Ceci est le guide du développeur du AWS CDK v2. L'ancien CDK v1 est entré en maintenance le 1er juin 2022 et a pris fin le 1er juin 2023.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Bonnes pratiques pour le développement et le déploiement d'une infrastructure cloud avec le AWS CDK
Avec le AWS CDK, les développeurs ou les administrateurs peuvent définir leur infrastructure cloud à l'aide d'un langage de programmation pris en charge. Les applications CDK doivent être organisées en unités logiques, telles que l'API, la base de données et les ressources de surveillance, et éventuellement disposer d'un pipeline pour les déploiements automatisés. Les unités logiques doivent être implémentées sous forme de constructions comprenant les éléments suivants :
-
Infrastructure (par exemple, des compartiments Amazon S3, des bases de données Amazon RDS ou un réseau Amazon VPC)
-
Code d'exécution (comme les fonctions AWS Lambda)
-
Code de configuration
Les piles définissent le modèle de déploiement de ces unités logiques. Pour une présentation plus détaillée des concepts qui sous-tendent le CDK, consultez Getting started with the AWS CDK.
Le AWS CDK reflète une prise en compte attentive des besoins de nos clients et de nos équipes internes, ainsi que des modèles de défaillance qui surviennent souvent lors du déploiement et de la maintenance continue d'applications cloud complexes. Nous avons découvert que les échecs sont souvent liés à des « out-of-band » modifications apportées à une application qui n'ont pas été entièrement testées, telles que des modifications de configuration. C'est pourquoi nous avons développé le AWS CDK autour d'un modèle dans lequel l'ensemble de votre application est défini dans le code, non seulement la logique métier, mais également l'infrastructure et la configuration. Ainsi, les modifications proposées peuvent être soigneusement examinées, testées de manière exhaustive dans des environnements ressemblant à la production à des degrés divers, et annulées complètement en cas de problème.
Au moment du déploiement, le AWS CDK synthétise un assemblage cloud contenant les éléments suivants :
-
AWS CloudFormation modèles décrivant votre infrastructure dans tous les environnements cibles
-
Ressources de fichiers contenant votre code d'exécution et ses fichiers de support
Avec le CDK, chaque commit dans la branche principale de contrôle de version de votre application peut représenter une version complète, cohérente et déployable de votre application. Votre application peut ensuite être déployée automatiquement chaque fois qu'une modification est apportée.
La philosophie qui sous-tend le AWS CDK débouche sur nos meilleures pratiques recommandées, que nous avons divisées en quatre grandes catégories.
Astuce
Tenez également compte des meilleures pratiques AWS CloudFormation et des AWS services individuels que vous utilisez, le cas échéant, pour l'infrastructure définie par le CDK.
Bonnes pratiques organisationnelles
Au début de l'adoption du AWS CDK, il est important de réfléchir à la manière de préparer votre organisation à la réussite. Il est recommandé de disposer d'une équipe d'experts chargée de former et de guider le reste de l'entreprise lors de l'adoption du CDK. La taille de cette équipe peut varier, allant d'une ou deux personnes dans une petite entreprise à un centre d'excellence cloud (CCoE) à part entière dans une grande entreprise. Cette équipe est chargée de définir les normes et les politiques relatives à l'infrastructure cloud de votre entreprise, ainsi que de former et d'encadrer les développeurs.
Le CCo E peut fournir des conseils sur les langages de programmation à utiliser pour l'infrastructure cloud. Les détails peuvent varier d'une organisation à l'autre, mais une bonne politique permet de s'assurer que les développeurs peuvent comprendre et gérer l'infrastructure cloud de l'entreprise.
Le CCo E crée également une « zone de landing zone » qui définit les unités organisationnelles au sein desquelles vous vous trouvez AWS. Une zone d'atterrissage est un AWS environnement multi-comptes préconfiguré, sécurisé, évolutif, basé sur les meilleures pratiques. Pour relier les services qui constituent votre zone d'atterrissage, vous pouvez utiliser AWS Control Tower
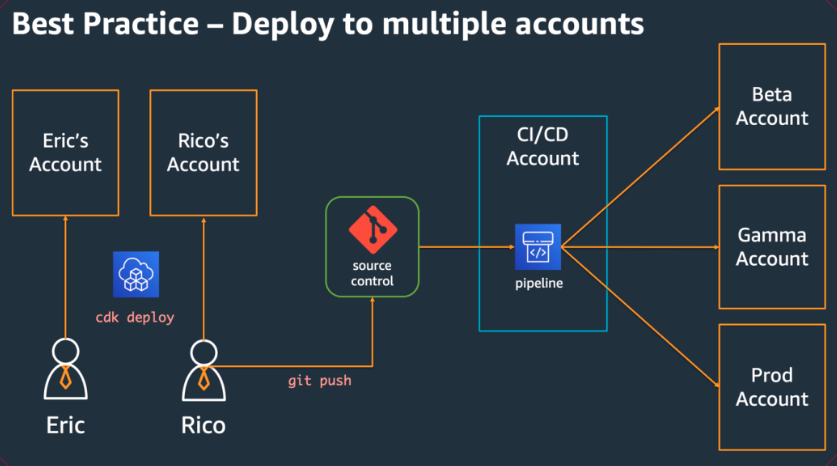
Les équipes de développement devraient être en mesure d'utiliser leurs propres comptes pour tester et déployer de nouvelles ressources dans ces comptes selon les besoins. Les développeurs individuels peuvent traiter ces ressources comme des extensions de leur propre poste de développement. À l'aide de CDK Pipelines, AWS les applications CDK peuvent ensuite être déployées via CI/CD un compte dans des environnements de test, d'intégration et de production (chacun étant isolé dans sa AWS propre région ou compte). Cela se fait en fusionnant le code des développeurs dans le référentiel canonique de votre organisation.
Bonnes pratiques de codage
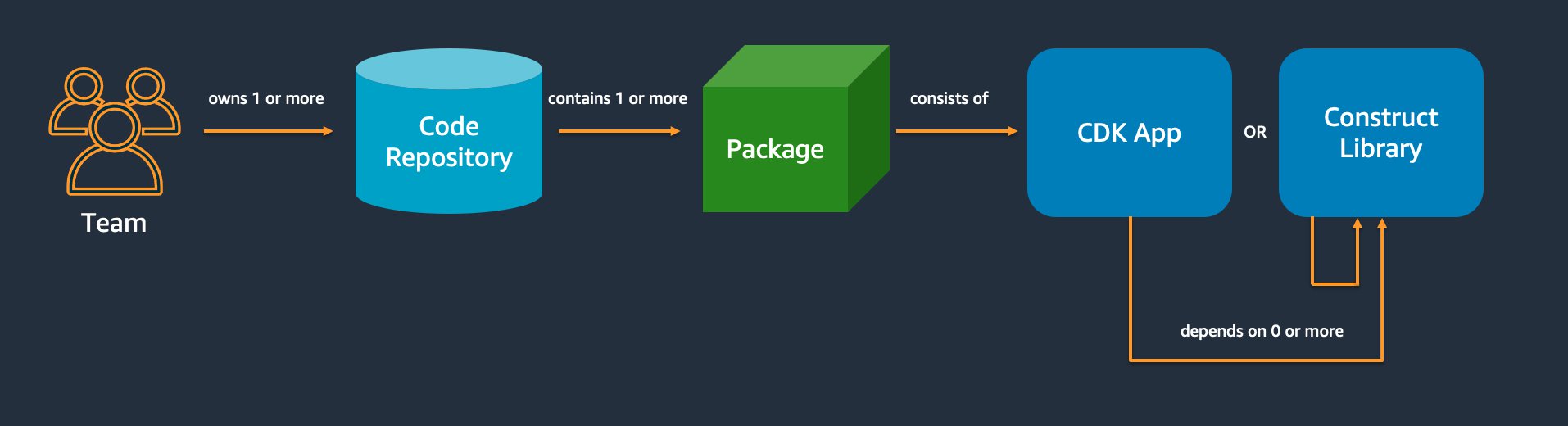
Cette section présente les meilleures pratiques pour organiser votre code AWS CDK. Le schéma suivant montre la relation entre une équipe et les référentiels de code, les packages, les applications et les bibliothèques de construction de cette équipe.
- Commencez simplement et ajoutez de la complexité uniquement lorsque vous en avez besoin
-
Le principe directeur de la plupart de nos meilleures pratiques est de garder les choses aussi simples que possible, mais rien de plus simple. Ajoutez de la complexité uniquement lorsque vos exigences imposent une solution plus complexe. Avec le AWS CDK, vous pouvez refactoriser votre code si nécessaire pour répondre aux nouvelles exigences. Vous n'avez pas à concevoir dès le départ tous les scénarios possibles.
- S'aligner sur le framework AWS Well-Architected
-
Le AWS Well-Architected
Framework définit un composant comme le code, la configuration AWS et les ressources qui, ensemble, répondent à une exigence. Un composant est souvent une unité de propriété technique. Il est découplé des autres composants. Le terme charge de travail est utilisé pour désigner un ensemble de composants qui collaborent pour apporter une valeur métier. La charge de travail représente généralement le niveau de détails dont discutent les responsables métier et techniques. Une application AWS CDK correspond à un composant tel que défini par le AWS Well-Architected Framework. AWS Les applications CDK sont un mécanisme permettant de codifier et de diffuser les meilleures pratiques en matière d'applications cloud Well-Architected. Vous pouvez également créer et partager des composants sous forme de bibliothèques de code réutilisables via des référentiels d'artefacts, tels que. AWS CodeArtifact
- Chaque application commence par un seul package dans un seul référentiel
-
Un seul package est le point d'entrée de votre application AWS CDK. Vous définissez ici comment et où déployer les différentes unités logiques de votre application. Vous définissez également le CI/CD pipeline pour déployer l'application. Les structures de l'application définissent les unités logiques de votre solution.
Utilisez des packages supplémentaires pour les constructions que vous utilisez dans plusieurs applications. (Les constructions partagées doivent également avoir leur propre cycle de vie et leur propre stratégie de test.) Les dépendances entre les packages d'un même référentiel sont gérées par les outils de compilation de votre dépôt.
Bien que cela soit possible, nous vous déconseillons de placer plusieurs applications dans le même référentiel, en particulier lorsque vous utilisez des pipelines de déploiement automatisés. Cela augmente le « rayon d'action » des modifications lors du déploiement. Lorsqu'un référentiel contient plusieurs applications, les modifications apportées à une application déclenchent le déploiement des autres (même si les autres n'ont pas changé). De plus, une interruption dans une application empêche le déploiement des autres applications.
- Transférez le code vers des référentiels en fonction du cycle de vie du code ou de la propriété de l'équipe
-
Lorsque des packages commencent à être utilisés dans plusieurs applications, déplacez-les vers leur propre référentiel. De cette façon, les packages peuvent être référencés par les systèmes de création d'applications qui les utilisent, et ils peuvent également être mis à jour à des cadences indépendantes du cycle de vie des applications. Cependant, dans un premier temps, il peut être judicieux de placer toutes les constructions partagées dans un seul référentiel.
Déplacez également les packages vers leur propre référentiel lorsque différentes équipes y travaillent. Cela permet de renforcer le contrôle d'accès.
Pour consommer des packages au-delà des limites des référentiels, vous avez besoin d'un référentiel de packages privé, similaire à NPM ou Maven Central PyPi, mais interne à votre organisation. Vous avez également besoin d'un processus de publication qui génère, teste et publie le package dans le référentiel de packages privé. CodeArtifactpeut héberger des packages pour les langages de programmation les plus courants.
Les dépendances vis-à-vis des packages du référentiel de packages sont gérées par le gestionnaire de packages de votre langue, tel que NPM for TypeScript ou JavaScript applications. Votre gestionnaire de packages permet de s'assurer que les builds sont répétables. Pour ce faire, il enregistre les versions spécifiques de chaque package dont dépend votre application. Il vous permet également de mettre à niveau ces dépendances de manière contrôlée.
Les packages partagés nécessitent une stratégie de test différente. Pour une seule application, il peut être suffisant de déployer l'application dans un environnement de test et de confirmer qu'elle fonctionne toujours. Mais les packages partagés doivent être testés indépendamment de l'application utilisatrice, comme s'ils étaient mis à la disposition du public. (Votre organisation peut choisir de mettre certains packages partagés à la disposition du public.)
N'oubliez pas qu'une construction peut être arbitrairement simple ou complexe. A
Bucketest une construction, maisCameraShopWebsitecela pourrait aussi être une construction.
- L'infrastructure et le code d'exécution se trouvent dans le même package
-
En plus de générer des AWS CloudFormation modèles pour le déploiement de l'infrastructure, le AWS CDK regroupe également les actifs d'exécution tels que les fonctions Lambda et les images Docker et les déploie parallèlement à votre infrastructure. Cela permet de combiner le code qui définit votre infrastructure et le code qui implémente votre logique d'exécution en une seule construction. C'est une bonne pratique de le faire. Ces deux types de code n'ont pas besoin de résider dans des référentiels séparés ni même dans des packages distincts.
Pour faire évoluer les deux types de code ensemble, vous pouvez utiliser une construction autonome qui décrit complètement une fonctionnalité, y compris son infrastructure et sa logique. Avec une construction autonome, vous pouvez tester les deux types de code de manière isolée, partager et réutiliser le code entre les projets, et synchroniser les versions de l'ensemble du code.
Élaborez les meilleures pratiques
Cette section contient les meilleures pratiques pour le développement de constructions. Les constructions sont des modules réutilisables et composables qui encapsulent des ressources. Ce sont les éléments de base des applications AWS CDK.
- Modélisez avec des constructions, déployez avec des piles
-
Les piles sont l'unité de déploiement : tous les éléments d'une pile sont déployés ensemble. Ainsi, lorsque vous créez les unités logiques de niveau supérieur de votre application à partir de plusieurs AWS ressources, représentez chaque unité logique sous forme de construction et non de pile. Utilisez les piles uniquement pour décrire comment vos constructions doivent être composées et connectées pour vos différents scénarios de déploiement.
Par exemple, si l'une de vos unités logiques est un site Web, les structures qui le composent (comme un bucket Amazon S3, une API Gateway, des fonctions Lambda ou des tables Amazon RDS) doivent être composées en une seule construction de haut niveau. Ensuite, cette construction doit être instanciée dans une ou plusieurs piles pour le déploiement.
En utilisant des structures pour la construction et des piles pour le déploiement, vous améliorez le potentiel de réutilisation de votre infrastructure et vous bénéficiez d'une plus grande flexibilité dans la manière dont elle est déployée.
- Configuration avec des propriétés et des méthodes, pas avec des variables d'environnement
-
Les recherches de variables d'environnement dans les constructions et les piles constituent un anti-modèle courant. Les constructions et les piles doivent accepter un objet de propriétés pour permettre une configurabilité complète dans le code. Sinon, cela crée une dépendance à l'égard de la machine sur laquelle le code sera exécuté, ce qui crée encore plus d'informations de configuration que vous devez suivre et gérer.
En général, les recherches de variables d'environnement doivent être limitées au niveau supérieur d'une application AWS CDK. Ils doivent également être utilisés pour transmettre les informations nécessaires à l'exécution dans un environnement de développement. Pour plus d'informations, consultez Environnements pour le AWS CDK.
- Testez votre infrastructure à l'unité
-
Pour exécuter de manière cohérente une suite complète de tests unitaires au moment de la création dans tous les environnements, évitez les recherches de réseau lors de la synthèse et modélisez toutes vos étapes de production dans le code. (Ces meilleures pratiques seront abordées plus loin.) Si un seul commit aboutit toujours au même modèle généré, vous pouvez faire confiance aux tests unitaires que vous rédigez pour confirmer que les modèles générés ressemblent à vos attentes. Pour plus d'informations, consultez la section Tester les applications AWS CDK.
- Ne modifiez pas l'ID logique des ressources dynamiques
-
La modification de l'ID logique d'une ressource entraîne son remplacement par un nouveau lors du prochain déploiement. Pour les ressources dynamiques telles que les bases de données et les compartiments S3, ou pour les infrastructures persistantes telles qu'un Amazon VPC, c'est rarement ce que vous souhaitez. Faites attention à toute refactorisation de votre code AWS CDK qui pourrait entraîner une modification de l'ID. Rédigez des tests unitaires qui affirment que la logique IDs de vos ressources dynamiques reste statique. L'identifiant logique est dérivé de celui
idque vous spécifiez lorsque vous instanciez la construction et de la position de la construction dans l'arbre de construction. Pour plus d'informations, consultez Logical IDs.
- Les constructions ne suffisent pas à assurer la conformité
-
De nombreuses entreprises clientes écrivent leurs propres enveloppes pour les constructions L2 (les constructions « sélectionnées » qui représentent des AWS ressources individuelles avec des valeurs par défaut et des meilleures pratiques intégrées). Ces wrappers appliquent les meilleures pratiques de sécurité telles que le chiffrement statique et les politiques IAM spécifiques. Par exemple, vous pouvez créer un
MyCompanyBucketque vous utiliserez ensuite dans vos applications à la place de la structure Amazon S3Buckethabituelle. Ce modèle est utile pour définir les directives de sécurité dès le début du cycle de développement logiciel, mais ne vous y fiez pas comme seul moyen de les faire appliquer.Utilisez plutôt des AWS fonctionnalités telles que les politiques de contrôle des services et les limites d'autorisation pour renforcer vos garde-fous au niveau de l'organisation. Utilisez Aspects et le AWS CDK ou des outils tels que CloudFormation Guard
pour affirmer les propriétés de sécurité des éléments de l'infrastructure avant le déploiement. Utilisez AWS CDK pour ce qu'il fait le mieux. Enfin, gardez à l'esprit que l'écriture de vos propres constructions « L2+ » peut empêcher vos développeurs de tirer parti des packages AWS CDK tels que AWS Solutions Constructs ou des constructions tierces de Construct Hub. Ces packages sont généralement construits sur des structures AWS CDK standard et ne pourront pas utiliser vos structures d'emballage.
Bonnes pratiques en matière d'applications
Dans cette section, nous expliquons comment écrire vos applications AWS CDK, en combinant des structures pour définir la manière dont vos AWS ressources sont connectées.
- Prendre des décisions au moment de la synthèse
-
Bien qu'il vous AWS CloudFormation permette de prendre des décisions au moment du déploiement (en utilisant
Conditions{ Fn::If }, etParameters) et que le AWS CDK vous donne un certain accès à ces mécanismes, nous vous déconseillons de les utiliser. Les types de valeurs que vous pouvez utiliser et les types d'opérations que vous pouvez effectuer sur celles-ci sont limités par rapport à ce qui est disponible dans un langage de programmation à usage général.Essayez plutôt de prendre toutes les décisions, telles que la construction à instancier, dans votre application AWS CDK en utilisant les
ifinstructions et les autres fonctionnalités de votre langage de programmation. Par exemple, un idiome CDK courant, qui consiste à itérer sur une liste et à instancier une construction avec les valeurs de chaque élément de la liste, n'est tout simplement pas possible à l'aide d'expressions. AWS CloudFormationAWS CloudFormation Traitez-le comme un détail d'implémentation utilisé par le AWS CDK pour des déploiements cloud robustes, et non comme une langue cible. Vous n'écrivez pas de AWS CloudFormation modèles en TypeScript Python, vous écrivez du code CDK qui est utilisé CloudFormation pour le déploiement.
- Utiliser les noms de ressources générés, pas les noms physiques
-
Les noms sont une ressource précieuse. Chaque nom ne peut être utilisé qu'une seule fois. Par conséquent, si vous codez en dur le nom d'une table ou d'un bucket dans votre infrastructure et votre application, vous ne pouvez pas déployer cet élément d'infrastructure deux fois dans le même compte. (Le nom dont nous parlons ici est le nom spécifié, par exemple, par la
bucketNamepropriété d'une construction de compartiment Amazon S3.)Pire encore, vous ne pouvez pas apporter de modifications à la ressource qui nécessitent son remplacement. Si une propriété ne peut être définie que lors de la création d'une ressource, telle que celle
KeySchemad'une table Amazon DynamoDB, cette propriété est immuable. La modification de cette propriété nécessite une nouvelle ressource. Cependant, la nouvelle ressource doit porter le même nom pour être une véritable ressource de remplacement. Mais elle ne peut pas porter le même nom tant que la ressource existante utilise toujours ce nom.Une meilleure approche consiste à spécifier le moins de noms possible. Si vous omettez les noms des ressources, le AWS CDK les générera pour vous d'une manière qui ne posera aucun problème. Supposons que vous ayez une table en tant que ressource. Vous pouvez ensuite transmettre le nom de table généré en tant que variable d'environnement à votre fonction AWS Lambda. Dans votre application AWS CDK, vous pouvez référencer le nom de la table sous
table.tableNamela forme. Vous pouvez également générer un fichier de configuration sur votre EC2 instance Amazon au démarrage ou écrire le nom réel de la table dans le AWS Systems Manager Parameter Store afin que votre application puisse le lire à partir de là.Si l'endroit où vous en avez besoin est une autre pile de AWS CDK, c'est encore plus simple. Supposons qu'une pile définisse la ressource et qu'une autre pile doive l'utiliser, les règles suivantes s'appliquent :
-
Si les deux piles se trouvent dans la même application AWS CDK, transmettez une référence entre les deux piles. Par exemple, enregistrez une référence à la construction de la ressource en tant qu'attribut de la stack (
this.stack.uploadBucket = amzn-s3-demo-bucket) de définition. Transmettez ensuite cet attribut au constructeur de la pile qui a besoin de la ressource. -
Lorsque les deux piles se trouvent dans des applications AWS CDK différentes, utilisez une
fromméthode statique pour utiliser une ressource définie de l'extérieur en fonction de son ARN, de son nom ou d'autres attributs. (Par exemple, utilisez-leTable.fromArn()pour une table DynamoDB). Utilisez laCfnOutputconstruction pour imprimer l'ARN ou toute autre valeur requise dans la sortie decdk deployou pour consulter la console AWS de gestion. La deuxième application peut également lire le CloudFormation modèle généré par la première application et récupérer cette valeur dans laOutputssection.
-
- Définissez les politiques de suppression et de conservation des journaux
-
Le AWS CDK tente de vous empêcher de perdre des données en appliquant par défaut des politiques qui conservent tout ce que vous créez. Par exemple, la politique de suppression par défaut pour les ressources contenant des données (telles que les compartiments Amazon S3 et les tables de base de données) consiste à ne pas supprimer la ressource lorsqu'elle est supprimée de la pile. Au lieu de cela, la ressource devient orpheline de la pile. De même, le CDK conserve par défaut tous les journaux pour toujours. Dans les environnements de production, ces valeurs par défaut peuvent rapidement entraîner le stockage de grandes quantités de données dont vous n'avez pas réellement besoin, et une AWS facture correspondante.
Réfléchissez bien aux règles que vous souhaitez appliquer à chaque ressource de production et spécifiez-les en conséquence. Utilisez Aspects et le AWS CDK pour valider les politiques de suppression et de journalisation de votre stack.
- Séparez votre application en plusieurs piles selon les exigences de déploiement
-
Il n'existe pas de règle absolue quant au nombre de piles dont votre application a besoin. Vous finirez généralement par baser votre décision sur vos modèles de déploiement. Tenez compte des consignes suivantes :
-
Il est généralement plus simple de conserver autant de ressources que possible dans la même pile, alors gardez-les ensemble, sauf si vous voulez qu'elles soient séparées.
-
Envisagez de conserver les ressources avec état (comme les bases de données) dans une pile séparée des ressources sans état. Vous pouvez ensuite activer la protection contre la résiliation sur la pile dynamique. Ainsi, vous pouvez librement détruire ou créer plusieurs copies de la pile apatride sans risque de perte de données.
-
Les ressources dynamiques sont plus sensibles au changement de nom des constructions ; le changement de nom entraîne le remplacement des ressources. Par conséquent, n'imbriquez pas de ressources dynamiques dans des constructions susceptibles d'être déplacées ou renommées (sauf si l'état peut être reconstruit en cas de perte, comme un cache). C'est une autre bonne raison de placer les ressources stateful dans leur propre pile.
-
- Engagez-vous
cdk.context.jsonà éviter les comportements non déterministes -
Le déterminisme est essentiel à la réussite des déploiements de AWS CDK. Une application AWS CDK doit avoir essentiellement le même résultat chaque fois qu'elle est déployée dans un environnement donné.
Comme votre application AWS CDK est écrite dans un langage de programmation à usage général, elle peut exécuter du code arbitraire, utiliser des bibliothèques arbitraires et effectuer des appels réseau arbitraires. Par exemple, vous pouvez utiliser un AWS SDK pour récupérer certaines informations de votre AWS compte lors de la synthèse de votre application. Sachez que cela se traduira par des exigences supplémentaires en matière de configuration des informations d'identification, une latence accrue et un risque, aussi minime soit-il, d'échec à chaque exécution
cdk synth.Ne modifiez jamais votre AWS compte ou vos ressources pendant la synthèse. La synthèse d'une application ne doit pas avoir d'effets secondaires. Les modifications de votre infrastructure ne doivent intervenir que pendant la phase de déploiement, une fois le AWS CloudFormation modèle généré. De cette façon, en cas de problème, AWS CloudFormation vous pouvez automatiquement annuler la modification. Pour apporter des modifications difficiles à apporter dans le framework AWS CDK, utilisez des ressources personnalisées pour exécuter du code arbitraire au moment du déploiement.
Même les appels strictement en lecture seule ne sont pas nécessairement sûrs. Réfléchissez à ce qui se passe si la valeur renvoyée par un appel réseau change. Quel aspect de votre infrastructure cela aura-t-il un impact ? Qu'adviendra-t-il des ressources déjà déployées ? Voici deux exemples de situations dans lesquelles une modification soudaine des valeurs peut poser problème.
-
Si vous fournissez un Amazon VPC à toutes les zones de disponibilité disponibles dans une région donnée, et que le nombre de ces zones AZs est de deux le jour du déploiement, votre espace IP est divisé en deux. Si une nouvelle zone de disponibilité est AWS lancée le jour suivant, le déploiement suivant tente de diviser votre espace IP en trois, ce qui nécessite de recréer tous les sous-réseaux. Cela ne sera probablement pas possible car vos EC2 instances Amazon sont toujours en cours d'exécution et vous devrez les nettoyer manuellement.
-
Si vous recherchez la dernière image de machine Amazon Linux et que vous déployez une EC2 instance Amazon, et que le lendemain une nouvelle image est publiée, le déploiement suivant récupère la nouvelle AMI et remplace toutes vos instances. Ce n'est peut-être pas ce à quoi vous vous attendiez.
Ces situations peuvent être pernicieuses, car le changement peut survenir après AWS des mois, voire des années, de déploiements réussis. Soudainement, vos déploiements échouent « sans aucune raison » et vous avez oublié depuis longtemps ce que vous avez fait et pourquoi.
Heureusement, le AWS CDK inclut un mécanisme appelé fournisseurs de contexte pour enregistrer un instantané des valeurs non déterministes. Cela permet aux futures opérations de synthèse de produire exactement le même modèle que lors de leur premier déploiement. Les seules modifications apportées au nouveau modèle sont celles que vous avez apportées à votre code. Lorsque vous utilisez la
.fromLookup()méthode d'une construction, le résultat de l'appel est mis encdk.context.jsoncache. Vous devez le valider dans le contrôle de version avec le reste de votre code pour vous assurer que les futures exécutions de votre application CDK utilisent la même valeur. Le kit d'outils CDK inclut des commandes pour gérer le cache de contexte, afin que vous puissiez actualiser des entrées spécifiques lorsque vous en avez besoin. Pour plus d'informations, consultez la section Valeurs de contexte et AWS CDK.Si vous avez besoin d'une valeur (provenant AWS ou d'une autre source) pour laquelle il n'existe aucun fournisseur de contexte CDK natif, nous vous recommandons d'écrire un script distinct. Le script doit récupérer la valeur et l'écrire dans un fichier, puis lire ce fichier dans votre application CDK. Exécutez le script uniquement lorsque vous souhaitez actualiser la valeur stockée, et non dans le cadre de votre processus de génération habituel.
-
- Laissez le AWS CDK gérer les rôles et les groupes de sécurité
-
Grâce à la
grantspropriété de la bibliothèque de constructions AWS CDK et à ses méthodes pratiques, vous pouvez créer des rôles AWS Identity and Access Management qui accordent l'accès à une ressource à une autre en utilisant des autorisations minimales. Par exemple, considérez une ligne comme celle-ci :amzn-s3-demo-bucket.grants.read(myLambda)Cette seule ligne ajoute une politique au rôle de la fonction Lambda (qui est également créée pour vous). Ce rôle et ses politiques comportent plus d'une douzaine de lignes CloudFormation que vous n'avez pas à écrire. Le AWS CDK n'accorde que les autorisations minimales requises pour que la fonction puisse lire depuis le compartiment.
Si vous demandez aux développeurs de toujours utiliser des rôles prédéfinis créés par une équipe de sécurité, le codage du AWS CDK devient beaucoup plus compliqué. Vos équipes risquent de perdre beaucoup de flexibilité dans la conception de leurs applications. Une meilleure alternative consiste à utiliser des politiques de contrôle des services et des limites d'autorisation pour s'assurer que les développeurs respectent les règles de sécurité.
- Modélisez toutes les étapes de production dans le code
-
Dans les AWS CloudFormation scénarios traditionnels, votre objectif est de produire un seul artefact paramétré afin qu'il puisse être déployé dans différents environnements cibles après avoir appliqué des valeurs de configuration spécifiques à ces environnements. Dans le CDK, vous pouvez et devez intégrer cette configuration dans votre code source. Créez une pile pour votre environnement de production et créez une pile distincte pour chacune de vos autres étapes. Ensuite, insérez les valeurs de configuration pour chaque pile dans le code. Utilisez des services tels que Secrets Manager
et Systems Manager Parameter Store pour les valeurs sensibles que vous ne souhaitez pas enregistrer dans le contrôle de source, en utilisant les noms ou ceux ARNs de ces ressources. Lorsque vous synthétisez votre application, l'assemblage cloud créé dans le
cdk.outdossier contient un modèle distinct pour chaque environnement. L'ensemble de votre build est déterministe. Aucune out-of-band modification n'est apportée à votre application, et chaque validation donne toujours exactement le même AWS CloudFormation modèle et les mêmes ressources associées. Cela rend les tests unitaires beaucoup plus fiables.
- Mesurez tout
-
Atteindre l'objectif d'un déploiement continu complet, sans intervention humaine, nécessite un haut niveau d'automatisation. Cette automatisation n'est possible qu'avec une surveillance étendue. Pour mesurer tous les aspects de vos ressources déployées, créez des métriques, des alarmes et des tableaux de bord. Ne vous limitez pas à mesurer des éléments tels que l'utilisation du processeur et l'espace disque. Enregistrez également les indicateurs de votre activité et utilisez-les pour automatiser les décisions de déploiement, telles que les annulations. La plupart des constructions L2 de AWS CDK proposent des méthodes pratiques pour vous aider à créer des métriques, telles que la
metricUserErrors()méthode de la classe.dynamodb.Table
