Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation d’index secondaires globaux dans DynamoDB
Certaines applications peuvent avoir besoin d’exécuter de nombreux types de requêtes, à l’aide de divers attributs comme critères de requête. Pour prendre en charge ces exigences, vous pouvez créer un ou plusieurs index secondaires globaux et émettre des demandes Query sur ces index dans Amazon DynamoDB.
Rubriques
Synchronisation des données entre les tables et les index secondaires globaux
Considérations sur le débit alloué pour les index secondaires globaux
Considérations relatives au stockage pour les index secondaires globaux
Détection et correction des violations de clé d’index dans DynamoDB
Gestion des index secondaires globaux dans DynamoDB à l’aide de l’AWS CLI
Étape 6 : Utiliser un index secondaire global
À des fins d’illustration, considérons une table nommée GameScores qui assure le suivi des utilisateurs et enregistre les scores d’une application de jeux pour appareils mobiles. Chaque élément dans GameScores est identifié par une clé de partition (UserId) et une clé de tri (GameTitle). Le schéma suivant illustre la façon dont les éléments de la table seront organisés. (Tous les attributs ne sont pas affichés.)
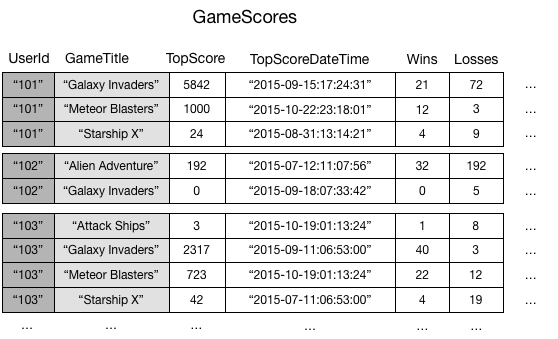
Supposons maintenant que vous vouliez écrire une application de classement pour afficher les meilleurs scores de chaque partie. Une requête ayant spécifié les attributs clé (UserId et GameTitle) serait très efficace. Cependant, si l’application a besoin d’extraire les données depuis GameScores en fonction de GameTitle uniquement, elle nécessiterait l’utilisation d’une opération Scan. Lorsque plusieurs éléments sont ajoutés à la table, les analyses de toutes les données deviennent lentes et inefficaces. Cela rend difficile la réponse aux questions suivantes :
-
Quel est le meilleur score jamais enregistré pour le jeu Meteor Blasters ?
-
Quel utilisateur a le score le plus élevé pour Galaxy Invaders ?
-
Quel est le taux plus élevé du nombre de victoires par rapport au nombre de pertes ?
Afin d’accélérer les requêtes sur des attributs autres que de clé, vous pouvez créer un index secondaire global. Un index secondaire global contient une sélection d’attributs de la table de base, mais ils sont organisés selon une clé primaire différente de celle de la table. La clé d’index n’a pas besoin d’avoir l’un des attributs de clé de la table. Elle n’a même pas besoin d’avoir le même schéma de clé qu’une table.
Par exemple, vous pouvez créer un index secondaire global nommé GameTitleIndex, avec une clé de partition GameTitle et une clé de tri TopScore. Comme les attributs de la clé primaire de la table de base sont toujours projetés sur un index, l’attribut UserId est également présent. Le schéma suivant illustre ce à quoi l’index GameTitleIndex doit ressembler.
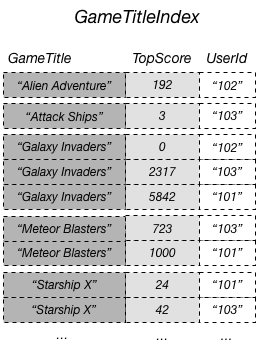
Maintenant, vous pouvez interroger GameTitleIndex et obtenir facilement les scores de Meteor Blasters. Les résultats sont triés sur les valeurs de la clé de tri, TopScore. Si vous définissez le paramètre ScanIndexForward sur la valeur false, les résultats sont retournés par ordre décroissant, de telle sorte que le meilleur score est retourné en premier.
Chaque index secondaire global doit avoir une clé de partition et peut avoir une clé de tri facultative. Le schéma de la clé d’index peut être différent de celui de la table de base. Vous pouvez disposer d’une table avec une clé primaire simple (clé de partition), et créer un index secondaire global avec une clé primaire composite (clé de partition et clé de tri), ou inversement. Les attributs de clé d’index peuvent se composer de n’importe lequel des attributs String, Number ou Binary de niveau supérieur de la table de base. Les autres types scalaires, types de document et types d’ensemble ne sont pas autorisés.
Vous pouvez projeter d’autres attributs de table de base sur l’index si vous le souhaitez. Lorsque vous interrogez l’index, DynamoDB peut extraire ces attributs projetés de façon efficace. Cependant, les interrogations d’index secondaire global ne peuvent pas extraire d’attributs de la table de base. Par exemple, si vous interrogez GameTitleIndex comme illustré dans le diagramme précédent, la requête ne peut pas accéder aux attributs non-clé autres que TopScore (même si les attributs de clé GameTitle et UserId sont automatiquement projetés).
Dans une table DynamoDB, chaque valeur de clé doit être unique. En revanche, les valeurs de clé dans un index secondaire global n’ont pas besoin d’être uniques. À des fins d’illustration, supposons qu’un jeu nommé Comet Quest soit particulièrement difficile, avec de nombreux utilisateurs qui tentent en vain d’obtenir un score supérieur à zéro. Les quelques données suivantes représentent ce comportement.
| UserId | GameTitle | TopScore |
|---|---|---|
| 123 | Comet Quest | 0 |
| 201 | Comet Quest | 0 |
| 301 | Comet Quest | 0 |
Lorsque de l’ajout de ces données à la table GameScores, DynamoDB les propage vers GameTitleIndex. Si nous interrogeons alors l’index à l’aide de Comet Quest pour GameTitle et de 0 pour TopScore, les données suivantes sont renvoyées.
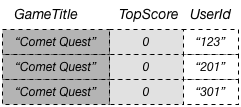
Seuls les éléments avec les valeurs de clé spécifiée apparaissent dans la réponse. Au sein de cet ensemble de données, les éléments ne figurent dans aucun ordre particulier.
Un index secondaire global ne suit que les éléments de données où ses attributs clés existent réellement. Par exemple, supposons que vous ayez ajouté un nouvel élément à la table GameScores, mais que vous n’ayez fourni que les attributs de clé primaires requis.
| UserId | GameTitle |
|---|---|
| 400 | Comet Quest |
Étant donné que vous n’avez pas spécifié l’attribut TopScore, DynamoDB ne propage pas cet élément vers GameTitleIndex. Par conséquent, si vous interrogiez GameScores pour tous les éléments Comet Quest, vous obtiendriez les quatre éléments suivants.
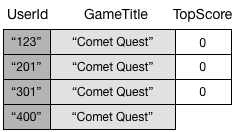
Une requête similaire sur GameTitleIndex renvoie toujours trois éléments, plutôt que quatre. Cela est dû au fait que l’élément avec TopScore non existant n’est pas propagé sur l’index.
Projections d’attribut
Une projection est l’ensemble d’attributs copié à partir d’une table dans un index secondaire. Les clés de partition et de tri de la table sont toujours projetées dans l’index. Vous pouvez projeter d’autres attributs en fonction des exigences de requête de votre application. Lorsque vous interrogez un index, Amazon DynamoDB peut accéder à n’importe quel attribut dans la projection, comme s’il se trouvait dans une table.
Lorsque vous créez un index secondaire, vous devez spécifier les attributs qui seront projetés dans celui-ci. Pour cela, DynamoDB propose trois options :
-
KEYS_ONLY – Chaque élément de l’index se compose uniquement des valeurs de clé de partition et de tri de la table, ainsi que des valeurs de clé d’index. L’option
KEYS_ONLYproduit l’index secondaire le plus petit possible. -
INCLUDE – En plus des attributs décrits dans
KEYS_ONLY, l’index secondaire inclut des attributs autres que de clé, que vous spécifiez. -
ALL – L’index secondaire inclut tous les attributs de la table source. Toutes les données de la table étant dupliquées dans l’index, une projection
ALLproduit l’index secondaire le plus grand possible.
Dans le précédent diagramme, GameTitleIndex n’a qu’un seul attribut projeté : UserId. Par conséquent, si une application peut déterminer efficacement le UserId des joueurs avec les scores les plus élevés pour chaque jeu à l’aide de GameTitle et de TopScore dans des requêtes, elle peut déterminer efficacement le taux le plus élevé de victoires par rapport au nombre de défaites pour ces joueurs. Pour ce faire, l'application devra effectuer une requête supplémentaire sur la table de base pour récupérer les victoires et les défaites de chacun des meilleurs buteurs. Une façon plus efficace de prendre en charge les requêtes sur ces données serait de projeter ces attributs de la table de base vers l’index secondaire global, comme illustré dans ce diagramme.
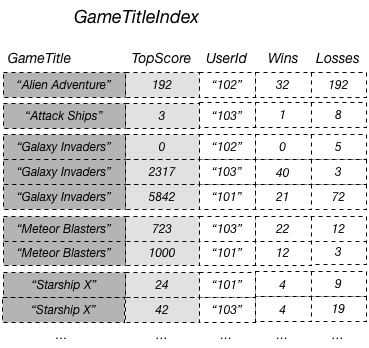
Comme les attributs non clés Wins etLosses sont projetés dans l’index, une application peut déterminer le rapport entre le nombre de victoires et le nombre de défaites de n’importe quel jeu, ou pour toute combinaison d’ID d’utilisateur et de jeu.
Lorsque vous choisissez les attributs à projeter sur un index secondaire global, vous devez prendre en compte le compromis entre les coûts de débit approvisionné et les coûts de stockage :
-
Si vous n’avez besoin d’accéder qu’à quelques attributs avec la plus faible latence possible, envisagez de projeter ces seuls attributs dans un index secondaire global. Plus l’index est petit, moins les coûts d’écriture et de stockage sont élevés.
-
Si votre application accède fréquemment à des attributs autres que de clé, vous devez envisager de projeter ceux-ci dans un index secondaire global. Les coûts de stockage supplémentaires de l’index secondaire global compensent le coût d’exécution d’analyses de table fréquentes.
-
Si vous avez besoin d’accéder fréquemment à la plupart des attributs autres que de clé, vous pouvez projeter ceux-ci (voire la table de base toute entière) dans un index secondaire global. Cela vous offre une flexibilité maximale. Cependant, vos coûts de stockage augmenteront, voire doubleront.
-
Si votre application doit interroger peu fréquemment une table, mais doit exécuter un grand nombre d’écritures ou de mises à jour des données de la table, pensez à projeter
KEYS_ONLY. L’index secondaire global sera d’une taille minimale, mais continuera d’être disponible chaque fois que ce sera nécessaire pour une activité de requête.
Multi-attribute schéma clé
Les index secondaires globaux prennent en charge les clés à attributs multiples, ce qui vous permet de composer des clés de partition et de trier les clés à partir de plusieurs attributs. Avec les clés à attributs multiples, vous pouvez créer une clé de partition à partir de quatre attributs au maximum et une clé de tri à partir de quatre attributs, pour un total de huit attributs par schéma de clé.
Multi-attribute les clés simplifient votre modèle de données en éliminant le besoin de concaténer manuellement les attributs dans des clés synthétiques. Au lieu de créer des chaînes compositesTOURNAMENT#WINTER2024#REGION#NA-EAST, vous pouvez utiliser directement les attributs naturels de votre modèle de domaine. DynamoDB gère automatiquement la logique des clés composites, en hachant plusieurs attributs de clé de partition pour la distribution des données et en maintenant un ordre de tri hiérarchique entre plusieurs attributs de clé de tri.
Par exemple, imaginez un système de tournois de jeu dans lequel vous souhaitez organiser les matchs par tournoi et par région. Avec les clés à attributs multiples, vous pouvez définir votre clé de partition sous la forme de deux attributs distincts : tournamentId etregion. De même, vous pouvez définir votre clé de tri à l'aide de plusieurs attributs tels que roundbracket, et matchId pour créer une hiérarchie naturelle. Cette approche permet de saisir vos données et de garder votre code propre, sans manipulation de chaînes ni analyse syntaxique.
Lorsque vous interrogez un index secondaire global avec des clés à attributs multiples, vous devez spécifier tous les attributs de clé de partition en utilisant des conditions d'égalité. Pour trier les attributs clés, vous pouvez les interroger de gauche à droite dans l'ordre dans lequel ils sont définis dans le schéma de clé. Cela signifie que vous pouvez interroger le premier attribut clé de tri seul, les deux premiers attributs ensemble ou tous les attributs ensemble, mais vous ne pouvez pas ignorer les attributs situés au milieu. Les conditions d'inégalité telles que > <BETWEEN,, ou begins_with() doivent être la dernière condition de votre requête.
Multi-attribute les clés fonctionnent particulièrement bien lors de la création d'index secondaires globaux sur des tables existantes. Vous pouvez utiliser des attributs qui existent déjà dans votre table sans avoir à ajouter des clés synthétiques à vos données. Il est ainsi facile d'ajouter de nouveaux modèles de requête à votre application en créant des index qui réorganisent vos données à l'aide de différentes combinaisons d'attributs.
Chaque attribut d'une clé à attributs multiples peut avoir son propre type de données : String (S), Number (N) ou Binary (B). Lorsque vous choisissez des types de données, considérez que Number les attributs sont triés numériquement sans nécessiter de remplissage nul, tandis que les String attributs sont triés de manière lexicographique. Par exemple, si vous utilisez un Number type pour un attribut de score, les valeurs 5, 50, 500 et 1000 sont triées par ordre numérique naturel. Les mêmes valeurs que le String type seront triées comme « 1000 », « 5 », « 50 », « 500 », sauf si vous les complétez avec des zéros en tête.
Lorsque vous concevez des clés à attributs multiples, classez vos attributs du plus général au plus spécifique. Pour les clés de partition, combinez les attributs qui sont toujours interrogés ensemble et qui assurent une bonne distribution des données. Pour les clés de tri, placez les attributs fréquemment demandés en premier dans la hiérarchie afin d'optimiser la flexibilité des requêtes. Cet ordre vous permet d'effectuer des requêtes à n'importe quel niveau de granularité correspondant à vos habitudes d'accès.
Consultez le Clés à attributs multiples pour des exemples de mise en œuvre.
Lecture de données à partir d’un index secondaire global
Vous pouvez extraire des éléments d’un index secondaire global à l’aide des opérations Query et Scan. Vous ne pouvez pas utiliser les opérations GetItem et BatchGetItem sur un index secondaire global.
Interrogation d’un index secondaire global
Vous pouvez utiliser l’opération Query pour accéder à un ou plusieurs éléments dans un index secondaire global. La requête doit spécifier le nom de la table de base et le nom de l’index que vous souhaitez utiliser, les attributs à renvoyer dans les résultats de la requête, ainsi que toutes les conditions de requête que vous souhaitez appliquer. DynamoDB peut renvoyer les résultats dans l’ordre croissant ou décroissant.
Prenez en compte les données suivantes retournées à partir d’une opération Query qui demande les données de jeu pour une application de classement.
{ "TableName": "GameScores", "IndexName": "GameTitleIndex", "KeyConditionExpression": "GameTitle = :v_title", "ExpressionAttributeValues": { ":v_title": {"S": "Meteor Blasters"} }, "ProjectionExpression": "UserId, TopScore", "ScanIndexForward": false }
Dans cette requête :
-
DynamoDB y GameTitleIndexaccède à l'aide de la clé de partition pour localiser GameTitleles éléments d'index des Meteor Blasters. Tous les éléments d’index avec cette clé sont stockés les uns à côté des autres pour une récupération rapide.
-
Dans ce jeu, DynamoDB utilise l’index pour accéder à tous les ID d’utilisateur et aux meilleurs scores pour ce jeu.
-
Les résultats sont retournés, triés par ordre décroissant, car le paramètre
ScanIndexForwarda la valeur false.
Interrogation d’un index secondaire global
Vous pouvez utiliser l’opération Scan pour extraire toutes les données d’un index secondaire global. Vous devez fournir le nom de la table de base et le nom de l’index dans la demande. Avec une opération Scan, DynamoDB lit toutes les données de l’index et les renvoie à l’application. Vous pouvez également demander que seules quelques données soient retournées, et que les données restantes soient ignorées. Pour ce faire, utilisez le paramètre FilterExpression de l’opération Scan. Pour de plus amples informations, veuillez consulter Filtrer les expressions à des fins d’analyse.
Synchronisation des données entre les tables et les index secondaires globaux
DynamoDB synchronise automatiquement chaque index secondaire global avec sa table de base. Quand une application écrit ou supprime des éléments dans une table, tout index secondaire global sur cette table est mis à jour de manière asynchrone, à l’aide d’un modèle éventuellement cohérent. Les applications n’écrivent jamais directement sur un index. Cependant, il est important de comprendre les implications de la façon dont DynamoDB gère ces index.
Les index secondaires globaux héritent du mode read/write capacité de la table de base. Pour de plus amples informations, veuillez consulter Considérations relatives au changement de mode de capacité dans DynamoDB.
Lorsque vous créez un index secondaire global, vous spécifiez un ou plusieurs attributs de clé d’index et leurs types de données. Cela signifie que chaque fois que vous écrivez un élément sur la table de base, les types de données de ces attributs doivent correspondre aux types de données du schéma de la clé d’index. Dans le cas de GameTitleIndex, la clé de partition GameTitle de l’index est définie comme type de données String. La clé de tri TopScore de l’index est de type Number. Si vous essayez d’ajouter un élément à la table GameScores et spécifiez un type de données différent pour GameTitle ou pour TopScore, DynamoDB renvoie une ValidationException en raison de la discordance des types de données.
Lorsque vous insérez ou supprimez des éléments dans une table, les index secondaires globaux sont mis à jour selon une façon éventuellement cohérente. Les modifications apportées aux données de la table sont propagées sur les index secondaires globaux en une fraction de seconde, dans des conditions normales. Cependant, dans certains scénarios de défaillance peu probables, les retards de propagation peuvent être plus longs. Pour cette raison, vos applications ont besoin d’anticiper et de gérer les situations où une requête sur un index secondaire global renvoie des résultats qui ne sont pas à jour.
Si vous écrivez un élément dans une table, vous n’avez pas à spécifier les attributs pour une clé de tri d’index secondaire global. Si vous utilisez GameTitleIndex comme exemple, vous n’avez pas besoin de spécifier une valeur pour l’attribut TopScore pour pouvoir écrire un nouvel élément sur la table GameScores. Dans ce cas, DynamoDB n’écrit aucune donnée dans l’index pour cet élément particulier.
Une table avec de nombreux index secondaires globaux s’expose à des coûts plus élevés pour l’activité d’écriture qu’une table ayant moins d’index. Pour de plus amples informations, veuillez consulter Considérations sur le débit alloué pour les index secondaires globaux.
Classes de tables avec index secondaire global
Un index secondaire global utilisera toujours la même classe de tables que sa table de base. Chaque fois qu’un nouvel index secondaire global est ajouté à une table, le nouvel index utilise la même classe de tables que sa table de base. Lorsque la classe de tables d’une table est mise à jour, tous les index secondaires globaux associés sont également mis à jour.
Considérations sur le débit alloué pour les index secondaires globaux
Lorsque vous créez un index secondaire global sur une table en mode approvisionné, vous devez spécifier des unités de capacité de lecture et d’écriture pour la charge de travail prévue sur cet index. Les paramètres de débit approvisionné d’un index secondaire global sont distincts de ceux de sa table de base. Une opération Query sur un index secondaire global consomme les unités de capacité de lecture de l’index, pas de la table de base. Lorsque vous insérez ou supprimez des éléments dans une table, les index secondaires globaux sont également mis à jour. Ces mises à jour d’index consomment des unités de capacité d’écriture à partir de l’index, et non à partir de la table de base.
Par exemple, si vous exécutez une opération Query sur un index secondaire global et dépassez sa capacité de lecture approvisionnée, votre demande est limitée. Si vous exécutez une activité d’écriture massive sur la table, alors qu’un index secondaire global sur celle-ci a une capacité d’écriture insuffisante, l’activité d’écriture sur la table est limitée.
Important
Pour éviter les limitations potentielles, la capacité d’écriture allouée pour un index secondaire global doit être supérieure ou égale à la capacité d’écriture de la table de base, car les nouvelles mises à jour écrivent dans la table de base et l’index secondaire global.
Afin de modifier les paramètres de débit approvisionné pour un index secondaire global, utilisez l’opération DescribeTable. Des informations détaillées sur tous les index secondaires globaux de la table sont retournées.
Unités de capacité de lecture
Les index secondaires globaux prennent en charge les lectures éventuellement cohérentes ; chacune d’elles utilise la moitié d’une unité de capacité en lecture. Cela signifie qu’une interrogation d’index secondaire global peut extraire jusqu’à 2 x 4 Ko = 8 Ko par unité de capacité de lecture.
Pour les interrogations d’index secondaire global, DynamoDB calcule l’activité de lecture approvisionnée de la même façon que pour les interrogations de tables. La seule différence est que le calcul est basé sur les tailles des entrées d’index, plutôt que sur la taille de l’élément de la table de base. Le nombre d’unités de capacité en lecture est la somme des tailles de tous les attributs projetés de tous les éléments renvoyés. Le résultat est ensuite arrondi à la limite de 4 Ko suivante. Pour plus d’informations sur la façon dont DynamoDB calcule l’utilisation du débit approvisionné, consultez Mode de capacité provisionnée DynamoDB.
La taille maximum des résultats renvoyés par une opération Query est de 1 Mo. Cela inclut les tailles de tous les noms et valeurs d’attribut à travers l’ensemble des éléments retournés.
Par exemple, considérons un index secondaire global où chaque élément contient 2 000 octets de données. Supposons à présent que vous effectuez une opération Query sur cet index et que la KeyConditionExpression de la requête renvoie huit éléments. La taille totale des éléments correspondants est de 2 000 octets x 8 éléments = 16 000 octets. Ce résultat est ensuite arrondi à la limite de 4 Ko la plus proche. Les interrogations d’index secondaire global étant éventuellement cohérentes, le coût total est de 0,5 x (16 Ko / 4 Ko), soit 2 unités de capacité de lecture.
Unités de capacité d’écriture
Lors de l’ajout, de la mise à jour ou de la suppression d’un élément dans une table, si l’opération affecte un index secondaire global, celui-ci consomme les unités de capacité d’écriture approvisionnée à cette fin. Le coût total du débit alloué pour une écriture se compose de la somme des unités de capacité en écriture utilisées par l’écriture sur la table de base et de celles utilisées par la mise à jour des index secondaires globaux. Notez que, si une écriture dans une table ne requiert de mise à jour d’index secondaire global, aucune capacité d’écriture n’est consommée à partir de l’index.
Pour qu’une écriture de table réussisse, les paramètres de débit provisionnés de la table et de tous ses index secondaires globaux doivent avoir une capacité d’écriture suffisante pour accueillir l’écriture. Sinon, l’écriture dans la table est limitée.
Important
Lors de la création d’un index secondaire global (GSI), les opérations d’écriture dans la table de base peuvent être limitées si l’activité GSI résultant des écritures dans la table de base dépasse la capacité d’écriture allouée au GSI. Cette limitation affecte toutes les opérations d’écriture, du processus d’indexation à la perturbation potentielle de vos charges de travail de production. Pour plus d’informations, consultez Résolution des problèmes de limitation dans Amazon DynamoDB.
Le coût d’écriture d’un élément dans un index secondaire global dépend de plusieurs facteurs :
-
Si vous écrivez un nouvel élément sur la table qui définit un attribut indexé, ou que vous mettez à jour un élément existant pour définir un attribut indexé précédemment non défini, une opération d’écriture est nécessaire pour insérer l’élément dans l’index.
-
Si une mise à jour de la table change la valeur d’un attribut de clé indexée (de A en B), deux écritures sont requises, une pour supprimer l’élément précédent de l’index et une autre pour insérer le nouveau élément dans l’index.
-
Si un élément était présent dans l’index, mais qu’une écriture sur la table a entraîné la suppression de l’attribut indexé, une écriture est nécessaire pour supprimer de l’index la projection de l’ancien élément.
-
Si un élément n’est pas présent dans l’index avant ou après la mise à jour de l’élément, il n’y a aucun coût d’écriture supplémentaire pour l’index.
-
Si la mise à jour de la table ne modifie que la valeur des attributs projetés du schéma de clé d’index, mais ne change pas la valeur d’un quelconque attribut de clé indexé, une écriture est nécessaire pour mettre à jour les valeurs des attributs projetés sur l’index.
-
Si une mise à jour de la table ne modifie que des attributs qui ne sont ni des attributs clés d'index ni des attributs projetés dans l'index, l'entrée d'index reste inchangée, de sorte qu'aucune capacité d'écriture n'est consommée pour cet index. La table de base est toujours facturée pour l'écriture.
Tous ces facteurs partent du principe que la taille de chaque élément dans l’index est inférieure ou égale à la taille d’élément de 1 Ko pour le calcul des unités de capacité d’écriture. Les plus grandes entrées d’index nécessitent des unités de capacité en écriture supplémentaires. Vous pouvez réduire vos coûts d’écriture en considérant les attributs que vos requêtes ont besoin de retourner et en projetant uniquement ces attributs dans l’index.
Considérations relatives au stockage pour les index secondaires globaux
Quand une application écrit un élément dans une table, DynamoDB copie automatiquement le sous-ensemble approprié d’attributs vers les index secondaires globaux où ces attributs doivent apparaître. Votre AWS compte est débité pour le stockage de l'article dans la table de base ainsi que pour le stockage des attributs dans les index secondaires globaux de cette table.
La quantité d’espace utilisée par un élément de l’index est la somme des éléments suivants :
-
La taille en octets de la clé primaire de la table de base (clé de partition et clé de tri)
-
La taille en octets de l’attribut de clé d’index
-
La taille en octets des attributs projetés (le cas échéant)
-
100 octets de surcharge par élément d’index
Afin d’estimer les exigences de stockage pour un index secondaire global, vous pouvez évaluer la taille moyenne d’un élément de l’index, puis la multiplier par le nombre d’éléments de la table de base ayant les attributs de clé d’index secondaire global.
Si une table contient un élément dont aucun attribut particulier n'est défini, mais que cet attribut est défini comme clé de partition d'index ou clé de tri, DynamoDB n'écrit aucune donnée pour cet élément dans l'index.
