Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Prévisions basées sur les moteurs de demande
Pour améliorer la précision des prévisions lors de la configuration de vos prévisions, vous pouvez utiliser des inducteurs de demande. Les moteurs de demande sont des entrées de séries chronologiques connexes qui reflètent les tendances et les saisons des produits. Au lieu de dépendre de l'historique de la demande, vous pouvez utiliser des facteurs de demande pour influencer la chaîne d'approvisionnement en fonction de divers facteurs. Par exemple, les promotions, les modifications de prix et les campagnes marketing. La planification de la demande prend en charge les moteurs de demande historiques et futurs.
Conditions préalables à l'utilisation de moteurs de demande
Avant d'ingérer des données pour les moteurs de demande, assurez-vous que les données répondent aux conditions suivantes :
-
Assurez-vous d'ingérer les données des inducteurs de demande dans l'entité de données supplementary_time_series. Vous pouvez fournir des informations sur les facteurs de demande historiques et futurs. Pour plus d'informations sur les entités de données requises par Demand Planning, consultezPlanification de la demande.
Si vous ne trouvez pas l'entité de données supplementary_time_series, votre instance utilise peut-être une version antérieure du modèle de données. Vous pouvez contacter le AWS Support pour mettre à jour la version de votre modèle de données ou créer une nouvelle connexion de données.
-
Assurez-vous que les colonnes suivantes sont renseignées dans l'entité de données supplementary_time_series.
-
id — Cette colonne est l'identifiant unique de l'enregistrement et est requise pour une ingestion de données réussie.
-
order_date — Cette colonne indique l'horodatage du moteur de demande. Il peut être daté à la fois du passé et du futur.
-
time_series_name — Cette colonne est l'identifiant de chaque moteur de demande. La valeur de cette colonne doit commencer par une lettre, comporter de 2 à 56 caractères et peut contenir des lettres, des chiffres et des traits de soulignement. Les autres caractères spéciaux ne sont pas valides.
-
time_series_value — Cette colonne fournit la mesure des points de données d'un facteur de demande particulier à un moment précis. Seules les valeurs numériques sont prises en charge.
-
-
Sélectionnez un minimum de 1 et un maximum de 13 inducteurs de demande. Assurez-vous que les méthodes d'agrégation et de remplissage sont configurées. Pour plus d'informations sur les méthodes de remplissage, consultezMéthode de remplissage des données sur les facteurs de demande. Vous pouvez modifier les paramètres à tout moment. La planification de la demande appliquera les modifications lors du prochain cycle de prévision.
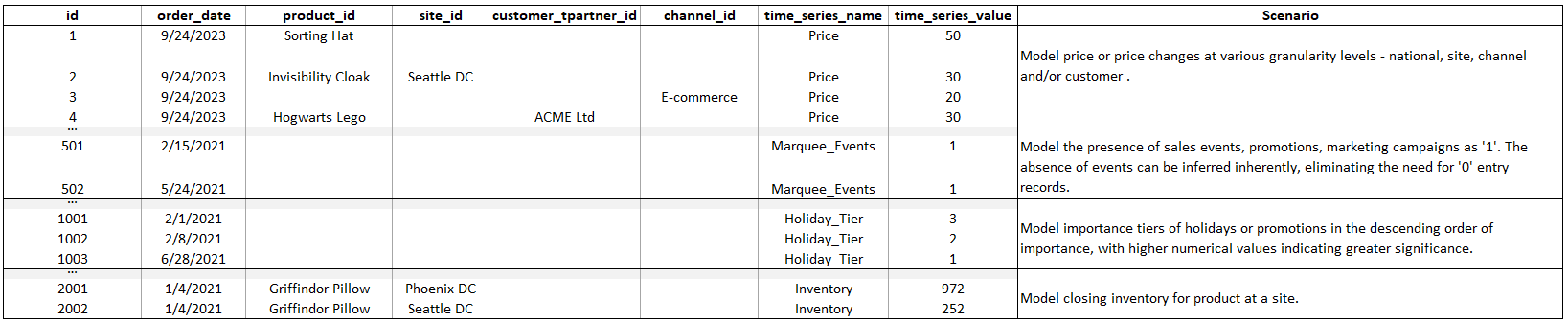
L'exemple suivant montre comment un plan de demande est généré lorsque les colonnes d'inducteur de demande requises sont ingérées dans l'entité de données supplementary_time_series. La planification de la demande recommande de fournir des données historiques et futures sur les facteurs de demande (si disponibles). Ces données aident le modèle d'apprentissage à apprendre et à appliquer le modèle aux prévisions.
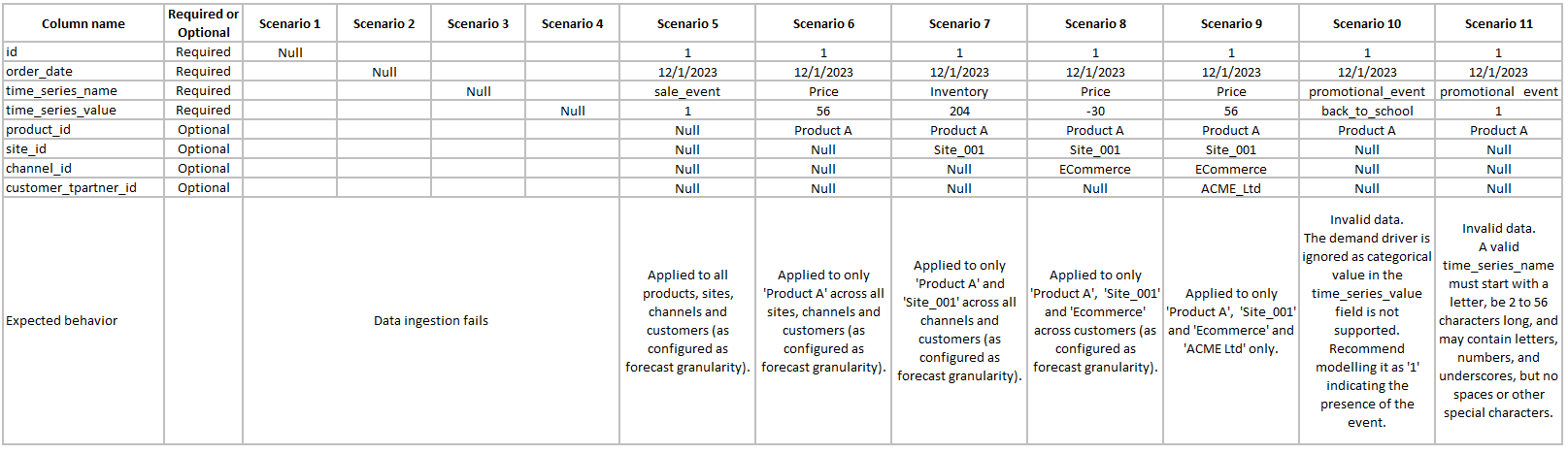
L'exemple suivant montre comment configurer certains moteurs de demande courants dans votre ensemble de données.
Lorsque vous fournissez des indicateurs avancés, Demand Planning vous recommande vivement d'ajuster la date de la série chronologique. Supposons, par exemple, qu'une métrique donnée serve d'indicateur avancé sur 20 jours avec un taux de conversion de 70 %. Dans ce cas, envisagez de décaler la date de la série chronologique de 20 jours, puis d'appliquer le facteur de conversion approprié. Bien que le modèle d'apprentissage puisse apprendre des modèles sans de tels ajustements, l'alignement des données des indicateurs avancés sur les résultats correspondants est plus efficace pour la reconnaissance des modèles. L'ampleur de la valeur joue un rôle important dans ce processus, car elle améliore la capacité du modèle à apprendre et à interpréter les modèles avec précision.
