitez migrer.
Pour exécuter et surveiller des tâches
-
Pour Afficher, choisissez Vue de migration des données. L'onglet Agents s'affiche.
-
Choisissez l'onglet Tasks. Vos tâches apparaissent dans la grille supérieure, comme illustré ci-après. Vous pouvez voir le statut d'une tâche dans la grille supérieure et celui de ses sous-tâches dans la grille inférieure.
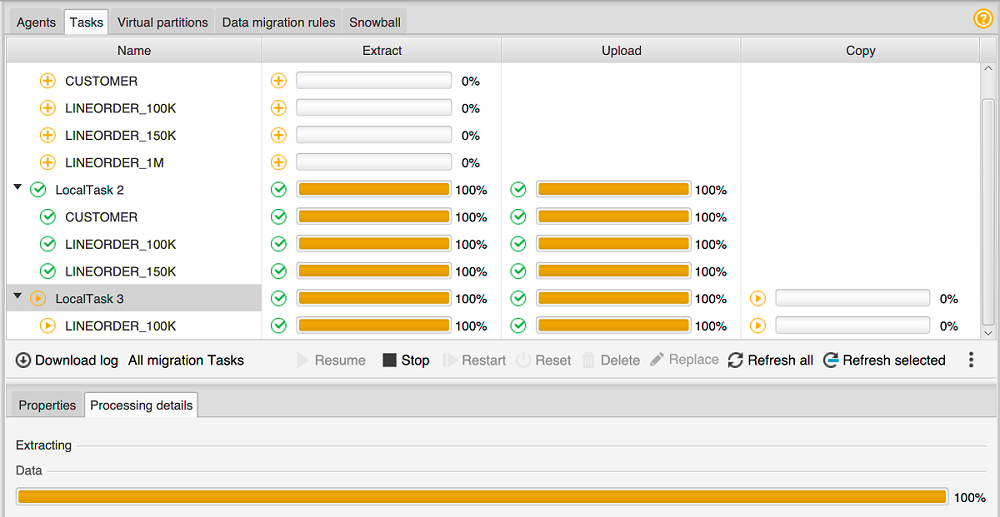
-
Choisissez une tâche dans la grille supérieure et développez-la. Selon le mode de migration que vous avez choisi, vous voyez la tâche divisée en Extract, Upload et Copy.
-
Choisissez Start pour une tâche afin de la démarrer. Vous pouvez surveiller le statut de vos tâches pendant leur exécution. Les sous-tâches s'exécutent en parallèle. Les opérations d'extraction, de chargement et de copie s'exécutent aussi en parallèle.
-
Si vous avez activé la journalisation lorsque vous avez configuré la tâche, vous pouvez afficher le journal:
-
Choisissez Télécharger le journal. Un message apparaît avec le nom du dossier qui contient le fichier journal. Ignorez le message.
-
Un lien apparaît dans l'onglet Task details. Cliquez sur le lien pour ouvrir le dossier qui contient le fichier journal.
-
Vous pouvez fermer AWS SCT, et vos agents et tâches continuent de s'exécuter. Vous pouvez rouvrir AWS SCT ultérieurement pour vérifier l'état de vos tâches et consulter les journaux des tâches.
Vous pouvez enregistrer les tâches d'extraction de données sur votre disque local et les restaurer dans le même projet ou dans un autre en utilisant l'exportation et l'importation. Pour exporter une tâche, assurez-vous qu'au moins une tâche d'extraction a été créée dans un projet. Vous pouvez importer une seule tâche d'extraction ou toutes les tâches créées dans le projet.
Lorsque vous exportez une tâche d'extraction, AWS SCT crée un .xml fichier distinct pour cette tâche. Le .xml fichier stocke les informations de métadonnées de cette tâche, telles que les propriétés, la description et les sous-tâches de la tâche. Le .xml fichier ne contient aucune information sur le traitement d'une tâche d'extraction. Les informations suivantes sont recréées lors de l'importation de la tâche :
-
Progression de la tâche
-
États des sous-tâches et des étapes
-
Répartition des agents d'extraction par sous-tâches et étapes
-
Tâche et sous-tâche IDs
-
Nom de la tâche
Exportation et importation d'une tâche d'extraction de AWS SCT données
Vous pouvez rapidement enregistrer une tâche existante d'un projet et la restaurer dans un autre projet (ou le même projet) à l'aide de l' AWS SCT exportation et de l'importation. Utilisez la procédure suivante pour exporter et importer des tâches d'extraction de données.
Pour exporter et importer une tâche d'extraction de données
-
Pour Afficher, choisissez Vue de migration des données. L'onglet Agents s'affiche.
-
Choisissez l'onglet Tasks. Vos tâches sont répertoriées dans la grille qui apparaît.
-
Choisissez les trois points alignés verticalement (icône en forme d'ellipse) situés dans le coin inférieur droit sous la liste des tâches.
-
Choisissez Exporter la tâche dans le menu contextuel.
-
Choisissez le dossier dans lequel vous AWS SCT souhaitez placer le
.xmlfichier d'exportation de tâches.AWS SCT crée le fichier d'exportation de tâches avec le format de nom de fichier
TASK-DESCRIPTION_TASK-ID.xml -
Choisissez les trois points alignés verticalement (icône en forme d'ellipse) en bas à droite sous la liste des tâches.
-
Choisissez Importer une tâche dans le menu contextuel.
Vous pouvez importer une tâche d'extraction dans un projet connecté à la base de données source, et le projet possède au moins un agent d'extraction enregistré actif.
-
Sélectionnez le
.xmlfichier pour la tâche d'extraction que vous avez exportée.AWS SCT obtient les paramètres de la tâche d'extraction à partir du fichier, crée la tâche et ajoute la tâche aux agents d'extraction.
-
Répétez ces étapes pour exporter et importer des tâches d'extraction de données supplémentaires.
À la fin de ce processus, votre exportation et votre importation sont terminées et vos tâches d'extraction de données sont prêtes à être utilisées.
Extraction de données à l'aide d'un appareil AWS Snowball Edge Edge
Le processus d'utilisation AWS SCT d' AWS Snowball Edge Edge comporte plusieurs étapes. La migration implique une tâche locale, qui AWS SCT utilise un agent d'extraction de données pour déplacer les données vers le périphérique AWS Snowball Edge Edge, puis une action intermédiaire qui AWS copie les données de l'appareil AWS Snowball Edge Edge vers un compartiment Amazon S3. Le processus termine le AWS SCT chargement des données depuis le compartiment Amazon S3 vers Amazon Redshift.
Les sections qui suivent cette présentation fournissent un step-by-step guide pour chacune de ces tâches. La procédure suppose que vous avez AWS SCT installé, configuré et enregistré un agent d'extraction de données sur une machine dédiée.
Procédez comme suit pour migrer les données d'un magasin de données local vers un magasin de AWS données à l'aide d' AWS Snowball Edge Edge.
Créez une tâche AWS Snowball Edge Edge à l'aide de la AWS Snowball Edge console.
Déverrouillez le périphérique AWS Snowball Edge Edge à l'aide de la machine Linux locale dédiée.
Créez un nouveau projet dans AWS SCT.
Installez et configurez vos agents d'extraction de données.
Créez et définissez les autorisations pour le compartiment Amazon S3 à utiliser.
Importez une AWS Snowball Edge tâche dans votre AWS SCT projet.
Enregistrez votre agent d'extraction de données dans AWS SCT.
Créez une tâche locale dans AWS SCT.
Exécutez et surveillez la tâche de migration des données dans AWS SCT.
Step-by-step procédures de migration des données à l'aide AWS SCT d'Edge AWS Snowball Edge
Les sections suivantes fournissent des informations détaillées sur les étapes de la migration.
Étape 1 : créer une tâche AWS Snowball Edge Edge
Créez un AWS Snowball Edge job en suivant les étapes décrites dans la section Creating an AWS Snowball Edge Edge Job du Guide du développeur AWS Snowball Edge Edge.
Étape 2 : déverrouillez l'appareil AWS Snowball Edge Edge
Exécutez les commandes qui déverrouillent et fournissent des informations d'identification à l'appareil Snowball Edge à partir de la machine sur laquelle vous avez installé l' AWS DMS agent. En exécutant ces commandes, vous pouvez être sûr que l'appel de l' AWS DMS agent se connecte au périphérique AWS Snowball Edge Edge. Pour plus d'informations sur le déverrouillage de l'appareil AWS Snowball Edge Edge, consultez la section Déverrouillage du Snowball Edge.
aws s3 ls s3://<bucket-name> --profile <Snowball Edge profile> --endpoint http://<Snowball IP>:8080 --recursive
Étape 3 : Création d'un nouveau AWS SCT projet
Créez ensuite un nouveau AWS SCT projet.
Pour créer un nouveau projet dans AWS SCT
-
Démarrez le AWS Schema Conversion Tool. Dans le menu Fichier, choisissez Nouveau projet. La boîte de dialogue Nouveau projet apparaît.
-
Entrez un nom pour votre projet, qui est stocké localement sur votre ordinateur.
-
Entrez l'emplacement de votre fichier de projet local.
-
Cliquez sur OK pour créer votre AWS SCT projet.
-
Choisissez Ajouter une source pour ajouter une nouvelle base de données source à votre AWS SCT projet.
-
Choisissez Ajouter une cible pour ajouter une nouvelle plateforme cible dans votre AWS SCT projet.
-
Choisissez le schéma de base de données source dans le panneau de gauche.
-
Dans le panneau de droite, spécifiez la plate-forme de base de données cible pour le schéma source sélectionné.
-
Choisissez Créer un mappage. Ce bouton devient actif une fois que vous avez choisi le schéma de base de données source et la plate-forme de base de données cible.
Étape 4 : Installation et configuration de votre agent d'extraction de données
AWS SCT utilise un agent d'extraction de données pour migrer les données vers Amazon Redshift. Le fichier .zip que vous avez téléchargé pour l'installer AWS SCT inclut le fichier d'installation de l'agent d'extraction. Vous pouvez installer l'agent d'extraction de données sous Windows, Red Hat Enterprise Linux ou Ubuntu. Pour de plus amples informations, veuillez consulter Installation d'agents d'extraction.
Pour configurer votre agent d'extraction de données, entrez vos moteurs de base de données source et cible. Assurez-vous également d'avoir téléchargé les pilotes JDBC pour vos bases de données source et cible sur l'ordinateur sur lequel vous exécutez votre agent d'extraction de données. Les agents d'extraction de données utilisent ces pilotes pour se connecter à vos bases de données source et cible. Pour de plus amples informations, veuillez consulter Installation des pilotes JDBC pour AWS Schema Conversion Tool.
Sous Windows, le programme d'installation de l'agent d'extraction de données lance l'assistant de configuration dans la fenêtre d'invite de commande. Sous Linux, exécutez le sct-extractor-setup.sh fichier à partir de l'emplacement où vous avez installé l'agent.
Étape 5 : Configuration AWS SCT pour accéder au compartiment Amazon S3
Pour plus d'informations sur la configuration d'un compartiment Amazon S3, consultez la présentation des compartiments dans le guide de l'utilisateur d'Amazon Simple Storage Service.
Étape 6 : Importer une AWS Snowball Edge tâche dans votre AWS SCT projet
Pour connecter votre AWS SCT projet à votre appareil AWS Snowball Edge Edge, importez votre AWS Snowball Edge tâche.
Pour importer votre AWS Snowball Edge travail
-
Ouvrez le menu Paramètres, puis choisissez Paramètres globaux. La boîte de dialogue Global settings s'affiche.
-
Choisissez des profils de AWS service, puis choisissez Importer une tâche.
Choisissez votre AWS Snowball Edge travail.
-
Entrez votre AWS Snowball Edge adresse IP. Pour plus d'informations, consultez la section Modification de votre adresse IP dans le guide de AWS Snowball Edge l'utilisateur.
-
Entrez votre AWS Snowball Edge port. Pour plus d'informations, consultez la section Ports requis pour utiliser les AWS services sur un périphérique AWS Snowball Edge Edge dans le guide du développeur AWS Snowball Edge Edge.
-
Entrez votre cléAWS Snowball Edge d'accès et votre cléAWS Snowball Edge secrète. Pour plus d'informations, consultez la section Autorisation et contrôle d'accès AWS Snowball Edge dans le guide de AWS Snowball Edge l'utilisateur.
Choisissez Appliquer, puis OK.
Étape 7 : Enregistrez un agent d'extraction de données dans AWS SCT
Dans cette section, vous enregistrez l'agent d'extraction de données dans AWS SCT.
Pour enregistrer un agent d'extraction de données
-
Dans le menu Affichage, choisissez Vue de migration des données (autre), puis sélectionnez Enregistrer.
-
Dans Description, entrez le nom de votre agent d'extraction de données.
-
Dans Nom d'hôte, entrez l'adresse IP de l'ordinateur sur lequel vous exécutez votre agent d'extraction de données.
-
Pour Port, entrez le port d'écoute que vous avez configuré.
-
Choisissez S’inscrire.
Étape 8 : Création d'une tâche locale
Ensuite, vous créez la tâche de migration. La tâche inclut deux sous-tâches. Une sous-tâche fait migrer les données de la base de données source vers l'appliance AWS Snowball Edge Edge. L'autre sous-tâche prend les données que l'appliance charge dans un compartiment Amazon S3 et les migre vers la base de données cible.
Pour créer la tâche de migration
-
Dans le menu Affichage, puis choisissez Affichage de migration des données (autre).
Dans le volet gauche où figure le schéma de votre base de données source, choisissez l'objet de schéma à migrer. Ouvrez le menu contextuel (clic droit) de l'objet, puis choisissez Créer une tâche locale.
-
Dans Nom de la tâche, entrez un nom descriptif pour votre tâche de migration de données.
-
Pour le mode migration, choisissez Extraire, uploader et copier.
-
Choisissez les paramètres Amazon S3.
-
Sélectionnez Utiliser Snowball Edge.
-
Entrez des dossiers et des sous-dossiers dans votre compartiment Amazon S3 où l'agent d'extraction de données peut stocker des données.
-
Choisissez Create pour créer la tâche.
Étape 9 : Exécution et surveillance de la tâche de migration des données dans AWS SCT
Pour démarrer votre tâche de migration de données, sélectionnez Démarrer. Assurez-vous d'avoir établi des connexions à la base de données source, au compartiment Amazon S3, à l' AWS Snowball Edge appareil, ainsi que la connexion à la base de données cible sur AWS.
Vous pouvez surveiller et gérer les tâches de migration des données et leurs sous-tâches dans l'onglet Tâches. Vous pouvez suivre la progression de la migration des données, ainsi que suspendre ou redémarrer vos tâches de migration de données.
Sortie de la tâche d'extraction de données
Une fois vos tâches de migration terminées, vos données sont prêtes. Utilisez les informations suivantes pour déterminer comment continuer en fonction du mode de migration que vous avez choisi et de l'emplacement de vos données.
| Mode de migration | Emplacement des données |
|---|---|
|
Extraire, télécharger et copier |
Les données se trouvent déjà dans votre entrepôt de données Amazon Redshift. Vous pouvez vérifier que les données sont bien là et commencer à les utiliser. Pour plus d'informations, consultez la section Connexion aux clusters à partir des outils et du code clients. |
|
Extraire et télécharger |
Les agents d'extraction ont enregistré vos données sous forme de fichiers dans votre compartiment Amazon S3. Vous pouvez utiliser la commande COPY d'Amazon Redshift pour charger vos données dans Amazon Redshift. Pour plus d'informations, consultez la section Chargement de données depuis Amazon S3 dans la documentation Amazon Redshift. Votre compartiment Amazon S3 contient plusieurs dossiers correspondant aux tâches d'extraction que vous avez configurées. Lorsque vous chargez vos données sur Amazon Redshift, spécifiez le nom du fichier manifeste créé par chaque tâche. Le fichier manifeste apparaît dans le dossier des tâches de votre compartiment Amazon S3, comme indiqué ci-dessous. 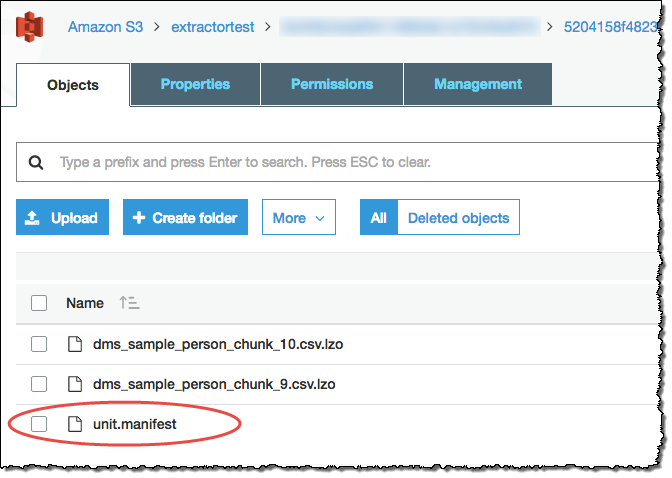
|
|
Extrait uniquement |
Les agents d'extraction ont enregistré vos données en tant que fichiers dans votre dossier de travail. Copiez manuellement vos données dans votre compartiment Amazon S3, puis suivez les instructions d'extraction et de chargement. |
Utilisation du partitionnement virtuel avec AWS Schema Conversion Tool
Il est souvent plus facile de gérer les grandes tables non partitionnées en créant des sous-tâches qui créent des partitions virtuelles des données de la table à l'aide des règles de filtrage. Dans AWS SCT, vous pouvez créer des partitions virtuelles pour vos données migrées. Il existe trois types de partitions, qui fonctionnent avec des types de données spécifiques :
Le type de partition RANGE fonctionne avec les types de données numérique, de date et d'heure.
Le type de partition LIST fonctionne avec les types de données numérique, de caractère, de date et d'heure.
Le type de partition DATE AUTO SPLIT fonctionne avec les types de données numériques, de date et d'heure.
AWS SCT valide les valeurs que vous fournissez pour créer une partition. Par exemple, si vous tentez de partitionner une colonne avec le type de données NUMERIC mais que vous fournissez des valeurs d'un autre type de données, une AWS SCT erreur est générée.
En outre, si vous migrez des données AWS SCT vers Amazon Redshift, vous pouvez utiliser le partitionnement natif pour gérer la migration de tables volumineuses. Pour de plus amples informations, veuillez consulter Utilisation du partitionnement natif.
Limites lors de la création d'un partitionnement virtuel
Les limitations à la création d'une partition virtuelle sont les suivantes :
Vous ne pouvez utiliser le partitionnement virtuel que pour les tables non partitionnées.
Vous ne pouvez utiliser le partitionnement virtuel que dans la vue de migration des données.
Vous ne pouvez pas utiliser l'option UNION ALL VIEW avec le partitionnement virtuel.
Type de cloison RANGE
Le type de partition RANGE partitionne les données en fonction d'une plage de valeurs de colonne pour les types de données numérique, de date et d'heure. Ce type de partition crée une clause WHERE et vous fournissez la plage de valeurs pour chaque partition. Pour spécifier une liste de valeurs pour la colonne partitionnée, utilisez la zone Valeurs. Vous pouvez charger les informations de valeur en utilisant un fichier .csv.
Le type de partition RANGE crée des partitions par défaut aux deux extrémités des valeurs de partition. Ces partitions par défaut capturent toutes les données inférieures ou supérieures aux valeurs de partition spécifiées.
Par exemple, vous pouvez créer plusieurs partitions en fonction d'une plage de valeurs que vous fournissez. Dans l'exemple suivant, les valeurs de partitionnement de LO_TAX sont spécifiées pour créer plusieurs partitions.
Partition1: WHERE LO_TAX <= 10000.9 Partition2: WHERE LO_TAX > 10000.9 AND LO_TAX <= 15005.5 Partition3: WHERE LO_TAX > 15005.5 AND LO_TAX <= 25005.95
Pour créer une partition virtuelle RANGE
Ouverte AWS SCT.
Choisissez le mode d'affichage de migration des données (autre).
Choisissez la table dans laquelle vous souhaitez configurer le partitionnement virtuel. Ouvrez le menu contextuel (clic droit) de la table, puis choisissez Ajouter un partitionnement virtuel.
Dans la boîte de dialogue Ajouter un partitionnement virtuel, entrez les informations suivantes.
Option Action Type de cloison
Choisissez RANGE. L'interface utilisateur de la boîte de dialogue varie en fonction du type que vous choisissez.
Nom de colonne
Choisissez la colonne à partitionner.
Type de colonne
Choisissez le type de données des valeurs de la colonne.
Valeurs
Ajoutez de nouvelles valeurs en tapant chaque valeur dans la zone New Value, puis en choisissant le signe plus pour ajouter la valeur.
Charger depuis un fichier
(Facultatif) Indiquez le nom du fichier .csv contenant les valeurs de partition.
-
Choisissez OK.
Type de partition LIST
Le type de partition LIST partitionne les données en fonction de valeurs de colonne pour les types de données numérique, de caractère, de date et d'heure. Ce type de partition crée une clause WHERE et vous fournissez les valeurs pour chaque partition. Pour spécifier une liste de valeurs pour la colonne partitionnée, utilisez la zone Valeurs. Vous pouvez charger les informations de valeur en utilisant un fichier .csv.
Par exemple, vous pouvez créer plusieurs partitions en fonction d'une valeur que vous fournissez. Dans l'exemple suivant, les valeurs de partitionnement de LO_ORDERKEY sont spécifiées pour créer plusieurs partitions.
Partition1: WHERE LO_ORDERKEY = 1 Partition2: WHERE LO_ORDERKEY = 2 Partition3: WHERE LO_ORDERKEY = 3 … PartitionN: WHERE LO_ORDERKEY = USER_VALUE_N
Vous pouvez également créer une partition par défaut pour les valeurs non incluses dans celles spécifiées.
Vous pouvez utiliser le type de partition LIST pour filtrer les données sources si vous souhaitez exclure des valeurs spécifiques de la migration. Supposons, par exemple, que vous souhaitiez omettre les lignes avecLO_ORDERKEY = 4. Dans ce cas, n'incluez pas la valeur 4 dans la liste des valeurs de partition et assurez-vous que l'option Inclure d'autres valeurs n'est pas sélectionnée.
Pour créer une partition virtuelle LIST
Ouverte AWS SCT.
Choisissez le mode d'affichage de migration des données (autre).
Choisissez la table dans laquelle vous souhaitez configurer le partitionnement virtuel. Ouvrez le menu contextuel (clic droit) de la table, puis choisissez Ajouter un partitionnement virtuel.
Dans la boîte de dialogue Ajouter un partitionnement virtuel, entrez les informations suivantes.
Option Action Type de cloison
Choisissez LIST. L'interface utilisateur de la boîte de dialogue varie en fonction du type que vous choisissez.
Nom de colonne
Choisissez la colonne à partitionner.
Nouvelle valeur
Tapez ici une valeur à ajouter à l'ensemble de valeurs de partitionnement.
Inclure d'autres valeurs
Choisissez cette option pour créer une partition par défaut dans laquelle sont stockées toutes les valeurs qui ne répondent aux critères de partitionnement.
Charger depuis un fichier
(Facultatif) Indiquez le nom du fichier .csv contenant les valeurs de partition.
Choisissez OK.
Type de partition DATE AUTO SPLIT
Le type de partition DATE AUTO SPLIT est un moyen automatique de générer des partitions RANGE. Avec DATA AUTO SPLIT, vous indiquez AWS SCT l'attribut de partitionnement, les points de départ et de fin, ainsi que la taille de la plage entre les valeurs. AWS SCT Calcule ensuite automatiquement les valeurs de partition.
DATA AUTO SPLIT automatise une grande partie du travail lié à la création de partitions de plage. Le compromis entre l'utilisation de cette technique et le partitionnement par plage est le niveau de contrôle dont vous avez besoin sur les limites de la partition. Le processus de division automatique crée toujours des plages de tailles égales (uniformes). Le partitionnement des plages vous permet de faire varier la taille de chaque plage en fonction de votre distribution de données particulière. Par exemple, vous pouvez utiliser tous les jours, toutes les semaines, toutes les deux semaines, tous les mois, etc.
Partition1: WHERE LO_ORDERDATE >= ‘1954-10-10’ AND LO_ORDERDATE < ‘1954-10-24’ Partition2: WHERE LO_ORDERDATE >= ‘1954-10-24’ AND LO_ORDERDATE < ‘1954-11-06’ Partition3: WHERE LO_ORDERDATE >= ‘1954-11-06’ AND LO_ORDERDATE < ‘1954-11-20’ … PartitionN: WHERE LO_ORDERDATE >= USER_VALUE_N AND LO_ORDERDATE <= ‘2017-08-13’
Pour créer une partition virtuelle DATE AUTO SPLIT
Ouverte AWS SCT.
Choisissez le mode d'affichage de migration des données (autre).
Choisissez la table dans laquelle vous souhaitez configurer le partitionnement virtuel. Ouvrez le menu contextuel (clic droit) de la table, puis choisissez Ajouter un partitionnement virtuel.
Dans la boîte de dialogue Ajouter un partitionnement virtuel, entrez les informations suivantes.
Option Action Type de cloison
Choisissez DATE AUTO SPLIT. L'interface utilisateur de la boîte de dialogue varie en fonction du type que vous choisissez.
Nom de colonne
Choisissez la colonne à partitionner.
Date de début
Tapez une date de début.
Date de fin
Tapez une date de fin.
Intervalle
Entrez l'unité d'intervalle et choisissez la valeur de cette unité.
Choisissez OK.
Utilisation du partitionnement natif
Pour accélérer la migration des données, vos agents d'extraction de données peuvent utiliser des partitions natives de tables sur votre serveur d'entrepôt de données source. AWS SCT prend en charge le partitionnement natif pour les migrations de Greenplum, Netezza et Oracle vers Amazon Redshift.
Par exemple, après avoir créé un projet, vous pouvez collecter des statistiques sur un schéma et analyser la taille des tables sélectionnées pour la migration. Pour les tables dont la taille dépasse la taille spécifiée, AWS SCT déclenche le mécanisme de partitionnement natif.
Pour utiliser le partitionnement natif
-
Ouvrez AWS SCT et choisissez Nouveau projet pour Fichier. La boîte de dialogue Nouveau projet apparaît.
-
Créez un nouveau projet, ajoutez vos serveurs source et cible et créez des règles de mappage. Pour de plus amples informations, veuillez consulter Démarrage et gestion de projets dans AWS SCT.
-
Choisissez Affichage, puis sélectionnez Affichage principal.
-
Pour les paramètres du projet, choisissez l'onglet Migration des données. Choisissez Utiliser le partitionnement automatique. Pour les bases de données sources Greenplum et Netezza, entrez la taille minimale des tables prises en charge en mégaoctets (par exemple, 100). AWS SCT crée automatiquement des sous-tâches de migration distinctes pour chaque partition native qui n'est pas vide. Pour les migrations d'Oracle vers Amazon Redshift, AWS SCT crée des sous-tâches pour toutes les tables partitionnées.
-
Dans le panneau de gauche qui affiche le schéma de votre base de données source, choisissez-en un. Ouvrez le menu contextuel (clic droit) de l'objet, puis choisissez Collecter des statistiques. Pour la migration des données d'Oracle vers Amazon Redshift, vous pouvez ignorer cette étape.
-
Choisissez toutes les tables à migrer.
-
Enregistrez le nombre d'agents requis. Pour de plus amples informations, veuillez consulter Enregistrement des agents d'extraction auprès du AWS Schema Conversion Tool.
-
Créez une tâche d'extraction de données pour les tables sélectionnées. Pour de plus amples informations, veuillez consulter Création, exécution et surveillance d'une tâche d'extraction de AWS SCT données.
Vérifiez si les grandes tables sont divisées en sous-tâches et que chaque sous-tâche correspond au jeu de données qui présente une partie de la table située sur une tranche de votre entrepôt de données source.
-
Démarrez et surveillez le processus de migration jusqu'à ce que AWS SCT les agents d'extraction de données aient terminé la migration des données depuis vos tables sources.
Migration LOBs vers Amazon Redshift
Amazon Redshift ne prend pas en charge le stockage d'objets binaires volumineux ()LOBs. Toutefois, si vous devez en migrer une ou plusieurs LOBs vers Amazon Redshift, AWS SCT vous pouvez effectuer la migration. Pour ce faire, AWS SCT utilise un compartiment Amazon S3 pour stocker LOBs et écrit l'URL du compartiment Amazon S3 dans les données migrées stockées dans Amazon Redshift.
Pour migrer LOBs vers Amazon Redshift
Ouvrez un AWS SCT projet.
Connectez-vous aux bases de données source et cible. Actualisez les métadonnées de la base de données cible et assurez-vous que les tables converties y existent.
Pour Actions, choisissez Créer une tâche locale.
-
Pour le mode migration, choisissez l'une des options suivantes :
-
Extrayez et chargez pour extraire vos données, et chargez vos données sur Amazon S3.
-
Extrayez, chargez et copiez pour extraire vos données, chargez vos données sur Amazon S3 et copiez-les dans votre entrepôt de données Amazon Redshift.
-
Choisissez les paramètres Amazon S3.
Pour LOBs le dossier du compartiment Amazon S3, entrez le nom du dossier dans le compartiment Amazon S3 où vous souhaitez le LOBs stocker.
Si vous utilisez le profil de AWS service, ce champ est facultatif. AWS SCT peut utiliser les paramètres par défaut de votre profil. Pour utiliser un autre compartiment Amazon S3, entrez le chemin ici.
-
Activez l'option Utiliser un proxy pour utiliser un serveur proxy afin de télécharger des données sur Amazon S3. Choisissez ensuite le protocole de transfert de données, entrez le nom d'hôte, le port, le nom d'utilisateur et le mot de passe.
-
Pour le type de point de terminaison, choisissez FIPS pour utiliser le point de terminaison FIPS (Federal Information Processing Standard). Choisissez VPCE pour utiliser le point de terminaison du cloud privé virtuel (VPC). Ensuite, pour le point de terminaison VPC, entrez le système de nom de domaine (DNS) de votre point de terminaison VPC.
-
Activez l'option Conserver les fichiers sur Amazon S3 après les avoir copiés sur Amazon Redshift pour conserver les fichiers extraits sur Amazon S3 après les avoir copiés sur Amazon Redshift.
Choisissez Create pour créer la tâche.
Bonnes pratiques et résolution des problèmes pour les agents d'extraction de données
Voici quelques bonnes pratiques et suggestions de dépannage relatives à l'utilisation des agents d'extraction.
| Problème | Suggestions de dépannage |
|---|---|
|
Les performances sont lentes |
Pour améliorer les performances, nous vous recommandons de procéder comme suit :
|
|
Délais d'attente en cas de conflit |
Evitez d'avoir un nombre trop élevé d'agents accédant simultanément à votre entrepôt de données. |
|
Un agent s'arrête temporairement |
Si un agent s'arrête, chacune de ses tâches apparaît comme ayant échoué dans AWS SCT. Si vous attendez un peu, il arrive parfois qu'une reprise de l'agent se produise. Dans ce cas, le statut de ses tâches est mis à jour dans AWS SCT. |
|
Un agent s'arrête définitivement |
Si l'ordinateur qui exécute un agent s'arrête de façon définitive alors que celui-ci est en train d'exécuter une tâche, vous pouvez remplacer cet agent par un autre afin de poursuivre l'exécution de la tâche. Vous pouvez le remplacer par un nouvel agent uniquement si le dossier de travail de l'agent d'origine ne se trouve pas sur le même ordinateur que l'agent d'origine. Pour le remplacer par un nouvel agent, procédez comme suit :
|
