Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Conception de votre schéma GraphQLLe schéma GraphQL est la base de toute implémentation de serveur GraphQL. Chaque API GraphQL est définie par un schéma unique qui contient des types et des champs décrivant la manière dont les données des demandes seront renseignées. Les données qui transitent par votre API et les opérations effectuées doivent être validées par rapport au schéma.
En général, le système de type GraphQL décrit les fonctionnalités d'un serveur GraphQL et est utilisé pour déterminer si une requête est valide. Le système de types d'un serveur est souvent appelé schéma de ce serveur et peut être composé de différents types d'objets, de types scalaires, de types d'entrée, etc. GraphQL est à la fois déclaratif et fortement typé, ce qui signifie que les types seront bien définis lors de l'exécution et ne renverront que ce qui a été spécifié.
AWS AppSync vous permet de définir et de configurer des schémas GraphQL. La section suivante décrit comment créer des schémas GraphQL à partir de zéro à l'aide AWS AppSync des services.
Structuration d'un schéma GraphQL
Nous vous recommandons de consulter la section Schémas avant de continuer.
GraphQL est un outil puissant pour implémenter des services d'API. Selon le site Web de GraphQL, GraphQL est le suivant :
« GraphQL est un langage de requête APIs et un environnement d'exécution permettant de répondre à ces requêtes avec vos données existantes. GraphQL fournit une description complète et compréhensible des données de votre API, donne aux clients le pouvoir de demander exactement ce dont ils ont besoin et rien de plus, facilite l'évolution au APIs fil du temps et permet de puissants outils de développement. «
Cette section couvre la toute première partie de votre implémentation GraphQL, le schéma. À l'aide de la citation ci-dessus, un schéma joue le rôle de « fournir une description complète et compréhensible des données de votre API ». En d'autres termes, un schéma GraphQL est une représentation textuelle des données, des opérations et des relations entre les données de votre service. Le schéma est considéré comme le point d'entrée principal pour l'implémentation de votre service GraphQL. Comme on pouvait s'y attendre, c'est souvent l'une des premières choses que vous réalisez dans votre projet. Nous vous recommandons de consulter la section Schémas avant de continuer.
Pour citer la section Schémas, les schémas GraphQL sont écrits dans le langage SDL (Schema Definition Language). SDL est composé de types et de champs dotés d'une structure établie :
-
Types : Les types sont la façon dont GraphQL définit la forme et le comportement des données. GraphQL prend en charge une multitude de types qui seront expliqués plus loin dans cette section. Chaque type défini dans votre schéma contiendra sa propre portée. Le champ d'application comportera un ou plusieurs champs pouvant contenir une valeur ou une logique qui sera utilisée dans votre service GraphQL. Les types remplissent de nombreux rôles différents, les plus courants étant les objets ou les scalaires (types de valeurs primitives).
-
Champs : les champs existent dans le cadre d'un type et contiennent la valeur demandée au service GraphQL. Elles sont très similaires aux variables d'autres langages de programmation. La forme des données que vous définissez dans vos champs déterminera la manière dont les données sont structurées lors d'une request/response opération. Cela permet aux développeurs de prévoir ce qui sera renvoyé sans savoir comment le backend du service est implémenté.
Les schémas les plus simples contiendront trois catégories de données différentes :
-
Racines du schéma : les racines définissent les points d'entrée de votre schéma. Il indique les champs qui effectueront certaines opérations sur les données, telles que l'ajout, la suppression ou la modification de quelque chose.
-
Types : il s'agit de types de base utilisés pour représenter la forme des données. Vous pouvez presque les considérer comme des objets ou des représentations abstraites de quelque chose avec des caractéristiques définies. Par exemple, vous pouvez créer un Person objet représentant une personne dans une base de données. Les caractéristiques de chaque personne seront définies dans les champs Person as. Ils peuvent être n'importe quoi comme le nom, l'âge, le travail, l'adresse de la personne, etc.
-
Types d'objets spéciaux : ce sont les types qui définissent le comportement des opérations dans votre schéma. Chaque type d'objet spécial est défini une fois par schéma. Ils sont d'abord placés dans la racine du schéma, puis définis dans le corps du schéma. Chaque champ d'un type d'objet spécial définit une opération unique à implémenter par votre résolveur.
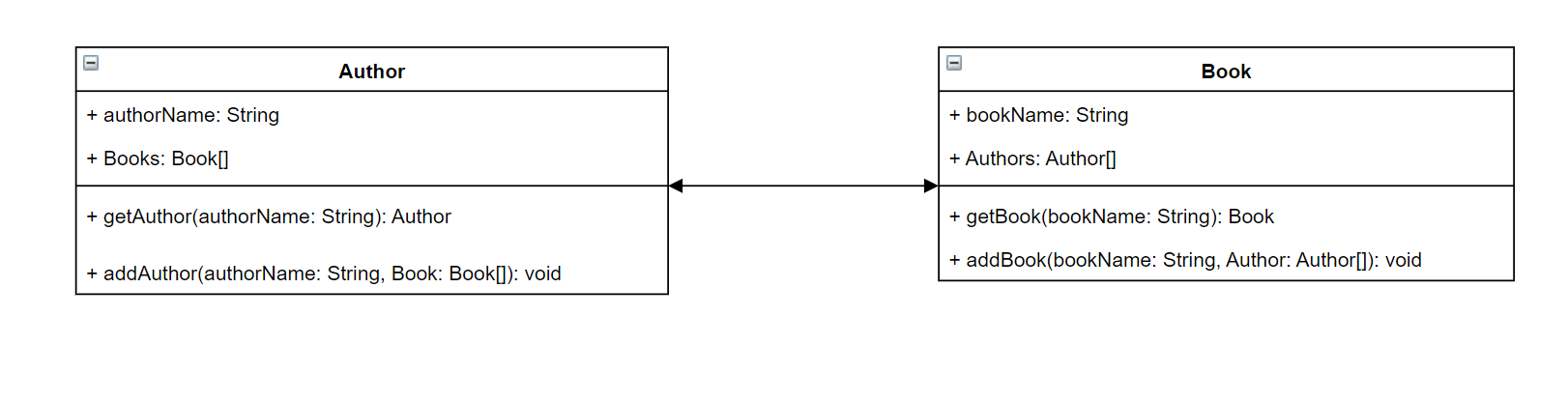
Pour mettre les choses en perspective, imaginez que vous créez un service qui stocke les auteurs et les livres qu'ils ont écrits. Chaque auteur a un nom et une liste de livres qu'il a écrits. Chaque livre a un nom et une liste d'auteurs associés. Nous voulons également pouvoir ajouter ou récupérer des livres et des auteurs. Une représentation UML simple de cette relation peut ressembler à ceci :
Dans GraphQL, les entités Author et B Book représentent deux types d'objets différents dans votre schéma :
type Author {
}
type Book {
}
Authorcontient authorName etBooks, tandis que Book contient bookName etAuthors. Ceux-ci peuvent être représentés sous la forme de champs correspondant à vos types :
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
Comme vous pouvez le constater, les représentations de type sont très proches du diagramme. Cependant, c'est dans les méthodes que cela devient un peu plus délicat. Ils seront placés dans l'un des rares types d'objets spéciaux sous forme de champ. La catégorisation des objets spéciaux dépend de leur comportement. GraphQL contient trois types d'objets spéciaux fondamentaux : les requêtes, les mutations et les abonnements. Pour plus d'informations, consultez la section Objets spéciaux.
Parce que getAuthor getBook les deux demandent des données, elles seront placées dans un type d'objet Query spécial :
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
Les opérations sont liées à la requête, elle-même liée au schéma. L'ajout d'une racine de schéma définira le type d'objet spécial (Querydans ce cas) comme l'un de vos points d'entrée. Cela peut être fait en utilisant le schema mot clé :
schema {
query: Query
}
type Author {
authorName: String
Books: [Book]
}
type Book {
bookName: String
Authors: [Author]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
Examinez les deux dernières méthodes addAuthor et ajoutez addBook des données à votre base de données, afin qu'elles soient définies dans un type d'objet Mutation spécial. Cependant, depuis la page Types, nous savons également que les entrées faisant directement référence à des objets ne sont pas autorisées car il s'agit uniquement de types de sortie. Dans ce cas, nous ne pouvons pas utiliser Author ouBook, nous devons donc créer un type de saisie avec les mêmes champs. Dans cet exemple, nous avons ajouté AuthorInput etBookInput, qui acceptent tous deux les mêmes champs de leurs types respectifs. Ensuite, nous créons notre mutation en utilisant les entrées comme paramètres :
schema {
query: Query
mutation: Mutation
}
type Author {
authorName: String
Books: [Book]
}
input AuthorInput {
authorName: String
Books: [BookInput]
}
type Book {
bookName: String
Authors: [Author]
}
input BookInput {
bookName: String
Authors: [AuthorInput]
}
type Query {
getAuthor(authorName: String): Author
getBook(bookName: String): Book
}
type Mutation {
addAuthor(input: [BookInput]): Author
addBook(input: [AuthorInput]): Book
}
Passons en revue ce que nous venons de faire :
-
Nous avons créé un schéma avec les Author types Book et pour représenter nos entités.
-
Nous avons ajouté les champs contenant les caractéristiques de nos entités.
-
Nous avons ajouté une requête pour récupérer ces informations dans la base de données.
-
Nous avons ajouté une mutation pour manipuler les données de la base de données.
-
Nous avons ajouté des types d'entrée pour remplacer les paramètres de nos objets dans la mutation afin de respecter les règles de GraphQL.
-
Nous avons ajouté la requête et la mutation à notre schéma racine afin que l'implémentation GraphQL comprenne l'emplacement du type de racine.
Comme vous pouvez le constater, le processus de création d'un schéma repose sur de nombreux concepts issus de la modélisation des données (en particulier de la modélisation de base de données) en général. Vous pouvez considérer le schéma comme s'adaptant à la forme des données provenant de la source. Il sert également de modèle que le résolveur implémentera. Dans les sections suivantes, vous allez apprendre à créer un schéma à l'aide de divers outils et services AWS basés sur des outils.
Les exemples présentés dans les sections suivantes ne sont pas destinés à être exécutés dans une application réelle. Ils ne sont là que pour présenter les commandes afin que vous puissiez créer vos propres applications.
Création de schémas
Votre schéma se trouvera dans un fichier appeléschema.graphql. AWS AppSync permet aux utilisateurs de créer de nouveaux schémas pour leur APIs GraphQL en utilisant différentes méthodes. Dans cet exemple, nous allons créer une API vide avec un schéma vide.
- Console
-
-
Connectez-vous à la AppSyncconsole Console de gestion AWS et ouvrez-la.
-
Dans le Tableau de bord, choisissez Créer une API.
-
Dans les options de l'API, choisissez GraphQL APIs, Design from scratch, puis Next.
-
Pour le nom de l'API, modifiez le nom prérempli en fonction des besoins de votre application.
-
Pour les coordonnées, vous pouvez saisir un point de contact afin d'identifier un responsable de l'API. Il s'agit d'un champ facultatif.
-
Dans Configuration de l'API privée, vous pouvez activer les fonctionnalités de l'API privée. Une API privée n'est accessible qu'à partir d'un point de terminaison VPC configuré (VPCE). Pour plus d'informations, voir Privé APIs.
Nous ne recommandons pas d'activer cette fonctionnalité pour cet exemple. Choisissez Next après avoir examiné vos entrées.
-
Sous Créer un type GraphQL, vous pouvez choisir de créer une table DynamoDB à utiliser comme source de données ou de l'ignorer et de le faire plus tard.
Pour cet exemple, choisissez Create GraphQL resources later. Nous allons créer une ressource dans une section séparée.
-
Passez en revue vos entrées, puis choisissez Create API.
-
Vous serez dans le tableau de bord de votre API spécifique. Vous pouvez le savoir, car le nom de l'API figurera en haut du tableau de bord. Si ce n'est pas le cas, vous pouvez sélectionner APIsdans la barre latérale, puis choisir votre API dans le APIs tableau de bord.
-
Dans la barre latérale située sous le nom de votre API, choisissez Schema.
-
Dans l'éditeur de schéma, vous pouvez configurer votre schema.graphql fichier. Il peut être vide ou rempli de types générés à partir d'un modèle. Sur la droite, vous avez la section Résolveurs pour associer des résolveurs aux champs de votre schéma. Nous n'examinerons pas les résolveurs dans cette section.
- CLI
-
Lorsque vous utilisez la CLI, assurez-vous de disposer des autorisations appropriées pour accéder au service et en créer des ressources. Vous souhaiterez peut-être définir des politiques de moindre privilège pour les utilisateurs non administrateurs qui ont besoin d'accéder au service. Pour plus d'informations sur AWS AppSync les politiques, consultez la section Gestion des identités et des accès pour AWS AppSync.
En outre, nous vous recommandons de lire d'abord la version console si ce n'est pas déjà fait.
-
Si ce n'est pas déjà fait, installez la AWS
CLI, puis ajoutez votre configuration.
-
Créez un objet d'API GraphQL en exécutant la create-graphql-apicommande.
Vous devez saisir deux paramètres pour cette commande en particulier :
-
Celui name de votre API.
-
Le ou authentication-type le type d'informations d'identification utilisées pour accéder à l'API (IAM, OIDC, etc.).
D'autres paramètres, tels que ceux qui Region doivent être configurés, sont généralement définis par défaut sur les valeurs de configuration de votre CLI.
Voici un exemple de commande :
aws appsync create-graphql-api --name testAPI123 --authentication-type API_KEY
Une sortie sera renvoyée dans la CLI. Voici un exemple :
{
"graphqlApi": {
"xrayEnabled": false,
"name": "testAPI123",
"authenticationType": "API_KEY",
"tags": {},
"apiId": "abcdefghijklmnopqrstuvwxyz",
"uris": {
"GRAPHQL": "https://zyxwvutsrqponmlkjihgfedcba.appsync-api.us-west-2.amazonaws.com/graphql",
"REALTIME": "wss://zyxwvutsrqponmlkjihgfedcba.appsync-realtime-api.us-west-2.amazonaws.com/graphql"
},
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz"
}
}
-
Il s'agit d'une commande facultative qui prend un schéma existant et le télécharge vers le AWS AppSync service à l'aide d'un blob en base 64. Nous n'utiliserons pas cette commande pour les besoins de cet exemple.
Exécutez la commande start-schema-creation.
Vous devez saisir deux paramètres pour cette commande en particulier :
-
C'est ce que vous api-id avez fait à l'étape précédente.
-
Le schéma definition est un blob binaire codé en base 64.
Voici un exemple de commande :
aws appsync start-schema-creation --api-id abcdefghijklmnopqrstuvwxyz --definition "aa1111aa-123b-2bb2-c321-12hgg76cc33v"
Une sortie sera renvoyée :
{
"status": "PROCESSING"
}
Cette commande ne renverra pas le résultat final après le traitement. Vous devez utiliser une commande séparée pour voir le résultat. get-schema-creation-status Notez que ces deux commandes sont asynchrones. Vous pouvez donc vérifier l'état de sortie même lorsque le schéma est encore en cours de création.
- CDK
-
Avant d'utiliser le CDK, nous vous recommandons de consulter la documentation officielle du CDK ainsi que la référence AWS AppSync du CDK.
Les étapes répertoriées ci-dessous ne montreront qu'un exemple général de l'extrait utilisé pour ajouter une ressource particulière. Cela n'est pas censé être une solution fonctionnelle dans votre code de production. Nous partons également du principe que vous disposez déjà d'une application fonctionnelle.
-
Le point de départ du CDK est un peu différent. Idéalement, votre schema.graphql fichier devrait déjà être créé. Il vous suffit de créer un nouveau fichier avec l'extension de .graphql fichier. Il peut s'agir d'un fichier vide.
-
En général, vous devrez peut-être ajouter la directive d'importation au service que vous utilisez. Par exemple, il peut suivre les formes suivantes :
import * as x from 'x'; # import wildcard as the 'x' keyword from 'x-service'
import {a, b, ...} from 'c'; # import {specific constructs} from 'c-service'
Pour ajouter une API GraphQL, votre fichier de pile doit importer le AWS AppSync service :
import * as appsync from 'aws-cdk-lib/aws-appsync';
Cela signifie que nous importons l'intégralité du service sous le appsync mot clé. Pour l'utiliser dans votre application, vos AWS AppSync constructions utiliseront le formatappsync.construct_name. Par exemple, si nous voulions créer une API GraphQL, nous dirions. new appsync.GraphqlApi(args_go_here) L'étape suivante illustre cela.
-
L'API GraphQL la plus basique inclura un name pour l'API et le schema chemin.
const add_api = new appsync.GraphqlApi(this, 'API_ID', {
name: 'name_of_API_in_console',
schema: appsync.SchemaFile.fromAsset(path.join(__dirname, 'schema_name.graphql')),
});
Voyons ce que fait cet extrait. Dans le cadre deapi, nous créons une nouvelle API GraphQL en appelant. appsync.GraphqlApi(scope: Construct, id:
string, props: GraphqlApiProps) La portée estthis, qui fait référence à l'objet actuel. L'identifiant estAPI_ID, qui sera le nom de la ressource de votre API GraphQL CloudFormation lors de sa création. Le GraphqlApiProps name contient votre API GraphQL et le. schema Le schema va générer un schéma (SchemaFile.fromAsset) en recherchant le chemin absolu (__dirname) du .graphql fichier (schema_name.graphql). Dans un scénario réel, votre fichier de schéma se trouvera probablement dans l'application CDK.
Pour utiliser les modifications apportées à votre API GraphQL, vous devez redéployer l'application.
Ajouter des types aux schémas
Maintenant que vous avez ajouté votre schéma, vous pouvez commencer à ajouter vos types d'entrée et de sortie. Notez que les types présentés ici ne doivent pas être utilisés dans le code réel ; ce ne sont que des exemples destinés à vous aider à comprendre le processus.
Nous allons d'abord créer un type d'objet. Dans le code réel, il n'est pas nécessaire de commencer par ces types. Vous pouvez créer le type que vous voulez à tout moment, à condition de respecter les règles et la syntaxe de GraphQL.
Les prochaines sections utiliseront l'éditeur de schéma, alors gardez-le ouvert.
- Console
-
-
Vous pouvez créer un type d'objet en utilisant le type mot-clé associé au nom du type :
type Type_Name_Goes_Here {}
Dans le champ d'application du type, vous pouvez ajouter des champs qui représentent les caractéristiques de l'objet :
type Type_Name_Goes_Here {
# Add fields here
}
Voici un exemple :
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Dans cette étape, nous avons ajouté un type d'objet générique avec un id champ obligatoire stocké sous formeID, un title champ stocké sous forme de et un date champ stocké sous forme deAWSDateTime. String Pour consulter la liste des types et des champs et leur fonction, reportez-vous à la section Schémas. Pour voir la liste des scalaires et leur fonction, consultez la référence Type.
- CLI
-
Nous vous recommandons de lire d'abord la version console si ce n'est pas déjà fait.
-
Vous pouvez créer un type d'objet en exécutant la create-typecommande.
Vous devez entrer quelques paramètres pour cette commande en particulier :
-
Celui api-id de votre API.
-
Ledefinition, ou le contenu de votre type. Dans l'exemple de console, c'était :
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
-
Celui format de votre contribution. Dans cet exemple, nous utilisonsSDL.
Voici un exemple de commande :
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Obj_Type_1{id: ID! title: String date: AWSDateTime}" --format SDL
Une sortie sera renvoyée dans la CLI. Voici un exemple :
{
"type": {
"definition": "type Obj_Type_1{id: ID! title: String date: AWSDateTime}",
"name": "Obj_Type_1",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Obj_Type_1",
"format": "SDL"
}
}
Dans cette étape, nous avons ajouté un type d'objet générique avec un id champ obligatoire stocké sous formeID, un title champ stocké sous forme de et un date champ stocké sous forme deAWSDateTime. String Pour consulter la liste des types et des champs et leur fonction, reportez-vous à la section Schémas. Pour consulter la liste des scalaires et leur fonction, reportez-vous à la section Référence des types.
Par ailleurs, vous vous êtes peut-être rendu compte que la saisie de la définition fonctionne directement pour les types plus petits, mais qu'elle est impossible pour l'ajout de types plus grands ou multiples. Vous pouvez choisir de tout ajouter dans un .graphql fichier, puis de le transmettre en entrée.
- CDK
-
Avant d'utiliser le CDK, nous vous recommandons de consulter la documentation officielle du CDK ainsi que la référence AWS AppSync du CDK.
Les étapes répertoriées ci-dessous ne montreront qu'un exemple général de l'extrait utilisé pour ajouter une ressource particulière. Cela n'est pas censé être une solution fonctionnelle dans votre code de production. Nous partons également du principe que vous disposez déjà d'une application fonctionnelle.
Pour ajouter un type, vous devez l'ajouter à votre .graphql fichier. Par exemple, l'exemple de console était le suivant :
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Vous pouvez ajouter vos types directement au schéma comme dans n'importe quel autre fichier.
Pour utiliser les modifications apportées à votre API GraphQL, vous devez redéployer l'application.
Le type d'objet contient des champs de type scalaire tels que des chaînes et des entiers. AWS AppSync vous permet également d'utiliser des types scalaires améliorés, AWSDateTime en plus des scalaires GraphQL de base. En outre, tout champ se terminant par un point d'exclamation est obligatoire.
Le type ID scalaire en particulier est un identifiant unique qui peut être String soitInt. Vous pouvez les contrôler dans le code de votre résolveur pour une attribution automatique.
Il existe des similitudes entre les types d'objets spéciaux Query et les types d'objets « ordinaires », comme dans l'exemple ci-dessus, en ce sens qu'ils utilisent tous deux le type mot-clé et sont considérés comme des objets. Cependant, pour les types d'objets spéciaux (Query,Mutation, etSubscription), leur comportement est très différent car ils sont exposés en tant que points d'entrée de votre API. Ils visent également à façonner les opérations plutôt que les données. Pour plus d'informations, consultez la section Les types de requête et de mutation.
En ce qui concerne les types d'objets spéciaux, l'étape suivante pourrait consister à en ajouter un ou plusieurs pour effectuer des opérations sur les données mises en forme. Dans un scénario réel, chaque schéma GraphQL doit au moins avoir un type de requête racine pour demander des données. Vous pouvez considérer la requête comme l'un des points d'entrée (ou points de terminaison) de votre serveur GraphQL. Ajoutons une requête à titre d'exemple.
- Console
-
-
Pour créer une requête, vous pouvez simplement l'ajouter au fichier de schéma comme n'importe quel autre type. Une requête nécessiterait un Query type et une entrée à la racine comme ceci :
schema {
query: Name_of_Query
}
type Name_of_Query {
# Add field operation here
}
Notez que Name_of_Query dans un environnement de production, il sera simplement appelé Query dans la plupart des cas. Nous vous recommandons de le maintenir à cette valeur. Dans le type de requête, vous pouvez ajouter des champs. Chaque champ effectuera une opération dans la demande. Par conséquent, la plupart de ces champs, sinon tous, seront attachés à un résolveur. Cependant, cela ne nous intéresse pas dans cette section. En ce qui concerne le format de l'opération sur le terrain, cela pourrait ressembler à ceci :
Name_of_Query(params): Return_Type # version with params
Name_of_Query: Return_Type # version without params
Voici un exemple :
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Dans cette étape, nous avons ajouté un Query type et l'avons défini dans notre schema racine. Notre Query type a défini un getObj champ qui renvoie une liste d'Obj_Type_1objets. Notez que Obj_Type_1 c'est l'objet de l'étape précédente. Dans le code de production, vos opérations sur le terrain travailleront normalement avec des données façonnées par des objets tels queObj_Type_1. De plus, les champs de getObj ce type auront normalement un résolveur pour exécuter la logique métier. Cela sera traité dans une autre section.
En outre, ajoute AWS AppSync automatiquement une racine de schéma lors des exportations. Techniquement, vous n'avez donc pas besoin de l'ajouter directement au schéma. Notre service traitera automatiquement les schémas dupliqués. Nous l'ajoutons ici en tant que meilleure pratique.
- CLI
-
Nous vous recommandons de lire d'abord la version console si ce n'est pas déjà fait.
-
Créez une schema racine avec une query définition en exécutant la create-typecommande.
Vous devez entrer quelques paramètres pour cette commande en particulier :
-
Celui api-id de votre API.
-
Ledefinition, ou le contenu de votre type. Dans l'exemple de console, c'était :
schema {
query: Query
}
-
Celui format de votre contribution. Dans cet exemple, nous utilisonsSDL.
Voici un exemple de commande :
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "schema {query: Query}" --format SDL
Une sortie sera renvoyée dans la CLI. Voici un exemple :
{
"type": {
"definition": "schema {query: Query}",
"name": "schema",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
Notez que si vous n'avez pas saisi quelque chose correctement dans la create-type commande, vous pouvez mettre à jour la racine de votre schéma (ou n'importe quel type du schéma) en exécutant la update-typecommande. Dans cet exemple, nous allons modifier temporairement la racine du schéma pour qu'elle contienne une subscription définition.
Vous devez entrer quelques paramètres pour cette commande en particulier :
-
Celui api-id de votre API.
-
Celui type-name de ton genre. Dans l'exemple de console, c'était le casschema.
-
Ledefinition, ou le contenu de votre type. Dans l'exemple de console, c'était :
schema {
query: Query
}
Le schéma après avoir ajouté un subscription ressemblera à ceci :
schema {
query: Query
subscription: Subscription
}
-
Celui format de votre contribution. Dans cet exemple, nous utilisonsSDL.
Voici un exemple de commande :
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query subscription: Subscription}" --format SDL
Une sortie sera renvoyée dans la CLI. Voici un exemple :
{
"type": {
"definition": "schema {query: Query subscription: Subscription}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
L'ajout de fichiers préformatés fonctionnera toujours dans cet exemple.
-
Créez un Query type en exécutant la create-typecommande.
Vous devez entrer quelques paramètres pour cette commande en particulier :
-
Celui api-id de votre API.
-
Ledefinition, ou le contenu de votre type. Dans l'exemple de console, c'était :
type Query {
getObj: [Obj_Type_1]
}
-
Celui format de votre contribution. Dans cet exemple, nous utilisonsSDL.
Voici un exemple de commande :
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Query {getObj: [Obj_Type_1]}" --format SDL
Une sortie sera renvoyée dans la CLI. Voici un exemple :
{
"type": {
"definition": "Query {getObj: [Obj_Type_1]}",
"name": "Query",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Query",
"format": "SDL"
}
}
Au cours de cette étape, nous avons ajouté un Query type et l'avons défini dans votre schema racine. Notre Query type définissait un getObj champ qui renvoyait une liste d'Obj_Type_1objets.
Dans le code schema racinequery: Query, la query: partie indique qu'une requête a été définie dans votre schéma, tandis que la Query partie indique le nom réel de l'objet spécial.
- CDK
-
Avant d'utiliser le CDK, nous vous recommandons de consulter la documentation officielle du CDK ainsi que la référence AWS AppSync du CDK.
Les étapes répertoriées ci-dessous ne montreront qu'un exemple général de l'extrait utilisé pour ajouter une ressource particulière. Cela n'est pas censé être une solution fonctionnelle dans votre code de production. Nous partons également du principe que vous disposez déjà d'une application fonctionnelle.
Vous devez ajouter votre requête et la racine du schéma au .graphql fichier. Notre exemple ressemble à celui ci-dessous, mais vous devez le remplacer par votre code de schéma actuel :
schema {
query: Query
}
type Query {
getObj: [Obj_Type_1]
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
Vous pouvez ajouter vos types directement au schéma comme dans n'importe quel autre fichier.
La mise à jour de la racine du schéma est facultative. Nous l'avons ajoutée à cet exemple en tant que meilleure pratique.
Pour utiliser les modifications apportées à votre API GraphQL, vous devez redéployer l'application.
Vous avez maintenant vu un exemple de création d'objets et d'objets spéciaux (requêtes). Vous avez également vu comment ils peuvent être interconnectés pour décrire les données et les opérations. Vous pouvez avoir des schémas contenant uniquement la description des données et une ou plusieurs requêtes. Cependant, nous aimerions ajouter une autre opération pour ajouter des données à la source de données. Nous allons ajouter un autre type d'objet spécial appelé Mutation qui modifie les données.
- Console
-
-
Une mutation sera appeléeMutation. Par exempleQuery, les opérations de terrain qu'Mutationil contient décriront une opération et seront associées à un résolveur. Notez également que nous devons le définir à la schema racine car il s'agit d'un type d'objet spécial. Voici un exemple de mutation :
schema {
mutation: Name_of_Mutation
}
type Name_of_Mutation {
# Add field operation here
}
Une mutation typique sera répertoriée à la racine comme une requête. La mutation est définie à l'aide du type mot clé associé au nom. Name_of_Mutationsera généralement appeléMutation, nous vous recommandons donc de continuer ainsi. Chaque champ effectuera également une opération. En ce qui concerne le format de l'opération sur le terrain, cela pourrait ressembler à ceci :
Name_of_Mutation(params): Return_Type # version with params
Name_of_Mutation: Return_Type # version without params
Voici un exemple :
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
Dans cette étape, nous avons ajouté un Mutation type avec un addObj champ. Résumons le rôle de ce champ :
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
addObjutilise l'Obj_Type_1objet pour effectuer une opération. Cela est évident en raison des champs, mais la syntaxe le prouve dans le type de : Obj_Type_1 retour. À l'intérieuraddObj, il accepte les date champsid,title, et de l'Obj_Type_1objet en tant que paramètres. Comme vous pouvez le constater, cela ressemble beaucoup à une déclaration de méthode. Cependant, nous n'avons pas encore décrit le comportement de notre méthode. Comme indiqué précédemment, le schéma est uniquement là pour définir quelles seront les données et les opérations, et non leur mode de fonctionnement. La mise en œuvre de la véritable logique métier interviendra plus tard lorsque nous créerons nos premiers résolveurs.
Une fois que vous avez terminé avec votre schéma, il est possible de l'exporter sous forme de schema.graphql fichier. Dans l'éditeur de schéma, vous pouvez choisir Exporter le schéma pour télécharger le fichier dans un format pris en charge.
En outre, ajoute AWS AppSync automatiquement une racine de schéma lors des exportations. Techniquement, vous n'avez donc pas besoin de l'ajouter directement au schéma. Notre service traitera automatiquement les schémas dupliqués. Nous l'ajoutons ici en tant que meilleure pratique.
- CLI
-
Nous vous recommandons de lire d'abord la version console si ce n'est pas déjà fait.
-
Mettez à jour votre schéma racine en exécutant la update-typecommande.
Vous devez entrer quelques paramètres pour cette commande en particulier :
-
Celui api-id de votre API.
-
Celui type-name de ton genre. Dans l'exemple de console, c'était le casschema.
-
Ledefinition, ou le contenu de votre type. Dans l'exemple de console, c'était :
schema {
query: Query
mutation: Mutation
}
-
Celui format de votre contribution. Dans cet exemple, nous utilisonsSDL.
Voici un exemple de commande :
aws appsync update-type --api-id abcdefghijklmnopqrstuvwxyz --type-name schema --definition "schema {query: Query mutation: Mutation}" --format SDL
Une sortie sera renvoyée dans la CLI. Voici un exemple :
{
"type": {
"definition": "schema {query: Query mutation: Mutation}",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/schema",
"format": "SDL"
}
}
-
Créez un Mutation type en exécutant la create-typecommande.
Vous devez entrer quelques paramètres pour cette commande en particulier :
-
Celui api-id de votre API.
-
Ledefinition, ou le contenu de votre type. Dans l'exemple de console, c'était
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
-
Celui format de votre contribution. Dans cet exemple, nous utilisonsSDL.
Voici un exemple de commande :
aws appsync create-type --api-id abcdefghijklmnopqrstuvwxyz --definition "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}" --format SDL
Une sortie sera renvoyée dans la CLI. Voici un exemple :
{
"type": {
"definition": "type Mutation {addObj(id: ID! title: String date: AWSDateTime): Obj_Type_1}",
"name": "Mutation",
"arn": "arn:aws:appsync:us-west-2:107289374856:apis/abcdefghijklmnopqrstuvwxyz/types/Mutation",
"format": "SDL"
}
}
- CDK
-
Avant d'utiliser le CDK, nous vous recommandons de consulter la documentation officielle du CDK ainsi que la référence AWS AppSync du CDK.
Les étapes répertoriées ci-dessous ne montreront qu'un exemple général de l'extrait utilisé pour ajouter une ressource particulière. Cela n'est pas censé être une solution fonctionnelle dans votre code de production. Nous partons également du principe que vous disposez déjà d'une application fonctionnelle.
Vous devez ajouter votre requête et la racine du schéma au .graphql fichier. Notre exemple ressemble à celui ci-dessous, mais vous devez le remplacer par votre code de schéma actuel :
schema {
query: Query
mutation: Mutation
}
type Obj_Type_1 {
id: ID!
title: String
date: AWSDateTime
}
type Query {
getObj: [Obj_Type_1]
}
type Mutation {
addObj(id: ID!, title: String, date: AWSDateTime): Obj_Type_1
}
La mise à jour de la racine du schéma est facultative. Nous l'avons ajoutée à cet exemple en tant que meilleure pratique.
Pour utiliser les modifications apportées à votre API GraphQL, vous devez redéployer l'application.
Considérations facultatives - Utilisation des énumérations comme statuts
À ce stade, vous savez comment créer un schéma de base. Cependant, vous pouvez ajouter de nombreux éléments pour améliorer les fonctionnalités du schéma. Une chose courante dans les applications est l'utilisation d'énumérations comme statuts. Vous pouvez utiliser une énumération pour forcer le choix d'une valeur spécifique d'un ensemble de valeurs lors de l'appel. C'est bon pour des choses dont vous savez qu'elles ne changeront pas radicalement sur de longues périodes. Hypothétiquement parlant, nous pourrions ajouter une énumération qui renvoie le code d'état ou une chaîne dans la réponse.
Par exemple, supposons que nous créons une application de réseau social qui stocke les données de publication d'un utilisateur dans le backend. Notre schéma contient un Post type qui représente les données d'une publication individuelle :
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
Notre message Post title contiendra une publication unique id et une énumération appelée PostStatus qui représente l'état de la publication telle qu'elle est traitée par l'application. date Pour nos opérations, nous aurons une requête qui renverra toutes les données de publication :
type Query {
getPosts: [Post]
}
Nous aurons également une mutation qui ajoutera des publications à la source de données :
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
En regardant notre schéma, l'PostStatusénumération peut avoir plusieurs statuts. Nous souhaiterons peut-être que les trois états de base soient appelés success (post traité avec succès), pending (post en cours de traitement) et error (post incapable d'être traité). Pour ajouter l'énumération, nous pourrions faire ceci :
enum PostStatus {
success
pending
error
}
Le schéma complet pourrait ressembler à ceci :
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts: [Post]
}
enum PostStatus {
success
pending
error
}
Si un utilisateur ajoute un Post dans l'application, l'addPostopération sera appelée pour traiter ces données. Au fur et à mesure que le résolveur attaché addPost traite les données, il les met continuellement à jour en poststatus fonction de l'état de l'opération. Lorsqu'il est demandé, le Post testament contiendra le statut final des données. N'oubliez pas que nous ne décrivons que la manière dont nous voulons que les données fonctionnent dans le schéma. Nous avons beaucoup d'hypothèses quant à la mise en œuvre de nos résolveurs, qui mettront en œuvre la logique métier réelle pour traiter les données afin de répondre à la demande.
Considérations facultatives - Abonnements
Les abonnements AWS AppSync sont invoqués en réponse à une mutation. Vous configurez cela avec un type Subscription et une directive @aws_subscribe() du schéma pour signifier quelles mutations appellent un ou plusieurs abonnements. Pour plus d'informations sur la configuration des abonnements, consultez la section Données en temps réel.
Considérations facultatives - Relations et pagination
Supposons qu'un million soit Posts stocké dans une table DynamoDB et que vous souhaitiez renvoyer certaines de ces données. Cependant, l'exemple de requête donné ci-dessus ne renvoie que tous les messages. Vous ne voudriez pas les récupérer tous à chaque fois que vous faites une demande. Au lieu de cela, vous devriez les paginer. Apportez les modifications suivantes à votre schéma :
-
Dans le getPosts champ, ajoutez deux arguments d'entrée : nextToken (itérateur) et limit (limite d'itération).
-
Ajoutez un nouveau PostIterator type contenant Posts (récupère la liste des Post objets) et des champs nextToken (itérateur).
-
getPostsModifiez-le pour qu'il renvoie PostIterator et non une liste d'Postobjets.
schema {
query: Query
mutation: Mutation
}
type Post {
id: ID!
title: String
date: AWSDateTime
poststatus: PostStatus
}
type Mutation {
addPost(id: ID!, title: String, date: AWSDateTime, poststatus: PostStatus): Post
}
type Query {
getPosts(limit: Int, nextToken: String): PostIterator
}
enum PostStatus {
success
pending
error
}
type PostIterator {
posts: [Post]
nextToken: String
}
Le PostIterator type vous permet de renvoyer une partie de la liste des Post objets et un nextToken pour obtenir la partie suivante. À l'intérieurPostIterator, il y a une liste d'Postitems ([Post]) qui est renvoyée avec un jeton de pagination (nextToken). En AWS AppSync, il serait connecté à Amazon DynamoDB via un résolveur et généré automatiquement sous forme de jeton chiffré. Cela convertir la valeur de l'argument limit en paramètre maxResults et l'argument nextToken en paramètre exclusiveStartKey. Pour des exemples et des exemples de modèles intégrés dans la AWS AppSync console, voir Resolver reference (JavaScript).