Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Connecteur Amazon Athena Apache Kafka
Le connecteur Amazon Athena pour Apache Kafka permet à Amazon Athena d'exécuter des SQL requêtes sur vos sujets Apache Kafka. Utilisez ce connecteur pour afficher les rubriques Apache Kafka
Prérequis
Déployez le connecteur sur votre Compte AWS à l’aide de la console Athena ou du AWS Serverless Application Repository. Pour plus d’informations, consultez Déployer un connecteur de source de données ou Utilisez le AWS Serverless Application Repository pour déployer un connecteur de source de données.
Limites
-
Les DDL opérations d'écriture ne sont pas prises en charge.
-
Toutes les limites Lambda pertinentes. Pour plus d’informations, consultez la section Quotas Lambda du Guide du développeur AWS Lambda .
-
Les types de données de date et d’horodatage dans des conditions de filtre doivent être convertis en types de données appropriés.
-
Les types de données de date et d'horodatage ne sont pas pris en charge pour le type de CSV fichier et sont traités comme des valeurs varchar.
-
Le mappage dans des JSON champs imbriqués n'est pas pris en charge. Le connecteur ne mappe que les champs de niveau supérieur.
-
Le connecteur ne prend pas en charge les types complexes. Les types complexes sont interprétés comme des chaînes.
-
Pour extraire ou utiliser des JSON valeurs complexes, utilisez les fonctions JSON associées disponibles dans Athena. Pour plus d’informations, consultez Extraire JSON des données à partir de chaînes.
-
Le connecteur ne prend pas en charge l’accès aux métadonnées des messages Kafka.
Conditions
-
Gestionnaire de métadonnées – Un gestionnaire Lambda qui extrait les métadonnées de votre instance de base de données.
-
Gestionnaire d’enregistrements – Un gestionnaire Lambda qui extrait les enregistrements de données de votre instance de base de données.
-
Gestionnaire de composites – Un gestionnaire Lambda qui extrait les métadonnées et les enregistrements de données de votre instance de base de données.
-
Point de terminaison Kafka – Chaîne de texte qui établit une connexion à une instance Kafka.
Compatibilité des clusters
Le connecteur Kafka peut être utilisé avec les types de clusters suivants.
-
Kafka autonome – Connexion directe à Kafka (authentifiée ou non).
-
Confluent – Une connexion directe à Confluent Kafka. Pour plus d'informations sur l'utilisation d'Athena avec les données Confluent Kafka, consultez Visualiser les données Confluent sur Amazon à l'aide d' QuickSight Amazon Athena sur le blog Business
Intelligence.AWS
Connexion à Confluent
La connexion à Confluent nécessite les étapes suivantes :
-
Générez une API clé à partir de Confluent.
-
Enregistrez le nom d'utilisateur et le mot de passe de la API clé Confluent dans. AWS Secrets Manager
-
Indiquer le nom secret de la variable d'environnement
secrets_manager_secretdans le connecteur Kafka. -
Suivez les étapes décrites dans la section Configuration du connecteur Kafka de ce document.
Méthodes d'authentification prises en charge
Le connecteur prend en charge les méthodes d'authentification suivantes.
-
SASL/PLAIN
-
SASL/PLAINTEXT
-
NON_ AUTH
-
Plate-forme Kafka et Confluent autogérée —SSL,SASL/,/SCRAM, NO_ SASL PLAINTEXT AUTH
-
Kafka et Confluent Cloud autogérés —/SASLPLAIN
Pour plus d’informations, consultez Configuration de l'authentification pour le connecteur Athena Kafka.
Formats de données d'entrée pris en charge
Le connecteur prend en charge les formats de données d'entrée suivants.
-
JSON
-
CSV
-
AVRO
-
PROTOBUF (PROTOCOL BUFFERS)
Paramètres
Utilisez les variables d'environnement Lambda mentionnées dans cette rubrique pour configurer le connecteur Kafka d'Athena.
-
auth_type – Spécifie le type d'authentification du cluster. Le connecteur prend en charge les types d'authentification suivants :
-
NO_ AUTH — Connectez-vous directement à Kafka (par exemple, à un cluster Kafka déployé sur une EC2 instance qui n'utilise pas l'authentification).
-
SASL_ SSL _ PLAIN — Cette méthode utilise le protocole
SASL_SSLde sécurité et lePLAINSASL mécanisme. Pour plus d'informations, consultez SASLla section configurationdans la documentation d'Apache Kafka. -
SASL_ PLAINTEXT _ PLAIN — Cette méthode utilise le protocole
SASL_PLAINTEXTde sécurité et lePLAINSASL mécanisme. Pour plus d'informations, consultez SASLla section configurationdans la documentation d'Apache Kafka. -
SASL_ SSL _ SCRAM _ SHA512 — Vous pouvez utiliser ce type d'authentification pour contrôler l'accès à vos clusters Apache Kafka. Cette méthode enregistre le nom d'utilisateur et le mot de passe dans AWS Secrets Manager. Le secret doit être associé au cluster Kafka. Pour plus d'informations, consultez Authentification à l'aide deSASL/SCRAM
dans la documentation d'Apache Kafka. -
SASL_ PLAINTEXT _ SCRAM _ SHA512 — Cette méthode utilise le protocole
SASL_PLAINTEXTde sécurité et leSCRAM_SHA512 SASLmécanisme. Cette méthode utilise votre nom d'utilisateur et votre mot de passe enregistrés dans AWS Secrets Manager. Pour plus d'informations, consultez la section de SASLconfigurationde la documentation d'Apache Kafka. -
SSL— SSL l'authentification utilise des fichiers de stockage de clés et de stockage de confiance pour se connecter au cluster Apache Kafka. Vous devez générer les fichiers keystore et truststore, les charger dans un compartiment Amazon S3 et fournir la référence à Amazon S3 lorsque vous déployez le connecteur. Le magasin de clés, le magasin de confiance et les SSL clés sont stockés dans AWS Secrets Manager. Votre client doit fournir la clé AWS secrète lors du déploiement du connecteur. Pour plus d'informations, consultez la section Utilisation du chiffrement et de l'authentification SSL
dans la documentation d'Apache Kafka. Pour plus d’informations, consultez Configuration de l'authentification pour le connecteur Athena Kafka.
-
-
certificates_s3_reference – L'emplacement Amazon S3 qui contient les certificats (les fichiers keystore et truststore).
-
disable_spill_encryption – (Facultatif) Lorsque la valeur est définie sur
True, le chiffrement des déversements est désactivé. Par défaut, les donnéesFalsetransmises à S3 sont chiffrées à l'aide de AES GCM -, soit à l'aide d'une clé générée de manière aléatoire, soit KMS pour générer des clés. La désactivation du chiffrement des déversements peut améliorer les performances, surtout si votre lieu de déversement utilise le chiffrement côté serveur. -
kafka_endpoint – Les détails du point de terminaison à fournir à Kafka.
-
schema_registry_url — URL Adresse du registre des schémas (par exemple,).
http://schema-registry.example.org:8081S'applique aux formatsAVROdePROTOBUFdonnées et. -
secrets_manager_secret – Le nom du secret AWS dans lequel sont enregistrées les informations d'identification.
-
Paramètres de déversement – Les fonctions Lambda stockent temporairement (« déversent ») les données qui ne tiennent pas en mémoire vers Amazon S3. Toutes les instances de base de données accessibles par la même fonction Lambda déversent au même emplacement. Utilisez les paramètres du tableau suivant pour spécifier l'emplacement de déversement.
Paramètre Description spill_bucketObligatoire. Le nom du compartiment Amazon S3 où la fonction Lambda peut déverser des données. spill_prefixObligatoire. Le préfixe dans le compartiment de déversement où la fonction Lambda peut déverser des données. spill_put_request_headers(Facultatif) Carte JSON codée des en-têtes et des valeurs de la putObjectdemande Amazon S3 utilisée pour le déversement (par exemple,{"x-amz-server-side-encryption" : "AES256"}). Pour les autres en-têtes possibles, consultez PutObjectle Amazon Simple Storage Service API Reference. -
Sous-réseau IDs : un ou plusieurs sous-réseaux correspondant au sous-réseau IDs que la fonction Lambda peut utiliser pour accéder à votre source de données.
-
Cluster Kafka public ou cluster Confluent Cloud standard : associez le connecteur à un sous-réseau privé doté d'une passerelle. NAT
-
Cluster Confluent Cloud avec connectivité privée – Associez le connecteur à un sous-réseau privé qui possède une route vers le cluster Confluent Cloud.
-
Pour AWS Transit Gateway
, les sous-réseaux doivent se trouver dans un VPC réseau connecté à la même passerelle de transit que celle utilisée par Confluent Cloud. -
Pour le VPCpeering
, les sous-réseaux doivent se trouver dans un réseau VPC apparenté à Confluent Cloud. VPC -
En AWS PrivateLink
effet, les sous-réseaux doivent se trouver sur une route VPC menant aux VPC points de terminaison qui se connectent à Confluent Cloud.
-
-
Note
Si vous déployez le connecteur VPC dans un afin d'accéder à des ressources privées et que vous souhaitez également vous connecter à un service accessible au public tel que Confluent, vous devez associer le connecteur à un sous-réseau privé doté d'une NAT passerelle. Pour plus d'informations, consultez les NATpasserelles dans le guide de l'VPCutilisateur Amazon.
Prise en charge du type de données
Le tableau suivant indique les types de données correspondants pris en charge par Kafka et Apache Arrow.
| Kafka | Flèche |
|---|---|
| CHAR | VARCHAR |
| VARCHAR | VARCHAR |
| TIMESTAMP | MILLISECOND |
| DATE | DAY |
| BOOLEAN | BOOL |
| SMALLINT | SMALLINT |
| INTEGER | INT |
| BIGINT | BIGINT |
| DECIMAL | FLOAT8 |
| DOUBLE | FLOAT8 |
Partitions et déversements
Les rubriques Kafka sont divisées en partitions. Chaque partition est ordonnée. Chaque message dans une partition a un ID incrémentiel appelé offset. Chaque partition Kafka est ensuite divisée en plusieurs parties pour un traitement parallèle. Les données sont disponibles pour la période de rétention configurée dans les clusters Kafka.
Bonnes pratiques
Il est recommandé d'utiliser la poussée vers le bas des prédicats lorsque vous interrogez Athena, comme dans les exemples suivants.
SELECT * FROM "kafka_catalog_name"."glue_schema_registry_name"."glue_schema_name" WHERE integercol = 2147483647
SELECT * FROM "kafka_catalog_name"."glue_schema_registry_name"."glue_schema_name" WHERE timestampcol >= TIMESTAMP '2018-03-25 07:30:58.878'
Configuration du connecteur Kafka
Pour pouvoir utiliser le connecteur, vous devez configurer votre cluster Apache Kafka, utilisez le Registre de schémas AWS Glue pour définir votre schéma et configurez l'authentification pour le connecteur.
Lorsque vous travaillez avec le registre des AWS Glue schémas, tenez compte des points suivants :
-
Assurez-vous que le texte du champ Description du registre de schémas AWS Glue inclut la chaîne
{AthenaFederationKafka}. Cette chaîne de marquage est obligatoire pour les AWS Glue registres que vous utilisez avec le connecteur Amazon Athena Kafka. -
Pour des performances optimales, n'utilisez que des minuscules pour vos noms de bases de données et de tables. L'utilisation d'une casse mixte oblige le connecteur à effectuer une recherche insensible à la casse, ce qui demande plus de temps de calcul.
Pour configurer votre environnement Apache Kafka et votre registre de AWS Glue schémas
-
Configurez votre environnement Apache Kafka.
-
Téléchargez le fichier de description de la rubrique Kafka (c'est-à-dire son schéma) JSON au format dans le registre des AWS Glue schémas. Pour plus d'informations, consultez la section Intégration à AWS Glue Schema Registry dans le guide du AWS Glue développeur.
-
Pour utiliser le format de
PROTOBUFdonnéesAVROou lorsque vous définissez le schéma dans le registre des AWS Glue schémas :-
Pour le nom du schéma, entrez le nom du sujet Kafka dans le même cadre que l'original.
-
Pour le format des données, choisissez Apache Avro ou Protocol Buffers.
Pour des exemples de schémas, voir la rubrique suivante.
-
Utilisez le format des exemples de cette rubrique lorsque vous téléchargez votre schéma dans le registre de schémas AWS Glue.
JSONexemple de schéma de type
Dans l'exemple suivant, le schéma à créer dans le registre des AWS Glue json schémas indique la valeur pour dataFormat et les utilisations datatypejson pourtopicName.
Note
La valeur de topicName doit utiliser la même casse que le nom de la rubrique de Kafka.
{ "topicName": "datatypejson", "message": { "dataFormat": "json", "fields": [ { "name": "intcol", "mapping": "intcol", "type": "INTEGER" }, { "name": "varcharcol", "mapping": "varcharcol", "type": "VARCHAR" }, { "name": "booleancol", "mapping": "booleancol", "type": "BOOLEAN" }, { "name": "bigintcol", "mapping": "bigintcol", "type": "BIGINT" }, { "name": "doublecol", "mapping": "doublecol", "type": "DOUBLE" }, { "name": "smallintcol", "mapping": "smallintcol", "type": "SMALLINT" }, { "name": "tinyintcol", "mapping": "tinyintcol", "type": "TINYINT" }, { "name": "datecol", "mapping": "datecol", "type": "DATE", "formatHint": "yyyy-MM-dd" }, { "name": "timestampcol", "mapping": "timestampcol", "type": "TIMESTAMP", "formatHint": "yyyy-MM-dd HH:mm:ss.SSS" } ] } }
CSVexemple de schéma de type
Dans l'exemple suivant, le schéma à créer dans le registre des AWS Glue csv schémas indique la valeur pour dataFormat et les utilisations datatypecsvbulk pourtopicName. La valeur de topicName doit utiliser la même casse que le nom de la rubrique de Kafka.
{ "topicName": "datatypecsvbulk", "message": { "dataFormat": "csv", "fields": [ { "name": "intcol", "type": "INTEGER", "mapping": "0" }, { "name": "varcharcol", "type": "VARCHAR", "mapping": "1" }, { "name": "booleancol", "type": "BOOLEAN", "mapping": "2" }, { "name": "bigintcol", "type": "BIGINT", "mapping": "3" }, { "name": "doublecol", "type": "DOUBLE", "mapping": "4" }, { "name": "smallintcol", "type": "SMALLINT", "mapping": "5" }, { "name": "tinyintcol", "type": "TINYINT", "mapping": "6" }, { "name": "floatcol", "type": "DOUBLE", "mapping": "7" } ] } }
AVROexemple de schéma de type
L'exemple suivant est utilisé pour créer un schéma AVRO basé dans le registre des AWS Glue
schémas. Lorsque vous définissez le schéma dans le registre des AWS Glue schémas, pour le nom du schéma, vous entrez le nom du sujet Kafka dans le même boîtier que l'original, et pour le format des données, vous choisissez Apache Avro. Comme vous spécifiez ces informations directement dans le registre, les topicName champs dataformat et ne sont pas obligatoires.
{ "type": "record", "name": "avrotest", "namespace": "example.com", "fields": [{ "name": "id", "type": "int" }, { "name": "name", "type": "string" } ] }
PROTOBUFexemple de schéma de type
L'exemple suivant est utilisé pour créer un schéma PROTOBUF basé dans le registre des AWS Glue schémas. Lorsque vous définissez le schéma dans le registre des AWS Glue schémas, pour le nom du schéma, vous entrez le nom du sujet Kafka dans le même boîtier que l'original, et pour le format des données, vous choisissez Protocol Buffers. Comme vous spécifiez ces informations directement dans le registre, les topicName champs dataformat et ne sont pas obligatoires. La première ligne définit le schéma commePROTOBUF.
syntax = "proto3"; message protobuftest { string name = 1; int64 calories = 2; string colour = 3; }
Pour plus d'informations sur l'ajout d'un registre et de schémas dans le registre des AWS Glue schémas, consultez la section Getting started with Schema Registry dans la AWS Glue documentation.
Configuration de l'authentification pour le connecteur Athena Kafka
Vous pouvez utiliser différentes méthodes pour vous authentifier auprès de votre cluster Apache Kafka, notammentSASL/SSLSCRAMPLAIN,SASL/etSASL/. PLAINTEXT
Le tableau suivant indique les types d'authentification pour le connecteur ainsi que le protocole et le SASL mécanisme de sécurité pour chacun d'eux. Pour de plus amples informations, consultez la section Sécurité
| auth_type | security.protocol | sasl.mechanism | Compatibilité avec les types de cluster |
|---|---|---|---|
SASL_SSL_PLAIN |
SASL_SSL |
PLAIN |
|
SASL_PLAINTEXT_PLAIN |
SASL_PLAINTEXT |
PLAIN |
|
SASL_SSL_SCRAM_SHA512 |
SASL_SSL |
SCRAM-SHA-512 |
|
SASL_PLAINTEXT_SCRAM_SHA512 |
SASL_PLAINTEXT |
SCRAM-SHA-512 |
|
SSL |
SSL |
N/A |
|
SSL
Si le cluster est SSL authentifié, vous devez générer les fichiers Trust Store et Key Store et les charger dans le compartiment Amazon S3. Vous devez fournir cette référence Amazon S3 lorsque vous déployez le connecteur. Le magasin de clés, le magasin de confiance et les SSL clés sont stockés dans le AWS Secrets Manager. Vous fournissez la clé AWS secrète lorsque vous déployez le connecteur.
Pour plus d'informations sur la création d'un secret dans Secrets Manager, voir la rubrique Créer un secret AWS Secrets Manager.
Pour utiliser ce type d'authentification, définissez les variables d'environnement comme indiqué dans le tableau suivant.
| Paramètre | Valeur |
|---|---|
auth_type |
SSL |
certificates_s3_reference |
L'emplacement Amazon S3 qui contient les certificats. |
secrets_manager_secret |
Le nom de votre clé AWS secrète. |
Après avoir créé un secret dans Secrets Manager, vous pouvez le consulter dans la console Secrets Manager.
Visualisation de votre secret dans Secrets Manager
Ouvrez la console Secrets Manager à l'adresse https://console.aws.amazon.com/secretsmanager/
. -
Dans le volet de navigation, sélectionnez Secrets.
-
Sur la page Secrets, choisissez le lien vers votre secret.
-
Sur la page de détails de votre secret, sélectionnez Retrieve secret value (Récupérer la valeur du secret).
L'image suivante montre un exemple de secret avec trois paires clé/valeur :
keystore_password,truststore_passwordetssl_key_password.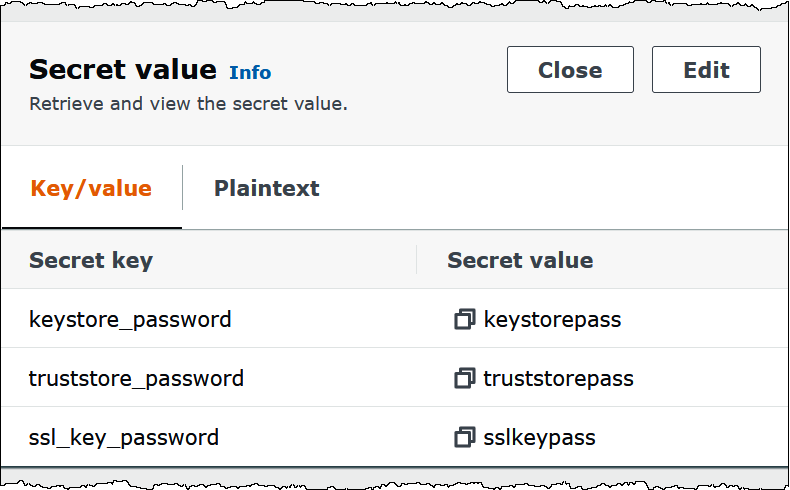
Pour plus d'informations sur l'utilisation SSL avec Kafka, consultez la section Utilisation du chiffrement et de l'authentification SSL
SASL/SCRAM
Si votre cluster utilise SCRAM l'authentification, fournissez la clé Secrets Manager associée au cluster lorsque vous déployez le connecteur. Les informations d'identification AWS de l'utilisateur (clé secrète et clé d'accès) sont utilisées pour s'authentifier au cluster.
Définissez les variables d'environnement comme indiqué dans le tableau suivant.
| Paramètre | Valeur |
|---|---|
auth_type |
SASL_SSL_SCRAM_SHA512 |
secrets_manager_secret |
Le nom de votre clé AWS secrète. |
L'image suivante montre un exemple de secret dans la console Secrets Manager avec deux paires clé/valeur : une pour username et une pour password.
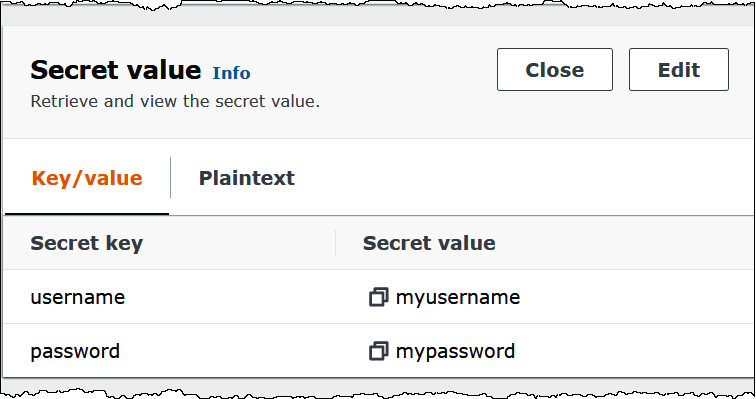
Pour plus d'informations sur l'utilisation deSASL/SCRAMavec Kafka, consultez Authentification à l'aide deSASL/SCRAM
Informations de licence
En utilisant ce connecteur, vous reconnaissez l'inclusion de composants tiers, dont la liste se trouve dans le fichier pom.xml
Ressources supplémentaires
Pour plus d'informations sur ce connecteur, rendez-vous sur le site correspondant
