Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Surveillance des mises à jour du statut d’un appareil dans DynamoDB
Ce cas d’utilisation décrit l’utilisation de DynamoDB pour surveiller les mises à jour du statut d’un appareil (ou les changements d’état d’un appareil) dans DynamoDB.
Cas d’utilisation
Dans les cas d’utilisation IoT (une fabrique intelligente, par exemple), de nombreux appareils doivent être surveillés par les opérateurs, qui envoient régulièrement leur statut ou leurs journaux à un système de surveillance. En cas de problème avec un appareil, son statut passe de normal à warning. Il existe différents niveaux ou statuts de journalisation en fonction de la gravité et du type de comportement anormal de l’appareil. Le système désigne ensuite un opérateur chargé de vérifier l’appareil et celui-ci peut faire remonter le problème à son superviseur si nécessaire.
Les modèles d’accès types pour ce système incluent :
-
Créer une entrée de journal pour un appareil
-
Obtenir tous les journaux pour un état d’appareil spécifique en affichant d’abord les journaux les plus récents
-
Obtenir tous les journaux pour un opérateur donné entre deux dates
-
Obtenir tous les journaux qui ont été remontés pour un superviseur donné
-
Obtenir tous les journaux qui ont été remontés avec un état d’appareil spécifique pour un superviseur donné
-
Obtenir tous les journaux qui ont été remontés avec un état d’appareil spécifique pour un superviseur donné à une date spécifique
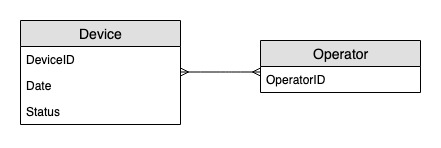
Diagramme des relations entre entités
Voici le diagramme des relations entre entités (ERD) que nous allons utiliser pour surveiller les mises à jour du statut d’un appareil.
Modèles d’accès
Voici les modèles d’accès que nous allons prendre en compte pour surveiller les mises à jour du statut d’un appareil.
-
createLogEntryForSpecificDevice -
getLogsForSpecificDevice -
getWarningLogsForSpecificDevice -
getLogsForOperatorBetweenTwoDates -
getEscalatedLogsForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisorForDate
Évolution de la conception du schéma
Étape 1 : Traitement des modèles d’accès 1 (createLogEntryForSpecificDevice) et 2 (getLogsForSpecificDevice)
L’unité de mise à l’échelle d’un système de suivi des appareils est constituée d’appareils individuels. Dans ce système, un deviceID identifie un appareil de manière unique. deviceID est donc un bon candidat pour la clé de partition. Chaque appareil envoie régulièrement des informations au système de suivi (toutes les cinq minutes environ). Cet ordre fait de la date un critère de tri logique et, par conséquent, la clé de tri. Dans ce cas, les exemples de données ressembleraient à ce qui suit :
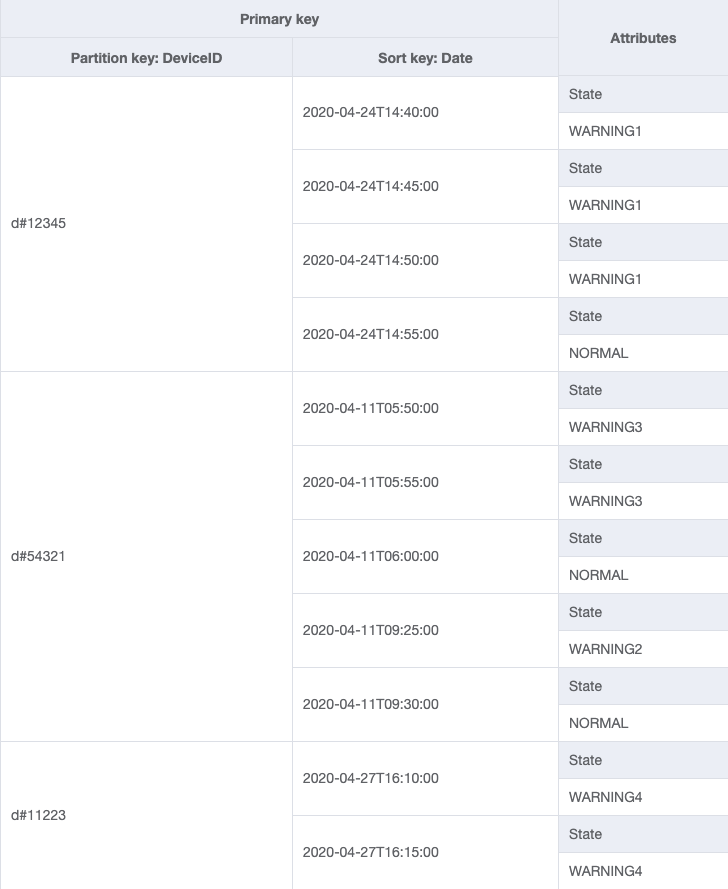
Pour extraire les entrées de journal d’un appareil spécifique, il est possible d’exécuter une opération query avec la clé de partition DeviceID="d#12345".
Étape 2 : Traitement du modèle d’accès 3 (getWarningLogsForSpecificDevice)
Étant donné que State est un attribut non clé, le traitement du modèle d’accès 3 avec le schéma actuel nécessiterait une expression de filtre. Dans DynamoDB, les expressions de filtre sont appliquées après la lecture des données à l’aide d’expressions de condition de clé. Par exemple, si nous devions extraire les journaux d’avertissement pour d#12345, l’opération de requête avec la clé de partition DeviceID="d#12345" lirait quatre éléments du tableau ci-dessus, puis filtrerait le seul élément sans l’état warning. Cette approche n’est pas efficace à grande échelle. L’expression de filtre peut être un bon moyen d’exclure les éléments interrogés si le ratio des éléments exclus est faible ou si la requête est rarement exécutée. Toutefois, dans les cas où de nombreux éléments sont extraits d’une table et que la majorité d’entre eux sont filtrés, nous pouvons continuer à faire évoluer la conception de notre table afin qu’elle s’exécute plus efficacement.
Nous allons changer la façon de traiter ce modèle d’accès en utilisant des clés de tri composites. Vous pouvez importer des exemples de données depuis DeviceStateLog_3.jsonState#Date Cette clé de tri est la composition des attributs State, # et Date. Dans cet exemple, # est utilisé comme délimiteur. Les données ressemblent désormais à ce qui suit :
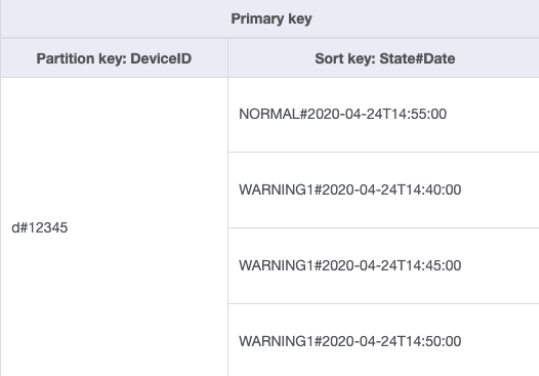
Pour extraire uniquement les journaux d’avertissement d’un appareil, la requête devient plus ciblée avec ce schéma. La condition de clé pour la requête utilise la clé de partition DeviceID="d#12345" et la clé de tri State#Date begins_with
“WARNING”. Cette requête ne lira que les trois éléments pertinents avec l’état warning.
Étape 3 : Traitement du modèle d’accès 4 (getLogsForOperatorBetweenTwoDates)
Vous pouvez importer DeviceStateLog_4.jsonOperatorattribut a été ajouté à la DeviceStateLog table avec des exemples de données.
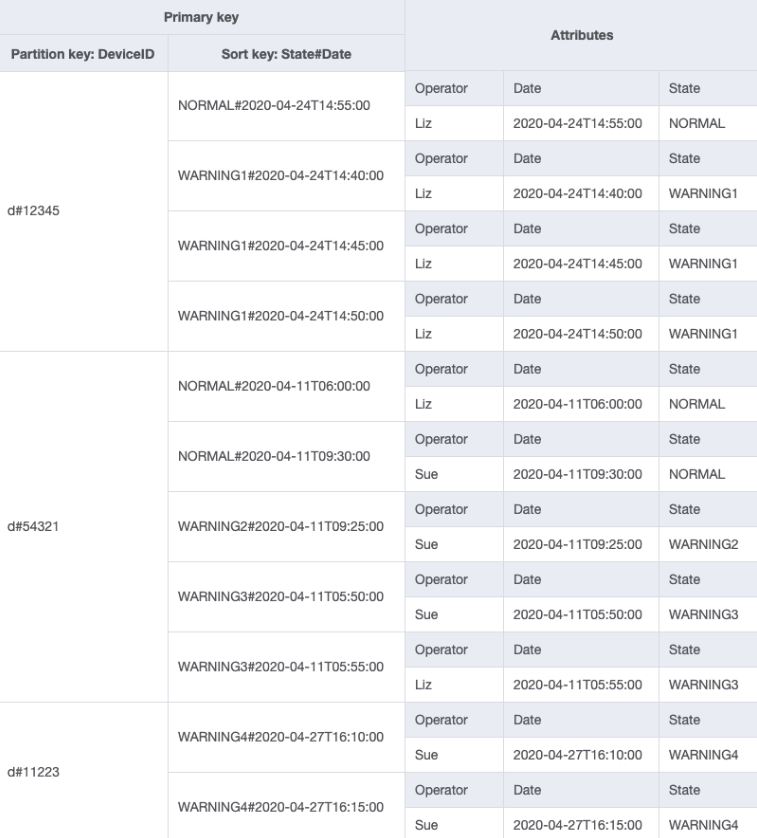
Étant donné que Operator n’est pas une clé de partition actuellement, il n’existe aucun moyen d’effectuer une recherche directe clé-valeur dans cette table en fonction de OperatorID. Nous devrons créer une collection d’éléments avec un index secondaire global sur OperatorID. Étant donné que le modèle d’accès nécessite une recherche basée sur les dates, Date est donc l’attribut de clé de tri pour l’index secondaire global (GSI). Voici à quoi ressemble désormais le GSI :
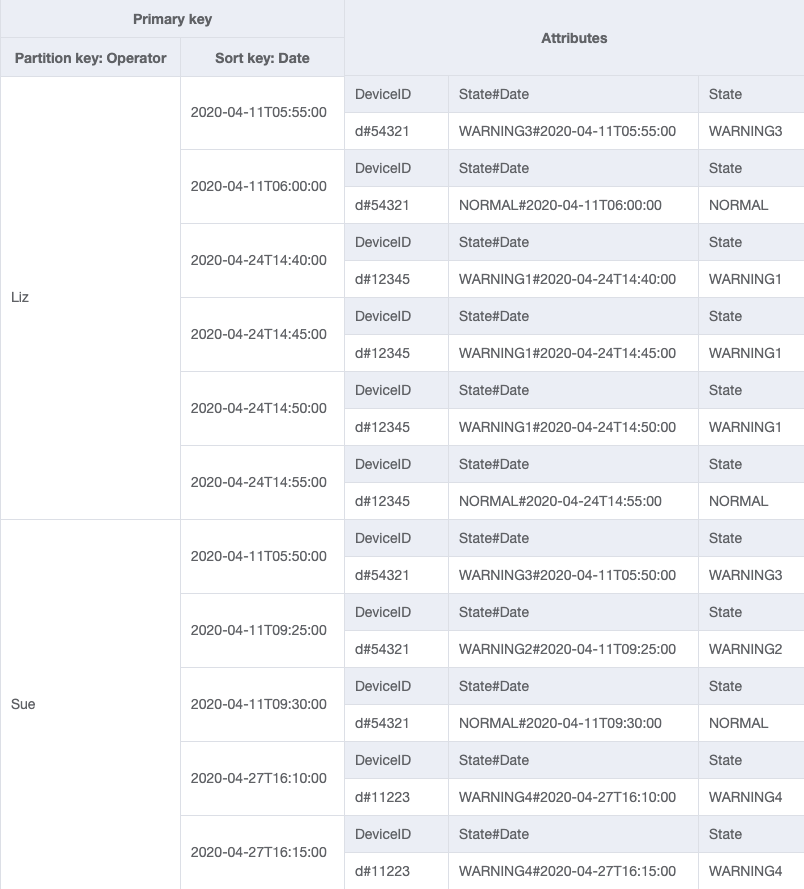
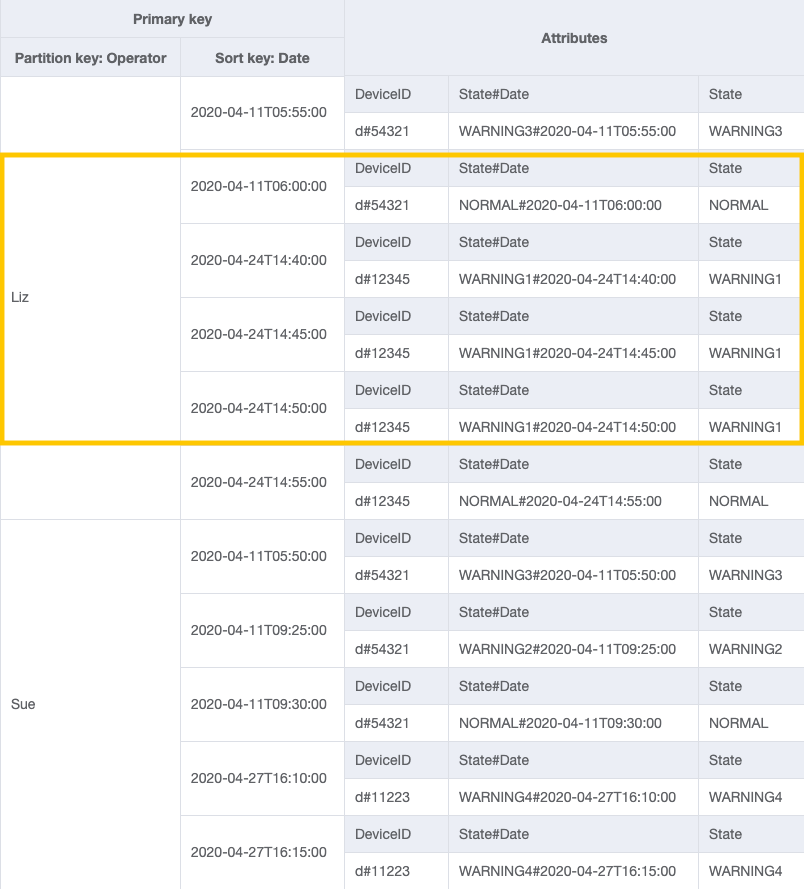
Pour le modèle d’accès 4 (getLogsForOperatorBetweenTwoDates), vous pouvez interroger ce GSI avec la clé de partition OperatorID=Liz et la clé de tri Date entre 2020-04-11T05:58:00 et 2020-04-24T14:50:00.
Étape 4 : Traitement des modèles d’accès 5 (getEscalatedLogsForSupervisor), 6 (getEscalatedLogsWithSpecificStatusForSupervisor) et 7 (getEscalatedLogsWithSpecificStatusForSupervisorForDate)
Nous utiliserons un index fragmenté pour traiter ces modèles d’accès.
Les index secondaires globaux sont fragmentés par défaut, de sorte que seuls les éléments de la table de base contenant les attributs de clé primaire de l’index apparaîtront réellement dans l’index. Il s’agit d’une autre façon d’exclure les éléments qui ne sont pas pertinents pour le modèle d’accès modélisé.
Vous pouvez importer DeviceStateLog_6.jsonEscalatedToattribut a été ajouté à la DeviceStateLog table avec des exemples de données. Comme mentionné précédemment, tous les journaux ne font pas l’objet d’une remontée à un superviseur.
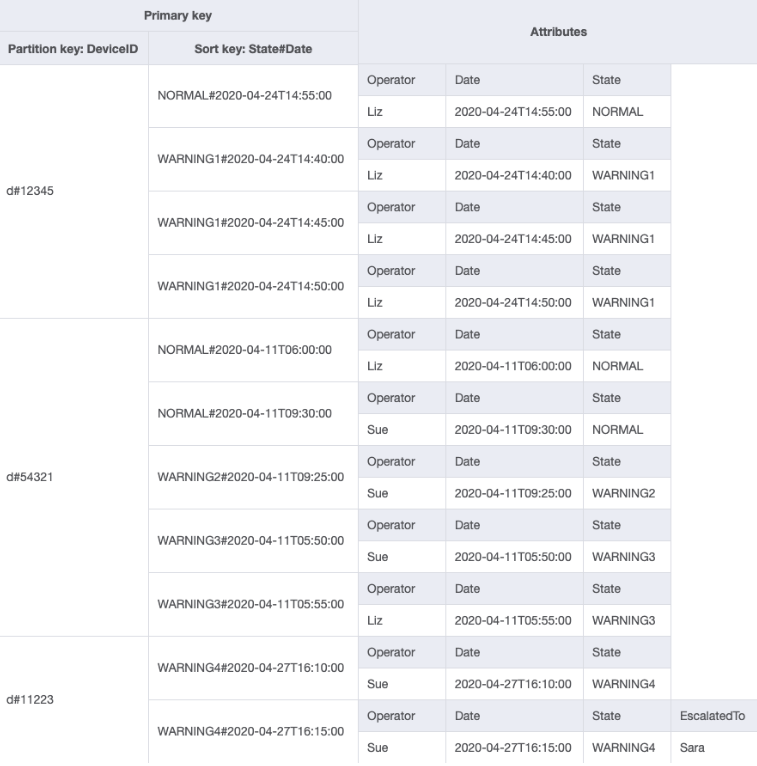
Vous pouvez maintenant créer un GSI où EscalatedTo est la clé de partition et State#Date est la clé de tri. Notez que seuls les éléments qui possèdent à la fois les attributs EscalatedTo et State#Date apparaissent dans l’index.

Les autres modèles d’accès sont résumés comme suit :
Tous les modèles d’accès et la façon dont ils sont traités par la conception du schéma sont résumés dans le tableau ci-dessous :
| Modèle d’accès | table/GSIBase/LSI | Opération | Valeur de la clé de partition | Valeur de clé de tri | Autres conditions/filters |
|---|---|---|---|---|---|
| créer LogEntryForSpecificDevice | Table de base | PutItem | DeviceID=deviceId | State#Date=state#date | |
| obtenir LogsForSpecificDevice | Table de base | Query | DeviceID=deviceId | State#Date begins_with "state1#" | ScanIndexForward = Faux |
| obtenir WarningLogsForSpecificDevice | Table de base | Query | DeviceID=deviceId | State#Date begins_with "WARNING" | |
| obtenir LogsForOperatorBetweenTwoDates | GSI-1 | Query | Operator=operatorName | Date between date1 and date2 | |
| obtenir EscalatedLogsForSupervisor | GSI-2 | Query | EscalatedTo= Nom du superviseur | ||
| obtenir EscalatedLogsWithSpecificStatusForSupervisor | GSI-2 | Query | EscalatedTo= Nom du superviseur | State#Date begins_with "state1#" | |
| obtenir EscalatedLogsWithSpecificStatusForSupervisorForDate | GSI-2 | Query | EscalatedTo= Nom du superviseur | State#Date begins_with "state1#date1" |
Schéma final
Voici les conceptions du schéma final. Pour télécharger cette conception de schéma sous forme de fichier JSON, consultez les exemples DynamoDB
Table de base
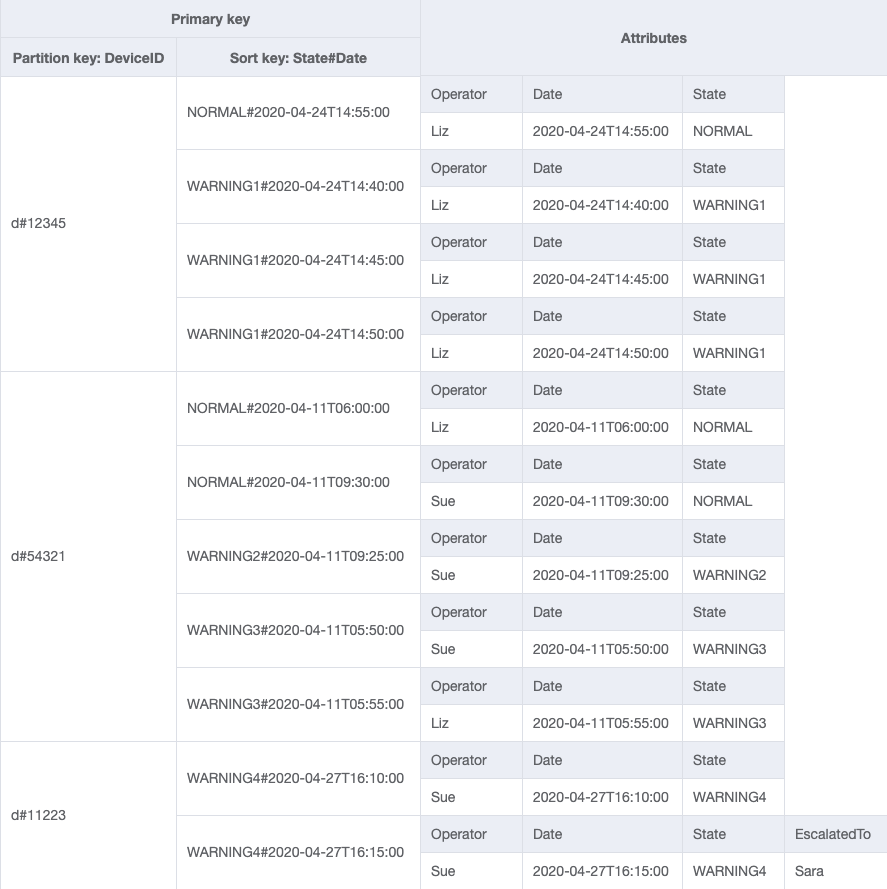
GSI-1
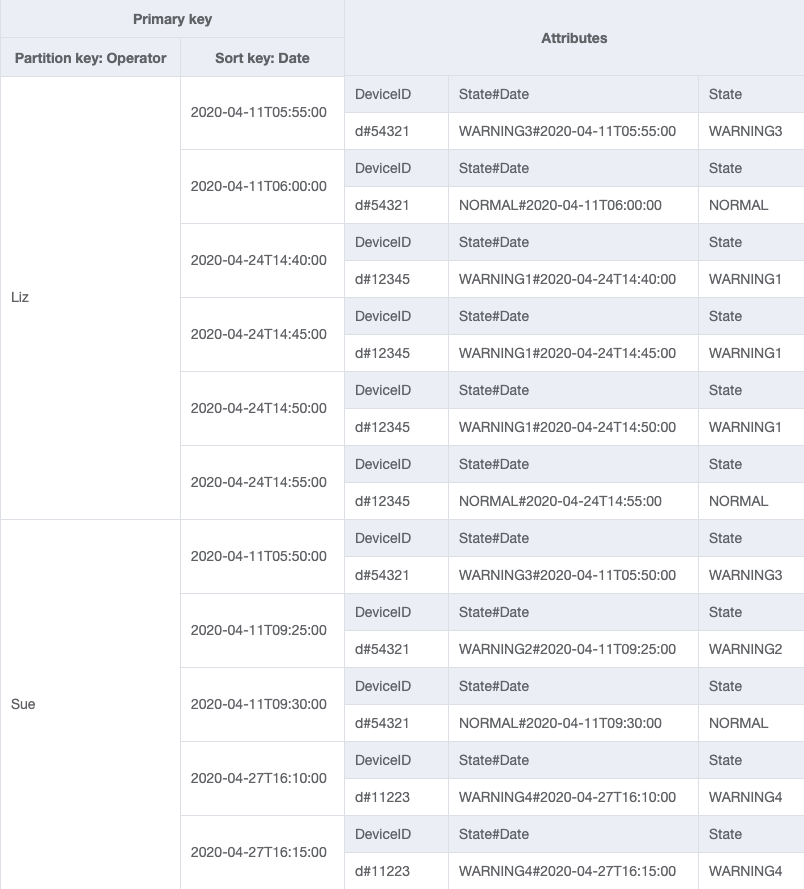
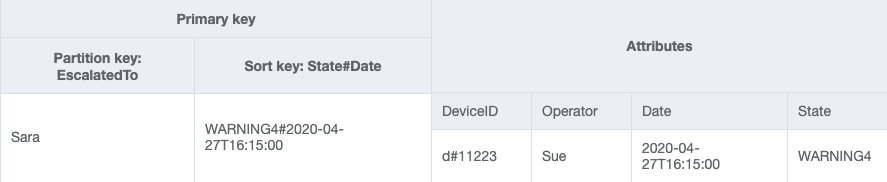
GSI-2
Utilisation de NoSQL Workbench avec cette conception de schéma
Vous pouvez importer ce schéma final dans NoSQL Workbench, un outil visuel qui fournit des fonctionnalités de modélisation des données, de visualisation des données et de développement des requêtes pour DynamoDB, afin d’explorer et de modifier davantage votre nouveau projet. Pour commencer, procédez comme suit :
-
Téléchargez NoSQL Workbench. Pour de plus amples informations, veuillez consulter Télécharger NoSQL Workbench pour DynamoDB.
-
Téléchargez le fichier de schéma JSON répertorié ci-dessus, qui est déjà au format du modèle NoSQL Workbench.
-
Importez le fichier de schéma JSON dans NoSQL Workbench. Pour de plus amples informations, veuillez consulter Importation d’un modèle de données existant.
-
Une fois que vous l’avez importé dans NoSQL Workbench, vous pouvez modifier le modèle de données. Pour de plus amples informations, veuillez consulter Modification d’un modèle de données existant.
