Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création d'un pipeline, d'étapes et d'actions
Vous pouvez utiliser la AWS CodePipeline console ou le AWS CLI pour créer un pipeline. Les pipelines doivent contenir au moins deux étapes. La première étape d'un pipeline doit être une étape source. Le pipeline doit avoir au moins une autre étape qui est une étape de génération ou de déploiement.
Important
Dans le cadre de la création d'un pipeline, un compartiment d'artefacts S3 fourni par le client sera utilisé CodePipeline pour les artefacts. (Ceci est différent du compartiment utilisé pour une action source S3.) Si le compartiment d'artefacts S3 se trouve dans un compte différent de celui de votre pipeline, assurez-vous que le compartiment d'artefacts S3 appartient à cette personne sûre et Comptes AWS qu'elle sera fiable.
Vous pouvez ajouter à votre pipeline des actions qui se trouvent dans un Région AWS autre pipeline. Une action interrégionale est une action dans laquelle an Service AWS est le fournisseur d'une action et le type d'action ou le type de fournisseur se trouve dans une AWS région différente de votre pipeline. Pour de plus amples informations, veuillez consulter Ajouter une action interrégionale dans CodePipeline.
Vous pouvez également créer des pipelines qui créent et déploient des applications basées sur des conteneurs en utilisant Amazon ECS comme fournisseur de déploiement. Avant de créer un pipeline qui déploie des applications basées sur des conteneurs avec Amazon ECS, vous devez créer un fichier de définitions d'images comme décrit dans. Référence pour les fichiers de définitions d'image
CodePipeline utilise des méthodes de détection des modifications pour démarrer votre pipeline lorsqu'une modification du code source est poussée. Ces méthodes de détection sont basées sur le type de source :
-
CodePipeline utilise Amazon CloudWatch Events pour détecter les modifications apportées à votre référentiel CodeCommit source et à votre branche ou à votre compartiment source S3.
Note
Lorsque vous utilisez la console pour créer ou modifier un pipeline, les ressources de détection des modifications sont créées pour vous. Si vous utilisez la AWS CLI pour créer le pipeline, vous devez créer vous-même les ressources supplémentaires. Pour de plus amples informations, veuillez consulter CodeCommit actions à la source et EventBridge.
Rubriques
Création d'un pipeline personnalisé (console)
Pour créer un pipeline personnalisé dans la console, vous devez fournir l'emplacement du fichier source et des informations sur les fournisseurs que vous utiliserez pour vos actions.
Lorsque vous utilisez la console pour créer un pipeline, vous devez inclure une étape source et l'une des actions suivantes :
-
Une étape de génération.
-
Une étape de déploiement.
Lorsque vous utilisez l'assistant de pipeline, il CodePipeline crée les noms des étapes (source, build, staging). Ces noms ne peuvent pas être modifiés. Vous pouvez utiliser des noms plus spécifiques (par exemple, BuildToGamma ou DeployToProd) pour les étapes que vous ajouterez ultérieurement.
Étape 1 : Créer et nommer votre pipeline
Connectez-vous à la CodePipeline console Console de gestion AWS et ouvrez-la à l'adresse http://console.aws.amazon. com/codesuite/codepipeline/home
. -
Sur la page Welcome (Bienvenue), choisissez Créer un pipeline.
Si c'est la première fois que vous l'utilisez CodePipeline, choisissez Get Started.
-
Sur la page Étape 1 : Choisir une option de création, sous Options de création, choisissez l'option Créer un pipeline personnalisé. Choisissez Suivant.
-
Sur la page Étape 2 : Choisir les paramètres du pipeline, dans Nom du pipeline, entrez le nom de votre pipeline.
Dans un seul AWS compte, chaque pipeline que vous créez dans une AWS région doit porter un nom unique. Les noms peuvent être réutilisés pour des pipelines de régions différentes.
Note
Une fois le pipeline créé, vous ne pouvez plus modifier son nom. Pour plus d'informations sur les autres limitations, consultez Quotas dans AWS CodePipeline.
-
Dans Type de pipeline, choisissez l'une des options suivantes. Les types de pipelines diffèrent en termes de caractéristiques et de prix. Pour de plus amples informations, veuillez consulter Types de pipelines.
-
Les pipelines de type V1 ont une structure JSON qui contient des paramètres standard au niveau du pipeline, de l'étape et de l'action.
-
Les pipelines de type V2 ont la même structure que les pipelines de type V1, avec une prise en charge de paramètres supplémentaires, tels que les déclencheurs sur les balises Git et les variables au niveau du pipeline.
-
-
Dans Rôle du service, sélectionnez l'une des options suivantes :
-
Choisissez Nouveau rôle de service pour autoriser CodePipeline la création d'un nouveau rôle de service dans IAM.
-
Choisissez Existing service role (Rôle de service existant) pour utiliser un rôle de service déjà créé dans IAM. Dans ARN de rôle, choisissez votre ARN de rôle de service dans la liste.
Note
En fonction de la date de création de votre rôle de service, vous devrez peut-être mettre à jour ses autorisations pour en prendre en charge d'autres Services AWS. Pour plus d'informations, consultez Ajouter des autorisations au rôle CodePipeline de service.
Pour plus d'informations sur le rôle de service et sa déclaration de stratégie, consultez Gérer le rôle CodePipeline de service.
-
-
(Facultatif) Sous Variables, choisissez Ajouter une variable pour ajouter des variables au niveau du pipeline.
Pour plus d'informations sur les variables au niveau du pipeline, consultezRéférence aux variables. Pour un didacticiel avec une variable au niveau du pipeline transmise au moment de l'exécution du pipeline, voir. Tutoriel : Utiliser des variables au niveau du pipeline
Note
Bien qu'il soit facultatif d'ajouter des variables au niveau du pipeline, pour un pipeline spécifié avec des variables au niveau du pipeline pour lequel aucune valeur n'est fournie, l'exécution du pipeline échouera.
-
(Facultatif) Développez Advanced settings (Paramètres avancés).
-
Dans Magasin d'artefacts, effectuez l'une des actions suivantes :
-
Choisissez Emplacement par défaut pour utiliser le magasin d'artefacts par défaut, tel que le compartiment d'artefacts S3 désigné par défaut, pour votre pipeline dans le répertoire que Région AWS vous avez sélectionné pour votre pipeline.
-
Choisissez Custom location (Emplacement personnalisé) si vous disposez déjà d'un magasin d'artefacts, par exemple, un compartiment d'artefacts S3, dans la même région que votre pipeline. Dans Bucket (Compartiment), choisissez le nom du compartiment.
Note
Il ne s'agit pas du compartiment source de votre code source. Il s'agit du magasin d'artefacts pour votre pipeline. Un magasin d'artefacts distinct, tel qu'un compartiment S3, est nécessaire pour chaque pipeline. Lorsque vous créez ou modifiez un pipeline, vous devez disposer d'un compartiment d'artefacts dans la région du pipeline et d'un compartiment d'artefacts par AWS région dans laquelle vous exécutez une action.
Pour plus d’informations, consultez Artefacts d'entrée et de sortie et CodePipeline référence de structure de pipeline.
-
-
Dans Encryption key (Clé de chiffrement), effectuez l'une des opérations suivantes :
-
Pour utiliser la CodePipeline valeur par défaut AWS KMS key pour chiffrer les données dans le magasin d'artefacts du pipeline (compartiment S3), choisissez Default AWS Managed Key.
-
Pour utiliser votre clé gérée par le client afin de chiffrer les données dans le magasin d'artefacts du pipeline (compartiment S3), choisissez Clé gérée par le client. Choisissez l'ID de clé, l'ARN de clé ou l'alias ARN.
-
-
Choisissez Suivant.
Étape 2 : Créer une étape source
-
Sur la page Étape 3 : Ajouter une étape source, dans Source provider, choisissez le type de référentiel dans lequel votre code source est stocké, puis spécifiez les options requises. Les champs supplémentaires s'affichent en fonction du fournisseur de source sélectionné comme suit.
-
Pour Bitbucket Cloud GitHub (via une GitHub application), GitHub Enterprise Server, GitLab .com ou en mode GitLab autogéré :
-
Sous Connexion, choisissez une connexion existante ou créez-en une nouvelle. Pour créer ou gérer une connexion pour votre action GitHub source, consultezGitHub connexions.
-
Choisissez le référentiel que vous souhaitez utiliser comme emplacement source pour votre pipeline.
Choisissez d'ajouter un déclencheur ou de filtrer les types de déclencheurs pour démarrer votre pipeline. Pour plus d'informations sur l'utilisation des déclencheurs, consultezAjouter un déclencheur avec des types d'événements de type code push ou pull request. Pour plus d'informations sur le filtrage à l'aide de modèles globulaires, consultezUtilisation de modèles globulaires dans la syntaxe.
-
Dans Format d'artefact de sortie, choisissez le format de vos artefacts.
-
Pour stocker les artefacts de sortie de l' GitHub action à l'aide de la méthode par défaut, choisissez CodePipelinepar défaut. L'action accède aux fichiers depuis le GitHub référentiel et stocke les artefacts dans un fichier ZIP dans le magasin d'artefacts du pipeline.
-
Pour stocker un fichier JSON contenant une référence d'URL au référentiel afin que les actions en aval puissent exécuter directement les commandes Git, choisissez Full clone (Clone complet). Cette option ne peut être utilisée que par les actions CodeBuild en aval.
Si vous choisissez cette option, vous devrez mettre à jour les autorisations associées à votre rôle de service de CodeBuild projet, comme indiqué dansRésolution des problèmes CodePipeline. Pour consulter un didacticiel expliquant comment utiliser l'option de clonage complet, voirTutoriel : Utiliser un clone complet avec une source de GitHub pipeline.
-
-
-
Pour Amazon S3 :
-
Dans Emplacement Amazon S3, indiquez le nom du compartiment S3 et le chemin d'accès à l'objet dans un compartiment où la gestion des versions est activée. Le format du nom et du chemin du compartiment ressemblent à l'exemple suivant :
s3://bucketName/folderName/objectNameNote
Lorsque Amazon S3 est le fournisseur source de votre pipeline, vous pouvez compresser votre ou vos fichiers source dans un seul fichier .zip et télécharger le fichier .zip dans votre compartiment source. Vous pouvez également charger un seul fichier décompressé ; toutefois, les actions en aval qui attendent un fichier .zip échoueront.
-
Après avoir choisi le compartiment source S3, vous CodePipeline créez la règle Amazon CloudWatch Events et AWS CloudTrail le journal à créer pour ce pipeline. Acceptez les valeurs par défaut sous Options de détection des modifications. Cela permet d' CodePipeline utiliser Amazon CloudWatch Events et AWS CloudTrail de détecter les modifications apportées à votre nouveau pipeline. Choisissez Suivant.
-
-
Pour AWS CodeCommit :
-
Dans Nom du référentiel, choisissez le nom du CodeCommit référentiel que vous souhaitez utiliser comme emplacement source pour votre pipeline. Dans Nom de branche, depuis la liste déroulante, choisissez la branche que vous souhaitez utiliser.
-
Dans Format d'artefact de sortie, choisissez le format de vos artefacts.
-
Pour stocker les artefacts de sortie de l' CodeCommit action à l'aide de la méthode par défaut, choisissez CodePipelinepar défaut. L'action accède aux fichiers depuis le CodeCommit référentiel et stocke les artefacts dans un fichier ZIP dans le magasin d'artefacts du pipeline.
-
Pour stocker un fichier JSON contenant une référence d'URL au référentiel afin que les actions en aval puissent exécuter directement les commandes Git, choisissez Full clone (Clone complet). Cette option ne peut être utilisée que par les actions CodeBuild en aval.
Si vous choisissez cette option, vous devrez ajouter l'
codecommit:GitPullautorisation à votre rôle de CodeBuild service, comme indiqué dansAjouter CodeBuild GitClone des autorisations pour les actions CodeCommit source. Vous devrez également ajouter lescodecommit:GetRepositoryautorisations à votre rôle de CodePipeline service, comme indiqué dansAjouter des autorisations au rôle CodePipeline de service. Pour consulter un didacticiel expliquant comment utiliser l'option de clonage complet, voirTutoriel : Utiliser un clone complet avec une source de GitHub pipeline.
-
-
Une fois que vous avez choisi le nom du CodeCommit référentiel et la branche, un message s'affiche dans les options de détection des modifications indiquant la règle Amazon CloudWatch Events à créer pour ce pipeline. Acceptez les valeurs par défaut sous Options de détection des modifications. Cela permet d' CodePipeline utiliser Amazon CloudWatch Events pour détecter les modifications apportées à votre nouveau pipeline.
-
-
Pour Amazon ECR :
-
Dans Nom du référentiel, choisissez le nom de votre référentiel Amazon ECR.
-
Dans Balise d'image, spécifiez le nom et la version de l'image, s'ils sont différents de LATEST.
-
Dans Artefacts de sortie, choisissez l'artefact de sortie par défaut, par exemple MyApp, qui contient le nom de l'image et les informations d'URI du référentiel que vous souhaitez utiliser à l'étape suivante.
Pour un didacticiel sur la création d'un pipeline pour Amazon ECS avec des déploiements CodeDeploy bleu-vert incluant un stage source Amazon ECR, consultez. Tutoriel : Création d'un pipeline avec une source Amazon ECR et déploiement ECS-to-CodeDeploy
Lorsque vous incluez un stage source Amazon ECR dans votre pipeline, l'action source génère un
imageDetail.jsonfichier en tant qu'artefact de sortie lorsque vous validez une modification. Pour de plus amples informations concernant le fichierimageDetail.json, veuillez consulter Fichier ImageDetail.json pour les actions de déploiement d'Amazon ECS blue/green. -
Note
L'objet et le type de fichier doivent être compatibles avec le système de déploiement que vous prévoyez d'utiliser (par exemple, Elastic Beanstalk ou). CodeDeploy Les types de fichier .zip, .tar et .tgz peuvent être pris en charge. Pour plus d'informations sur les types de conteneurs pris en charge pour Elastic Beanstalk, consultez Personnalisation et configuration des environnements Elastic Beanstalk et des plateformes prises en charge. Pour plus d'informations sur le déploiement de révisions avec CodeDeploy, consultez les sections Chargement de la révision de votre application et Préparation d'une révision.
-
-
Pour configurer l'étape pour une nouvelle tentative automatique, choisissez Activer la nouvelle tentative automatique en cas d'échec de l'étape. Pour plus d'informations sur la nouvelle tentative automatique, consultezConfiguration d'une étape pour une nouvelle tentative automatique en cas d'échec.
-
Choisissez Suivant.
Étape 4 : Création d'une phase de construction
Cette étape est facultative si vous prévoyez de créer une étape de déploiement.
-
Sur la page Étape 4 : Ajouter une phase de construction, effectuez l'une des opérations suivantes, puis choisissez Next :
-
Choisissez Ignorer l'étape de construction si vous prévoyez de créer une phase de test ou de déploiement.
-
Pour choisir l'action Commandes pour votre phase de construction, sélectionnez Commandes.
Note
L'exécution de l'action Commandes entraînera des frais distincts. AWS CodeBuild Si vous prévoyez d'insérer des commandes de compilation dans le cadre CodeBuild d'une action, choisissez Autres fournisseurs de build, puis sélectionnez CodeBuild.
Dans Commandes, entrez les commandes shell pour votre action. Pour plus d'informations sur l'action Commandes, consultezRéférence d'action des commandes.
-
Pour choisir d'autres fournisseurs de build CodeBuild, par exemple, choisissez Autres fournisseurs. Dans Fournisseur de génération, choisissez un fournisseur d'action personnalisée de services de génération, puis indiquez les détails de configuration pour ce fournisseur. Pour obtenir un exemple sur la manière d'ajouter Jenkins comme fournisseur de génération, consultez Didacticiel : Création d'un pipeline à quatre étapes.
-
Dans Fournisseur de génération, choisissez AWS CodeBuild.
Dans Région, choisissez la AWS région dans laquelle se trouve la ressource. Le champ Région indique l'endroit où les AWS ressources sont créées pour ce type d'action et ce type de fournisseur. Ce champ s'affiche uniquement pour les actions pour lesquelles le fournisseur d'actions est un Service AWS. Le champ Région correspond par défaut à la même AWS région que votre pipeline.
Dans Nom du projet, choisissez votre projet de génération. Si vous avez déjà créé un projet de construction dans CodeBuild, choisissez-le. Vous pouvez également créer un projet de construction dans CodeBuild puis revenir à cette tâche. Suivez les instructions de la section Création d'un pipeline utilisant CodeBuild dans le Guide de l'utilisateur CodeBuild.
Sous Spécifications de construction, le fichier CodeBuild buildspec est facultatif et vous pouvez saisir des commandes à la place. Dans Insérer des commandes de construction, entrez les commandes shell pour votre action. Pour plus d'informations sur les considérations relatives à l'utilisation des commandes de génération, consultezRéférence d'action des commandes. Choisissez Utiliser un fichier buildspec si vous souhaitez exécuter des commandes dans d'autres phases ou si vous avez une longue liste de commandes.
Dans Variables d'environnement, pour ajouter des variables d' CodeBuildenvironnement à votre action de génération, choisissez Ajouter une variable d'environnement. Chaque variable est composée de trois entrées :
-
Dans Nom, entrez le nom ou clé de la variable d'environnement.
-
Dans Valeur, entrez la valeur de la variable d'environnement. Si vous choisissez Parameter pour le type de variable, assurez-vous que cette valeur est le nom d'un paramètre que vous avez déjà stocké dans le magasin de paramètres de AWS Systems Manager.
Note
Nous déconseillons vivement l'utilisation de variables d'environnement pour stocker des valeurs sensibles, en particulier des AWS informations d'identification. Lorsque vous utilisez la CodeBuild console ou la AWS CLI, les variables d'environnement sont affichées en texte brut. Pour les valeurs sensibles, nous vous recommandons d'utiliser plutôt le type Parameter (Paramètre).
-
(Facultatif) Dans Type, entrez le type de variable d'environnement. Les valeurs valides sont Plaintext (Texte brut) ou Parameter (Paramètre). La valeur par défaut est Plaintext (Texte brut).
(Facultatif) Dans Type de construction, choisissez l'une des options suivantes :
-
Pour exécuter chaque build en une seule exécution d'action de build, choisissez Single build.
-
Pour exécuter plusieurs builds lors de la même exécution d'une action de build, choisissez Batch build.
(Facultatif) Si vous avez choisi d'exécuter des constructions par lots, vous pouvez choisir Combiner tous les artefacts du lot dans un seul emplacement pour placer tous les artefacts de construction dans un seul artefact de sortie.
-
-
-
Pour configurer l'étape pour une nouvelle tentative automatique, choisissez Activer la nouvelle tentative automatique en cas d'échec de l'étape. Pour plus d'informations sur la nouvelle tentative automatique, consultezConfiguration d'une étape pour une nouvelle tentative automatique en cas d'échec.
-
Choisissez Suivant.
Étape 5 : Création d'une phase de test
Cette étape est facultative si vous prévoyez de créer une phase de construction ou de déploiement.
-
Sur la page Étape 5 : Ajouter une phase de test, effectuez l'une des opérations suivantes, puis choisissez Next :
-
Choisissez Ignorer la phase de test si vous prévoyez de créer une phase de construction ou de déploiement.
-
Dans Fournisseur de tests, choisissez le fournisseur d'actions de test et renseignez les champs appropriés.
-
-
Choisissez Suivant.
Étape 6 : Création d'une phase de déploiement
Cette étape est facultative si vous avez déjà créé une étape de génération.
-
Sur la page Étape 6 : Ajouter une phase de déploiement, effectuez l'une des opérations suivantes, puis choisissez Next :
-
Choisissez Ignorer l'étape de déploiement si vous avez créé une phase de génération ou de test au cours des étapes précédentes.
Note
Cette option n'apparaît pas si vous avez déjà ignoré l'étape de génération ou de test.
-
Dans Deploy provider (Fournisseur de déploiement), choisissez une action personnalisée que vous avez créée pour un fournisseur de déploiement.
Dans Région, pour les actions interrégionales uniquement, choisissez la AWS région dans laquelle la ressource est créée. Le champ Région indique l'endroit où les AWS ressources sont créées pour ce type d'action et ce type de fournisseur. Ce champ s'affiche uniquement pour les actions dont le fournisseur d'actions est un Service AWS. Le champ Région correspond par défaut à la même AWS région que votre pipeline.
-
Dans Fournisseur de déploiement, les champs sont disponibles pour les fournisseurs par défaut comme suit :
-
CodeDeploy
Dans Nom de l'application, entrez ou choisissez le nom d'une CodeDeploy application existante. Dans Groupe de déploiement, saisissez le nom d'un groupe de déploiement pour l'application. Choisissez Suivant. Vous pouvez également créer une application, un groupe de déploiement ou les deux dans la console CodeDeploy.
-
AWS Elastic Beanstalk
Dans Nom de l'application, entrez ou choisissez le nom d'une application Elastic Beanstalk existante. Dans Nom de l'environnement, saisissez un environnement pour l'application. Choisissez Suivant. Vous pouvez également créer une application, un environnement ou les deux dans la console Elastic Beanstalk.
-
AWS OpsWorks Stacks
Dans Stack, saisissez ou choisissez le nom de la pile que vous souhaitez utiliser. Dans Couche, choisissez la couche à laquelle appartiennent vos instances cibles. Dans App, choisissez l'application que vous souhaitez mettre à jour et déployer. Si vous avez besoin de créer une application, choisissez Crée une nouvelle dans AWS OpsWorks.
Pour plus d'informations sur l'ajout d'une application à une pile et à une couche AWS OpsWorks, consultez la section Ajouter des applications dans le guide de AWS OpsWorks l'utilisateur.
Pour un end-to-end exemple d'utilisation d'un pipeline simple en CodePipeline tant que source du code que vous exécutez sur des AWS OpsWorks couches, consultez la section Utilisation CodePipeline avec AWS OpsWorks Stacks.
-
AWS CloudFormation
Effectuez l’une des actions suivantes :
-
En mode Action, choisissez Créer ou mettre à jour une pile, entrez le nom de la pile et le nom du fichier modèle, puis choisissez le nom du rôle AWS CloudFormation à assumer. Entrez éventuellement le nom d'un fichier de configuration et choisissez une option de fonctionnalité IAM.
-
En mode Action, choisissez Créer ou remplacer un ensemble de modifications, entrez un nom de pile et un nom d'ensemble de modifications, puis choisissez le nom d'un rôle AWS CloudFormation à assumer. Entrez éventuellement le nom d'un fichier de configuration et choisissez une option de fonctionnalité IAM.
Pour plus d'informations sur l'intégration de AWS CloudFormation fonctionnalités dans un pipeline CodePipeline, voir Continuous Delivery with CodePipeline dans le guide de AWS CloudFormation l'utilisateur.
-
-
Amazon ECS
Dans Nom du cluster, entrez ou choisissez le nom d'un cluster Amazon ECS existant. Dans Nom du service, saisissez ou choisissez le nom du service exécuté sur le cluster. Vous pouvez également créer un cluster et un service. Dans Nom du fichier d'image, tapez le nom du fichier de définitions d'image qui décrit le conteneur et l'image du service.
Note
L'action de déploiement Amazon ECS nécessite un
imagedefinitions.jsonfichier comme entrée pour l'action de déploiement. Le nom de fichier par défaut est imagedefinitions.json. Si vous choisissez d'utiliser un autre nom de fichier, vous devez l'indiquer lorsque vous créez la phase de déploiement du pipeline. Pour de plus amples informations, veuillez consulter fichier imagedefinitions.json pour les actions de déploiement standard d'Amazon ECS.Choisissez Suivant.
Note
Assurez-vous que votre cluster Amazon ECS est configuré avec deux instances ou plus. Les clusters Amazon ECS doivent contenir au moins deux instances afin que l'une soit maintenue en tant qu'instance principale et l'autre utilisée pour les nouveaux déploiements.
Pour un didacticiel concernant le déploiement d'applications basées sur conteneur avec votre pipeline, consultez Didacticiel : Déploiement continu avec CodePipeline.
-
Amazon ECS (Bleu/vert)
Entrez l' CodeDeploy application et le groupe de déploiement, la définition de la tâche Amazon ECS et les informations sur AppSpec le fichier, puis choisissez Next.
Note
L'action Amazon ECS (Bleu/Vert) requiert un fichier imageDetail.json en tant qu'artefact d'entrée de l'action de déploiement. Étant donné que l'action source Amazon ECR crée ce fichier, les pipelines dotés d'une action source Amazon ECR n'ont pas besoin de fournir de fichier.
imageDetail.jsonPour de plus amples informations, veuillez consulter Fichier ImageDetail.json pour les actions de déploiement d'Amazon ECS blue/green.Pour un didacticiel sur la création d'un pipeline pour les déploiements bleu-vert vers un cluster Amazon ECS avec CodeDeploy, consultez. Tutoriel : Création d'un pipeline avec une source Amazon ECR et déploiement ECS-to-CodeDeploy
-
AWS Service Catalog
Choisissez Enter deployment configuration (Entrer une configuration de déploiement) si vous souhaitez utiliser des champs dans la console pour spécifier votre configuration, ou choisissez Configuration file (Fichier de configuration) si vous disposez d'un fichier de configuration distinct. Entrez les informations sur le produit et la configuration, puis choisissez Suivant.
Pour un didacticiel sur le déploiement des modifications apportées aux produits dans Service Catalog avec votre pipeline, consultezTutoriel : Création d'un pipeline à déployer sur Service Catalog.
-
Kit Alexa Skills
Dans Alexa Skill ID (ID Alexa Skill), entrez l'ID de votre compétence Alexa. Dans Client ID (ID client) et Client secret (Clé secret client), entrez les informations d'identification générées à l'aide d'un profil de sécurité Login with Amazon (LWA). Dans Refresh token (Jeton d'actualisation), entrez le jeton d'actualisation que vous avez généré à l'aide de la commande CLI ASK pour récupérer un jeton d'actualisation. Choisissez Suivant.
Pour accéder à un didacticiel sur le déploiement des compétences Alexa avec votre pipeline et la génération des informations d'identification LWA, consultez Didacticiel : Création d'un pipeline qui déploie un kit Amazon Alexa Skill.
-
Amazon S3
Dans Bucket (Compartiment), entrez le nom du compartiment S3 que vous souhaitez utiliser. Choisissez Extract file before deploy (Extraire le fichier avant le déploiement) si l'artefact d'entrée de votre étape de déploiement est un fichier ZIP. Si Extract file before deploy (Extraire le fichier avant le déploiement) est sélectionné, vous pouvez, si vous le souhaitez, entrer une valeur pour Deployment path (Chemin du déploiement), où votre fichier ZIP sera décompressé. Dans le cas contraire, vous devez saisir une valeur dans Clé d'objet S3.
Note
La plupart des artefacts source et des artefacts de sortie d'étape de génération sont compressés. Tous les fournisseurs de sources de pipeline, à l'exception d'Amazon S3, compressent vos fichiers source avant de les fournir comme artefact d'entrée pour l'action suivante.
(Facultatif) Dans Caned ACL, entrez l'ACL prédéfinie à appliquer à l'objet déployé sur Amazon S3.
Note
L'application d'une liste ACL prête à l'emploi remplace toutes les listes ACL existantes appliquées à l'objet.
(Facultatif) Dans Cache control (Contrôle de cache), spécifiez les paramètres de contrôle de cache pour les demandes pour télécharger des objets à partir du compartiment. Pour obtenir la liste des valeurs valides, consultez le champ d'en-tête
Cache-Controlpour les opérations HTTP. Pour entrer plusieurs valeurs dans Cache control (Contrôle de cache), utilisez une virgule entre chaque valeur. Vous pouvez ajouter un espace après chaque virgule (facultatif), comme illustré dans cet exemple. 
L'exemple précédent s'affiche dans l'interface de ligne de commande comme suit :
"CacheControl": "public, max-age=0, no-transform"Choisissez Suivant.
Pour un didacticiel sur la création d'un pipeline avec un fournisseur d'actions de déploiement Amazon S3, consultezTutoriel : Création d'un pipeline qui utilise Amazon S3 comme fournisseur de déploiement.
-
-
-
Pour configurer l'étape pour une nouvelle tentative automatique, choisissez Activer la nouvelle tentative automatique en cas d'échec de l'étape. Pour plus d'informations sur la nouvelle tentative automatique, consultezConfiguration d'une étape pour une nouvelle tentative automatique en cas d'échec.
-
Pour configurer la phase de restauration automatique, choisissez Configurer la restauration automatique en cas d'échec de l'étape. Pour plus d'informations sur l'annulation automatique, consultezConfiguration d'une étape pour une annulation automatique.
-
Choisissez Étape suivante.
Étape 7 : Passez en revue le pipeline
-
Sur la page Étape 7 : Révision, passez en revue la configuration de votre pipeline, puis choisissez Create pipeline pour créer le pipeline ou Previous pour revenir en arrière et modifier vos choix. Pour quitter l'assistant sans créer de pipeline, choisissez Cancel.
Maintenant que vous avez créé votre pipeline, vous pouvez le voir dans la console. Le pipeline commence à s'exécuter après sa création. Pour de plus amples informations, veuillez consulter Afficher les pipelines et les détails dans CodePipeline. Pour plus d'informations sur les modifications de votre pipeline, consultez Modifier un pipeline dans CodePipeline.
Création d'un pipeline (interface de ligne de commande)
Pour utiliser le AWS CLI pour créer un pipeline, vous devez créer un fichier JSON pour définir la structure du pipeline, puis exécuter la create-pipeline commande avec le --cli-input-json paramètre.
Important
Vous ne pouvez pas utiliser le AWS CLI pour créer un pipeline incluant les actions des partenaires. Vous devez plutôt utiliser la CodePipeline console.
Pour plus d'informations sur la structure du pipeline, consultez CodePipeline référence de structure de pipeline et create-pipeline dans la référence de l' CodePipeline API.
Pour créer un fichier JSON, utilisez l'exemple de fichier JSON de pipeline, modifiez-le, puis appelez ce fichier lorsque vous exécutez la commande create-pipeline.
Prérequis :
Vous avez besoin de l'ARN du rôle de service que vous avez créé pour CodePipeline dansCommencer avec CodePipeline. Vous utilisez le rôle CodePipeline de service ARN dans le fichier JSON du pipeline lorsque vous exécutez la create-pipeline commande. Pour plus d'informations sur la création d'un rôle de service, consultez la section Création du rôle CodePipeline de service. Contrairement à la console, l'exécution de la create-pipeline commande dans le AWS CLI ne permet pas de créer le rôle CodePipeline de service pour vous. Le rôle de service doit déjà exister.
Vous avez besoin du nom d'un compartiment S3 où les artefacts du pipeline sont stockés. Ce compartiment doit être situé dans la même région que votre pipeline. Vous utilisez le nom du compartiment dans le fichier JSON du pipeline lorsque vous exécutez la commande create-pipeline. Contrairement à la console, l'exécution de la create-pipeline commande dans le AWS CLI ne crée pas de compartiment S3 pour le stockage des artefacts. Le compartiment doit déjà exister.
Note
Vous pouvez aussi utiliser la commande get-pipeline pour obtenir une copie de la structure JSON de ce pipeline, puis modifier cette structure dans un éditeur de texte brut.
Rubriques
Pour créer le fichier JSON
-
Sur un terminal (Linux, macOS ou Unix) ou à l'invite de commande (Windows), créez un nouveau fichier texte dans un répertoire local.
-
(Facultatif) Vous pouvez ajouter une ou plusieurs variables au niveau du pipeline. Vous pouvez référencer cette valeur dans la configuration des CodePipeline actions. Vous pouvez ajouter les noms et les valeurs des variables lorsque vous créez le pipeline, et vous pouvez également choisir d'attribuer des valeurs lorsque vous démarrez le pipeline dans la console.
Note
Bien qu'il soit facultatif d'ajouter des variables au niveau du pipeline, pour un pipeline spécifié avec des variables au niveau du pipeline pour lequel aucune valeur n'est fournie, l'exécution du pipeline échouera.
Une variable au niveau du pipeline est résolue au moment de l'exécution du pipeline. Toutes les variables sont immuables, ce qui signifie qu'elles ne peuvent pas être mises à jour une fois qu'une valeur a été attribuée. Les variables au niveau du pipeline avec des valeurs résolues s'afficheront dans l'historique pour chaque exécution.
Vous fournissez des variables au niveau du pipeline à l'aide de l'attribut variables de la structure du pipeline. Dans l'exemple suivant, la valeur de la variable
Variable1estValue1."variables": [ { "name": "Timeout", "defaultValue": "1000", "description": "description" } ]Ajoutez cette structure au JSON de pipeline ou à l'exemple de JSON à l'étape suivante. Pour plus d'informations sur les variables, y compris les informations sur les espaces de noms, consultezRéférence aux variables.
-
Ouvrez le fichier dans un éditeur de texte brut et modifiez les valeurs pour refléter la structure que vous souhaitez créer. Vous devez au moins modifier le nom du pipeline. Vous devez également prendre en compte si vous souhaitez modifier :
-
Le compartiment S3 où les artefacts de ce pipeline sont stockés.
-
L'emplacement source de votre code.
-
Le fournisseur du déploiement.
-
Comment vous souhaitez que votre code soit déployé.
-
Les balises de votre pipeline.
La structure du modèle de pipeline en deux étapes suivant met en évidence les valeurs que vous devez penser à modifier pour votre pipeline. Votre pipeline contient probablement plus de deux étapes :
{ "pipeline": { "roleArn": "arn:aws:iam::80398EXAMPLE::role/AWS-CodePipeline-Service", "stages": [ { "name": "Source", "actions": [ { "inputArtifacts": [], "name": "Source", "actionTypeId": { "category": "Source", "owner": "AWS", "version": "1", "provider": "S3" }, "outputArtifacts": [ { "name": "MyApp" } ], "configuration": { "S3Bucket": "amzn-s3-demo-source-bucket", "S3ObjectKey": "ExampleCodePipelineSampleBundle.zip", "PollForSourceChanges": "false" }, "runOrder": 1 } ] }, { "name": "Staging", "actions": [ { "inputArtifacts": [ { "name": "MyApp" } ], "name": "Deploy-CodeDeploy-Application", "actionTypeId": { "category": "Deploy", "owner": "AWS", "version": "1", "provider": "CodeDeploy" }, "outputArtifacts": [], "configuration": { "ApplicationName": "CodePipelineDemoApplication", "DeploymentGroupName": "CodePipelineDemoFleet" }, "runOrder": 1 } ] } ], "artifactStore": { "type": "S3", "location": "codepipeline-us-east-2-250656481468" }, "name": "MyFirstPipeline", "version": 1, "variables": [ { "name": "Timeout", "defaultValue": "1000", "description": "description" } ] }, "triggers": [ { "providerType": "CodeStarSourceConnection", "gitConfiguration": { "sourceActionName": "Source", "push": [ { "tags": { "includes": [ "v1" ], "excludes": [ "v2" ] } } ] } } ] "metadata": { "pipelineArn": "arn:aws:codepipeline:us-east-2:80398EXAMPLE:MyFirstPipeline", "updated": 1501626591.112, "created": 1501626591.112 }, "tags": [{ "key": "Project", "value": "ProjectA" }] }Cet exemple ajoute le balisage du pipeline en incluant la clé de balise
Projectet la valeurProjectAsur le pipeline. Pour plus d'informations sur le balisage des ressources CodePipeline, consultezBalisage des ressources.Assurez-vous que le paramètre
PollForSourceChangesest défini comme suit dans votre fichier JSON :"PollForSourceChanges": "false",CodePipeline utilise Amazon CloudWatch Events pour détecter les modifications apportées à votre référentiel CodeCommit source et à votre branche ou à votre compartiment source S3. L'étape suivante comporte les instructions de création de ces ressources pour votre pipeline. Vous pouvez définir l'indicateur sur
falsepour désactiver les vérifications périodiques, lesquelles ne sont pas nécessaires lorsque les méthodes de détection des modifications recommandées sont utilisées. -
-
Pour créer une action de génération, de test ou de déploiement dans une région différente de celle de votre pipeline, vous devez ajouter les éléments suivants à la structure de votre pipeline. Pour obtenir des instructions, veuillez consulter Ajouter une action interrégionale dans CodePipeline.
-
Ajoutez le paramètre
Regionà la structure de pipeline de votre action. -
Utilisez le
artifactStoresparamètre pour spécifier un compartiment d'artefacts pour chaque AWS région dans laquelle vous avez une action.
-
-
Une fois que vous êtes satisfait de sa structure, enregistrez votre fichier en lui attribuant un nom tel que
pipeline.json.
Pour créer un pipeline
-
Exécutez la commande create-pipeline et utilisez le paramètre
--cli-input-jsonpour spécifier le fichier JSON que vous venez de créer.Pour créer un pipeline nommé à l'
MySecondPipelineaide d'un fichier JSON nommé pipeline.json qui inclut le nom «MySecondPipeline» comme valeurnamedans le JSON, votre commande devrait ressembler à ce qui suit :aws codepipeline create-pipeline --cli-input-json file://pipeline.jsonImportant
N'oubliez pas d'inclure
file://devant le nom du fichier. Il est nécessaire dans cette commande.Cette commande renvoie la structure de l'ensemble du pipeline que vous avez créé.
-
Pour afficher le pipeline, ouvrez la CodePipeline console et choisissez-le dans la liste des pipelines, ou utilisez la get-pipeline-state commande. Pour de plus amples informations, veuillez consulter Afficher les pipelines et les détails dans CodePipeline.
-
Si vous utilisez l'interface de ligne de commande pour créer un pipeline, vous devez créer manuellement les ressources de détection des modifications recommandées pour votre pipeline :
-
Pour un pipeline doté d'un CodeCommit référentiel, vous devez créer manuellement la règle CloudWatch Events, comme décrit dansCréation d'une EventBridge règle pour une CodeCommit source (CLI).
-
Pour un pipeline avec une source Amazon S3, vous devez créer manuellement la règle et le suivi des CloudWatch AWS CloudTrail événements, comme décrit dansConnexion aux actions source Amazon S3 qui utilisent EventBridge et AWS CloudTrail.
-
Création d'un pipeline à partir de modèles statiques
Vous pouvez créer un pipeline dans la console qui utilise un modèle pour configurer un pipeline avec le code source et les propriétés que vous spécifiez. Vous devez fournir l'emplacement du fichier source et des informations sur les fournisseurs de source que vous utiliserez pour vos actions. Vous pouvez spécifier une action source pour Amazon ECR ou pour tout référentiel tiers pris en charge par CodeConnections, tel que. GitHub
Le modèle créera une pile CloudFormation pour votre pipeline qui inclut les ressources suivantes :
-
Un pipeline est créé avec le type de pipeline V2. Dans Type de pipeline, choisissez l'une des options suivantes. Les types de pipelines diffèrent en termes de caractéristiques et de prix. Pour de plus amples informations, veuillez consulter Types de pipelines.
-
Un rôle de service est créé pour votre pipeline et référencé dans le modèle.
-
Un magasin d'artefacts est créé à l'aide du magasin d'artefacts par défaut, tel que le compartiment d'artefacts S3 désigné par défaut, pour votre pipeline dans le répertoire que Région AWS vous avez sélectionné pour votre pipeline.
Pour consulter la collection de modèles de démarrage open source utilisés pour l'assistant de création de modèles statiques, consultez le référentiel à l'adresse https://github.com/aws/codepipeline-starter-templates
Lorsque vous utilisez des modèles statiques pour créer un pipeline, la structure du pipeline est configurée dans chaque modèle en fonction des besoins du cas d'utilisation. Par exemple, le modèle de déploiement vers CloudFormation est utilisé comme exemple dans cette procédure. Le modèle génère un pipeline nommé DeployToCloudFormationServiceselon la structure suivante :
-
Une phase de construction qui contient une action source avec une configuration que vous spécifiez dans l'assistant.
-
Une phase de déploiement avec une action de déploiement et une pile de ressources associée CloudFormation.
Lorsque vous utilisez un modèle statique pour créer un pipeline, il CodePipeline crée les noms des étapes (source, build, staging). Ces noms ne peuvent pas être modifiés. Vous pouvez utiliser des noms plus spécifiques (par exemple, BuildToGamma ou DeployToProd) pour les étapes que vous ajouterez ultérieurement.
Étape 1 : accéder à la console
Connectez-vous à la CodePipeline console Console de gestion AWS et ouvrez-la à l'adresse http://console.aws.amazon. com/codesuite/codepipeline/home
. -
Sur la page Welcome (Bienvenue), choisissez Créer un pipeline.
Si c'est la première fois que vous l'utilisez CodePipeline, choisissez Get Started.
Étape 2 : Choisissez le modèle
Choisissez un modèle pour créer un pipeline avec une phase de déploiement, une automatisation ou un pipeline CI.
-
Sur la page Étape 1 : Choisir une option de création, effectuez l'une des opérations suivantes, puis choisissez Suivant :
-
Choisissez Deployment si vous prévoyez de créer une phase de déploiement. Consultez les options des modèles déployés sur ECR ou CloudFormation. Pour cet exemple, choisissez Deployment, puis choisissez de déployer vers CloudFormation.
-
Choisissez Continuous Integration si vous envisagez de créer un pipeline CI. Consultez les options pour les pipelines CI, telles que la construction vers Gradle.
-
Choisissez Automation si vous envisagez de créer un pipeline automatisé. Consultez les options d'automatisation, telles que la planification d'une construction en python.
-
-
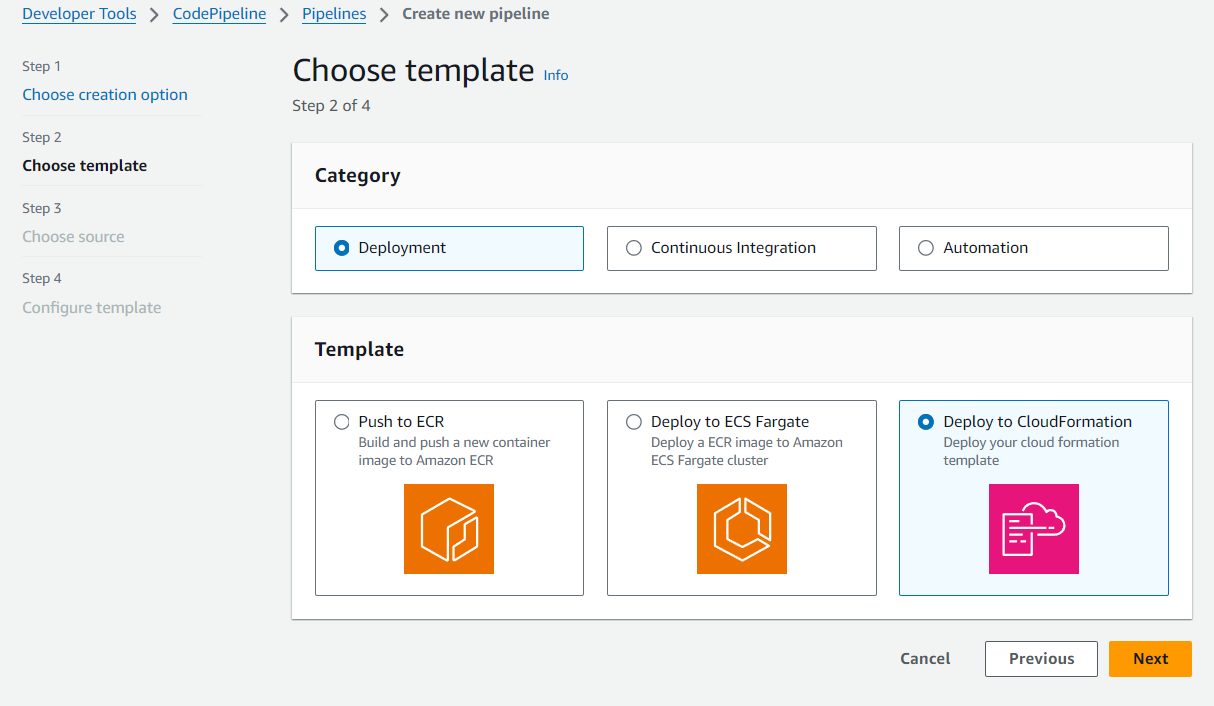
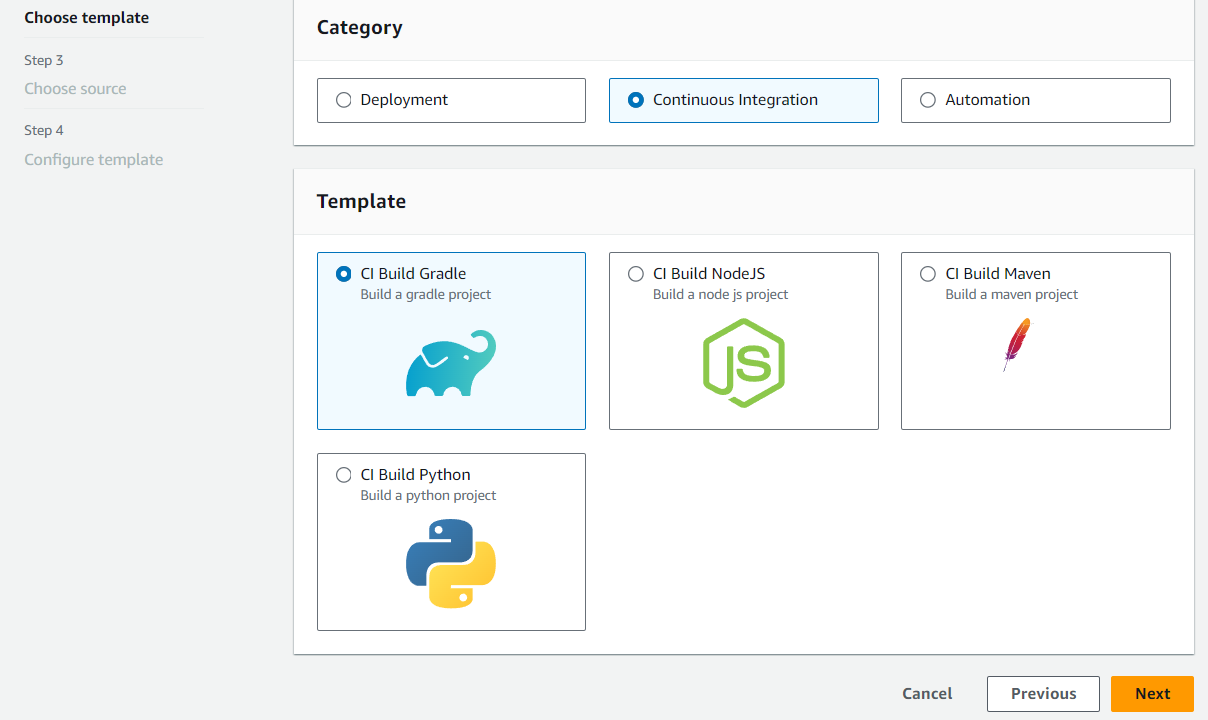
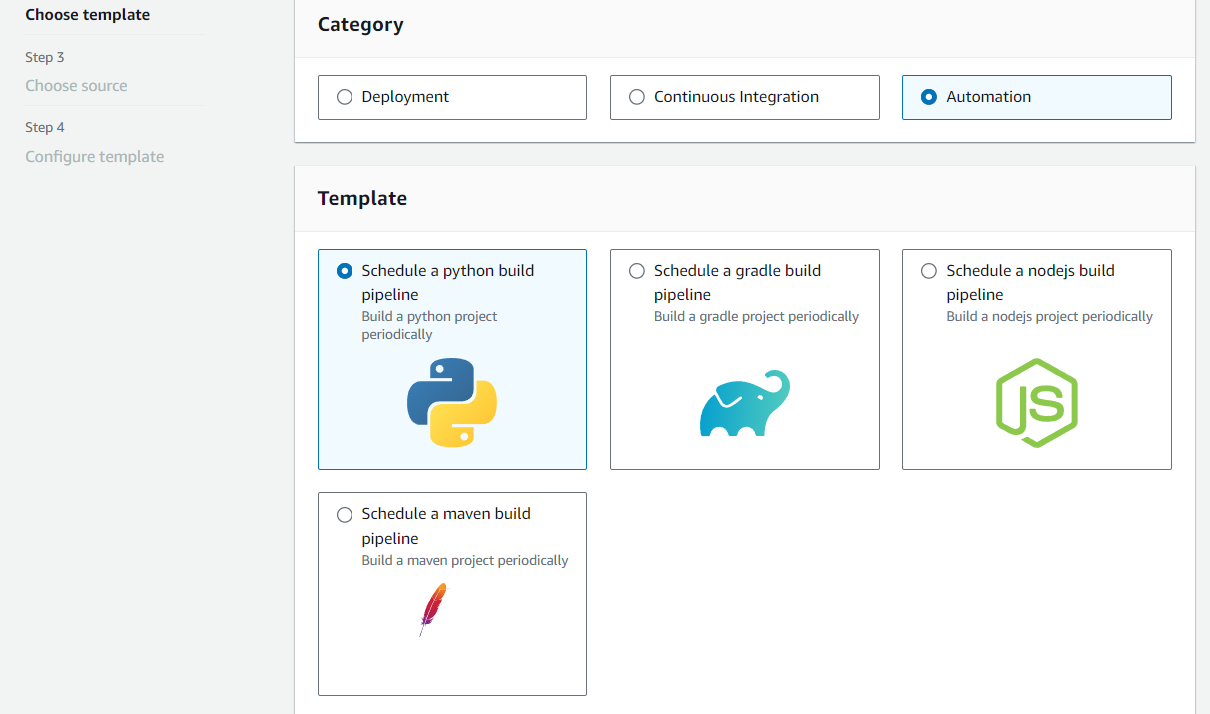
Étape 3 : Choisissez la source
-
Sur la page Étape 3 : Choisir une source, dans Fournisseur de source, choisissez le fournisseur du référentiel dans lequel votre code source est stocké, spécifiez les options requises, puis choisissez Étape suivante.
-
Pour Bitbucket Cloud GitHub (via une GitHub application), GitHub Enterprise Server, GitLab .com ou en mode GitLab autogéré :
-
Sous Connexion, choisissez une connexion existante ou créez-en une nouvelle. Pour créer ou gérer une connexion pour votre action GitHub source, consultezGitHub connexions.
-
Choisissez le référentiel que vous souhaitez utiliser comme emplacement source pour votre pipeline.
Choisissez d'ajouter un déclencheur ou de filtrer les types de déclencheurs pour démarrer votre pipeline. Pour plus d'informations sur l'utilisation des déclencheurs, consultezAjouter un déclencheur avec des types d'événements de type code push ou pull request. Pour plus d'informations sur le filtrage à l'aide de modèles globulaires, consultezUtilisation de modèles globulaires dans la syntaxe.
-
Dans Format d'artefact de sortie, choisissez le format de vos artefacts.
-
Pour stocker les artefacts de sortie de l' GitHub action à l'aide de la méthode par défaut, choisissez CodePipelinepar défaut. L'action accède aux fichiers depuis le GitHub référentiel et stocke les artefacts dans un fichier ZIP dans le magasin d'artefacts du pipeline.
-
Pour stocker un fichier JSON contenant une référence d'URL au référentiel afin que les actions en aval puissent exécuter directement les commandes Git, choisissez Full clone (Clone complet). Cette option ne peut être utilisée que par les actions CodeBuild en aval.
Si vous choisissez cette option, vous devrez mettre à jour les autorisations associées à votre rôle de service de CodeBuild projet, comme indiqué dansRésolution des problèmes CodePipeline. Pour consulter un didacticiel expliquant comment utiliser l'option de clonage complet, voirTutoriel : Utiliser un clone complet avec une source de GitHub pipeline.
-
-
-
Pour Amazon ECR :
-
Dans Nom du référentiel, choisissez le nom de votre référentiel Amazon ECR.
-
Dans Balise d'image, spécifiez le nom et la version de l'image, s'ils sont différents de LATEST.
-
Dans Artefacts de sortie, choisissez l'artefact de sortie par défaut, par exemple MyApp, qui contient le nom de l'image et les informations d'URI du référentiel que vous souhaitez utiliser à l'étape suivante.
Lorsque vous incluez un stage source Amazon ECR dans votre pipeline, l'action source génère un
imageDetail.jsonfichier en tant qu'artefact de sortie lorsque vous validez une modification. Pour de plus amples informations concernant le fichierimageDetail.json, veuillez consulter Fichier ImageDetail.json pour les actions de déploiement d'Amazon ECS blue/green. -
Note
L'objet et le type de fichier doivent être compatibles avec le système de déploiement que vous prévoyez d'utiliser (par exemple, Elastic Beanstalk ou). CodeDeploy Les types de fichier .zip, .tar et .tgz peuvent être pris en charge. Pour plus d'informations sur les types de conteneurs pris en charge pour Elastic Beanstalk, consultez Personnalisation et configuration des environnements Elastic Beanstalk et des plateformes prises en charge. Pour plus d'informations sur le déploiement de révisions avec CodeDeploy, consultez les sections Chargement de la révision de votre application et Préparation d'une révision.
-
Étape 4 : Configuration du modèle
Pour cet exemple, le déploiement vers CloudFormation a été sélectionné. Au cours de cette étape, ajoutez la configuration de votre modèle.
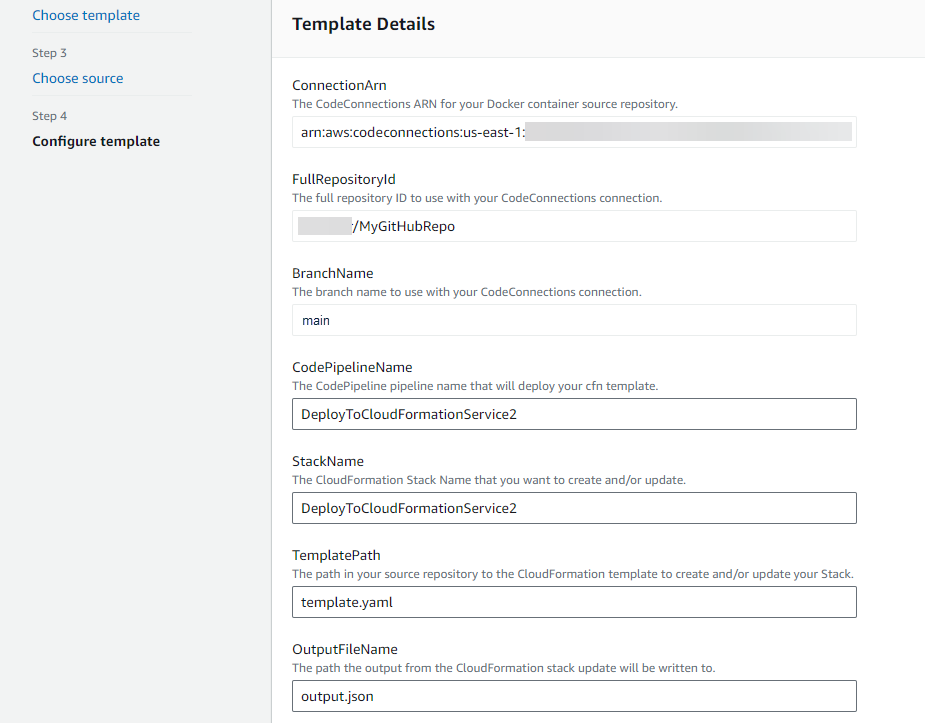
-
À l'étape 4 : Configurer le modèle, dans Nom de la pile, entrez le nom de votre pipeline.
-
Modifiez la politique IAM de l'espace réservé pour les autorisations qui s'appliquent à votre modèle.
-
Choisissez Créer un pipeline à partir d'un modèle
-
Un message s'affiche indiquant que les ressources de votre pipeline sont en cours de création.
Étape 5 : Afficher le pipeline
-
Maintenant que vous avez créé votre pipeline, vous pouvez le visualiser dans la CodePipeline console et voir le stack in CloudFormation. Le pipeline commence à s'exécuter après sa création. Pour de plus amples informations, veuillez consulter Afficher les pipelines et les détails dans CodePipeline. Pour plus d'informations sur les modifications de votre pipeline, consultez Modifier un pipeline dans CodePipeline.
